当前位置:网站首页>网页分析和一些基础题目
网页分析和一些基础题目
2022-08-10 15:42:00 【华为云】
本次练习的是<有关网页分析和一些基础题目>,想要学习Python和巩固基础的可以现在打开来一起学习吧。
文章目录
题目一
题目要求
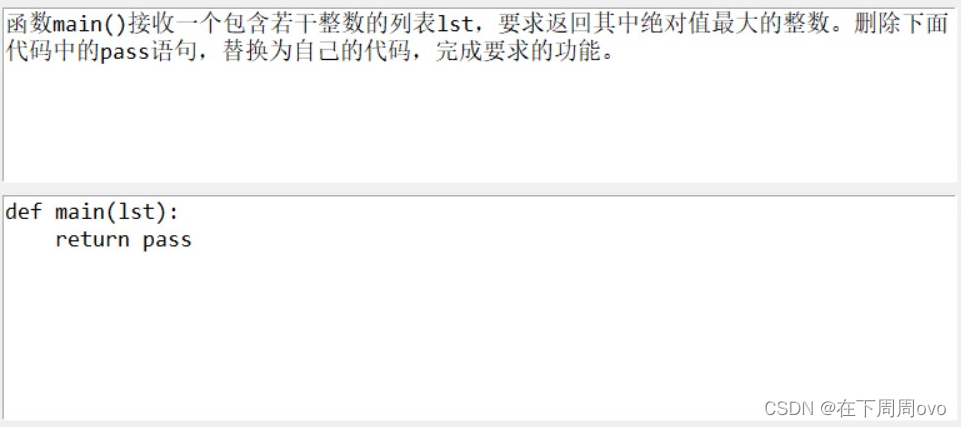
我的解析
本道题目难度较小主要考察了内置函数的基本使用方法
我的答案
def main(lst): return sorted(lst,key=abs)[len(lst) - 1]
题目二
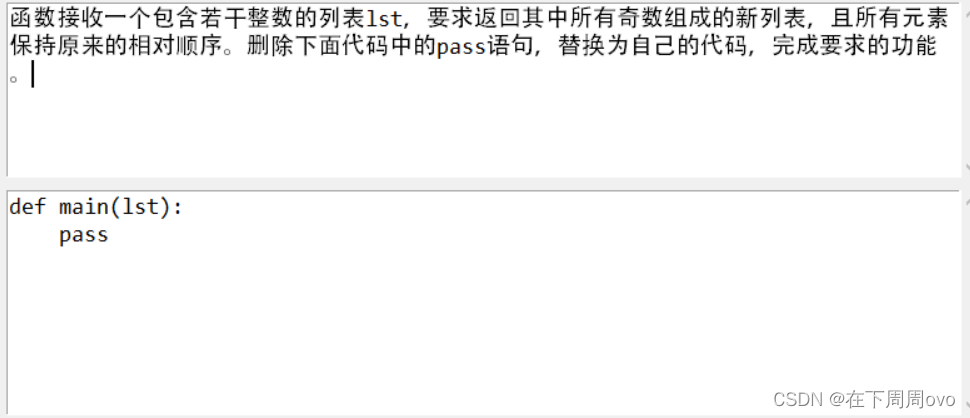
我的解析
本题难度较小,主要考察列表,匿名函数,列表推导式的基本使用方法。
我的答案
def main(lst): is_odd = lambda l : l % 2 == 1 #判断列表中元素是否为奇数的函数 return [i for i in filter(is_odd,lst)]#生成器中的列表推导式------>>】
------>> 【】
题目三
题目要求

我的解析
本题难度很小主要考察的是if-else语句和格式化输出
我的答案
print('What kind of drink would you like?')kind_of_drink = input()if kind_of_drink == 'cola': print('Below is your cola. Please check it!')else: print('The {} has been sold out!'.format(kind_of_drink))
题目四
写在前面
写本道题目之前需要掌握以下知识点哟,不清楚的可以翻看我之前的博客或者是网上查找相应的视频来回顾
- 知识点一urlib库的使用中请求对象的定制使用urllib来获取源码
- 知识点二re模块的基本使用方法
- 知识点三json模块的基本使用方法
- 知识点四正则匹配(用于对网页想要信息的提取和不想要信息的剔除)
- 知识点五文件的基本使用方法
题目要求
获取某瓣电影排名前十页电影的<"电影排名" "电影标题" "豆瓣评分"和"评论人数">并且将爬取下来的数据放到名为<豆瓣电影信息>的文件中

我的答案
import jsonimport reimport urllib.requestdef html_get(url): headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36' } request = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(request).read().decode('utf-8') return responsedef page_info(h): com = re.compile( '<div class="item">.*?<div class="pic">.*?<em .*?>(?P<电影排名>\d+).*?<span class="title">(?P<电影标题>.*?)</span>' '.*?<span class="rating_num" .*?>(?P<豆瓣评分>.*?)</span>.*?<span>(?P<评论人数>.*?)评价</span>', re.S) ret = com.finditer(h) for i in ret: yield { "电影排名": i.group("电影排名"), "电影标题": i.group("电影标题"), "豆瓣评分": i.group("豆瓣评分"), "评论人数": i.group("评论人数"), }def main(num): url = 'https://movie.douban.com/top250?start=%s&filter=' % num douban_html = html_get(url) res = page_info(douban_html) print(res) f=open("豆瓣电影信息","a",encoding="utf8") for obj in res: print(obj) data=json.dumps(obj,ensure_ascii=False) f.write(data+"\n") f.close()if __name__ == '__main__': count = 0 for page_num in range(10): main(count) count += 25输出结果:输出结果:
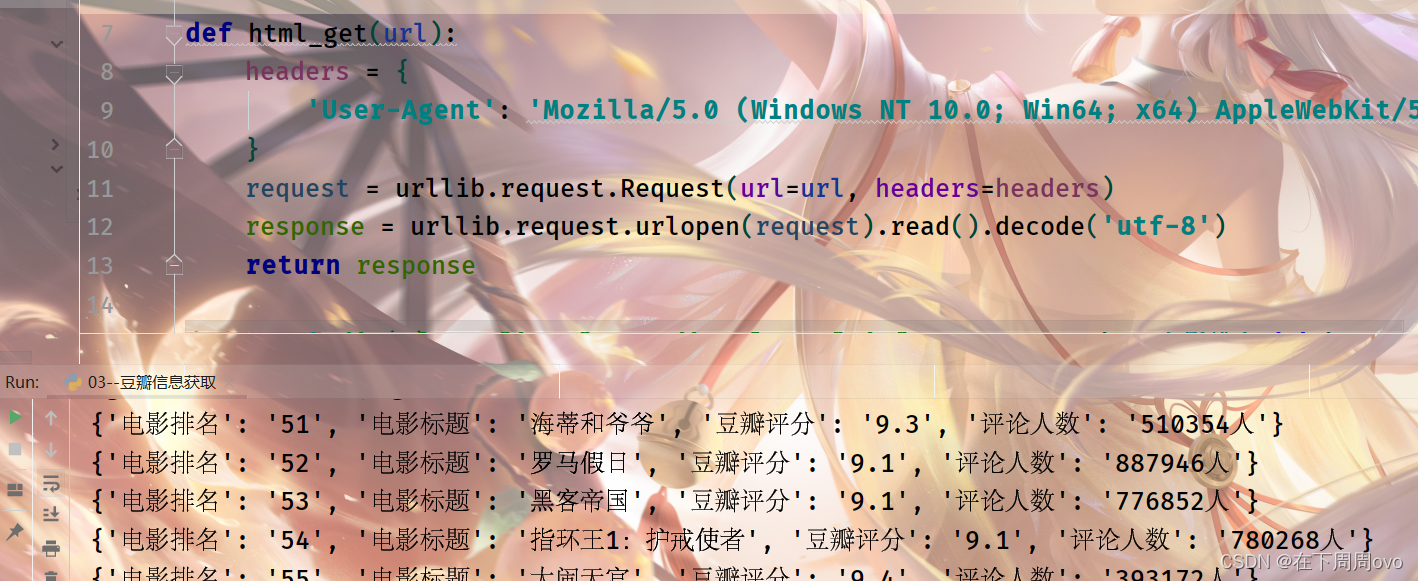
知识点:
flags有很多可选值:
- re.I(IGNORECASE)忽略大小写,括号内是完整的写法
- re.M(MULTILINE)多行模式,改变^和$的行为
- re.S(DOTALL)点可以匹配任意字符,包括换行符
- re.L(LOCALE)做本地化识别的匹配,表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境,不推荐使用
- re.U(UNICODE) 使用\w \W \s \S \d \D使用取决于unicode定义的字符属性。在python3中默认使用该flag
- re.X(VERBOSE)冗长模式,该模式下pattern字符串可以是多行的,忽略空白字符,并可以添加注释

我的解析:
html_get(url)函数:
- 作用:
获取豆瓣对应网址的网页源码
- 参数:
要获取信息的网址
- 返回值:
豆瓣对应网址的网页源码
page_info(h)函数
- 作用:
该函数的作用是匹配获取到的网页源码中的"电影排名" "电影标题" "豆瓣评分"和"评论人数"
- 参数:
对应网址的网页源码
- 返回值:
一个生成器函数
main(num)函数
- 作用:
顾名思义该函数是程序中的主函数,调用它获取对应页数的<"电影排名" "电影标题" "豆瓣评分"和"评论人数">并且将爬取下来的数据放到名为<豆瓣电影信息>的文件中
- 参数:
num = 0 则表示第一页,num = 25则表示第二页,num = 50则表示第三页,以此类推,因为每页有25部电影。
- 返回值:
将爬取下来的数据放到名为<豆瓣电影信息>的文件中
边栏推荐
- 【服务器数据恢复】raid5崩溃导致lvm信息和VXFS文件系统损坏的数据恢复案例
- fastposter v2.9.1 程序员必备海报生成器
- 商业版SSL证书
- Detailed understanding of anonymous functions and all built-in functions (Part 2)
- Spike project harvest
- Recommend a few had better use the MySQL open source client, collection!
- const-modified pointer variable (detailed)
- 面了个腾讯25k+出来的,他让我见识到什么基础的天花板
- MySQL command line export import database
- ExceptionInInitializerError
猜你喜欢


随机推荐
Taurus.MVC WebAPI 入门开发教程4:控制器方法及参数定义、获取及基础校验属性【Require】。
LeetCode-876. Middle of the Linked List
Spike project harvest
为什么中国的数字是四位一进,而西方的是三位一进?
Introduction to the functional logic of metaForce Fosage 2.0 system development
十年架构五年生活-09 五年之约如期而至
如何将静图变gif动图?教你jpg合成gif的方法
spark面试常问问题
C#去水印软件源代码
【芯片】人人皆可免费造芯?谷歌开源芯片计划已释放90nm、130nm和180nm工艺设计套件
FP6378AS5CTR SOT - 23-5 effective 1 mhz2a synchronous buck regulator
智为链接,慧享生活,荣耀智慧服务,只为 “懂” 你
Cesium Quick Start 4-Polylines primitive usage explanation
程序调试介绍及其使用
LeetCode-876. Middle of the Linked List
Chapter II Module Encyclopedia "collections Module"
匿名函数和全部内置函数详细认识(下篇)
不爱生活的段子手不是好设计师|ONES 人物
IPC:Interrupts and Signals
【每日一题】【leetcode】25. 数组-旋转数组的最小数字