当前位置:网站首页>兴盛优选:时序数据如何高效处理?
兴盛优选:时序数据如何高效处理?
2022-08-11 11:14:00 【InfoQ】
企业介绍
业务背景
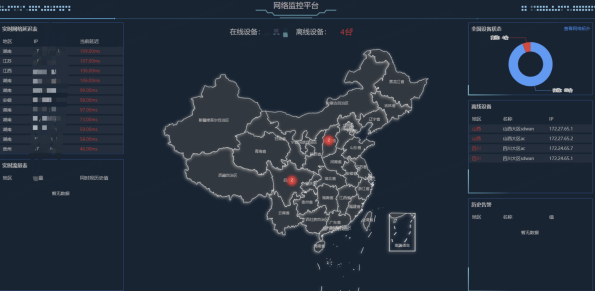
产品调研
- 优点:可以分布式部署,可以无障碍插入,支持任意的字段类型,查询速度快。
- 缺点:只适合记录日志且并发数据量不大的情况,对于海量设备的时序数据写入有性能问题。
- 优点:支持无模式(Schemaless 写入),限制较少。
- 缺点:当面对大批量的数据同时插入或读取时,内存容易被占满,导致死机。尤其是其中的轮询机制,在检验过期数据时,内存占用特别大。此外,在读取数据时,读出来的是列表,可读性差,解析比较麻烦。
- 优点:列式存储以及“一个设备一张表”的模型与我们业务场景十分契合。此外,还可以兼容我们以前使用 InfluxDB 时所习惯的插入方式,代码可读性强,支持强绑定参数。在执行海量数据的查询时,响应速度比 InfluxDB 更快。
- 缺点:Schemeless 的支持还在持续完善之中。
系统架构
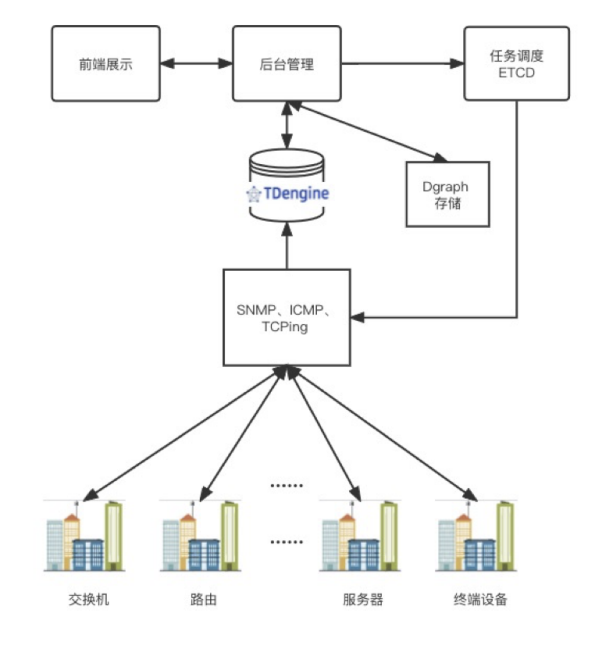
- SNMP 引擎通过 OID 监控网络设备各项指标
- TCPing 引擎用于监控服务器 TCP 端口状态
- ICMP 引擎重点采集接收或返回数据的时间
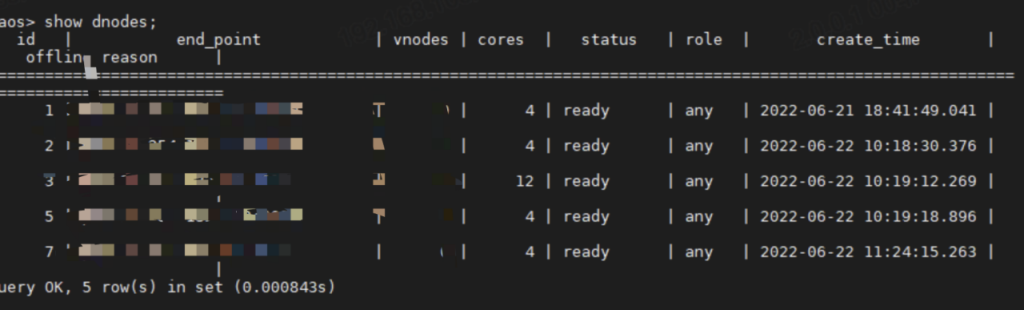
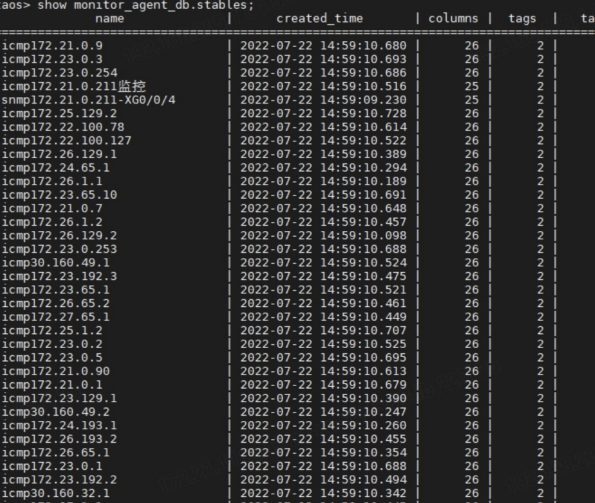
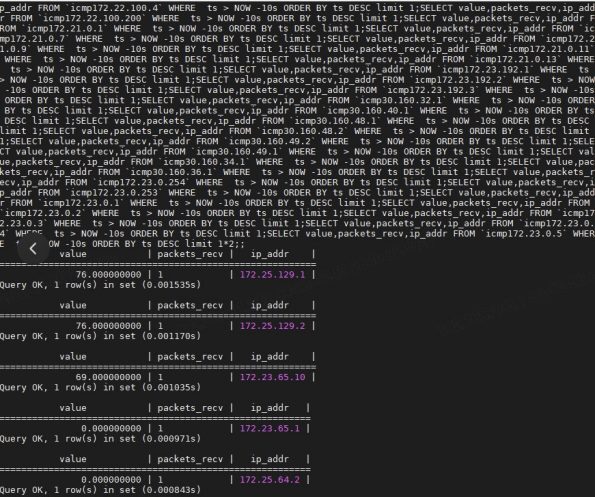
经验总结
边栏推荐
猜你喜欢
2022-08-10北京华为OD机试真题分享
【综合练习12】实现静态网页的相关功能
「开源推荐」一个通用的后台管理系统
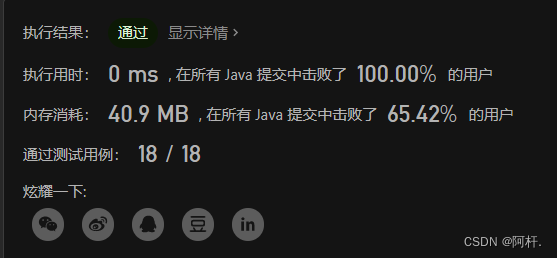
LeetCode 剑指 Offer 35. 复杂链表的复制
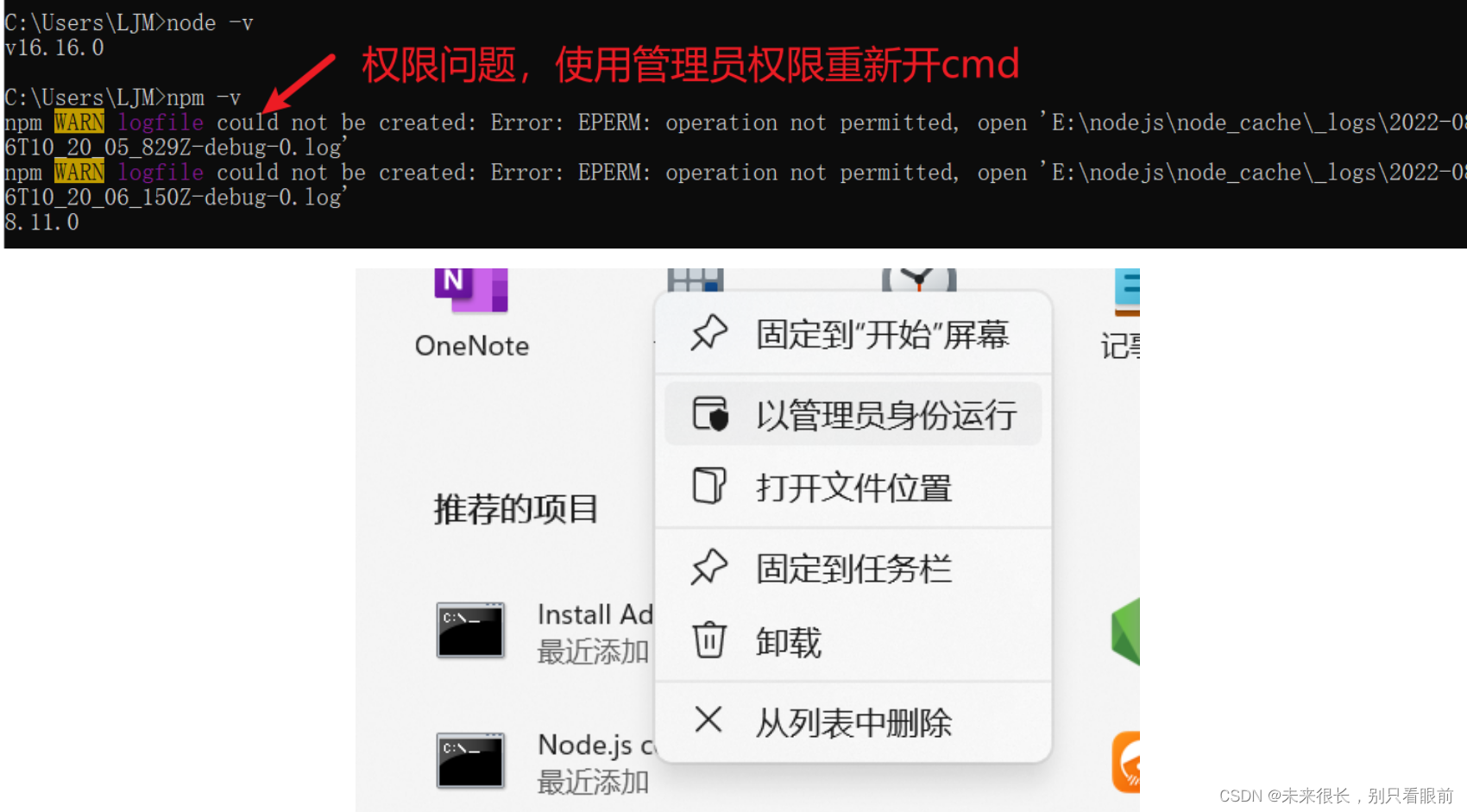
Install nodejs
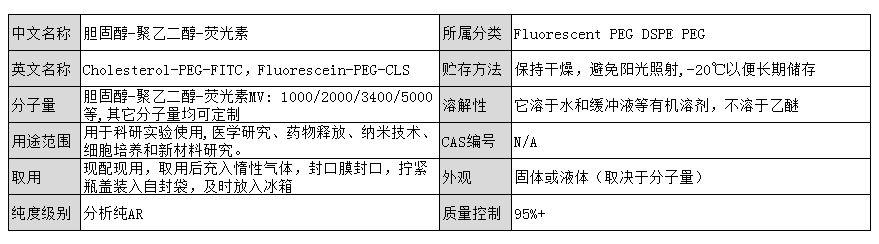
Cholesterol-PEG-FITC,Fluorescein-PEG-CLS,胆固醇-聚乙二醇-荧光素水溶性
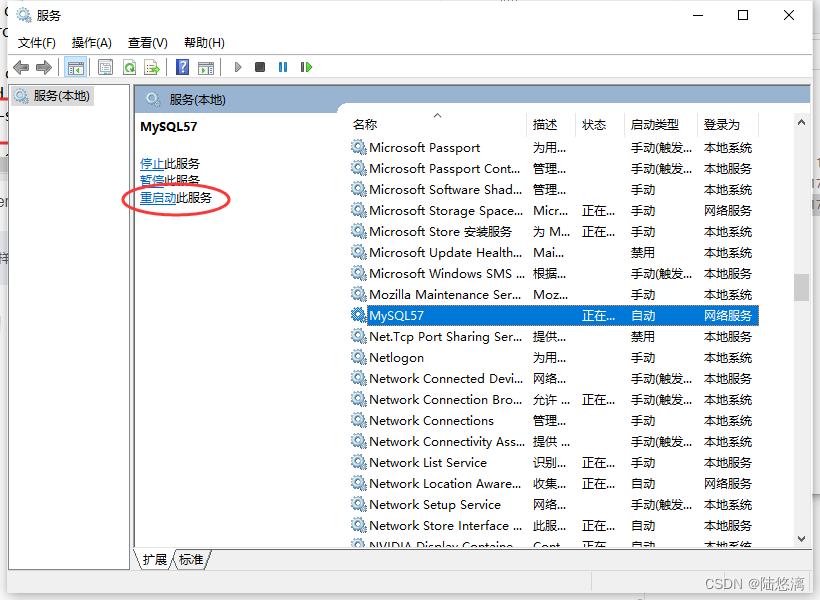
2.MySQL ---- 修改数据库的字符集(日常小技巧)
1元限时秒杀 | 接口抓包分析与Mock实战训练营

The ceiling-level microservice boss summed up this 451-page note to tell you that microservices should be learned this way

Jetpack Compose学习(9)——Compose中的列表控件(LazyRow和LazyColumn)
随机推荐
[Study Notes] Dual Theorem of Linear Programming
数据库导出的csv文件纯数字被转为科学计数法
SDUT数据库 SQL语句练习(MySQL)
5. 内部类
【2022】【论文笔记】基于激光直写氧化石墨烯纸的超薄THz偏转——
那些不用写代码也能做游戏的工具
关于数据权限的设计
a sequence of consecutive positive numbers with sum s
LeetCode·每日一题·1417.重新格式化字符串·模拟
Cholesterol-PEG-FITC, Fluorescein-PEG-CLS, Cholesterol-PEG-Fluorescein water-soluble
论文笔记:《Time Series Generative Adversrial Networks》(TimeGAN,时间序列GAN)
国产数据库有没有在国外的应用案例?
Bitmap这个“内存刺客”你也要小心
阿里云 Hologres助力好未来网校实时数仓降本增效
form-making爬坑笔记(jeecg项目替换表单设计器)
沃土云创计划重磅来袭
openEuler小程序会议指南
fetch请求设置请求头错误导致无法跨域
你必须懂的一些MySQL索引技巧
开源汇智创未来 | 软通动力出席开放原子全球开源峰会OpenAtom openEuler分论坛