当前位置:网站首页>秒杀项目收获
秒杀项目收获
2022-08-10 14:59:00 【威斯布鲁克.猩猩】
目录
项目架构设计
分层设计有什么好处:
1. 分层的设计可以简化系统设计,让不同的人专注做某一层次的事情;2. 分层之后可以做到很高的复用;3. 分层架构可以让我们更容易做横向扩展,比如说:业务逻辑里面包含有比较复杂的计算,导致 CPU 成为性能的瓶颈,那这样就可以把逻辑层单独抽取出来独立部署,然后只对逻辑层来做扩展,这相比于针对整体系统扩展所付出的代价就要小的多了
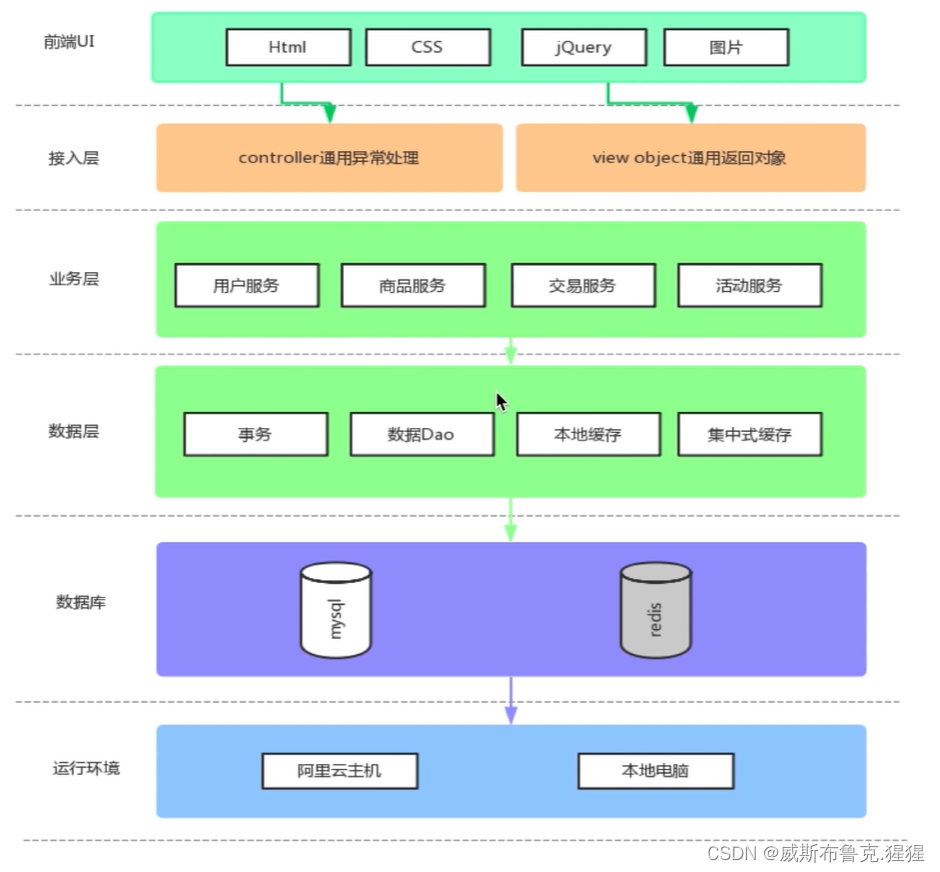
接入层使用了spring MVC的controller;
业务层使用了mybatis的接入以及数据层模型借助于mybatis的ORM方式操作数据库的能力模型
终端显示层:各端模板渲染并执行显示的层。当前主要是 Velocity 渲染,JS 渲染, JSP渲染,移动端展示等。Controller层:Controller层就是做一个请求转发,它接收来自客户端/外部页面传来的参数,传给Service层去做处理,然后收到Service层返回来的结果,再传给页面。简单理解就是:Controller——>Service——>Dao(Mapper)。
Service 层:业务逻辑层。大致就是通过对Dao层数据的各种封装利用,组成一个个服务,跟controller层交互。用来作为controller层与dao层之间沟通的桥梁。这里就涉及到了数据库的事务控制(增删改查)。至于Service接口里的方法全部声明,在Serviceimpl部分具体实现。dataobject:mybatis自动生成的;
dao层:mybatis自动生成的mapper文件
validator:数据校验
error:异常处理
pom.xml :公共依赖
config:全局配置
resources :测试需要用的资源库
数据层:事务@Transcantional注解的处理方式表示:处于一个事务当中,若一个事务中有任何一个步骤失败,事务就会回滚
数据接入层数据Dao:本地缓存、集中式缓存在商品详情页的应用,提高流式读取的效率
整个流程是:整个页面基于HTML、CSS,然后基于JavaScript的jQuery库发送了一个动态交互的请求,给接入层controller进行通用处理,然后我们基于SpringMVC的controller层会向业务层调用相应的服务,业务层会调用数据层的Dao,通过事务管理数据DaoMapper的方式将数据的增删改查落入到数据库中,最后到本地电脑中
数据模型(Data Object):借助于Mybatis的ORM操作将关系型数据库的表结构,通过XML的方式,定义成Java的Object结构
领域模型(Domain Model):具有一个对象的生命周期(创建、更新、删除、消亡),它可以和数据模型组合,比如用户对象是一个领域模型,它是由用户基本信息+用户密码信息两个数据模型共同组成的。
贫血模型:项目里的用户对象就设计成贫血模型:指的是拥有各种属性信息和get、set方法,但是不包含有登陆、注册等功能
ViewObject:与前端对接的模型,供展示的聚合模型
对应三层模型所得到的启示
最上层是商品的视图模型(前端页面的展示);中间层是商品对应的领域模型,用来做商品服务模型的聚合;下层是数据库模型,一个领域模型可能对应多个数据库模型,多个数据库模型取决于数据库的设计,然后聚合成一个领域模型,几个领域模型聚合为上层的秒杀商品的视图模型
异常处理
全局异常统一处理
通过拦截所有异常,对各种异常进行相应的处理,当遇到异常就逐层上抛,一直抛到最终由一个统一的、专门负责异常处理的地方处理,这有利于对异常的维护。
在BaseController中,使用 @ExceptionHandler(Exception.class)处理 controller 层抛出的 Exception定义 EmBusinessError 枚举统一管理错误码;包装器业务异常类实现:包装了 CommonError 即 EmBusinessError,解决了枚举不能 new 对象的问题MD5加密
登录部分使用了Java的MD5加密,既JDK自带的MessageDigest,由于单纯使用md5很容易被识破,对原串进行简单处理
public String EncodeByMd5(String str) throws NoSuchAlgorithmException,UnsupportedEncodingException { //确定计算方法 MessageDigest md5 = MessageDigest.getInstance("MD5"); BASE64Encoder base64en = new BASE64Encoder(); //加密字符串 String newstr = base64en.encode(md5.digest(str.getBytes("utf-8"))); return newstr; }
数据库设计
1. 为什么要将商品的库存表item_stock与商品表item分开?
库存操作非常耗时、性能,在商品交易过程中库存减,如果合并到item表中,每次会对对应行加行锁。如果分开库存表,虽然每次减库存过程还是会加行锁,但是可以将这张表拆到另一个数据库当中,分库分表,做效果的优化
数据库优化:查询请求增加时,如何做主从分离?
假设在双十一活动秒杀单件商品,无疑会引发查询量骤然增加的问题。当查询请求增加时,需要做主从分离来解决问题。主从读写分离
大部分系统的访问模型是读多写少,读写请求量的差距可能达到几个数量级。本系统也是这样。因此,优先考虑数据库如何抗住更高的查询请求,那么首先需要把读写流量区分开,因为这样才方便针对读流量做单独的扩展,这就是主从读写分离主从读写的两个技术关键点
一般在主从读写分离机制中,将一个数据库的数据拷贝为一份或者多份,并且写入到其它的数据库服务器中,原始的数据库称为主库,主要负责数据的写入,拷贝的目标数据库称为从库,主要负责支持数据查询。主从读写分离有两个技术上的关键点:1. 一个是数据的拷贝,我们称为主从复制;2. 在主从分离的情况下,如何屏蔽主从分离带来的访问数据库方式的变化,让开发同学像是在使用单一数据库一样。做了主从复制之后,就可以在写入时只写主库,在读数据时只读从库,这样即使写请求 会锁表或者锁记录,也不会影响到读请求的执行。同时,在读流量比较大的情况下,可以部署多个从库共同承担读流量,这就是“一主多从”部署方式。项目中就可以通过这种方式来抵御较高的并发读流量。另外,从库也可以当成一个备库来使用,以避免主库故障导致数据丢失。1.主从复制的缺点:
主从复制也有一些缺陷,除了带来了部署上的复杂度,还有就是会带来一定的主从同步的延迟,这种延迟有时候会对业务产生一定的影响。读写分离后,主从的延迟是一个关键的监控指标,可能会造成写入数据之后立刻读的时候读取不到的情况;例如:在发微博的过程中会有些同步的操作,像是更新数据库的操作,也有一些异步的操作,比如说将微博的信息同步给审核系统,所以我们在更新完主库之后,会将微博的 ID 写入消息队列,再由队列处理机依据 ID 在从库中获取微博信息再发送给审核系统。此时如果主从数据库存在延迟,会导致在从库中获取不到微博信息,整个流程会出现异常。本项目采用的解决主从复制缺点的方案:使用缓存
在同步写数据库的同时,也把微博的数据写入到redis缓存里面,这样队列处理机在获取微博信息的时候会优先查询缓存,(redis缓存优先于数据库查找)但是不可以保证数据的一致性缓存不能保证数据一致性的原因:在更新数据的场景下,先更新缓存可能会造成数据的不一致,比方说两个线程同时更新数据,线程 A 把缓存中的数据更新为 1,此时另一个线程 B 把缓存中的数据更新为 2,然后线程 B 又更新数据库中的数据为 2,此时线程 A 更新
数据库中的数据为 1,这样数据库中的值(1)和缓存中的值(2)就不一致了。本项目如何保证数据一致性(解决引入缓存后数据不一致):
引入rocketmq,利用rocketmq的事务消息最终解决数据的最终一致性
综上,本项目依靠主从复制的技术使得数据库实现了数据复制为多份,增强了抵抗大量并发读请求的能力,提升了数据库的查询性能的同时,也提升了数据的安全性,当某一个数据库节点,无论是主库还是从库发生故障时,我们还有其他的节点中存储着全量的数据,保证数据不会丢失。
缓存简介:
缓存:是一种存储数据的组件,它的作用是让对数据的请求更快地返回。实际上,凡是位于速度相差较大的两种硬件之间,用于协调两者数据传输速度差异的结构,均可称之为缓存。内存是最常见的一种缓存数据的介质。缓存可以提高低速设备的访问速度,或者减少复杂耗时的计算带来的性能问题。理论上说,我们可以通过缓存解决所有关于“慢”的问题,比如从磁盘随机读取数据慢,从数据库查询数据慢,只是不同的场景消耗的存储成本不同。缓冲区:缓冲区则是一块临时存储数据的区域,这些数据后面会被传输到其他设备上。缓存分类:
常见的缓存主要就是静态缓存、分布式缓存和热点本地缓存这三种。静态缓存:一般通过生成 Velocity 模板或者静态 HTML文件来实现静态缓存,在 Nginx 上部署静态缓存可以减少对于后台应用服务器的压力,这种缓存只能针对静态数据来缓存,对于动态请求就无能为力。分布式缓存:通过一些分布式的方案组成集群可以突破单机的限制;主要针对动态请求做缓存。热点本地缓存:当遇到极端的热点数据查询的时候。热点本地缓存主要部署在应用服务器的代码中,用于阻挡热点查询对于分布式缓存节点或者数据库的压力。比如某位明星在微博上有了热点话题,“吃瓜群众”会到他 (她) 的微博首页围观,这就会引发这个用户信息的热点查询。这些查询通常会命中某一个缓存节点或者某一个数据库分区,短时间内会形成极高的热点查询。缓存的不足:
首先,缓存比较适合于读多写少的业务场景,并且数据最好带有一定的热点属性,这是因为缓存毕竟会受限于存储介质不可能缓存所有数据,那么当数据有热点属性的时候才能保证一定的缓存命中率。比如说类似朋友圈这种 20% 的内容会占到 80% 的流量。所以,一旦当业务场景读少写多时或者没有明显热点时,比如在搜索的场景下,每个人搜索的词都会不同,没有明显的热点,那么这时缓存的作用就不明显了。其次,缓存会给整体系统带来复杂度,并且会有数据不一致的风险。当更新数据库成功,更新缓存失败的场景下,缓存中就会存在脏数据。对于这种场景,可以考虑使用较短的过期时间或者手动清理的方式来解决。总而言之,只要用了缓存就没办法完全解决脏读,只能尽可能的在更新后快速刷缓存 所以业务要能够容忍短暂的脏读。再次,之前提到缓存通常使用内存作为存储介质,但是内存并不是无限的。因此,在使用缓存的时候要做数据存储量级的评估,对于可预见的需要消耗极大存储成本的数据,要慎用缓存方案。同时,缓存一定要设置过期时间,这样可以保证缓存中的会是热点数据。最后,缓存会给运维也带来一定的成本,运维需要对缓存组件有一定的了解,在排查问题的时候也多了一个组件需要考虑在内。针对缓存重点应该关注的点:
1. 缓存可以有多层,比如上面提到的静态缓存处在负载均衡层,分布式缓存处在应用层和数据库层之间,本地缓存处在应用层。我们需要将请求尽量挡在上层,因为越往下层,对于并发的承受能力越差;2. 缓存命中率是我们对于缓存最重要的一个监控项,越是热点的数据,缓存的命中率就越高。3. 缓存不仅仅是一种组件的名字,更是一种设计思想,可以认为任何能够加速读请求的组件和设计方案都是缓存思想的体现。而这种加速通常是通过两种方式来实现:a. 使用更快的介质,比方说课程中提到的内存;b. 缓存复杂运算的结果,比方说前面 TLB 的例子就是缓存地址转换的结果;4. 当在实际工作中碰到“慢”的问题时,缓存就是第一时间需要考虑的。多级缓存:查询性能优化
本秒杀项目使用的是单机版的redis,但是弊端是redis容量问题,单点故障问题
redis没有办法提供事务的完全一致性 ,所以项目的设计是允许少卖但不允许超卖
项目中的缓存逻辑
现在取缓存的逻辑变成:本地缓存 ---> redis缓存 ---> 数据库
//商品详情页浏览 @RequestMapping(value = "/get",method = {RequestMethod.GET}) @ResponseBody public CommonReturnType getItem(@RequestParam(name = "id")Integer id){ ItemModel itemModel = null; //先取本地缓存 itemModel = (ItemModel) cacheService.getFromCommonCache("item_"+id); if(itemModel == null){ //根据商品的id到redis内获取 itemModel = (ItemModel) redisTemplate.opsForValue().get("item_"+id); //若redis内不存在对应的itemModel,则访问下游service if(itemModel == null){ itemModel = itemService.getItemById(id); //设置itemModel到redis内 redisTemplate.opsForValue().set("item_"+id,itemModel); redisTemplate.expire("item_"+id,10, TimeUnit.MINUTES); } //填充本地缓存 cacheService.setCommonCache("item_"+id,itemModel); } ItemVO itemVO = convertVOFromModel(itemModel); return CommonReturnType.create(itemVO); }redis没有办法提供事务的完全一致性 所以课程的设计是允许少卖但不允许超卖
redis的加减命令本身就可以保证原子性,多个并发操作更改数据不会出现错误
缓存库存:交易性能优化
交易性能瓶颈
- jmeter压测(对活动下单过程进行压测,采用post请求,设置传入参数,性能发现下单avarage大约2s,tps500,交易验证主要完全依赖数据库的操作)
- 交易验证完全依赖数据库
解决方案:库存行锁优化
回顾之前减库存的操作:
<update id="decreaseStock"> update item_stock set stock = stock - #{amount} where item_id = #{itemId} and stock >= #{amount} </update>库存的数量就是
stock-amount条件是商品itemId和stock的大小大于amount,条件是item_id要加上唯一索引,这样查询的时候为数据库加上行锁,否则是数据库表锁解决方案:异步同步数据库
采用异步消息队列的方式,将异步扣减的消息同步给消息的consumer端,并由消息的consunmer端完成数据库扣减的操作
(1)活动发布同步库存进缓存
(2)下单交易减缓存库存
(3)异步消息扣减数据库内存
异步消息队列rocketmq
具体的实现过程为:
- 如果秒杀商品库存尚有,则生成一条秒杀消息发送到消息队列中(信息中含有用户信息与商品id);
- 消息的消费者收到秒杀消息后,从数据库中读取用户是否已经完成秒杀,如果没有,则减库存,下订单,写入订单信息到数据库中。
常见的异步消息中间件用到的有ActiveMQ(实现java的AMS)、Kafka(基于流式处理)、RocketMQ是阿里巴巴基于Kafka改造的一种异步消息队列
为什么要使用RocketMQ?
答: 为了redis挂的时候不会丢数据
引入RocketMQ:一可以解决redis和数据库一致性的问题,二是减少库存行锁竞争,先执行creatOrder事务,再异步执行减库存,这样可以减少事务持锁时间减少行锁竞争;异步处理简化秒杀请求中的业务流程,提升系统的性能
其它问题:
1. 引入事务型消息RocketMQ是为了解决redis和数据库最终一致性的问题,但是还是会存在消息回滚,数据库扣减失败,redis和数据库不一致的问题,那么为什么要引入事务性消息呢?
防止redis挂了以后数据库有问题,redis挂了就系统不可用,因为无法确保数据库的数据和redis是同步的
2. 第一阶段中,redis减库存成功而下单db操作失败了,最终数据库的库存是不会减的,这时候redis和数据库库存不是不一致吗?如果不一致,那么和不使用事务消息的方案不是没有什么区别吗?
redis如果扣减成功了,下单失败会导致redis库存无法回滚,这种情况下业务是可以接受的,除非redis也使用事务型操作,否则没办法和下单请求共享事务;但是用了事务性能会降低,因此这里假定redis扣减成功后下单失败的概率近乎很小,因为所有的验证等操作都提前做完了,除非db挂了。
库存一致性问题
1. 库存redis和数据库异步,那产品展示中的库存数是用redis中的还是数据库中的?2. 目前redis和provider消息是符合一致性了,那如果消息consumer处理失败,依旧无法保证redis和数据库最终事务一致?关于展示问题,按照redis中取,取不出来再取数据库的,若数据库内数据更新,比如下单成功,则发送异步消息去清除redis数据,这样下次过来就可以走数据库拿到正确的数据了,当然也会有扣减库存没有清redis快,但业务上对库存还剩多少件展示层面没必要那么实时。consumer处理失败分为两种情况:
项目如何保证产生的消息一定会被消费到,并且只被消费一次?
问题引入:
在项目的学习过程中,这两个问题感觉挺重要:1. 如果producer消息发送成功,consumer端接收到了消息,然后往数据库里写的时候失败了,未写入,那么之前存入数据库的数据(如订单信息)怎么办,已经写入无法回滚了;2. 如果数据库操作成功了,但是返回的消费成功没有被mq接收到,那么重试就会导致数据库的数据被多扣减吗?怎么避免这种情况呢?
找到的解释:
1. 没写成功就不会返回消费成功,消息中间件自己会重试
2. 消费方要做幂等,课程中的stock_log表就是这么做的
下面是对此问题的深入探讨
要保证产生的消息一定会被消费到,并且只被消费一次,需要考虑两个方面:
1. 避免消息丢失
消息从被写入到消息队列,到被消费者消费完成,这个链路上主要三个地方存在丢失消息的可能:A. 消息从生产者写入到消息队列的过程针对这种情况,采用的方案是消息重传:也就是当发现发送超时后就将消息重新发一次,但是也不能无限制地重传消息。一般来说,如果不是消息队列发生故障,或者是到消息队列的网络断开了,重试 2~3 次就可以了。B. 消息在消息队列中的存储场景如果需要确保消息一条都不能丢失,建议不要开启消息队列的同步刷盘,而是使用集群的方式来解决,可以配置当所有 ISR Follower 都接收到消息才返回成功。如果对消息的丢失有一定的容忍度,建议不部署集群,本项目采用此方式。C. 消息被消费者消费的过程等到消息接收和处理完成后才能更新消费进度总结:为了避免消息丢失,我们需要付出两方面的代价:一方面是性能的损耗;一方面可能造成消息重复消费。2. 保证消息只被消费一次
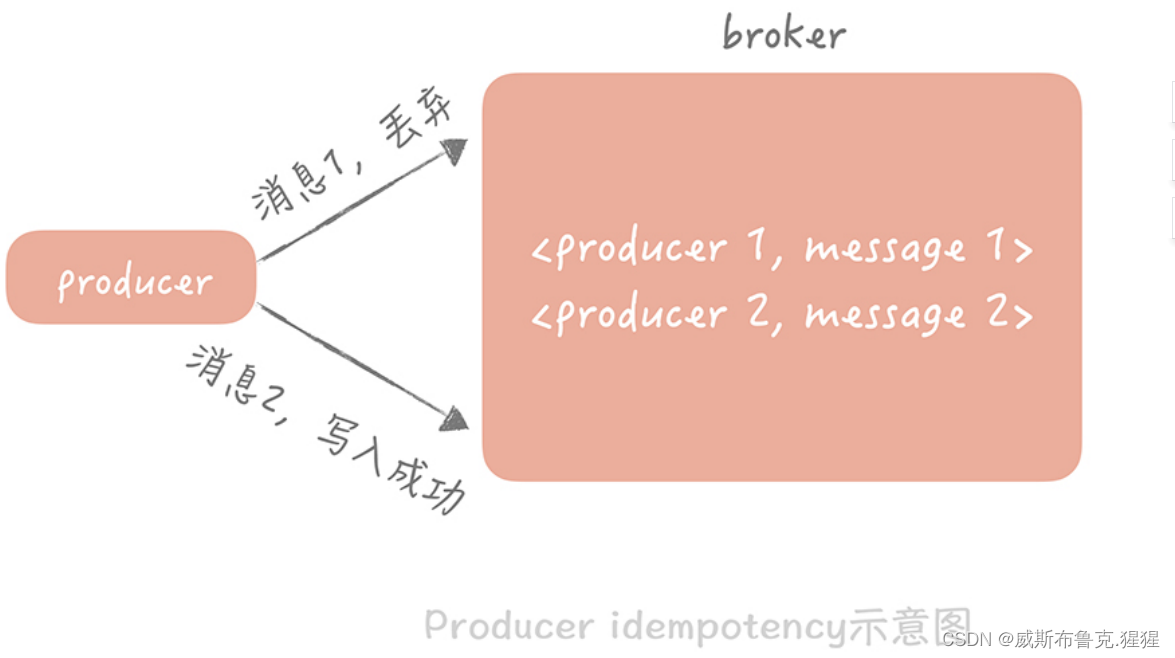
完全的避免消息重复的发生是很难做到的,因此我们会把要求放宽,保证即使消费到了重复的消息,从消费的最终结果来看和只消费一次是等同的就好了,也就是保证在消息的生产和消费的过程是“幂等”的。消息在生产和消费的过程中都可能会产生重复,所以,在生产过程和消费过程中增加消息幂等性的保证,这样就可以认为从“最终结果上来看”,消息实际上是只被消费了一次的。在消息生产过程中:保证消息虽然可能在生产端产生重复,但是最终在消息队列存储时只会存储一份。 具体做法是给每一个生产者一个唯一的 ID,并且为生产的每一条消息赋予一个唯一 ID,消息队列的服务端会存储 < 生产者 ID,最后一条消息 ID> 的映射。当某一个生产者产生新的消息时,消息队列服务端会比对消息 ID 是否与存储的最后一条 ID 一致,如果一致,就认为是重复的消息,服务端会自动丢弃。在消费端幂等性的保证会稍微复杂一些,可以从通用层和业务层两个层面来考虑:
在通用层面,你可以在消息被生产的时候,使用发号器给它生成一个全局唯一的消息 ID,消息被处理之后,把这个 ID 存储在数据库中,在处理下一条消息之前,先从数据库里面查询这个全局 ID 是否被消费过,如果被消费过就放弃消费。总结:可以看到,无论是生产端的幂等性保证方式,还是消费端通用的幂等性保证方式,它们的共同特点都是为每一个消息生成一个唯一的 ID,然后在使用这个消息的时候,先比对这个ID 是否已经存在,如果存在,则认为消息已经被使用过。所以这种方式是一种标准的实现 幂等的方式,在项目之中可以拿来直接使用。
不过这样会有一个问题:如果消息在处理之后,还没有来得及写入数据库,消费者宕机了重启之后发现数据库中并没有这条消息,还是会重复执行两次消费逻辑,这时就需要引入事务机制,保证消息处理和写入数据库必须同时成功或者同时失败,但是这样消息处理的成本就更高了,所以,如果对于消息重复没有特别严格的要求,可以直接使用这种通用的方案,而不考虑引入事务。在业务层面,这里有很多种处理方式,其中有一种是增加乐观锁的方式。比如, 消息处理程序需要给一个人的账号加钱,那么可以通过乐观锁的方式来解决。具体的操作方式是这样的:给每个人的账号数据中增加一个版本号的字段,在生产消息时先查询这个账户的版本号,并且将版本号连同消息一起发送给消息队列。消费端在拿到消息和版本号后,在执行更新账户金额 SQL 的时候带上版本号,类似于执行:update user set amount = amount + 20, version=version+1 where userId=1 and vers在更新数据时给数据加了乐观锁,这样在消费第一条消息时,version 值为 1,SQL可以执行成功,并且同时把 version 值改为了 2;在执行第二条相同的消息时,由于version 值不再是 1,所以这条 SQL 不能执行成功,也就保证了消息的幂等性。
秒杀时如何处理每秒上万次的下单请求(流量削峰)?
对于电商项目而言,当秒杀活动开始初期,更多的人可能只是在浏览秒杀商品都有哪些,有没有适合自己的或者需要的,真正参与秒杀活动的只是其中的一部分;此时,整体的流量比较小,而写流量可能只占整体流量的百分之一,那么即使整体的 QPS 到了 10000 次 / 秒,写请求也只是到了每秒 100 次,如果要对写请求做性能优化,它的性价比确实不太高。
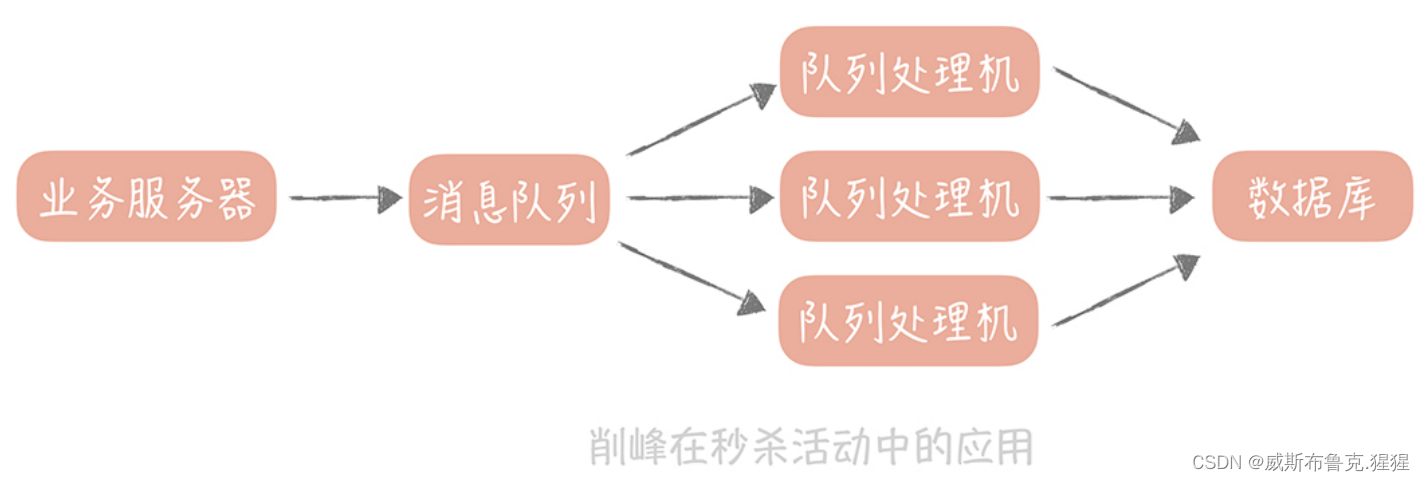
但是,当秒杀即将开始时,后台会显示用户正在疯狂地刷新 APP 或者浏览器来保证自己能够尽量早的看到商品。 这时,面对的依旧是读请求过高,那么应对的措施有哪些呢?因为用户查询的是少量的商品数据,属于查询的热点数据,可以采用缓存策略,将请求尽量挡在上层的缓存中,能被静态化的数据,比如说商城里的图片和视频数据,尽量做到静态化,这样就可以命中 CDN 节点缓存,减少 Web 服务器的查询量和带宽负担。Web 服务器比如 Nginx 可以直接访问分布式缓存节点,这样可以避免请求到达 Tomcat 等业务服务器。当然,可以加上一些限流的策略,比如,对于短时间之内来自某一个用户、某一个 IP 或者某一台设备的重复请求做丢弃处理。通过这几种方式,可以将请求尽量挡在数据库之外了。稍微缓解了读请求之后,00:00 分秒杀活动准时开始,用户瞬间向电商系统请求生成订单,扣减库存,用户的这些写操作都是不经过缓存直达数据库的。1 秒钟之内,有 1 万个数据库连接同时达到,系统的数据库濒临崩溃,寻找能够应对如此高并发的写请求方案迫在眉睫。这时就要用到消息队列。在秒杀场景下,短时间之内数据库的写流量会很高,依照以前的思路应该对数据分库分表。如果已经做了分库分表,那么就需要扩展更多的数据库来应对更高的写流量。但是无论是分库分表,还是扩充更多的数据库,都会比较复杂,原因是需要将数据库中的数据做迁移,这个时间就要按天甚至按周来计算了。而在秒杀场景下,高并发的写请求并不是持续的,也不是经常发生的,而只有在秒杀活动开始后的几秒或者十几秒时间内才会存在。为了应对这十几秒的瞬间写高峰,就要花费几天甚至几周的时间来扩容数据库,再在秒杀之后花费几天的时间来做缩容,这无疑是得不偿失的。本项目针对短时间的流量削减是这样处理的:将秒杀请求暂存在消息队列中,然后业务服务器会响应用户“秒杀结果正在计算中”,释放了系统资源之后再处理其它用户的请求。在后台启动若干个队列处理程序,消费消息队列中的消息,再执行校验库存、下单等逻辑。因为只有有限个队列处理线程在执行,所以落入后端数据库上的并发请求是有限的。而请求是可以在消息队列中被短暂地堆积,当库存被消耗完之后,消息队列中堆积的请求就可以被丢弃了。这就是消息队列在秒杀系统中最主要的作用:削峰填谷,也就是说它可以削平短暂的流量高峰,虽说堆积会造成请求被短暂延迟处理,但是只要时刻监控消息队列中的堆积长度,在堆积量超过一定量时,增加队列处理机数量,来提升消息的处理能力就好了,而且秒杀的用户对于短暂延迟知晓秒杀的结果,也是有一定容忍度的。这里需要注意一下,“短暂”延迟,如果长时间没有给用户公示秒杀结果,那么用户可能就会怀疑你的秒杀活动有猫腻了。所以,在使用消息队列应对流量峰值时,需要对队列处理的时间、前端写入流量的大小,数据库处理能力做好评估,然后根据不同的量级来决定部署多少台队列处理程序。比如秒杀商品有 1000 件,处理一次购买请求的时间是 500ms,那么总共就需要 500s的时间。这时,部署 10 个队列处理程序,那么秒杀请求的处理时间就是 50s,也就是说用户需要等待 50s 才可以看到秒杀的结果,这是可以接受的。这时会并发 10 个请求到达数据库,并不会对数据库造成很大的压力。本项目流量削峰的具体实现
由于基础的代码架构中:可能存在黄牛使用脚本恶意下单,秒杀下单接口会被脚本不停的刷;秒杀验证逻辑和秒杀下单接口强关联,代码冗余度高;秒杀下单和对活动是否开始是没有关联的,接口关联过高
所以实现以下优化:
秒杀令牌实现
- 秒杀接口需要依靠令牌才能进入
- 秒杀的令牌由秒杀活动模块负责生成
- 秒杀活动模块对秒杀令牌生成全权处理,逻辑收口
- 秒杀下单前需要先获得秒杀令牌
令牌限制的是秒下单的数量
PromoService接口上实现generateSecondKillToken秒杀令牌生成函数
//生成秒杀用的令牌 String generateSecondKillToken(Integer promoId,Integer itemId,Integer userId);PromoServiceImpl类
public String generateSecondKillToken(Integer promoId,Integer itemId,Integer userId) { PromoDO promoDO = promoDOMapper.selectByPrimaryKey(promoId); //promoDo(dataObject) -> PromoModel PromoModel promoModel = convertFromDataObject(promoDO); if(promoModel == null) { return null; } //判断当前时间是否秒杀活动即将开始或正在进行 DateTime now = new DateTime(); if(promoModel.getStartDate().isAfterNow()) { promoModel.setStatus(1); }else if(promoModel.getEndDate().isBeforeNow()) { promoModel.setStatus(3); }else { promoModel.setStatus(2); } //判断活动是否正在进行 if(promoModel.getStatus().intValue()!=2){ return null; } //判断item信息是否存在 ItemModel itemModel = itemService.getItemByIdInCache(itemId); if(itemModel == null) { return null; } //判断用户信息是否存在 UserModel userModel = userService.getUserByIdInCache(userId); if(userModel == null) { return null; } //生成token并且存入redis设置5分组有效期 String token = UUID.randomUUID().toString().replace("-",""); redisTemplate.opsForValue().set("promo_token_"+promoId+"_userid_"+userId+"_itemid_"+itemId,token); redisTemplate.expire("promo_token_"+promoId+"_userid_"+userId+"_itemid_"+itemId,5, TimeUnit.MINUTES); return token; }OrderController类
//生成秒杀令牌 @RequestMapping(value = "/generatetoken",method = {RequestMethod.POST},consumes={CONTENT_TYPE_FORMED}) @ResponseBody public CommonReturnType generatetoken(@RequestParam(name="itemId")Integer itemId, @RequestParam(name="promoId")Integer promoId) throws BusinessException { //根据token获取用户信息 String token = httpServletRequest.getParameterMap().get("token")[0]; if(StringUtils.isEmpty(token)){ throw new BusinessException(EmBusinessError.USER_NOT_LOGIN,"用户还未登陆,不能下单"); } //获取用户的登陆信息 UserModel userModel = (UserModel) redisTemplate.opsForValue().get(token); if(userModel == null){ throw new BusinessException(EmBusinessError.USER_NOT_LOGIN,"用户还未登陆,不能下单"); } //获取秒杀访问令牌 String promoToken = promoService.generateSecondKillToken(promoId,itemId,userModel.getId()); if(promoToken == null){ throw new BusinessException(EmBusinessError.PARAMETER_VALIDATION_ERROR,"生成令牌失败"); } //返回对应的结果 return CommonReturnType.create(promoToken); }但是此时还是有缺陷:秒杀令牌只要活动一开始就无限制生成,影响系统性能;下面继续解释解决此缺陷的方式。
秒杀大闸原理及实现
依靠秒杀令牌的授权原理定制化发牌逻辑,做大闸功能
根据秒杀商品初始化库存颁发对应数量令牌,控制大闸流量
用户风控策略前置到秒杀令牌发放中
库存售罄判断前置到秒杀令牌发放中
设置一个以秒杀商品初始库存x倍数量作为秒杀大闸,若超出这个数量,则无法发放秒杀令牌
//将大闸限制数字设置到redis内 redisTemplate.opsForValue().set("promo_door_count_"+promoId,itemModel.getStock().intValue()*5);此时还是有缺陷:秒杀活动开始,用户瞬间向电商系统请求生成订单, 用户的这些写操作都是不经过缓存直达数据库的。1 秒钟之内,有 1 万个数据库连接同时达到,系统的数据库濒临崩溃,这时就要用到消息队列;这也是最重要的一个点;即浪涌流量
队列泄洪原理
所谓的队列泄洪,就是新开一个线程池,来将不同的订单多线程执行,相当于使用了一个拥塞窗口来泄洪
- 排队有些时候比并发更高效(例如redis单线程模型,innodb mutex key等)
innodb在数据库操作时要加上行锁,mutex key是竞争锁,阿里sql优化了mutex key结构,当判断存在多个线程竞争锁时,会设置队列存放SQL语句
依靠排队去限制并发流量
依靠排队和下游拥塞窗口程度调整队列释放流量大小
支付宝银行网关队列举例
支付宝有多种支付渠道,在大促活动开始时,支付宝的网关有上亿级别的流量,银行的网关无法支持这种大流量,支付宝会将支付请求放到自己的队列中,根据银行网关可以承受的tps流量调整拥塞窗口,去泄洪
OrderController类
private ExecutorService executorService; @PostConstruct public void init(){ //定义一个只有20个可工作线程的线程池 executorService = Executors.newFixedThreadPool(20); } //同步调用线程池的submit方法 //拥塞窗口为20的等待队列,用来队列化泄洪 Future<Object> future = executorService.submit(new Callable<Object>() { @Override public Object call() throws Exception { //加入库存流水init状态 String stockLogId = itemService.initStockLog(itemId,amount); //再去完成对应的下单事务型消息机制 if(!mqProducer.transactionAsyncReduceStock(userModel.getId(),itemId,promoId,amount,stockLogId)){ throw new BusinessException(EmBusinessError.UNKNOWN_ERROR,"下单失败"); } return null; } }); try { future.get(); } catch (InterruptedException e) { throw new BusinessException(EmBusinessError.UNKNOWN_ERROR); } catch (ExecutionException e) { throw new BusinessException(EmBusinessError.UNKNOWN_ERROR); } return CommonReturnType.create(null); }关注点:
1. 拥塞窗口利用创建20大小的固定线程池通过传入callable对象并执行其call方法来提交线程的运行,并通过future对象来获取其执行的结果;这不就意味着包括核心线程数至少有20多个线程并发执行,那应该怎样理解线程安全问题呢,是redis的单线程模型还是数据库操作的行锁??
答: 线程池的多线程和运用spring mvc的多线程是一个概念;web应用本身就有个线程池该怎么加锁锁都可以
2. 如果请求量超出了队列承受范围,多出的这些请求怎么处理?
答: 如果系统都无法承载这些量,不拒绝处理系统就挂了;所以设计上秉承着宁可拒绝保证系统正常运行也不能让系统挂掉。
3. 用Future和队列有什么关系呀,future只是说等待线程池里面任务完成后就返回输出结果,然后又没有用BlockQuene?
答:首先:线程池中有一个等待队列,就是用blockqueue实现的,我们将任务提交给线程池,线程池中可执行线程沾满后会将任务放到等待队列中,这样做就等于是限制了用户并发的流量,使得其在线程池的等待队列中排队处理。然后future的使用是为了让前端用户在调用controller后可以同步的获得执行的结果; 用future只是为了获取线程池执行后的结果,和future队列无关,用的只是线程池的队列让所有执行排队而已
本地或分布式
- 本地:维护在内存当中,没有网络消耗,性能高,只要jvm不挂,那么应用服务器就是存活的
- 分布式:存在网络消耗的问题,redis将会成为系统瓶颈,当redis挂了,就全部凉凉。
比如说我们有100台机器,假设每台机器设置20个队列,那我们的拥塞窗口就是2000,但是由于负载均衡的关系,很难保证每台机器都能够平均收到对应的createOrder的请求,那如果将这2000个排队请求放入redis中,每次让redis去实现以及去获取对应拥塞窗口设置的大小,这种就是分布式队列
本地队列的好处就是完全维护在内存当中的,因此其对应的没有网络请求的消耗,只要JVM不挂,应用是存活的,那本地队列的功能就不会失效。因此企业级开发应用还是推荐使用本地队列,本地队列的性能以及高可用性对应的应用性和广泛性。可以使用外部的分布式集中队列,当外部集中队列不可用时或者请求时间超时,可以采用降级的策略,切回本地的内存队列;分布式队列+本地内存队列,企业级高可用队列泄洪方案
如何做到防刷限流
限流技术简介:
限流指的是通过限制到达系统的并发请求数量,保证系统能够正常响应部分用户请求,而对于超过限制的流量,通过拒绝服务的方式保证整体系统的可用性。限流策略一般部署在服务的入口层,比如 API 网关中,这样可以对系统整体流量做塑形。验证码技术
包装秒杀令牌前置,需要验证码来错峰
数学公式验证码生成器
// randomCode用于保存随机产生的验证码,以便用户登录后进行验证。 StringBuffer randomCode = new StringBuffer(); int red = 0, green = 0, blue = 0; // 随机产生codeCount数字的验证码。 for (int i = 0; i < codeCount; i++) { // 得到随机产生的验证码数字。 String code = String.valueOf(codeSequence[random.nextInt(36)]); // 产生随机的颜色分量来构造颜色值,这样输出的每位数字的颜色值都将不同。 red = random.nextInt(255); green = random.nextInt(255); blue = random.nextInt(255); // 用随机产生的颜色将验证码绘制到图像中。 gd.setColor(new Color(red, green, blue)); gd.drawString(code, (i + 1) * xx, codeY); // 将产生的四个随机数组合在一起。 randomCode.append(code); } Map<String,Object> map =new HashMap<String,Object>(); //存放验证码 map.put("code", randomCode); //存放生成的验证码BufferedImage对象 map.put("codePic", buffImg); return map; } public static void main(String[] args) throws Exception { //创建文件输出流对象 OutputStream out = new FileOutputStream("/Users/hzllb/Desktop/javaworkspace/miaoshaStable/"+System.currentTimeMillis()+".jpg"); Map<String,Object> map = CodeUtil.generateCodeAndPic(); ImageIO.write((RenderedImage) map.get("codePic"), "jpeg", out); System.out.println("验证码的值为:"+map.get("code")); }在OrderController中加入生成验证码
@RequestMapping(value = "/generateverifycode",method = {RequestMethod.POST,RequestMethod.GET}) @ResponseBody public void generateeverifycode(HttpServletResponse response) throws BusinessException, IOException { //根据token获取用户信息 String token = httpServletRequest.getParameterMap().get("token")[0]; if(StringUtils.isEmpty(token)){ throw new BusinessException(EmBusinessError.USER_NOT_LOGIN,"用户还未登陆,不能生成验证码"); } //获取用户的登陆信息 UserModel userModel = (UserModel) redisTemplate.opsForValue().get(token); if(userModel == null){ throw new BusinessException(EmBusinessError.USER_NOT_LOGIN,"用户还未登陆,不能生成验证码"); } Map<String,Object> map = CodeUtil.generateCodeAndPic(); ImageIO.write((RenderedImage) map.get("codePic"), "jpeg", response.getOutputStream()); redisTemplate.opsForValue().set("verify_code_"+userModel.getId(),map.get("code")); redisTemplate.expire("verify_code_"+userModel.getId(),10,TimeUnit.MINUTES); }生成秒杀令牌前验证验证码的有效性
//通过verifycode验证验证码的有效性 String redisVerifyCode = (String) redisTemplate.opsForValue().get("verify_code_"+userModel.getId()); if(StringUtils.isEmpty(redisVerifyCode)) { throw new BusinessException(EmBusinessError.PARAMETER_VALIDATION_ERROR,"请求非法"); } if(!redisVerifyCode.equalsIgnoreCase(redisVerifyCode)) { throw new BusinessException(EmBusinessError.PARAMETER_VALIDATION_ERROR,"请求非法,验证码错误"); }限流的目的
- 流量远比你想的要多
- 系统活着比挂了要好
- 宁愿只让少数人能用,也不要让所有人不能用
限流方案(限并发)
对同一时间固定访问接口的线程数做限制,利用全局计数器,在下单接口OrderController处加一个全局计数器,并支持并发操作,当controller在入口的时候,计数器减1,判断计数器是否大于0,在出口时计数器加一,就可以控制同一时间访问的固定。
限流范围
集群限流:依赖redis或其他的中间件技术做统一计数器,往往会产生性能瓶颈
单击限流:负载均衡的前提下单机平均限流效果更好
令牌桶算法(项目使用)
如果我们需要在一秒内限制访问次数为 N 次,那么就每隔 1/N 的时间,往桶内放入一个令牌;在处理请求之前先要从桶中获得一个令牌,如果桶中已经没有了令牌,那么就需要等待新的令牌或者直接拒绝服务;桶中的令牌总数也要有一个限制,如果超过了限制就不能向桶中再增加新的令牌了。这样可以限制令牌的总数,一定程度上可以避免瞬时流量高峰的问题。
使用令牌桶算法就需要存储令牌的数量,如果是单机上实现限流的话,可以在进程中使用一个变量来存储;但是如果在分布式环境下,不同的机器之间无法共享进程中的变量,一般会使用 Redis 来存储这个令牌的数量。这样的话,每次请求的时候都需要请求一次 Redis 来获取一个令牌,会增加几毫秒的延迟,性能上会有一些损耗。因此,一个折中的思路是: 可以在每次取令牌的时候,不再只获取一个令牌,而是获取一批令牌,这样可以尽量减少请求 Redis的次数。限流策略很难在实际中确认限流的阈值是多少,设置的小了容易误伤正常的请求,设置的大了则达不到限流的目的。所以,一般在实际项目中,会把阈值放置在配置中心中方便动态调整;同时,我们可以通过定期地压力测试得到整体系统以及每个微服务的实际承载能力,然后再依据这个压测出来的值设置合适的阈值。其它限流算法(了解)
1. 基于时间窗口维度的算法有固定窗口算法和滑动窗口算法,两者虽然能一定程度上实现限流的目的,但是都无法让流量变得更平滑;2. 令牌桶算法和漏桶算法则能够塑形流量,让流量更加平滑,但是令牌桶算法能够应对一定的突发流量,不能超过限定值;所以在实际项目中应用更多。限流代码实现(Guava RateLimit)
RateLimiter没有实现令牌桶内定时器的功能,
reserve方法是当前秒的令牌数,如果当前秒内还有令牌就直接返回;
若没有令牌,需要计算下一秒是否有对应的令牌,有一个下一秒计算的提前量
使得下一秒请求过来的时候,仍然不需要重复计算
RateLimiter的设计思想比较超前,没有依赖于人为定时器的方式,而是将整个时间轴
归一化到一个数组内,看对应的这一秒如果不够了,预支下一秒的令牌数,并且让当前的线程睡眠;如果当前线程睡眠成功,下一秒唤醒的时候令牌也会扣掉,程序也实现了限流private RateLimiter orderCreateRateLimiter; @PostConstruct public void init(){ executorService = Executors.newFixedThreadPool(30); orderCreateRateLimiter = RateLimiter.create(300); }防刷技术
- 排队,限流,令牌均只能控制总流量,无法控制黄牛流量
传统防刷
- 限制一个会话(session_id,token)同一秒/分钟接口调用多少次:多会话接入绕开无效(黄牛开多个会话)
- 限制一个ip同一秒钟/分钟 接口调用多少次:数量不好控制,容易误伤,黑客仿制ip
黄牛为什么难防
- 模拟器作弊:模拟硬件设备,可修改设备信息
- 设备牧场作弊:工作室里一批移动设备
- 人工作弊:靠佣金吸引兼职人员刷单
设备指纹
- 采集终端设备各项参数,启动应用时生成唯一设备指纹
- 根据对应设备指纹的参数猜测出模拟器等可疑设备概率
凭证系统
- 根据设备指纹下发凭证
- 关键业务链路上带上凭证并由业务系统到凭证服务器上验证
- 凭证服务器根据对应凭证所等价的设备指纹参数并根据实时行为风控系统判定对应凭证的可疑度分数
- 若分数低于某个数值则由业务系统返回固定错误码,拉起前端验证码验身,验身成功后加入凭证服务器对应分数
支付宝的闲鱼就用到了 这个防止数据采集的防刷策略
用手机正常访问闲鱼,大概半个小时,就会让我休息会,给我个验证码让我 划一下,我当时还纳闷呢,原来是为了防止数据被采集,长时间访问数据,就会进行一个可疑身份的校验
限流与队列泄洪(流量削峰)的再理解:
假设一台机器的极限tps是400,那我们限流到300tps,如果这300tps全部是去请求createOrder这个方法,那么这个时候我们如果不用队列泄洪,那么在这1秒内需要处理300个请求,便是有300个线程,导致cpu将会在这个300线程中来回切换,使cpu的消耗加大,所以为了更好的处理300个线程,减小cpu的切换时间开销,减小cpu处理者300个请求的时间,所以我们引入队列泄洪,减少cpu在线程间切换的时间,从而提高相应速度。
最后呢,我觉得,我们如果不使用队列泄洪,其实系统应该也可以解决,但是响应时间会增加。但是我们如果只使用队列泄洪,就只考虑createOrder这个接口应该也是可以解决的,但是有可能,会导致这个order类的tps过大,导致系统处理不过来。
所以,限流应该和队列泄洪是相辅相成的,只用限流可以解决流量过大的问题,但是可能会导致并发量过大,增加cpu的处理时间,所以引入队列泄洪来减少cpu处理300个请求的时间。
边栏推荐
猜你喜欢
metaForce佛萨奇2.0系统开发功能逻辑介绍
fastposter v2.9.1 程序员必备海报生成器

社区动态——恭喜海豚调度中国区用户组新晋 9 枚“社群管理员”

产品使用说明书小程序开发制作说明
E. Cross Swapping(并查集变形/好题)

Analysys and the Alliance of Small and Medium Banks jointly released the Hainan Digital Economy Index, so stay tuned!
Meaning and names of 12 nautical miles, 24 nautical miles and 200 nautical miles

程序调试介绍及其使用
使用Uiautomator2进行APP自动化测试
Redis -- Nosql
随机推荐
容器化 | 在 S3 实现定时备份
antd组件中a-modal设置固定高度,内容滚动显示
High-paid programmers & interview questions series 135 How do you understand distributed?Do you know CAP theory?
const-modified pointer variable (detailed)
丁香园
PCL 最小二乘拟合空间曲线
Parallels 将扩展桌面平台产品,以进一步改善在 Mac 上运行 Windows 的用户体验和工作效率
【芯片】人人皆可免费造芯?谷歌开源芯片计划已释放90nm、130nm和180nm工艺设计套件
2022-08-10 Daily: Swin Transformer author Cao Yue joins Zhiyuan to carry out research on basic vision models
Pagoda panel open Redis to specify the network machine
JS入门到精通完整版
Basic learning of XML
[Data warehouse design] Why should enterprise data warehouses be layered?(six benefits)
Appium for APP automation testing
领域驱动模型设计与微服务架构落地-从项目去剖析领域驱动
BFT机器人带你走进智慧生活 ——探索遨博机器人i系列的多种应用
redhat替换yum源时redhat.repo无法删除或无法禁用的问题解决方法
BCG库简介
640. 求解方程 : 简单模拟题
PyTorch 多机多卡训练:DDP 实战与技巧