当前位置:网站首页>最新BEV感知基线 | 你确定需要激光雷达?(卡内基梅隆大学)
最新BEV感知基线 | 你确定需要激光雷达?(卡内基梅隆大学)
2022-08-09 18:07:00 【3D视觉工坊】
点击上方“3D视觉工坊”,选择“星标”
干货第一时间送达

作者丨汽车人
来源丨 自动驾驶之心
1提出背景
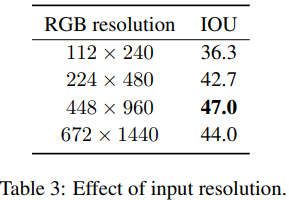
camera和其他传感器相比成本更低,而激光雷达系统的成本很高,因此为不依赖激光雷达构建三维感知系统是一个关键的研究问题。目前主流方法使用多个camera的多视图数据,并将透视图像中的特征“提升”到二维地平面,从而产生车辆周围三维空间的“鸟瞰视图”(BEV)特征表示。最近的研究重点是如何将特征从图像提升到BEV平面。相反,我们提出了一个简单的基线模型,其中“提升”步骤简单地平均了所有投影图像位置的特征,并发现它优于目前SOTA方案的BEV vehicle 分割。消融实验表明,bs_size、数据增强和输入分辨率在很大程度上影响性能。此外,论文重新考虑了radar输入的效用,最近的工作要么忽略了雷达输入,要么发现雷达输入没有帮助。通过一个简单的RGB-radar融合模块,获得了相当大的性能提升,接近支持激光雷达的系统的精度。
2BEV感知的一些方法
三维激光雷达相比于Radar和Camera,成本过于高昂。目前大多数工作的重点是仅使用多view camera数据输入,生成“鸟瞰视图”(BEV)语义表示。这种方法捕获了驾驶相关任务所需的信息,例如导航、障碍物检测和移动障碍物预测。
BEV车辆语义分割IoU在短短两年内从23.9提高到43.2!虽然令人鼓舞,但对创新和准确性的关注是以牺牲简单性为代价的,并且有可能掩盖对性能“真正重要的东西。之前的工作已经探索了使用同形图将特征直接扭曲到地平面,使用深度估计将特征放置在其近似的三维位置,使用具有各种几何偏差的MLP,以及最近使用几何感知变换器和跨空间和时间的可变形注意力。相反,论文提出了一个简单的基线模型,其中“提升”步骤是无参数的,不依赖深度估计:只需在BEV平面上定义一个三维坐标体,将这些坐标投影到所有图像中,并平均从投影位置采样的特征。令人惊讶的是,我们的简单基线超过了最先进模型的性能,同时速度更快,参数更少。
1.无参数无投影方法
该方法使用camera几何体定义体素与其投影坐标之间的映射,并通过在投影坐标处进行双线性采样来收集特征。这会将每个图像特征放置到多个三维坐标中,本质上是沿着光线在体积中的范围平铺特征。这种提升方法通常不用于鸟瞰语义任务。
2.基于深度的非投影方法
使用单目深度估计器估计每像素深度,并使用深度将特征放置在其估计的三维位置,这是一种有效的策略;
3.基于单应性的非投影方法
一些paper估计地平面而不是每个像素深度,并使用将图像与地面相关的单应性来将特征从一个平面转移到另一个平面。当场景本身是非平面的(例如,高大的对象分散在一个很宽的区域)时,此操作往往会产生较差的结果。
4.基于MLP的非投影方法
用MLP将图像特征的纵轴带转换为地平面特征的前轴带。
5.基于几何感知transformer模型方法
使用transformer新方法完成,可以参考BEVFormer新思路;
6.基于Radar方法
Radar测量提供位置、速度和角度方向,因此数据通常用于检测障碍物(例如紧急制动),并估计移动物体的速度。与激光雷达相比,雷达的射程更长,对天气影响的敏感性更低,而且价格也更低。然而雷达固有的稀疏性和噪声使得使用它成为一个挑战。一些早期方法使用雷达进行BEV语义分割任务,与我们的工作非常相似,但仅在小数据集中。
3模型结构
baseline结构如下图所示,传感器设置由多个摄像机和radar单元组成,首先用ResNet-101对每个camera图像进行特征化,然后定义了一组围绕ego载体的三维坐标,将这些坐标投影到所有图像中,并在投影位置对特征进行双线性采样,产生三维特征量。最后,concat光栅化radar图像,并降低体素的垂直维度,以生成BEV特征图。紧接着使用Resnet-18处理BEV映射特征,在任务头生成语义分割结果。
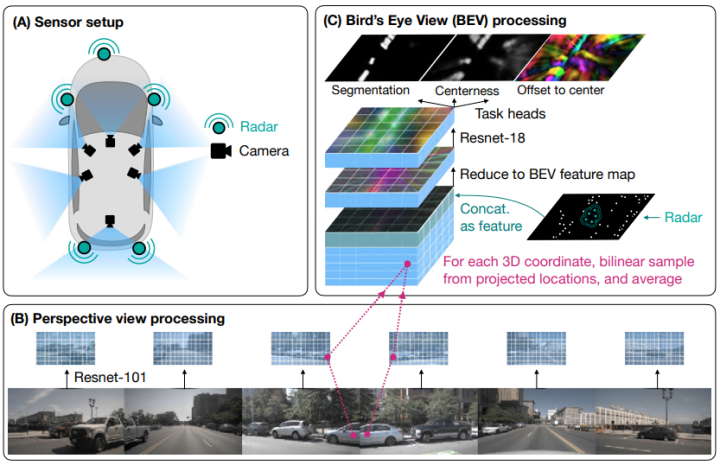
(1) 使用ResNet-101主干对每个输入RGB图像进行特征化,形状为3×H×W, 对最后一层的输出进行上采样,并将其与第三层输出连接起来,然后应用两个卷积层,并进行实例归一化和ReLU激活,得到形状为C×H/8×W/8(图像分辨率的八分之一)的特征图。
(2) 将预定义的三维坐标体积投影到所有特征图中,并在那里对特征进行双线性采样,每个camera会生成一个三维特征volume ,同时计算每个摄像机的二进制“有效”体积(三维坐标是否落在摄像机截锥体内)。
(3) 然后对整个volume集进行有效的加权平均,将我们的表示减少到单个三维特征体积,形状为C×Z×Y×X。重新排列三维特征体积维度,以便垂直维度扩展通道维度,如C×Z×Y×X→ (C·Y)×Z×X,得到高维BEV特征图。
(4) 将雷达信息光栅化,以创建另一个BEV特征图。可以使用任意数量的雷达通道R(包括R=0,表示没有雷达)。在nuScenes中,每个雷达回波总共由18个场组成,其中5个是位置和速度,其余的是内置预处理的结果(例如,表明返回有效的置信度)。论文使用所有这些数据,通过使用位置数据选择网格上最近的XZ位置(如果在边界内),并使用15个非位置项作为通道,生成形状为R×Z×X的BEV特征地图,R=15。如果提供了激光雷达,我们将其体素化为形状为Y×Z×X的二进制占用网格,并使用它代替radar特征(仅用于比较)。
(5) 最后将RGB特征和雷达特征连接起来,并通过应用3×3卷积核将扩展信道压缩到C维。这实现了减少(C·Y+R)×Z×X→ C×Z×X。此时,有一个单一的特征平面,表示场景的鸟瞰图。并使用Resnet-18的三个block来处理,生成三个特征映射,最后应用特定于任务的头:分割、中心度和偏移,分割头产生每个像素的车辆/背景分割。
4实验结果
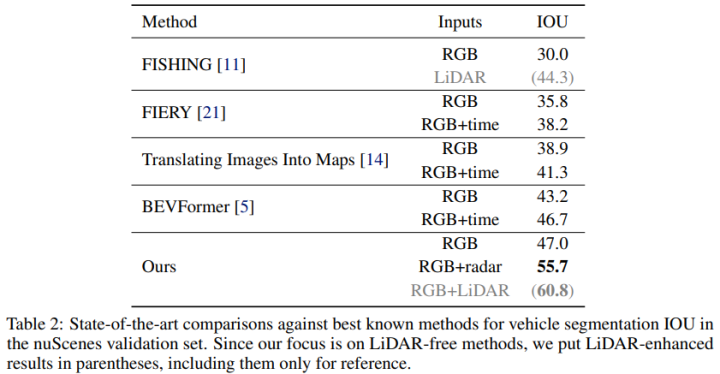
在纯RGB数据上和其它领域方法对比:

论文中RGB+Radar方法和其它领域反方法性能对比,引入Radar数据,直接提升了8.7%:
速度优势
在V100 GPU上以7.3 FPS的速度运行。这比BEVFormer快3倍多(以2.3 FPS的速度运行)。与BEVFormer的68.7M相比,论文的模型参数更少:47.2M。大多数参数(44.5M)来自Resnet-101,这也是由于RGB分辨率高(主要的速度瓶颈)。
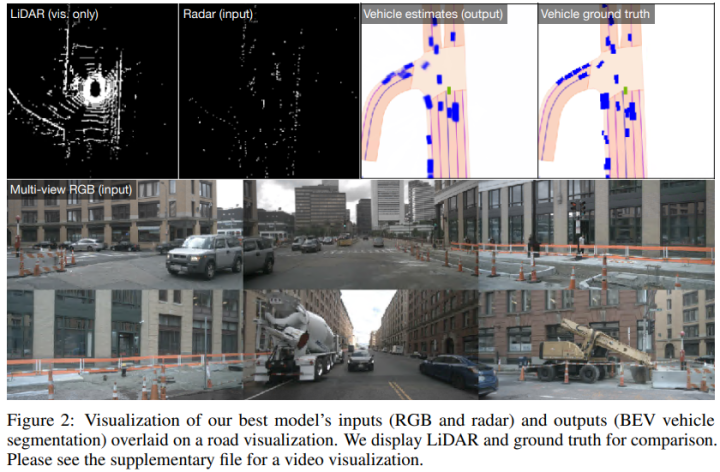
可视化
5论文参考
[1] A Simple Baseline for BEV Perception Without LiDAR.
本文仅做学术分享,如有侵权,请联系删文。
干货下载与学习
后台回复:巴塞罗那自治大学课件,即可下载国外大学沉淀数年3D Vison精品课件
后台回复:计算机视觉书籍,即可下载3D视觉领域经典书籍pdf
后台回复:3D视觉课程,即可学习3D视觉领域精品课程
3D视觉工坊精品课程官网:3dcver.com
2.面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
3.彻底搞透视觉三维重建:原理剖析、代码讲解、及优化改进
4.国内首个面向工业级实战的点云处理课程
5.激光-视觉-IMU-GPS融合SLAM算法梳理和代码讲解
6.彻底搞懂视觉-惯性SLAM:基于VINS-Fusion正式开课啦
7.彻底搞懂基于LOAM框架的3D激光SLAM: 源码剖析到算法优化
8.彻底剖析室内、室外激光SLAM关键算法原理、代码和实战(cartographer+LOAM +LIO-SAM)
重磅!3DCVer-学术论文写作投稿 交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、多传感器融合、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、学术交流、求职交流、ORB-SLAM系列源码交流、深度估计等微信群。
一定要备注:研究方向+学校/公司+昵称,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,可快速被通过且邀请进群。原创投稿也请联系。

▲长按加微信群或投稿
▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款
圈里有高质量教程资料、答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~
边栏推荐
猜你喜欢

每周给我10分钟,我给你一个Flink SQL 菜谱——甜点:数据过滤

鹅厂机器狗花式穿越10m梅花桩:前空翻、单桩跳、起身作揖...全程不打一个趔趄...
.NET现代应用的产品设计 - DDD实践

loadrunner script -- parameterization
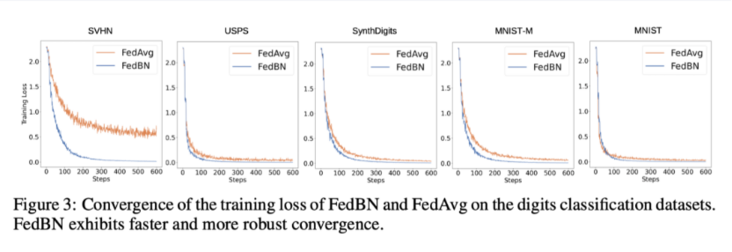
Paper sharing: "FED BN" uses the LOCAL BATCH NORMALIZATION method to solve the Non-iid problem

Samsung's flagship discount is 1,800, Apple's discount is over 1,000, and the domestic flagship is only reduced by 500 to send beggars
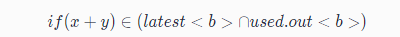
毕昇编译器优化:Lazy Code Motion
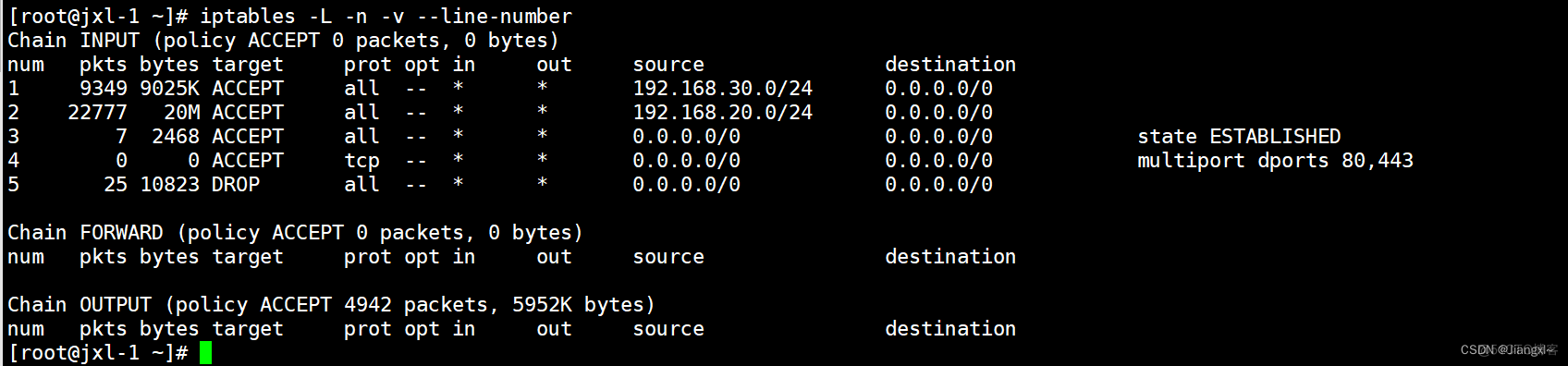
Iptables防火墙常见的典型应用场景

字节二面,差点倒在了MySQL上面
Open Source Summer | List Details Display Based on Ruoyi Architecture
随机推荐
图像处理部分详细目录
Unity webgl 关于适配网页 ,并且用到js中的SetTimeOut和SetInterval()
第三方bean使用ConfigurationProperties注解获取yml配置文件数据 & 获取yml配置文件数据的校验
PHP基础笔记-NO.4
Ng DevUI 周下载量突破1000啦!
太厉害了!华为大牛终于把 MySQL 讲的明明白白(基础 + 优化 + 架构)
[免费专栏] Android安全之GDB动态调试APP
Fully automated machine learning modeling!The effect hangs the primary alchemist!
Ros简介
对应运放 RC 滤波负反馈的波形
ThreadLocal 夺命 11 连问,万字长文深度解析
Sublime Text如何安装Package Control
Typora 结合 Picgo 自动上传图像
sublime快速打开终端terminal
WPF 实现带蒙版的 MessageBox 消息提示框
[免费专栏] Android安全之Android工程模式
论文分享:「FED BN」使用LOCAL BATCH NORMALIZATION方法解决Non-iid问题
Uniapp 应用未读角标插件 Ba-Shortcut-Badge
字节二面,差点倒在了MySQL上面
[免费专栏] Android安全之静态方式逆向APK应用浅析【手动注入smali+】+【IDA Pro静态分析so文件】+【IDA Pro基础使用讲解】