当前位置:网站首页>[target detection] small script: extract training set images and labels and update the index
[target detection] small script: extract training set images and labels and update the index
2022-08-10 13:21:00 【zstar-_】
问题场景
在做目标检测任务时,I would like to extract images of the training set for external data augmentation alone.因此,need to be divided according totrain.txtto extract training set images and labels.
需求实现
我使用VOC数据集进行测试,实现比较简单.
import shutil
if __name__ == '__main__':
img_src = r"D:\Dataset\VOC2007\images"
xml_src = r"D:\Dataset\VOC2007\Annotations"
img_out = "image_out/"
xml_out = "xml_out/"
txt_path = r"D:\Dataset\VOC2007\ImageSets\Segmentation\train.txt"
# 读取txt文件
with open(txt_path, 'r') as f:
line_list = f.readlines()
for line in line_list:
line_new = line.replace('\n', '') # 将换行符替换为空('')
shutil.copy(img_src + '/' + line_new + ".jpg", img_out)
shutil.copy(xml_src + '/' + line_new + ".xml", xml_out)
效果: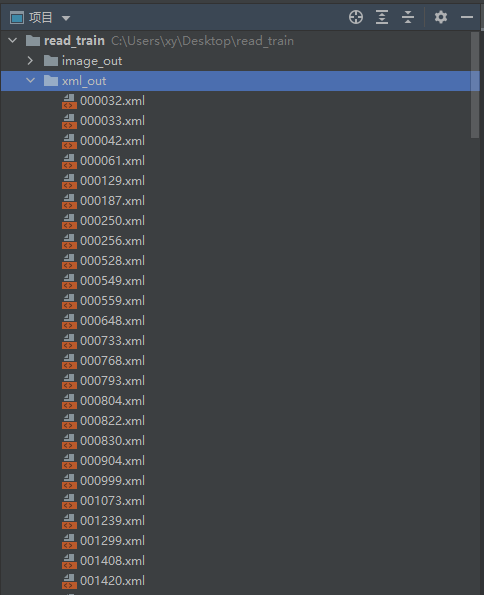
Update the training set index
使用数据增强之后,Throw the generated image and label thereVOC里面,混在一起.

Then write a script,Add the generated image name to train.txt文件中.
import os
if __name__ == '__main__':
xml_src = r"C:\Users\xy\Desktop\read_train\xml_out_af"
txt_path = r"D:\Dataset\VOC2007\ImageSets\Segmentation\train.txt"
for name in os.listdir(xml_src):
with open(txt_path, 'a') as f:
f.write(name[:-4] + "\n")
效果: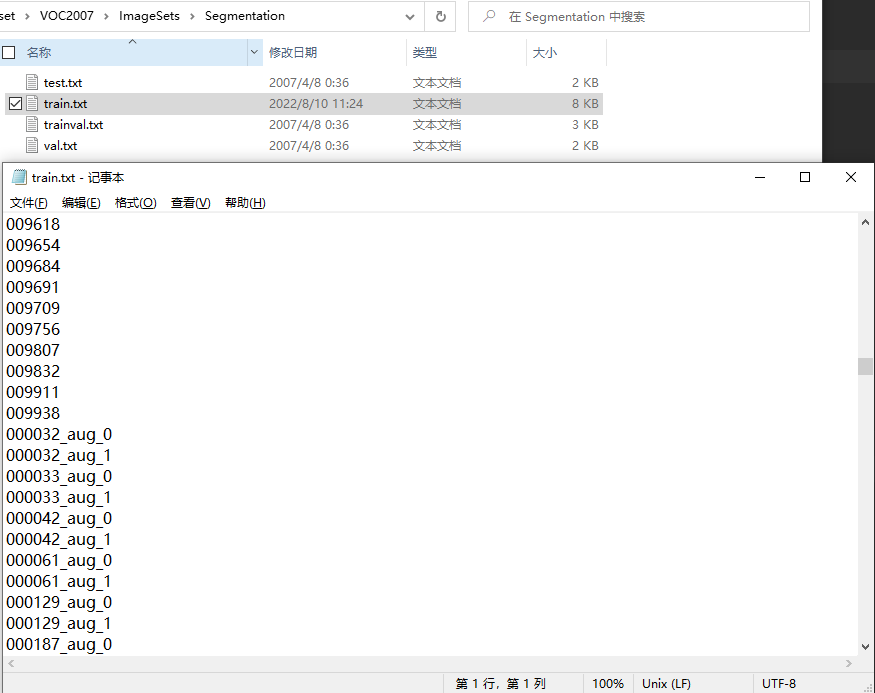
最后,before running againVOCWritten in the blog postxml2txt脚本:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
Imgpath = r'D:\Dataset\VOC2007\images' # 图片文件夹
xmlfilepath = r'D:\Dataset\VOC2007\Annotations' # xml文件存放地址
ImageSets_path = r'D:\Dataset\VOC2007\ImageSets\Segmentation'
Label_path = r'D:\Dataset\VOC2007'
classes = ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open(xmlfilepath + '/%s.xml' % (image_id))
out_file = open(Label_path + '/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
for image_set in sets:
if not os.path.exists(Label_path + 'labels/'):
os.makedirs(Label_path + 'labels/')
image_ids = open(ImageSets_path + '/%s.txt' % (image_set)).read().strip().split()
list_file = open(Label_path + '%s.txt' % (image_set), 'w')
for image_id in image_ids:
# print(image_id) # DJI_0013_00360
list_file.write(Imgpath + '/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
运行之后,You can see that the generated data augmentation samples are perfectly added to the original dataset.
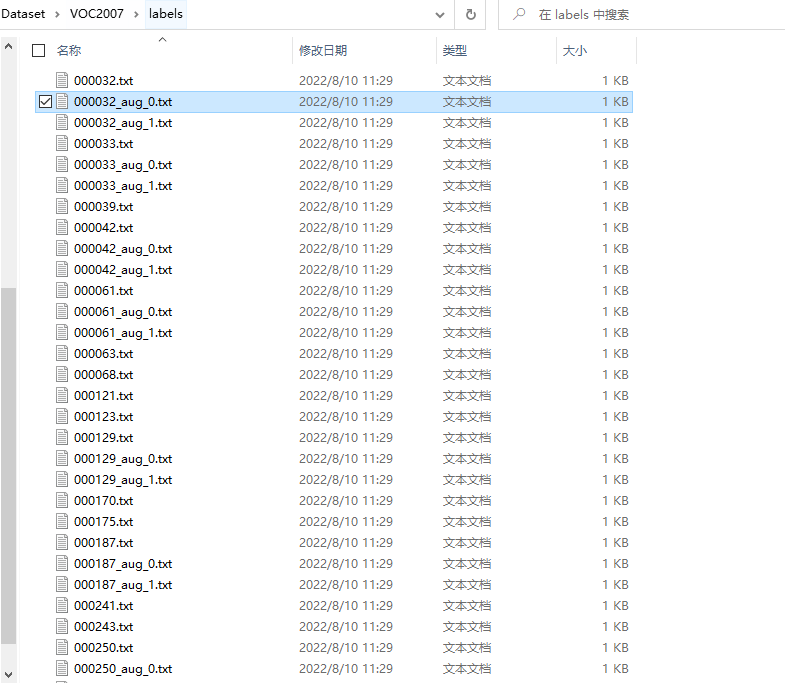
边栏推荐
- 生成树协议STP(Spanning Tree Protocol)
- bgp dual plane experiment routing strategy to control traffic
- mSystems | Zhongnong Wang Jie Group Reveals the Mechanisms Affecting Soil "Plastic Interstitial" Microbial Communities
- 表中存在多个索引问题? - 聚集索引,回表,覆盖索引
- Solution for "Certificate not valid for requested usage" after Digicert EV certificate signing
- 2022-08-09: What does the following go code output?A: No, it will panic; B: Yes, it can run correctly; C: Not sure, see the voting result.package main import (“fmt“ “syn
- LeetCode中等题之搜索二维矩阵
- Shell:数组
- 矩阵键盘&基于51(UcosII)计算器小项目
- Codeforces Round #276 (Div. 1) B. Maximum Value
猜你喜欢
kubernetes介绍
MySQL面试题整理
jenkins数据迁移和备份

Reversing words in a string in LeetCode

Detailed explanation of es6-promise object

跨域的五种解决方案
系统的安全和应用(不会点安全的东西你怎么睡得着?)
Code Casual Recording Notes_Dynamic Programming_70 Climbing Stairs

广东10个项目入选工信部2021年物联网示范项目名单

M²BEV: Multi-Camera Joint 3D Detection and Segmentation with Unified Bird’s-Eye View Representation
随机推荐
【iOS】Organization of interviews
BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection 论文笔记
3DS MAX batch export file script MAXScript with interface
Ethernet channel Ethernet channel
接口自动化测试基础篇
【百度统计】用户行为分析
BEVDet4D: Exploit Temporal Cues in Multi-camera 3D Object Detection Paper Notes
想问下大佬们 ,cdc oracle初始化一张300万的表任务运行着后面就这个错 怎么解决哇
友邦人寿可观测体系设计与落地
大佬们有遇到过这个问题吗? MySQL 2.2 和 2.3-SNAPSHOT 都这样,貌似是
Codeforces Round #276 (Div. 1) D. Kindergarten
中科院深圳先进技术院合成所赵国屏院士组2022年招聘启事
Interface Automation Testing Basics
娄底疾控中心实验室设计理念说明
Fragment-hide和show
2022年五大云虚拟化趋势
Jenkins修改端口号, jenkins容器修改默认端口号
没有接班人,格力只剩“明珠精选”
【黑马早报】雷军称低谷期曾想转行开酒吧;拜登正式签署芯片法案;软银二季度巨亏230亿美元;北京市消协约谈每日优鲜...
11+ chrome高级调试技巧,学会效率直接提升666%