当前位置:网站首页>阿里云 Hologres助力好未来网校实时数仓降本增效
阿里云 Hologres助力好未来网校实时数仓降本增效
2022-08-11 10:51:00 【InfoQ】
客户介绍

实时数仓1.0:以Kudu为OLAP引擎,技术瓶颈凸显
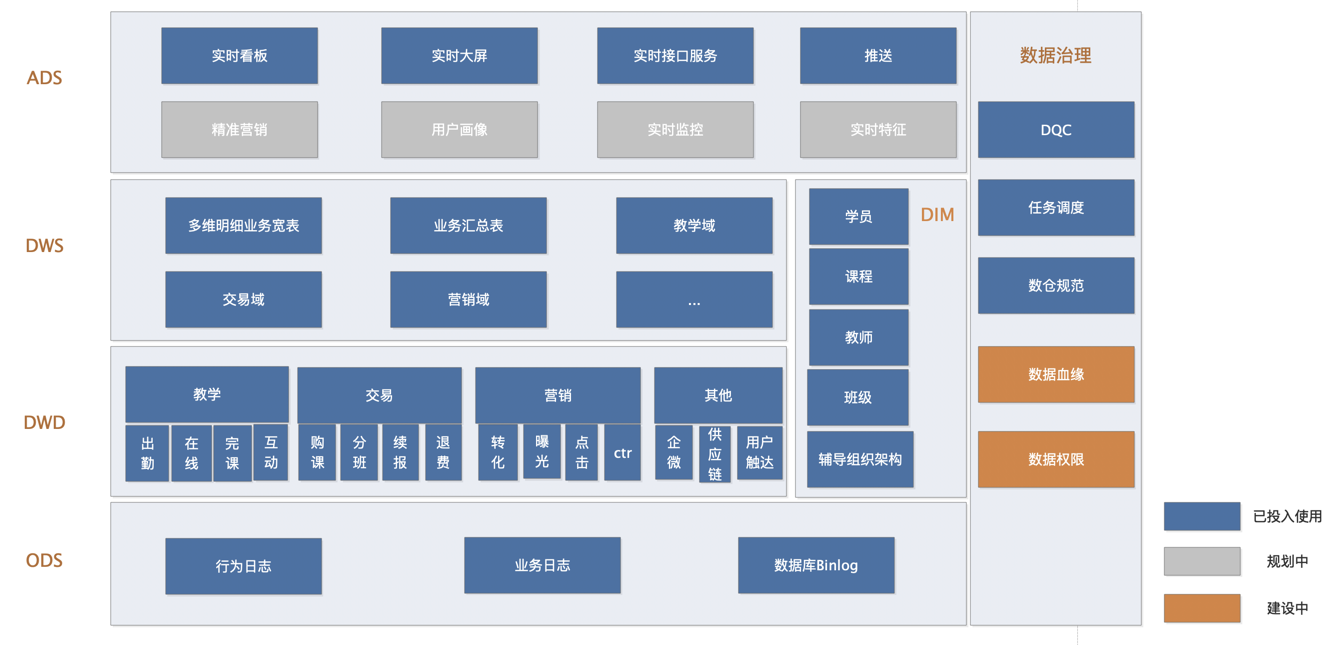
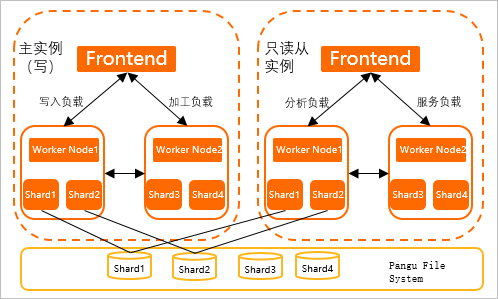
1、网校实时数仓1.0全景图
- ODS层主要存储日志、业务库同步过来的原始数据,包括用户行为等埋点日志以及业务数据等。
- ODS层数据清洗后,写入DWD层,并在DWD层对根据业务需求数据做细分,分为教学、交易、营销等明细数据。
- DWS层将DWD数据与学员、课程、班级、讲次信息等维表进行关联,生成业务宽表或者业务模型汇总等数据。
- ADS层从DWS获取数据,面向应用层,主要是使用MSQL、Polardb作为查询引擎,根据业务场景对接实时看板、实时大屏、实时接口等,赋能实时销量、转化、续报、在线、出勤、完课等场景。
2、基于Kudu架构的场景方案

3、业务挑战:Kudu技术瓶颈凸显,业务成本治理刻不容缓
- 业务发展后期,Impala服务器内存压力较大,内存不足问题频发:网校80%的业务使用分钟级数仓实现且都是每隔5分钟计算一次,Impala承载Kudu数据的加载、计算,大量复杂计算的Sql任务在同一时间瞬时打到服务器,导致Impala节点内存压力较大,甚至出现部分批次任务执行失败情况。
- 运维困难:缺乏Kudu专业运维同学,当某个数据指标计算出现问题,或者集群不稳定时,有比较长的运维流程和修订流程,严重影响实时服务的稳定性,无法保证实时数据的SLA,使得用户体验非常不好。
- 故障恢复时间长,当出现节点故障的时候,为了快速恢复业务,短期靠扩容节点来暂时解决问题,导致运维和成本压力逐步增大。
- “双减”原因,急需对成本进行治理,迫切需要将Kudu切换到建设成本更低、更稳定、可靠的OLAP引擎。
实时数仓2.0:Hologres读写分离部署全面替换Kudu
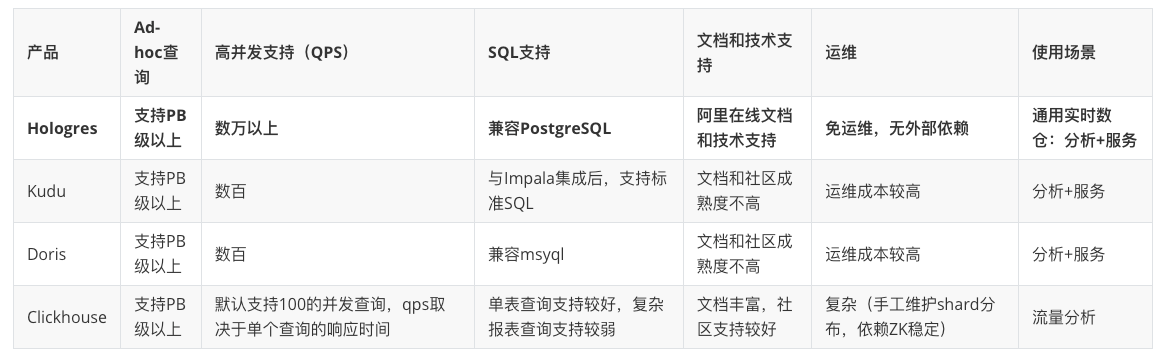
1、OLAP引擎技术选型需求:高吞吐、高可用
- 强大的OLAP能力
- 支持SQL,支持更新、删除、Upsert操作
- 高吞吐、高可用
- 运维方便,资源伸缩便捷
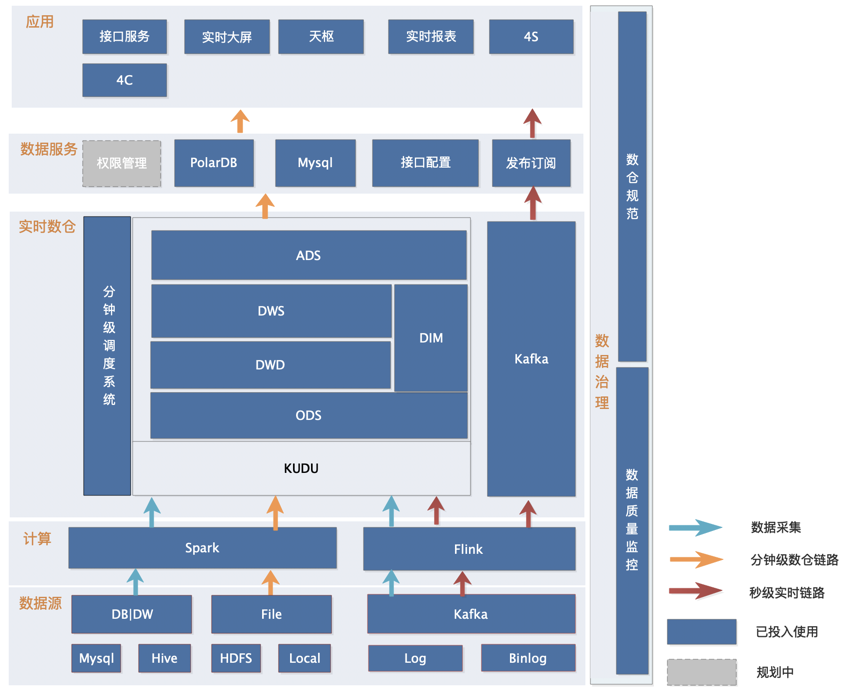
2、Hologres全面替换Kudu作为主OLAP引擎
- 数据分为离线和实时两部分。离线部分数据源数据通过集团采集工具T-Collect接入Hologres ODS层,实时部分通过Flink实时接入MySQL Binlog、埋点日志等数据入仓。
- 在Hologres中对数仓分为ODS、DWD、DWS、ADS等4层,每一层的数据通过集团T-Data平台分钟级调度、清洗,并最后由Hologres从库提供线上服务出口。
- 实时和离线数据统一由Hologres存储,并由从库作为查询引擎统一提供线上数据出口,支撑的业务场景包括实时看板、实时大屏、实时接口服务、实时推送等场景。
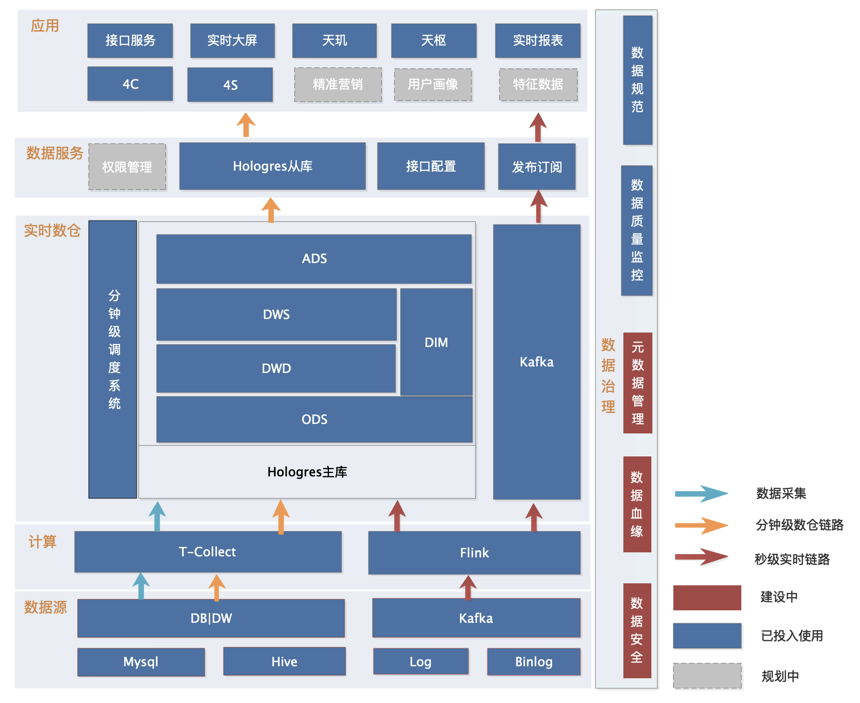
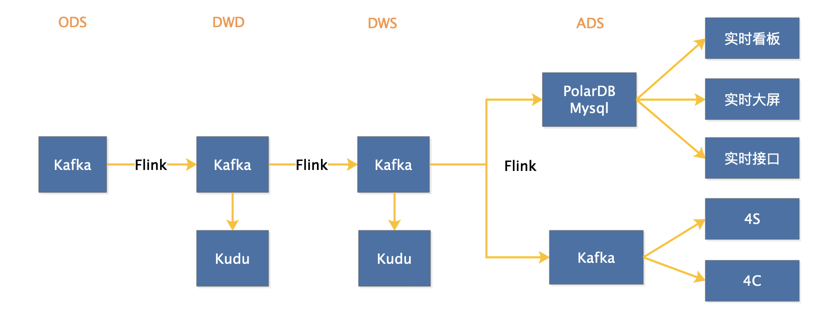
3、查询引擎统一切换到Hologres从实例
助力数仓业务升级,完成降本增效
1、百万级写入和毫秒级查询能力
- 实际业务中,Hologres的写入能力达到百万行+/秒,业务就能快速拿到数据并查询。同时在查询上不仅能支持秒级OLAP分析,还能支持在线服务毫秒级响应,使得业务探索数据的效率变得更快。
- 通过Hologres多子实例的部署方式,天然的就支持了网校实时数仓的多个查询场景,统一了数据的出口,简化了数仓的使用。并且写入和查询之间互不影响,非常有效的做到了读、写分离。
2、降低成本近百万/年
- 实时数仓底座升级Hologres后,无需维护多套系统,通过Hologres一套系统支持了实时数仓的全部场景,OLAP引擎成本相比Kudu节约了近百万/年的费用。
- 公司业务转型背景下,通过数据治理、任务治理等任务数下降80%,Yarn队列资源成本节约几十万/月,数据冗余存储减少90%,提升了数据的利用率。
3、减少运维压力
- 通过Hologres替换Kudu后,依托阿里强大的技术运维能力,很大程度减少了我们在运维层面上的压力,更加专注于业务开发,有更多精力去做好实时数据的稳定性、准确性、及时性,把用户体验做好。
- 周末、暑假等业务高峰资源不足时,可随时进行扩容;业务低峰时,可以对资源进行缩容处理,做到很好的一个资源伸缩和成本控制。
4、集团内Hologres实时数仓架构推广
- 网校实时数仓天然带有K9基因,希望学成功复制网校实时数仓2.0架构,并承载核心实时数据服务,比如实时续报、转化、企微等
未来规划和期望
- 网校实时数仓的持续建设
- 数据治理:元数据、数据质量、数据资产、数据安全等
- 流批一体技术探索
- Hologres暂时还不支持自定义函数,系统自带函数满足不了部分特殊需求,自定义函数这块可以同阿里的技术伙伴一起去共建、推动此功能的实现、上线。
- 其次是Hologres权限配置问题,目前支持简单权限模型、专家权限模型和Schema级别权限模型三种模式,专家模型功能最强大(支持细粒度表级别权限控制),但配置比较复杂,需要执行的命令细节多,从而运维不方便,线上使用的是简单权限模型,权限要控制到schema、表级别,需要在应用系统层面加一层库、表权限管理系统,增加了开发成本;开源Hadoop离线数仓有Range等权限控制框架,能做到精准库、表等权限控制,期望Hologres以后能把权限模型优化得更加简单易用,更多白屏化操作,方便上手。
- 同时,我们期待Hologres后面可以支持查询开源架构Hive表的数据,这样的话做流批一体可以有更加便捷、简单的实现方案。
边栏推荐
猜你喜欢

『独家』互联网 BAT 大厂 Android高级工程师面试题:174道题目让你做到面试无忧

PerfView专题 (第一篇):如何寻找热点函数
How to improve the efficiency of telecommuting during the current epidemic, sharing telecommuting tools
Convolutional Neural Network Gradient Vanishing, The Concept of Gradient in Neural Networks
虚拟机使用 WinSCP & Putty
1.TCP/IP基础知识
Install nodejs
chrome is set to dark mode (including the entire webpage)

LeetCode·每日一题·1417.重新格式化字符串·模拟
The crawler is encapsulated into an api
随机推荐
SAP 产品增强技术回顾
Some time function records commonly used in mysql
天花板级微服务大佬总结出这份451页笔记告诉你微服务就该这么学
日志使用注意事项和建议
The ceiling-level microservice boss summed up this 451-page note to tell you that microservices should be learned this way
7 天找个 Go 工作,Gopher 要学的条件语句,循环语句 ,第3篇
和为s的连续正数序列
爆料!前华为微服务专家纯手打500页落地架构实战笔记,已开源
PerfView专题 (第一篇):如何寻找热点函数
> 家乡旅游景点网页作业制作 网页代码运用了DIV盒子的使用方法,如盒子的嵌套、浮动、margin、border、backgro
SDS观察站
【教程】区块链是数据库?那么区块链的数据存储在哪里?如何查看数据?FISCO-BCOS如何更换区块链的数据存储,由RocksDB更换为MySQL、MariaDB,联盟链区块链数据库,区块链数据库应用
10Super详解
运动健康服务场景事件订阅,让应用推送“更懂用户”
小目标绝技 | 用最简单的方式完成Yolov5的小目标检测升级!
神经网络可视化有3D版本了,美到沦陷!(已开源)
【综合练习12】实现静态网页的相关功能
MySQL数据库基础_常用数据类型_表设计
09什么是继承
全新FIDE 编译简单评测