当前位置:网站首页>redis学习五redis的持久化RDB,fork,copyonwrite,AOF,RDB&AOF混合使用
redis学习五redis的持久化RDB,fork,copyonwrite,AOF,RDB&AOF混合使用
2022-08-11 02:08:00 【lsd&xql】
redis学习五redis的持久化RDB,fork,copyonwrite,AOF,RDB&AOF混合使用
回顾
redis作为缓存:数据可以丢【追求的是急速】
redis作为数据库:数据绝对不能丢的
通常所说的redis+mysql -》是将redis作为数据库来用的,但是这样的话就需要保证redis
和mysql数据一致性的问题。【一般会加个消息队列来写】
从而引出redis自己的持久化操作。
RDB
RDB时点性
RDB相当于生成一个快照或者副本。
并且具有时点性的特性:
要说明时点性的问题的话redis数据从内存中持久化到磁盘中分为如下几种
情况:
1、redis阻塞去读取内存的数据到磁盘中,读取到磁盘数据的时间不对外提供
服务。
如果从八点持续读取到八点半,磁盘里面的数据是归属于八点的。
在实际生产中,如果采用上述方式导致服务不可用是个非常不好的方式:
所以引出如下方式:
本来要写b=4,还没写,然后修改b=6了,就把b=6写入到磁盘里面去了,在写入b=6的时候a右变成8了,然而这个时候a不会再写了,这个文件的时点就混乱了,磁盘里面有八点这个时间点的数据也有八点半这个时间点的数据
所以引入如下形式:
在说这个形式之前,引入一个管道的概念: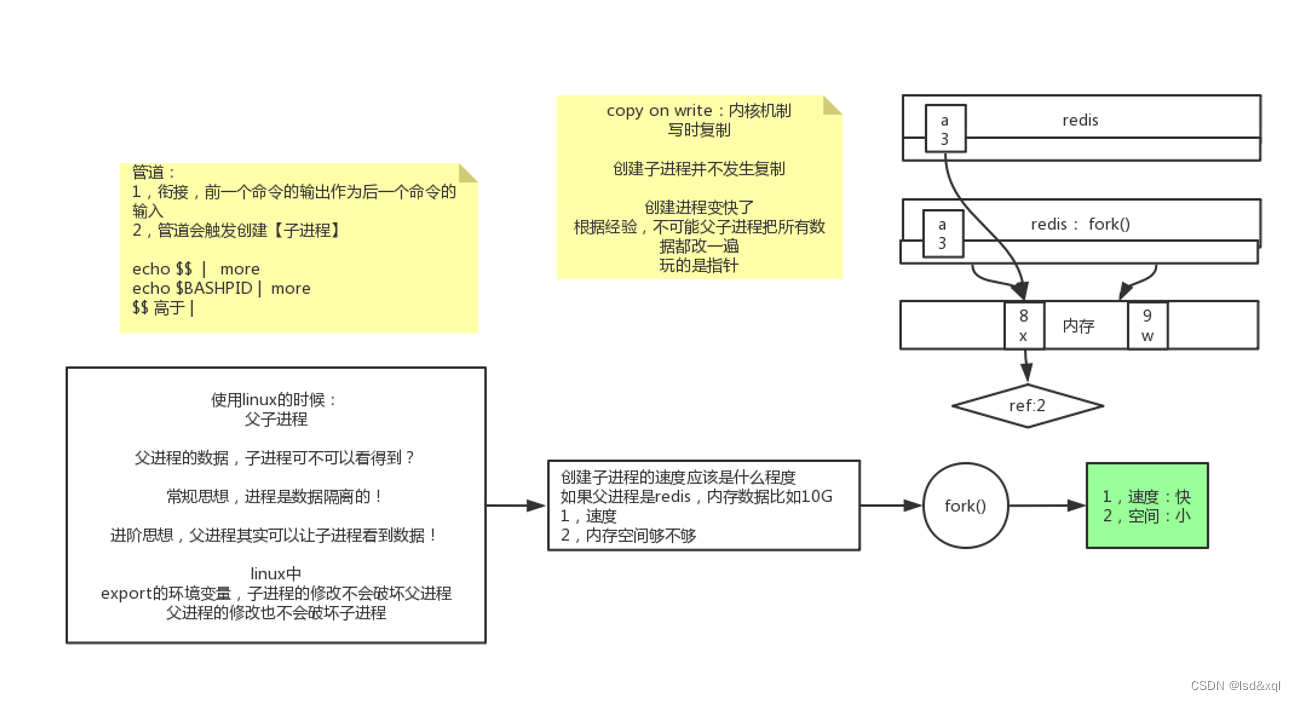
((num++)) | echo ok 执行此命令会在管道的左边创建一个子进程以及管道的右边创建一个子进程
$$的优先级高于 | 管道
从而引出使用linux的时候是有一个父子进程的概念的:
父进程的数据,子进程可不可以看到?
此时起了一个子进程,发现子进程是看不了父进程的数据的【常规思想是进程间的数据是隔离的】
此时再退回为父进程【是能够取到num的】
再用export 关键字修饰一下num【发现子进程也能访问父进程的数据了】
子进程修改是否影响父进程,然后看父进程修改是否影响子进程,写出如下脚本

然后执行脚本:并让他在后台执行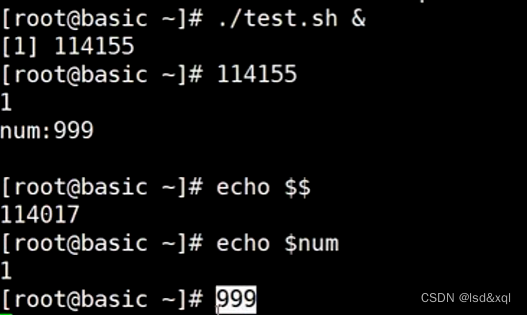
回到父进程发现父进程还是1,子进程的修改不会影响到父进程。
父进程的修改也不会影响子进程:
从而子进程是有父进程的一个副本,且修改互相不影响,如果父进程是redis,那么它的内存数据如果
有10个G,那么当他需要持久化数据的时候,那么就创建一个子进程,将数据导入到子进程里面去,
但是这样速度会慢并且内存空间也需要考虑【需要空余的空间多余10G】
所以linux有个系统调用fork(),这个的优点是速度相对比较快,且占用空间相对较少,这个fork如何实现
的呢?
计算机会有一个固定内存空间物理地址,想象成一个数组,redis会有一个虚拟地址空间,从而做一个虚拟地址
到物理地址的一个映射,假设redis有个a的key,对应的虚拟地址是3,指向了物理地址的8位置,redis
想取a的时候能把8对应的x取出来,如果redis想创建一个子进程【它也有一个虚拟地址】,通过fork
创建进程可以让两个进程同时指向一个物理空间,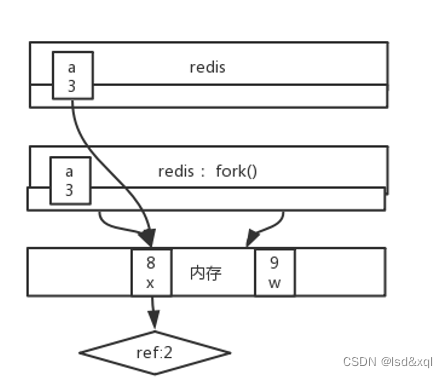
(copy on write)创建子进程的时候并不发生复制,只有父子进程任意一方想修改数据的时候才
定向的去复制数据,这样创建进程的速度变快了,同时子进程不可能把所有
数据都改一遍。
输入man 2 fork,可以看到关于fork的描述信息:
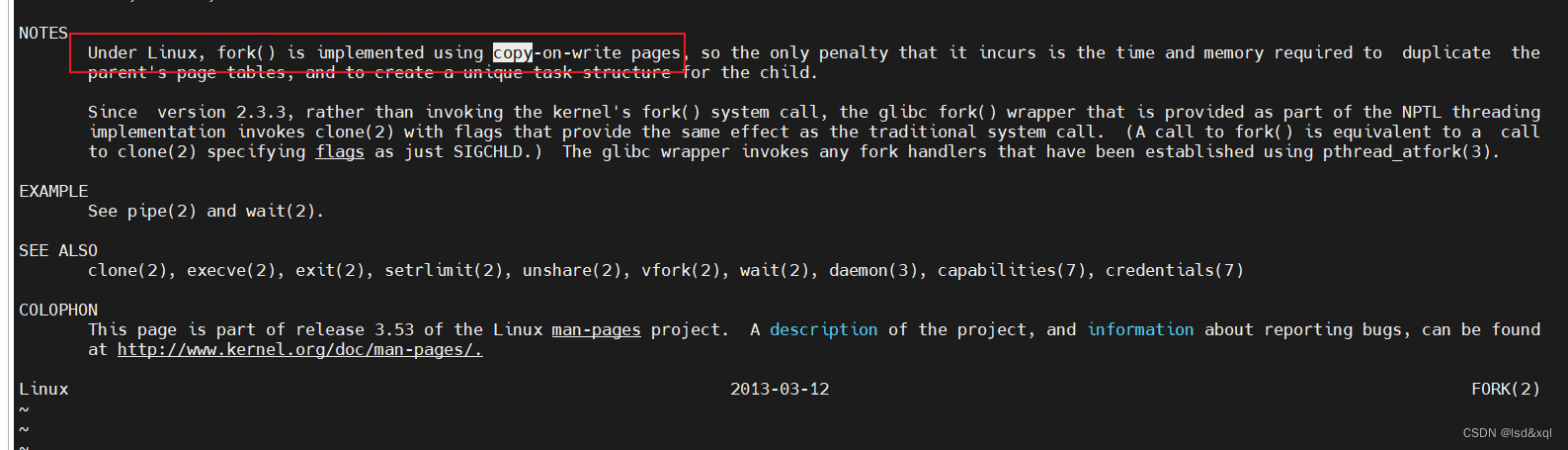
下面就来说redis中RDB的真正做法了:
redis通过fork的方式创建一个子进程,且数据没有真的拷贝出来,只是加了相应的指针指向,当父进程有某些
值改变了以后,会触发内核级别的一个写时复制,则在内存中对应物理地址中,让父进程中的那个key指向新
的地址,而子进程的那个key还是指向原来的那个物理地址
RDB配置方式
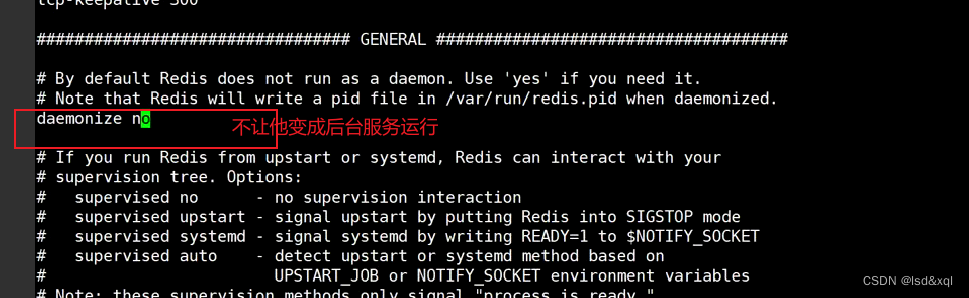
save方式:前台阻塞的方式去持久化【需要明确情况:比如,关机维护】
bgsave方式:后台异步非阻塞的方式去持久化(fork创建子进程)【要求不影响对外提供服务的时候】
配置文件中给出bgsave的规则:save这个标识、
进入redis的配置文件,可以看到如下配置信息:
第一个参数是时间,第二个参数是操作数,一般是操作数随时间增加而减少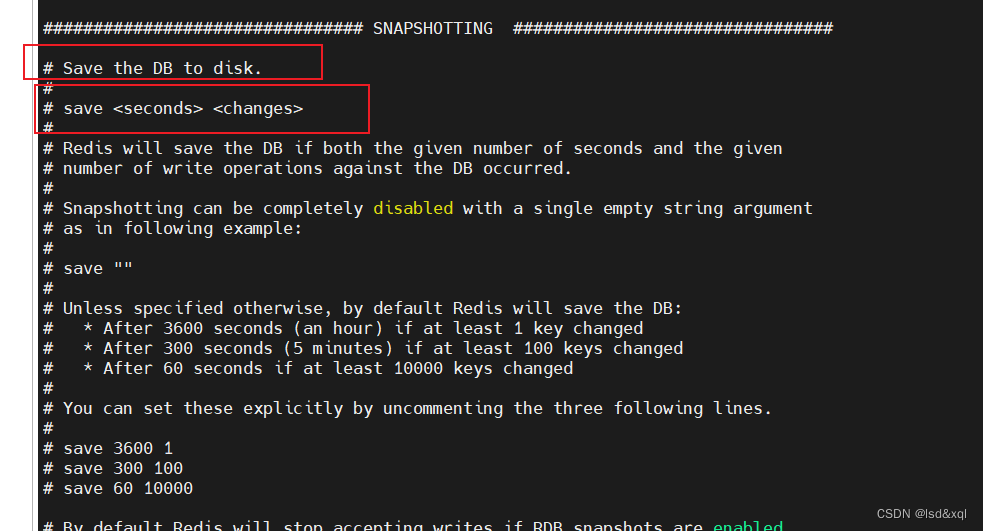
# save 3600 1
# save 300 100 //如果60s操作数没有到10000次,那么会等到300s的时候判断操作数是否有100次
# save 60 10000 //表示60s,操作数有10000次的时候执行bgsave持久化
save "" 这样写的话rdb功能会关闭
rbdchecksum是rdb的校验位,然后下面一个是配置的持久化到磁盘的文件名

RDB的优缺点
缺点:
1、不支持拉链,只有一个dump.rdb【需要运维去做维护】
2、丢失数据相对多一些,不是实时记录数据的变化,8点得到一个RDB文件,9点的时候刚要
做持久化的时候服务器挂机了
优点:
1、类似java中的序列化,恢复的速度相对快一些
AOF(Append Only File)
只会向文件里面追加,文件里面追加的是redis的写操作。
优势:
1、丢失数据少
2、RDB和AOF可以同时开启,如果开启了AOF,只会用AOF恢复【
在redis的4.0版本以后,AOF中包含了RDB的一个全量,并且增加增量记录新的
写操作】
弊端:
1、就是序列化慢
2、假设redis运行了10年,开启了AOF,首先这个AOF会非常大,其次恢复这个
数据也很慢,但是恢复不会造成内存溢出。【AOF的体量会无限变大,恢复慢】
如何设计出一个方案来让AOF足够小呢?
1、hdfs,fsimage+edits.log,让日志只记录增量,合并的过程
2、redis的4.0以前,重写,删除可以抵消的命令,合并重复的命令,最终是一个
纯指令的日志文件。
3、redis的4.0以后,将老的数据通过RDB的方式写到AOF文件中(二进制的字节),
将增量的以指令的方式Append到AOF,AOF是一个混合体,利用了RDB的快,也利用了日志
的全量【例如8点开始执行持久化,将8点前的数据RDB到硬盘文件中,其间增量的数据
通过AOF追加在文件中】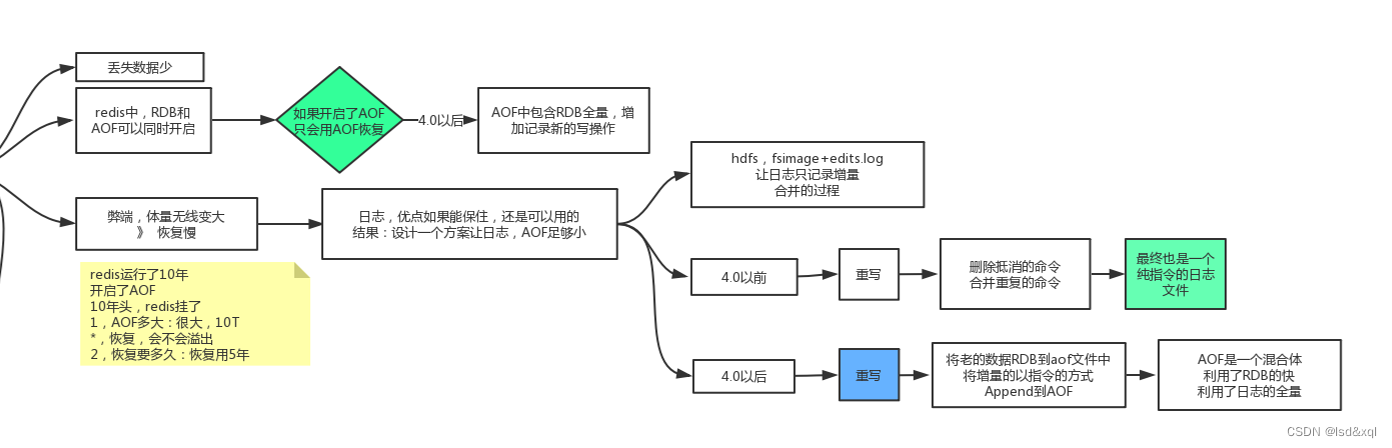
再回到redis作为内存数据库来使用,增删改写操作会触发IO行为,redis写IO会有
三种级别可以调整 appendsync always/no/everysec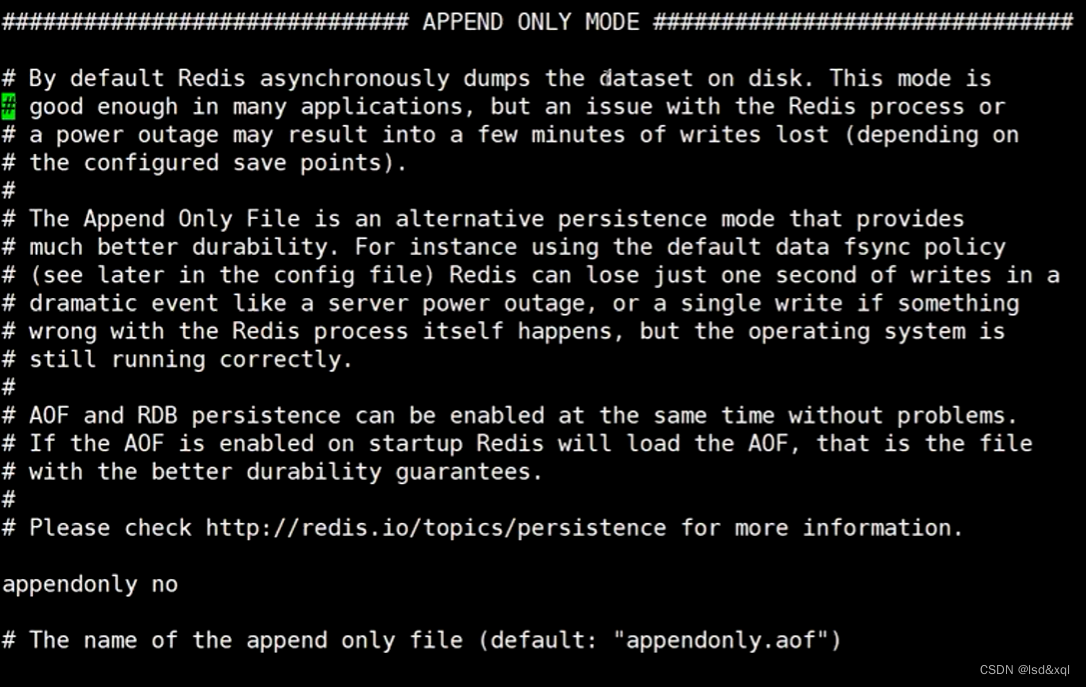
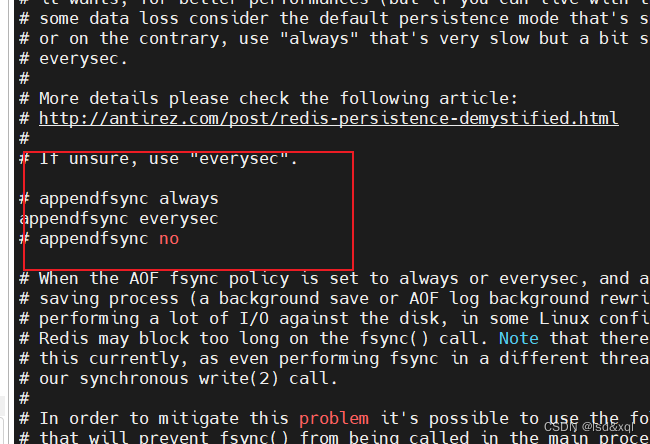
appendsync no :内核的buffer什么时候满了,再向磁盘里面刷数据,可能会丢一个buffer大
小的数据:这里就是把数据放在操作系统的buffer中,并没有落盘,如果数据刚好放满一个buffer,操作系统刚要把数据刷到磁盘,机器挂了,那么这一个buffer的数据也就丢失了
appendsync always:发生写的时候立马调用操作系统的内核去把操作系统中的buffer里的数据写入
到磁盘里面去,相对来说数据最可靠
appendsync everysec:每秒级别,每一秒调一次flush,可能会接近丢一个buffer的数据,这个
概率会比较小

redis抛出一个子进程,子进程在做RDB,那么父进程不会再去调刷新磁盘争抢
IO的操作。
当AOF 的appendfsync配置为 everysec 或 always ,并且后台运行着RDB的save或者AOF重写时,(由于save和rewrite会)消耗大量的磁盘性能。在某些Linux配置下,aof同步到磁盘执行 fsync() 将被阻塞很长时间。
注意:这个问题目前还没有解决办法。因为即使在不同的线程中执行fsync,也会阻塞同步 write() 调用。
为了减轻这个问题,可以使用 no-appendfsync-on-rewrite 选项防止执行BGSAVE或BGREWRITEAOF时,在主进程中调用fsync()。
这意味着当有另一个子进程执行BGSAVE或BGREWRITEAOF 时,磁盘同步策略相当于 appendfsync no。在最坏的情况下(使用默认的Linux设置)可能会丢失最多30秒的日志。
如果你有延迟问题可以将该项设置为“yes”。否则,从数据完整性的角度看,使用“no”更安全。

auto-aof-rewrite-percentage 100 # 触发重写百分比 (指定百分比为0,将禁用aof自动重写功能)
auto-aof-rewrite-min-size 64mb # 触发自动重写的最低文件体积(小于64mb不自动重写)
Redis能够在AOF文件大小增长了指定百分比时,自动隐式调用 BGREWRITEAOF 命令进行重写。
这里是它如何工作的说明:
Redis记录上一次执行AOF重写后的文件大小作为基准。(如果启动后没有发生过重写,则使用启动时的AOF文件大小)。
将该基准值与当前文件大小进行比较,如果当前体积超出基准值的指定百分比,将触发重写。
另外你还需要指定要重写的AOF文件的最小体积(auto-aof-rewrite-min-size),这可以避免在文件体积较小时多次重写。
如果指定百分比为0,将禁用AOF自动重写功能
实际演示

下面来说明一下AOF文件,*后面的数字代表后面是由几个元素组成 代表select 和 0 这两个
元素,代表是从redis 0 号库里面存,$描述这个元素是由几个字符或者字节组成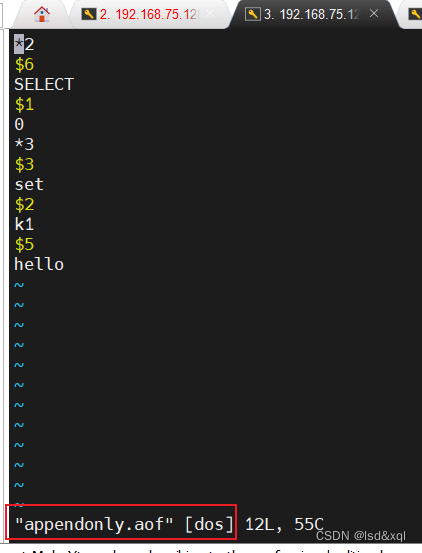
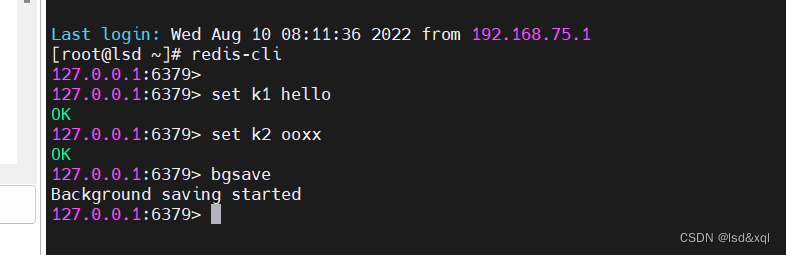
执行bgsave命令后会看到如下的日志打印
RDB对应的dump文件如下:是个二进制文件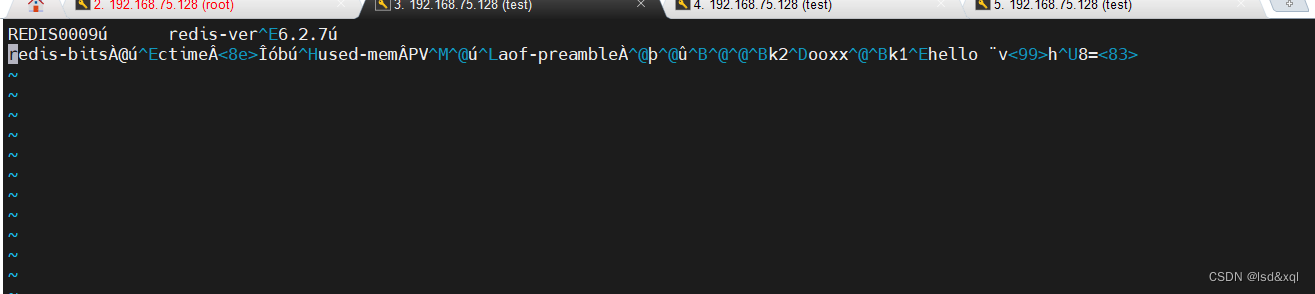
输入redis-check-rdb dump .rdb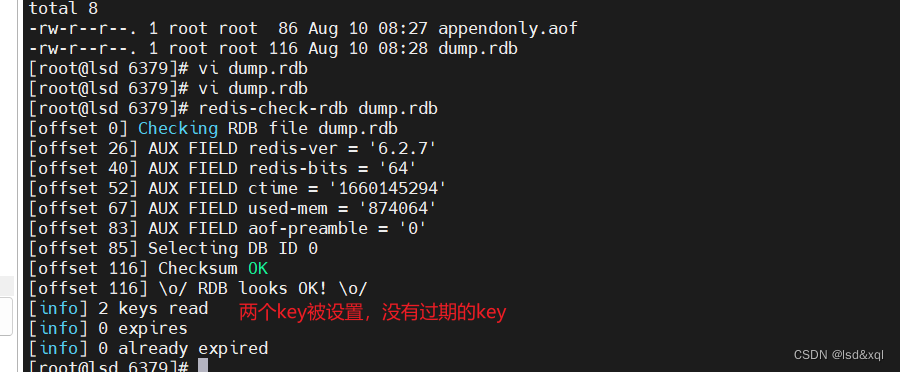
然后再来验证redis重写的功能:
把k1设置很多次
此时查看aof文件大小为170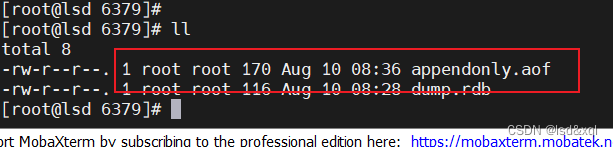
执行一个BGREWRITEAOF,发现aof文件的大小变成82个字节了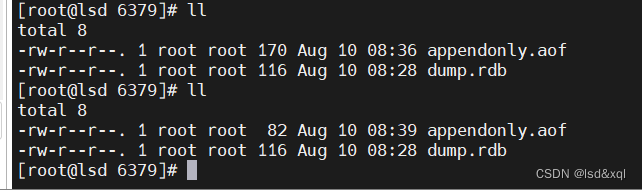
发现踢出掉了没意义的指令了
下面我们来看新版本的【4.0以后的】:
将此配置打开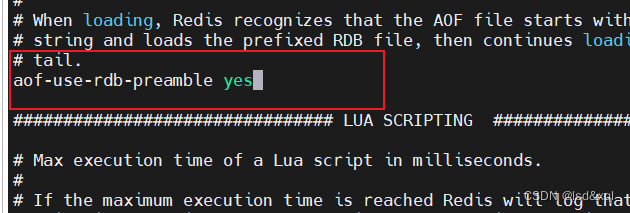
修改之后重启redis
会发现日志文件夹下面多了一个aof文件

此时的aof文件是没有rdb的内容的
此时再调用一个AOF的存储:
观察生成的aof文件:
此时就包含了rdb的内容了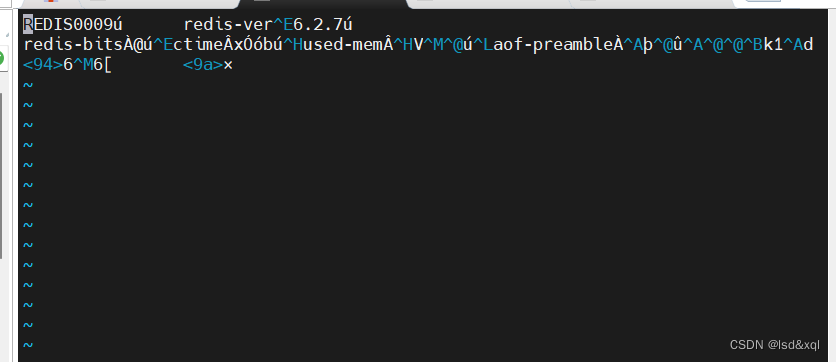
这种方式的话就没有浪费CPU计算前面调用的设置的其他的k1来判断了。
此时再设置k1的内容就是明文的方式去设置的:
此时同时执行
发现aof和rdb的文件大小及内容都是一样的

redis重启会自动加载rdb和aof的内容
边栏推荐
- 维特智能惯导配置
- GBJ3510-ASEMI家电电源用整流桥GBJ3510
- The classification of inter-process communication (IPC) and the development of communication methods
- OpenWrt之opkg详解
- ASEMI整流桥GBJ5010参数,GBJ5010电压,GBJ5010电流
- C# WebBrower1控件可编辑模式保存时会提示“该文档已被修改,是否保存修改结果”
- 思念家乡的月亮
- MySQL - 一条SQL在MySQL中是如何被执行的?
- 生信实验记录(part3)--scipy.spatial.distance_matrix
- leetcode 739. Daily Temperatures 每日温度(中等)
猜你喜欢

88Q2110 通过C22方式访问C45 phy地址
![Deep Learning [Chapter 2]](/img/09/5eb16731c3c47965da131c2aa0c2c3.png)
Deep Learning [Chapter 2]

MySQL - 一条SQL在MySQL中是如何被执行的?

Inter-process communication method (2) Named pipe
![MySQL Basics [Part 1] | Database Overview and Data Preparation, Common Commands, Viewing Table Structure Steps](/img/61/bebf5661ef1013e233e8d32c79f9ae.png)
MySQL Basics [Part 1] | Database Overview and Data Preparation, Common Commands, Viewing Table Structure Steps
OpenHarmony啃论文俱乐部-啃论文心得

Lianshengde W801 series 6-Analyze the Bluetooth communication source code of W801 from the perspective of WeChat applet (indicate method)
如何解决高度塌陷

项目构建工具-Gradle入门
![[The method of calling the child page from the parent page of the iframe] Stepping on the pit: It is the key to use `[x]` when getting elements. You cannot use `.eq(x)`, otherwise it will not be obtai](/img/ec/0cca8c7011770429c34a6aa1f36460.png)
[The method of calling the child page from the parent page of the iframe] Stepping on the pit: It is the key to use `[x]` when getting elements. You cannot use `.eq(x)`, otherwise it will not be obtai

随机推荐
js原型和原型链及原型继承
颠覆性创新招商,链动2+1是个怎么样的制度模式?
软件测试面试题:Web服务器指标指标?
【备战“金九银十”】2022年软件测试面试题最新汇总
Please talk about for...in and for...of in JS (below)
Mysq_Note4
【oops-framework】模板项目【oops-game-kit】使用简介
第二课第一周第4-6节 医学预后案例欣赏+作业解析
通过热透镜聚焦的高斯光束
Deep Learning【第二章】
leetcode 739. Daily Temperatures 每日温度(中等)
comp3331-9331-22t1-midterm复习辅导-tutorial week 5
sql 使用到where和groupby时到底怎么建立索引?
Ora - 00001 in violation of the only constraint
进程间通信方式(1)无名管道(全CSDN最用心的博主)
Lianshengde W801 series 6-Analyze the Bluetooth communication source code of W801 from the perspective of WeChat applet (indicate method)
软件测试面试题:在频繁的版本发布中,如何回归测试?
0图中等 LeetCode565. 数组嵌套
JVM类加载机制
【websocket】