当前位置:网站首页>ASCII, Unicode and UTF-8
ASCII, Unicode and UTF-8
2022-08-10 22:31:00 【TABE_】
Encoding
Standard ASCII
Standard ASCII, also known as Basic ASCII, uses 7 binary digits (the remaining 1 binary 0 is 0) to represent all uppercase and lowercase letters, the numbers 0 to 9, punctuation, and the alphanumeric characters used in American English.Special control characters.
ASCII code just uses 7-bit binary number, when it is represented by a byte, its first bit is always 0.If only English is represented, one byte is enough, but to represent all the characters in the world, multiple bytes must be used.
Unicode
Unicode is to be able to represent all text on the computer.It sets a unified and unique binary encoding for each character in each language to meet the requirements of cross-language and cross-platform text conversion and processing.It should be noted that Unicode is only a symbol set, it only specifies the binary code of the symbol, but does not specify how the binary code should be stored.
UTF-8
UTF-8 is the most widely used unicode implementation on the Internet.UTF-8 is a variable-length encoding method, which can use 1~4 bytes to represent a symbol, and the byte length varies according to different symbols.
UTF-8 encoding rules:
- For a single-byte character, the first bit is set to 0, and the next 7 bits correspond to the Unicode code point of the character.Therefore, for characters 0 - 127 in English, it is exactly the same as the ASCII code.This means that documents from the ASCII era can be opened with UTF-8 encoding without any problems.
- For a character that needs to be represented by N bytes (N > 1), the first N bits of the first byte are set to 1, the N + 1th bit is set to 0, and the remaining N - 1 wordsThe first two bits of the section are set to 10, and the remaining bits are filled with the character's Unicode code point.
边栏推荐
- SDP
- Shell 编程--Sed
- FPGA - Memory Resources of 7 Series FPGA Internal Structure -03- Built-in Error Correction Function
- 爬虫request.get()出现错误
- STL-stack
- VLAN huawei 三种模式
- The Thread State,
- port forwarding
- 3D model reconstruction of UAV images based on motion structure restoration method based on Pix4Dmapper
- STL-deque
猜你喜欢

Shell编程之条件语句(二)
这款可视化工具神器,更直观易用!太爱了

谁是边缘计算服务的采购者?是这六个关键角色

字节跳动原来这么容易就能进去...
FPGA - 7系列 FPGA内部结构之Memory Resources -03- 内置纠错功能
RK3399平台开发系列讲解(内核驱动外设篇)6.35、IAM20680陀螺仪介绍

Why general company will say "go back messages such as" after the end of the interview, rather than just tell the interviewer the result?
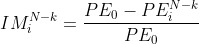
基于交流潮流的电力系统多元件N-k故障模型研究(Matlab代码实现)【电力系统故障】

Regular expression of shell programming and text processor

How to translate financial annual report, why choose a professional translation company?
随机推荐
QT笔记——QT工具uic,rcc,moc,qmake的使用和介绍
接口测试的概念、目的、流程、测试方法有哪些?
geemap的详细安装步骤及环境配置
An article to teach you a quick start and basic explanation of Pytest, be sure to read
SDP
c语言之 练习题1 大贤者福尔:魔法数,神奇的等式
JVM classic fifty questions, now the interview is stable
Using SylixOS virtual serial port, serial port free implementation system
商家招募电商主播要考虑哪些内容
MySQL Advanced Commands
Web Reverse Lilac Garden
BM7 链表中环的入口结点
Live Classroom System 09--Tencent Cloud VOD Management Module (1)
Live Classroom System 08-Tencent Cloud Object Storage and Course Classification Management
服务——DHCP原理与配置
学会开会|成为有连接感组织的重要技能
About DataFrame: Processing Time
shell (text printing tool awk)
String类的常用方法
过滤器