当前位置:网站首页>sklearn.datasets.make_circles
sklearn.datasets.make_circles
2022-08-10 22:54:00 【xiaozheng123121】
目录
sklearn.datasets.make_circles(n_samples = 100,shuffle = True,noise = None,random_state = None,factor = 0.8)
作用:在 2d 中创建一个包含较小圆的大圆的样本集。
from sklearn.datasets import make_circles
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
X, y = make_circles(n_samples=1_000, factor=0.3, noise=0.05, random_state=0)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=0)
_, (train_ax, test_ax) = plt.subplots(ncols=2, sharex=True, sharey=True, figsize=(8, 4))
train_ax.scatter(X_train[:, 0], X_train[:, 1], c=y_train)
train_ax.set_ylabel("Feature #1")
train_ax.set_xlabel("Feature #0")
train_ax.set_title("Training data")
test_ax.scatter(X_test[:, 0], X_test[:, 1], c=y_test)
test_ax.set_xlabel("Feature #0")
_ = test_ax.set_title("Testing data")
plt.show()
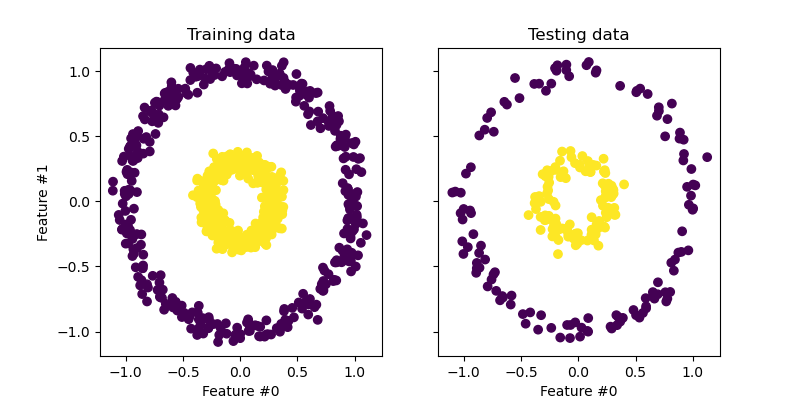
一个简单的玩具数据集,用于可视化聚类和分类算法。
参数:
n_samples : int,optional(默认值= 100)
# 生成的总点数。如果是奇数,则内圆将比外圆具有一个点。
shuffle : bool,optional(默认值= True)
# 是否洗牌样品。
noise: 双倍或无(默认=无)
# 高斯噪声的标准偏差加到数据上。
random_state : int,RandomState实例或None(默认)
# 确定数据集重排和噪声的随机数生成。传递一个int,用于跨多个函数调用的可重现输出。见术语表。
factor : 0 <double <1(默认值= .8)
# 内圈和外圈之间的比例因子。
返回值:
X : 形状数组 [n_samples,2] 生成的样本。
y : 形状数组[n_samples]
每个样本的类成员资格的整数标签(0 或 1)。
参考资料
[1] 官方链接;
边栏推荐
猜你喜欢
EL表达式
Flink(Pometheus监控)

68:第六章:开发文章服务:1:内容梳理;article表介绍;创建【article】文章服务;
还在用 Xshell?你 out 了,推荐一个更现代的终端连接工具,好用到爆!

分享一个后台管理系统可拖拽式组件的设计思路
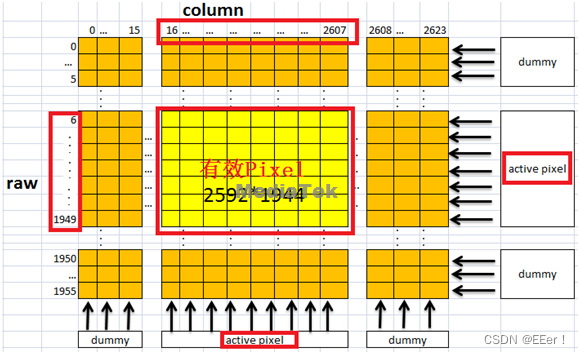
计算需要的MIPI lane数目

高精度减法

解析方法的参数列表(包含参数名称)
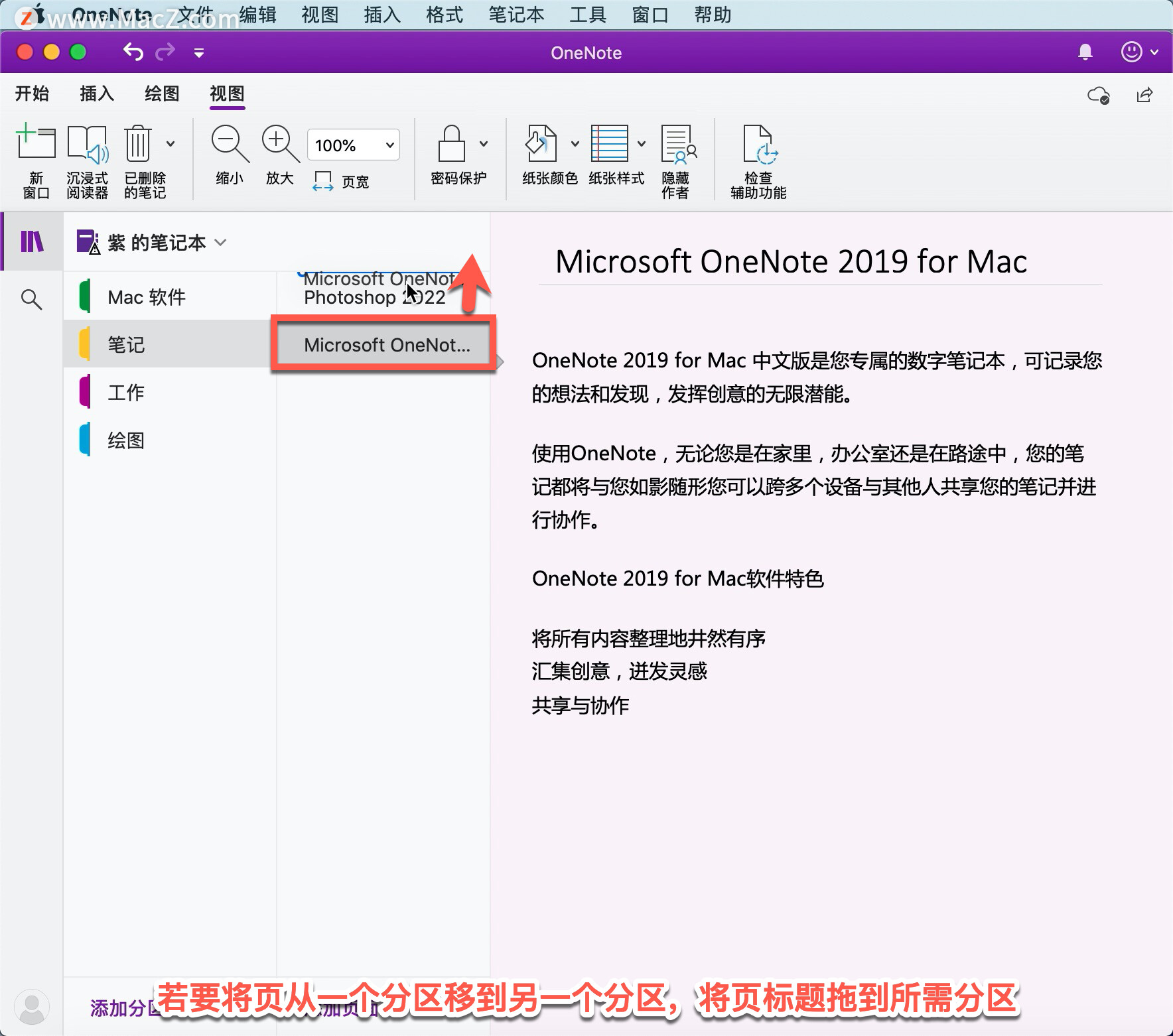
OneNote tutorial, how to organize notebooks in OneNote?
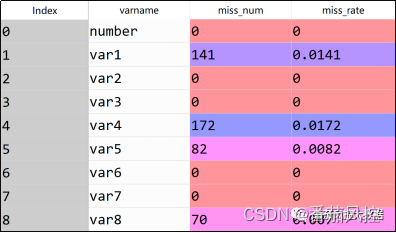
Pro-test is effective | A method to deal with missing features of risk control data
随机推荐
房间虚拟样板间vr制作及价格
还在用 Xshell?你 out 了,推荐一个更现代的终端连接工具,好用到爆!
确诊了!是Druid1.1.20的锅,查询无法映射LocalDateTime类型(带源码解析及解决方案)
Glide监听Activity生命周期源码分析
B站数据分析岗实习生面试记录
August 10, 2022: Building Web Applications for Beginners with ASP.NET Core -- Creating Web UIs with ASP.NET Core
PlaidCTF 2022 Amongst Ourselves: Shipmate writeup
高学历毕业生,该学单片机还是plc?
Android | 安卓好用软件来袭,多御安全浏览器免费又强大
瑞幸咖啡第二季营收33亿:门店达7195家 更换CFO
GoldenGate中使用 exp/imp 进行初始化
完全自定义MaterialButtonToggleGroup颜色。
自学软件测试不知道该如何学起,【软件测试技能图谱|自学测试路线图】
IFIT的架构与功能
How many threads does LabVIEW allocate?
MySQL之JDBC编程增删改查
68:第六章:开发文章服务:1:内容梳理;article表介绍;创建【article】文章服务;
【MySQL】mysql因为字符集导致left join出现Using join buffer (Block Nested Loop)
消息队列总结
[Autumn Recruitment] [Updating ing] Hand Tear Code Series