当前位置:网站首页>shell (text printing tool awk)
shell (text printing tool awk)
2022-08-10 21:52:00 【Guannan cattle x people】
目录
AWK概述
awk是一种处理文本文件的语言,是一个强大的文本分析工具.awk是一种处理文本文件的语言,是一个强大的文本分析工具.
它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描、过滤、统计汇总工作数据可以来白标准输入也可以是管道或文件
20世纪70年代诞生于贝尔实验室,现在centos7用的是gawk
可以在无交互的模式下实现复杂的文本操作;数据可以来自标准输入也可以是管道或文件
相较于sed常作用于一整个行的处理,awk则比较倾向于一行当中分成数个字段来处理,因为awk相当适合小型的文本数据.
awk工作原理
他和sed的区别
前面提到sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个"字段"然后再进行处理,And by default the fields areThe delimiter is a space or tab键.awk 执行结果可以通过print的功能将字段数据打印显示.
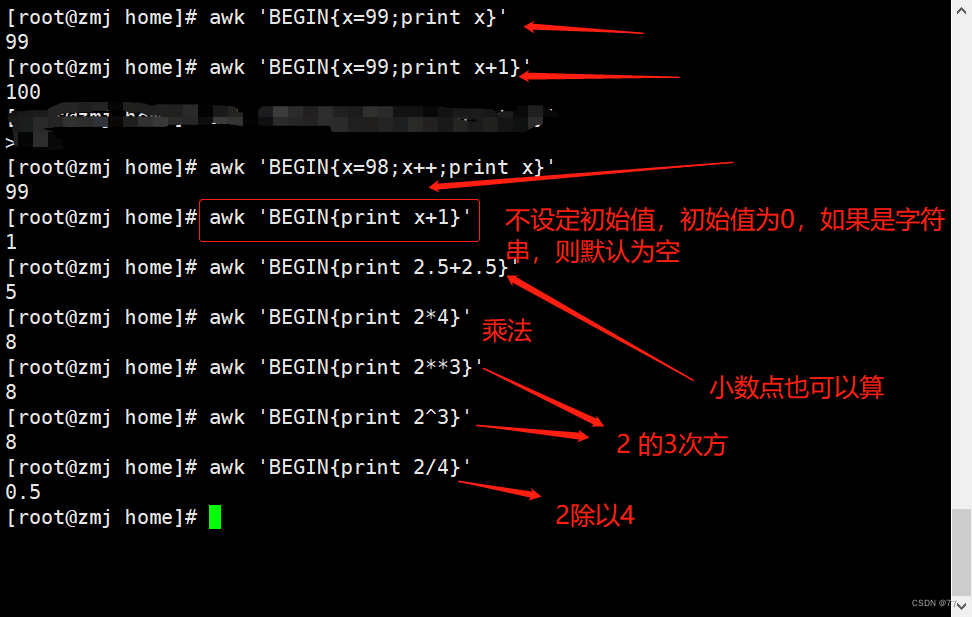
在使用awk命令的过程中,可以使用逻辑操作符"&&“表示"与”、"||“表示"或”、"!“表示"非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方.
awk后面接两个单引号并加上大括号{ }来设置想要对数据进行的处理操作,awk可以处理后续接的文件,也可以读取来自前个命令的标准输.
当读到第一行时,匹配条件,然后执行指定动作,再接着读取第二行数据处理,不会默认输出
如果没有定义匹配条件默认是匹配所有数据行,awk隐含循环,条件匹配多少次动作就会执行多少次
逐行读取文木,默认以空格或tab键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令
AWK命令的格式
awk 选项 ‘模式或条件{编辑命令}’ 文件1 文件2…. //过滤并输出文件中符合条件的内容
awk -f 脚本文件 文件1 文件2… //从脚本中调用的编辑指令,过滤并输出内容
格式: awk关键字 选项 命令部分 '{xxxxxx}' 文件名
awkContains several common built-in variables(可直接用)
| 变量 | 意义 |
|---|---|
| FS: | 指定每行文本的字段分隔符,默认为空格或制表位; |
| NF: | 当前处理的行的字段个数; |
| NR: | 当前处理的行的行号(序数); |
| $0: | 当前处理的行的整行内容; |
| $n: | 当前处理的行的第n个字段(第n列); |
| FILENAME: | 被处理的文件名; |
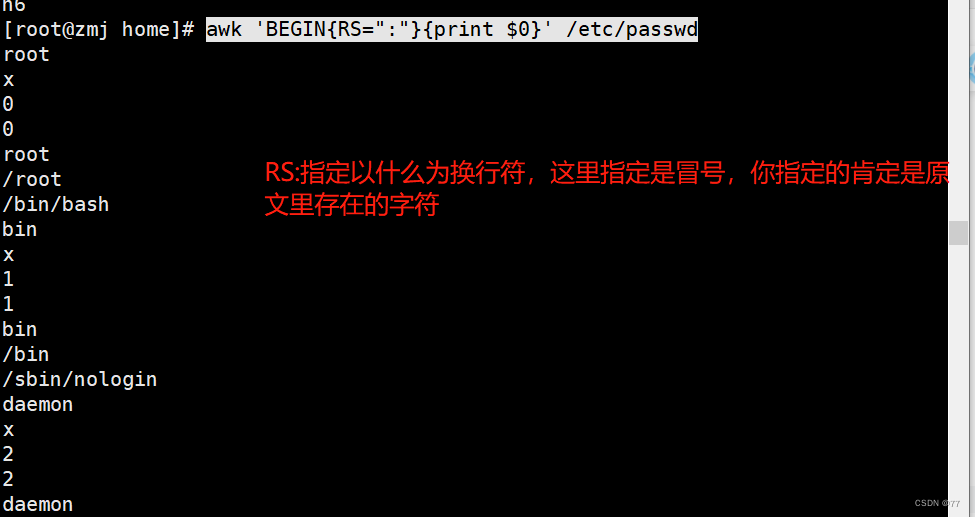
| RS: | 数据记录分隔,默认为\n,即每行为一条记录. |
例:

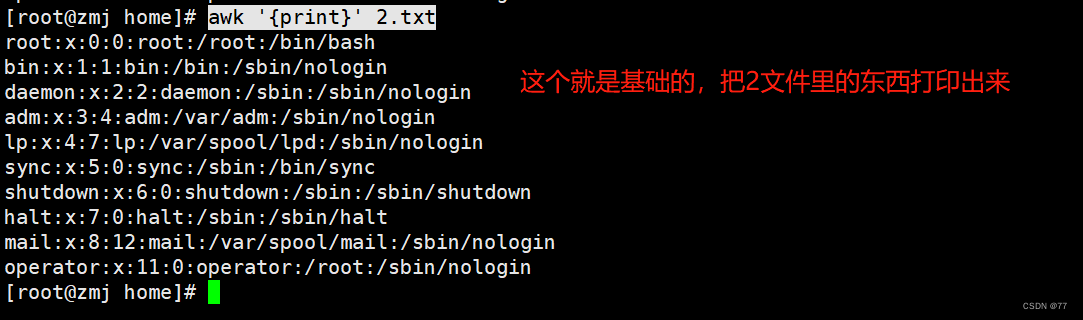
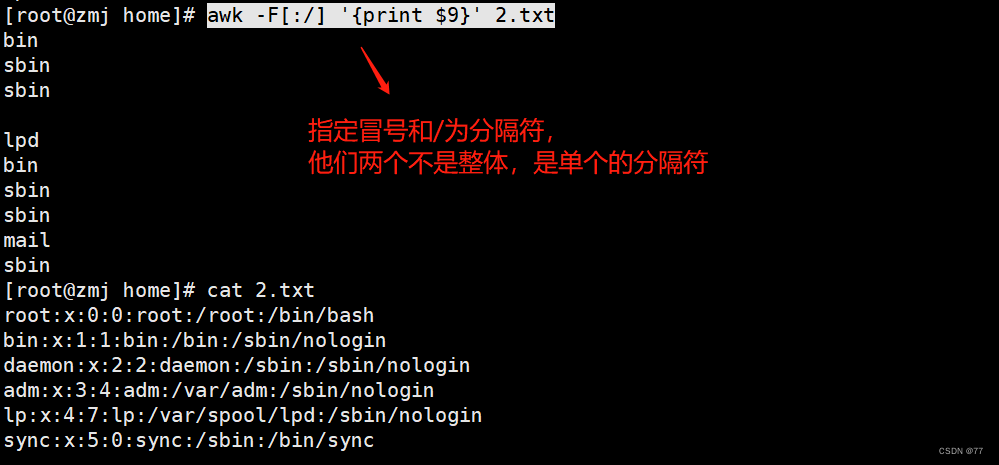
Displays the separated fifth column with a colon as a delimiter
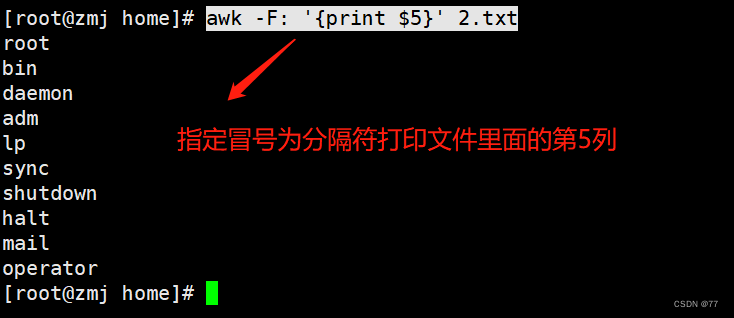
Display the first and second columns separated by colons
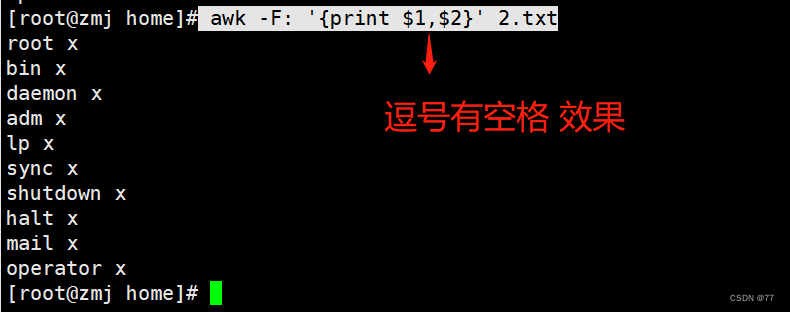
The effect is the same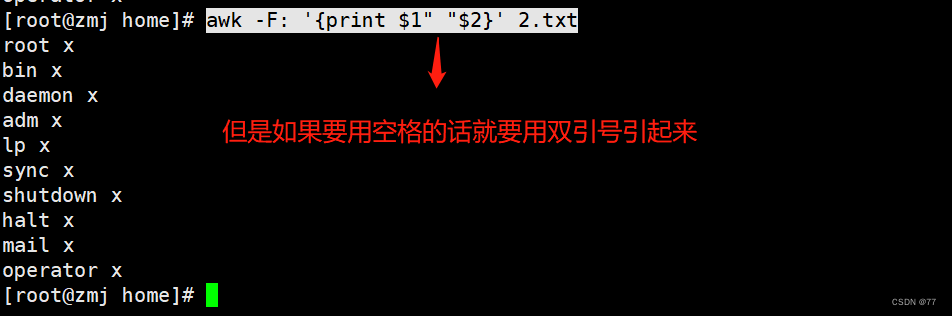
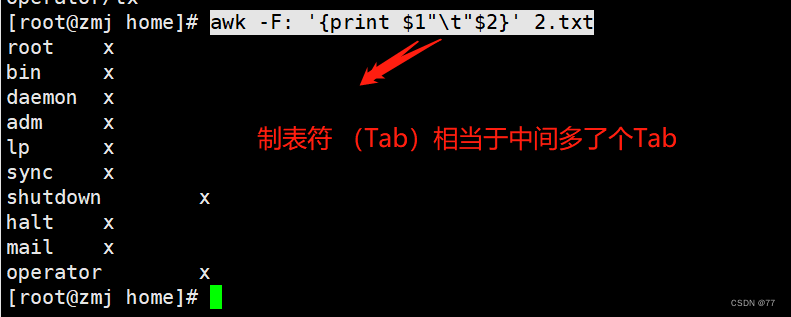
用制表符作为分隔符输出
定义多个分隔符,只要看到其中一个都算作分隔符
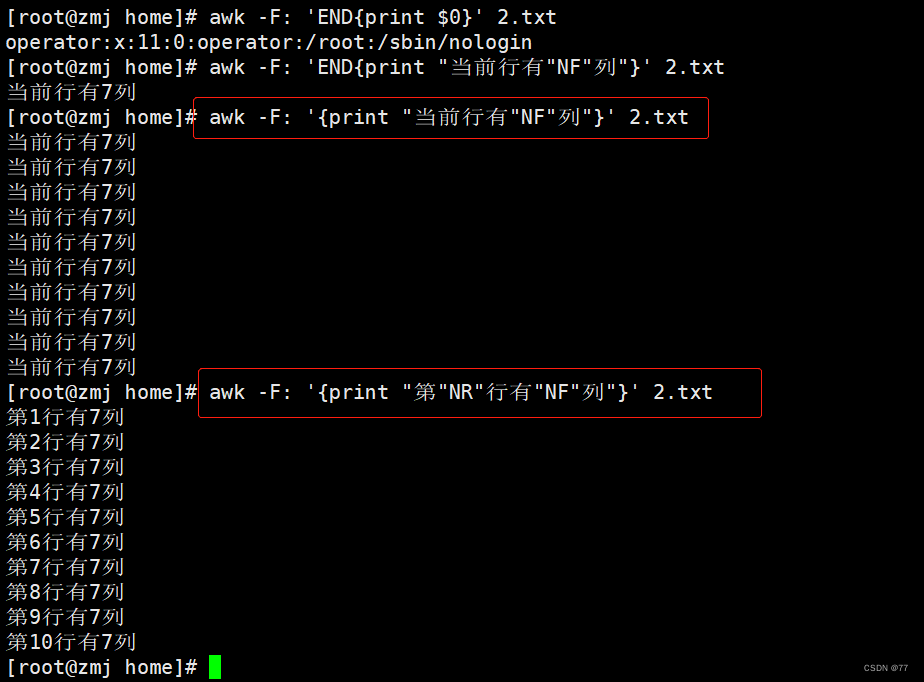
awk常用内置变量:$1、$2、NF、NR、$0
$1:代表第一列
$2:代表第二列 以此类推
$0:代表整行
NF:一行的列数
NR:行数
案例
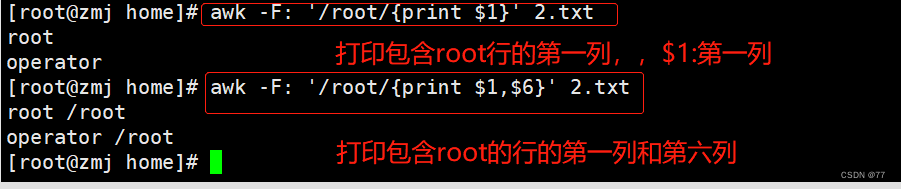
打印包含root的整行内容

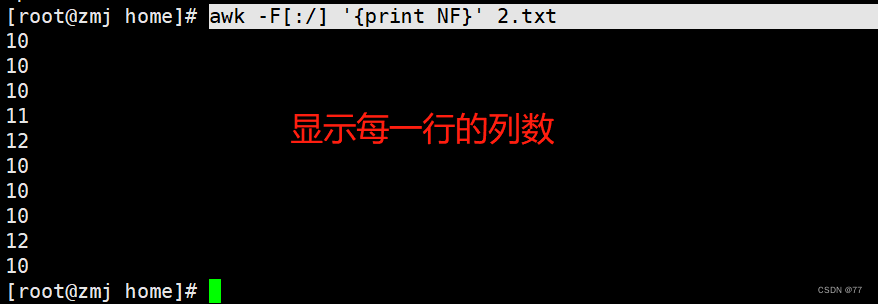
打印每一行的列数,显示行号
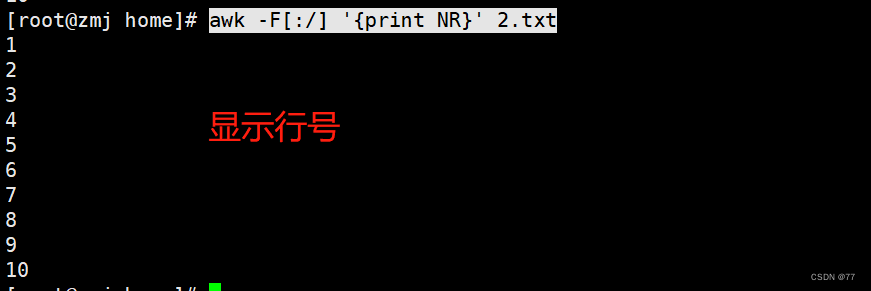
Displays the line number of the processed line and the entire line content
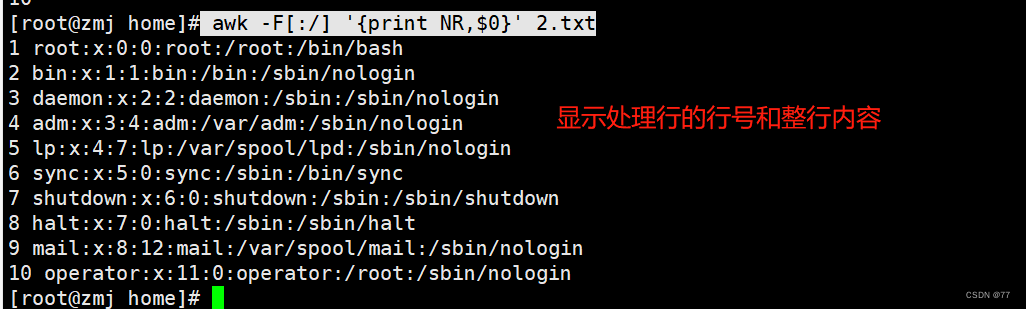
打印第二行,不加print也一样,默认就是打印

打印第二行的第一列

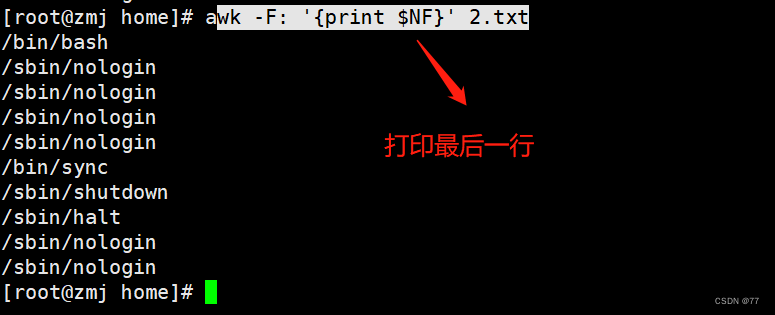
打印最后一行
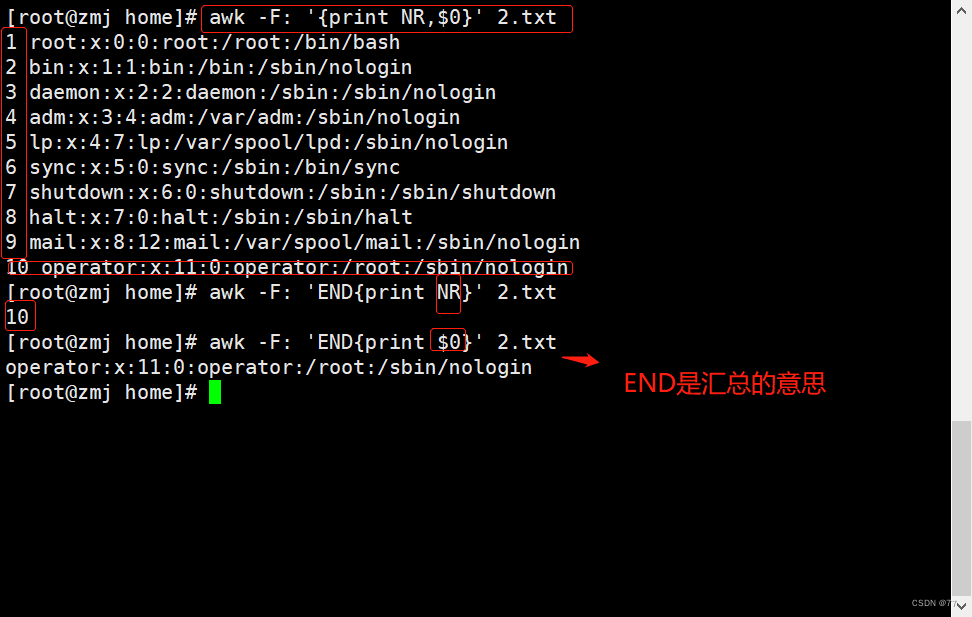
Prints the total number of lines and prints the last line of the file,END是汇总的意思
可以输入中文
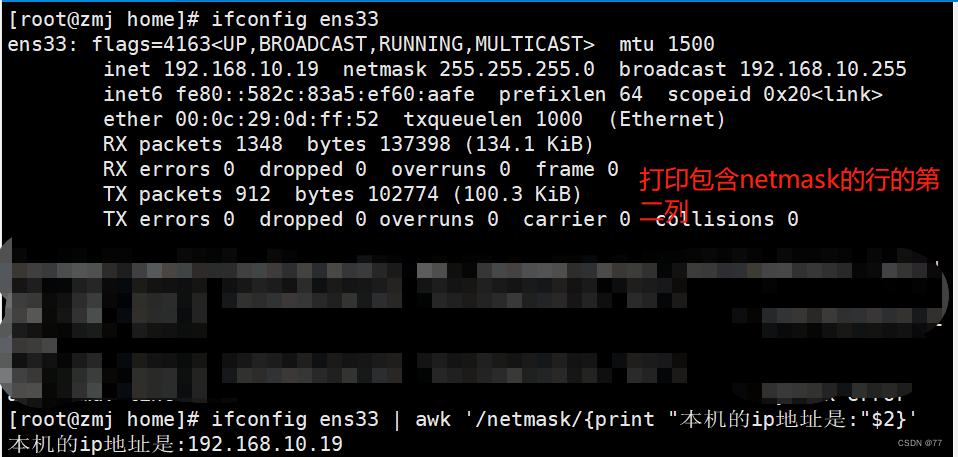
扩展案例:网卡的ip、流量

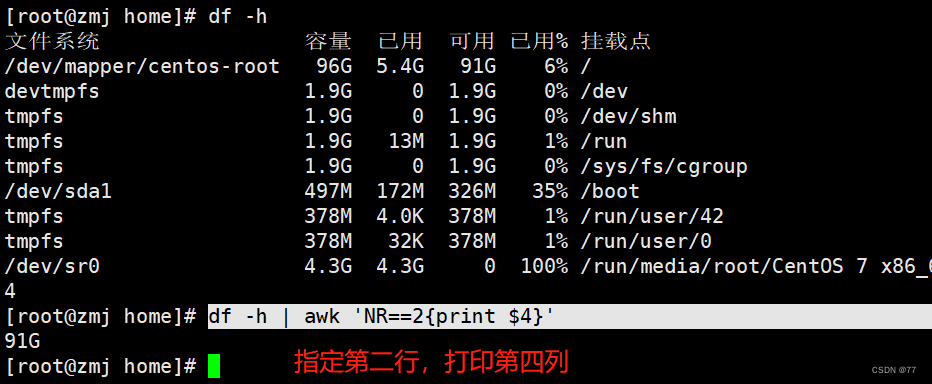
扩展案例:根分区的可用量
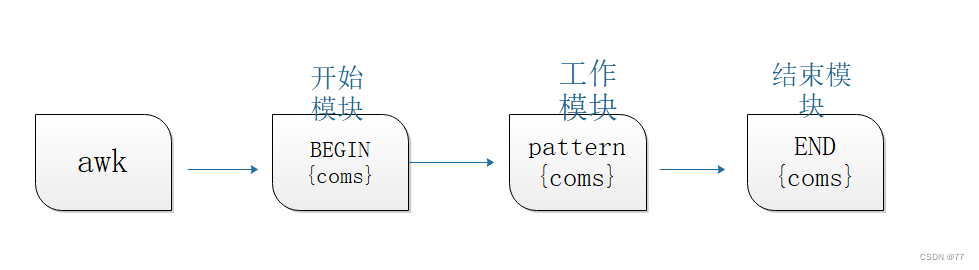
BEGIN和END的用法与区别
逐行执行开始之前执行什么任务,结束之后再执行什么任务,用BEGIN、END
BEGIN:一般用来做初始化操作,仅在读取数据记录之前执行一次
END:一般用来做汇总操作,Execute again only after the data record has been read
 awk的运算案例:
awk的运算案例:
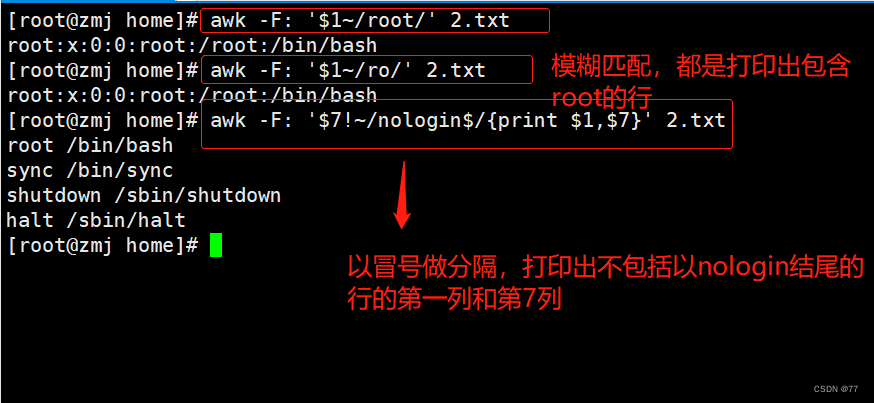
模糊匹配,用~表示包含;!~表示不包含
关于数值与字符串的比较
比较符号:== != <= >= < >
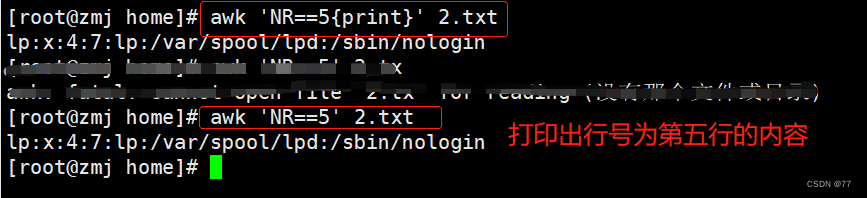
Print the line number as th5行的内容
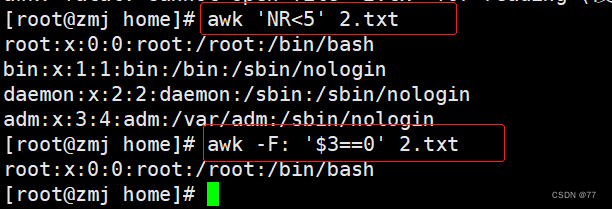
Print line number less than5行的内容;Use colons to separate the values of the third column0的行
精确匹配

Numbers are combined with string comparisons and logical operations
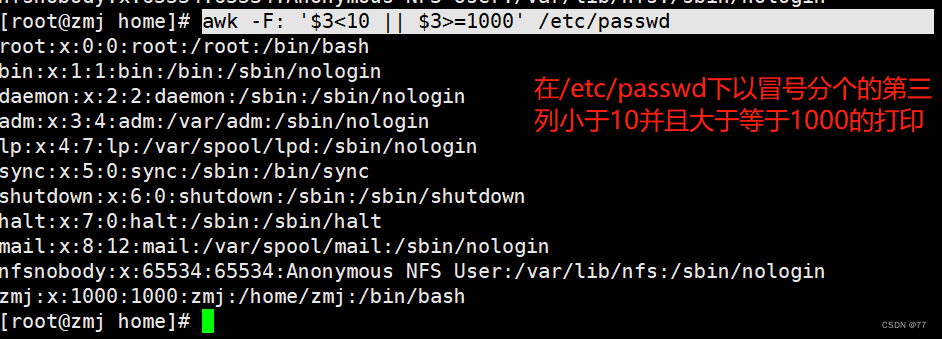
filter columns

其他内置变量的用法FS(输入)、OFS、NR、FNR、RS、ORS
Add the first three
NF 字段个数(读取的列数)
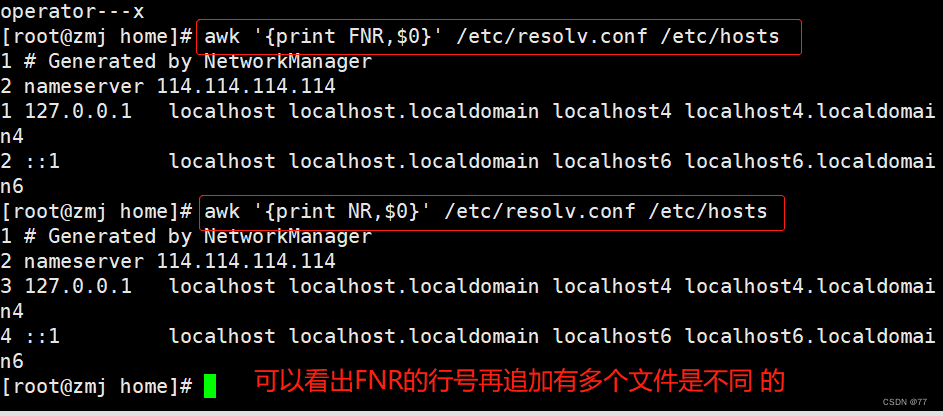
NR 记录数(行号)从1开始,The new document continues the above technique,新文件不从1开始
FNR 读取文件的记录数(行号),从1开始,新的文件重新从1开始计数
FS 输入字段分隔符,默认是空格
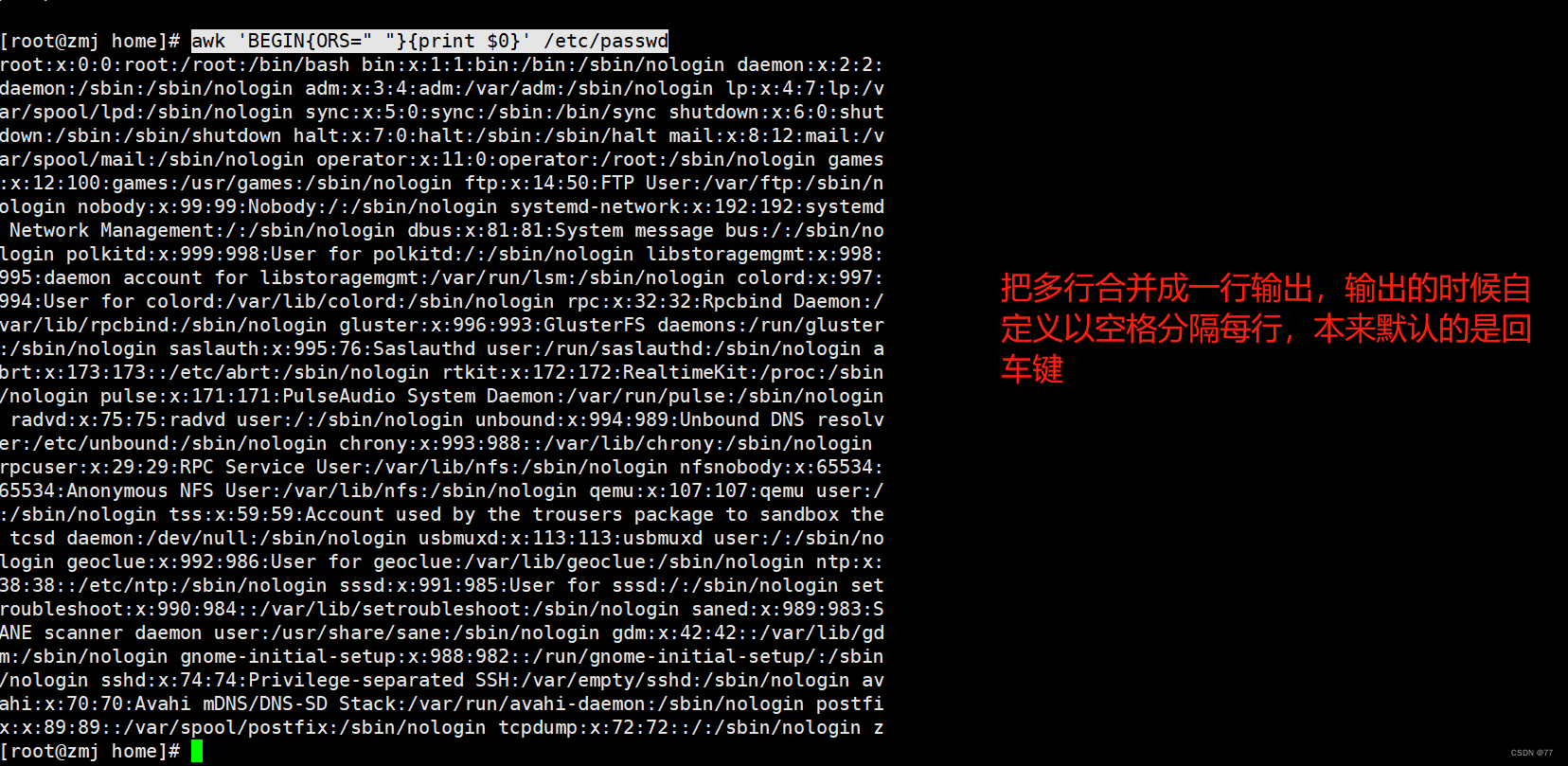
OFS 输出字段分隔符,默认是空格
RS 输入行分隔符,默认为换行符
ORS 输出行分隔符,默认为换行符
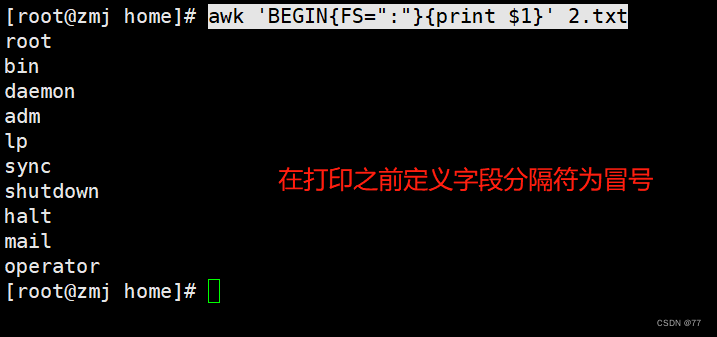
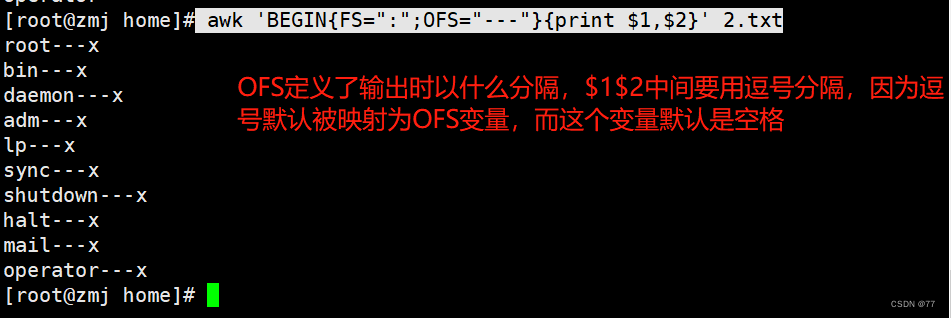
在打印之前定义字段分隔符为冒号
FNR和NR的区别
RS和ORS的区别
 awk高级用法
awk高级用法
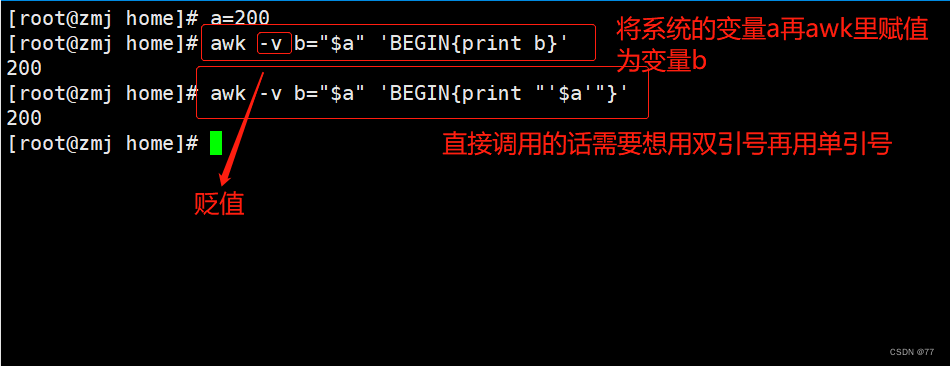
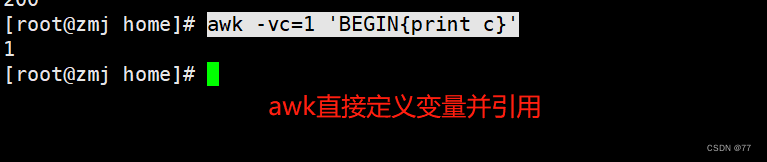
定义引用变量
案例:
调用函数getline:读取一行数据的时候并不是得到当前行而是当前行的下一行
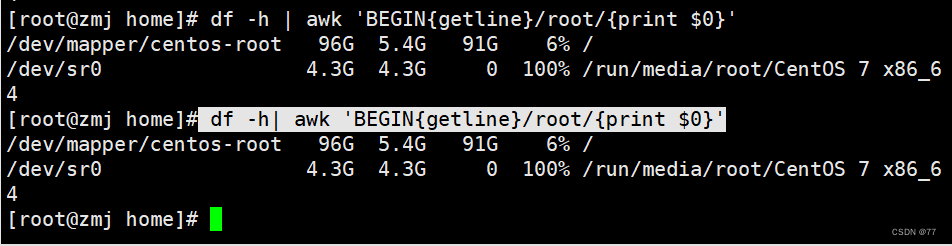 显示偶数行;显示奇数行
显示偶数行;显示奇数行
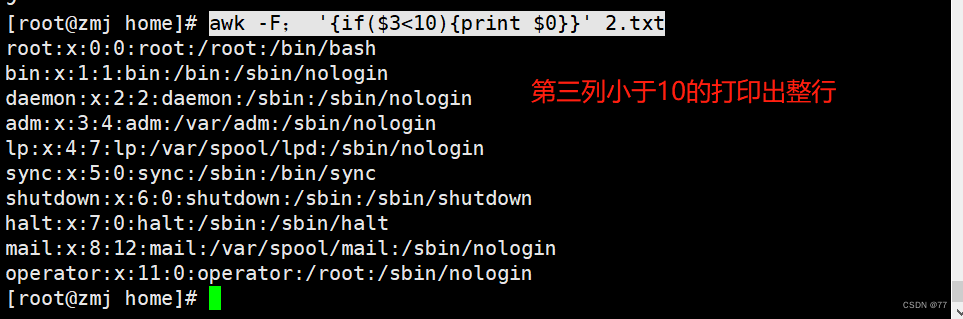
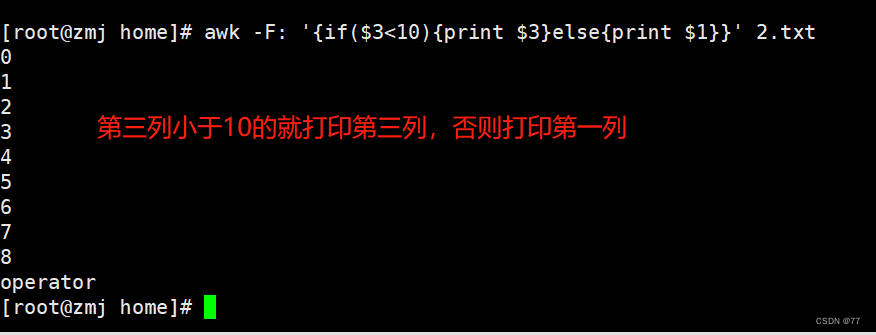
 awk中使用if语句
awk中使用if语句
awk的if语句也分为单分支、双分支和多分支
单分支为if () {}
双分支为if() {}else{}
多分支为if() {}else if () {}else{}
总结
Usage of base regular expression and extended regular expression metacharacters in regular expressions,And the online Three Musketeersgrep、sed、awkHow to use and use cases combined with regular expressions and text widgetscut、sort、uniq、trexample of usage,掌握其用法,It can make our work more convenient in the production environment.
边栏推荐
猜你喜欢

PROCEDURE :存储过程结构——《mysql 从入门到内卷再到入土》

TCL:事务的特点,语法,测试例——《mysql 从入门到内卷再到入土》
【Windows】你不能访问此共享文件夹,因为你组织的安全策略阻止未经身份验证的来宾访问,这些策略可帮助保护你的电脑

LeetCode-402 - Remove K digits
These must-know JVM knowledge, I have sorted it out with a mind map

异常的了解
![[SQL brush questions] Day3----Special exercises for common functions that SQL must know](/img/b8/05589138441ada5d453297de7d181b.png)
[SQL brush questions] Day3----Special exercises for common functions that SQL must know

翻译科技论文,俄译中怎样效果好
ACM解题笔记——HDU 1401 Solitaire(DBFS)
The use of TortoiseSVN little turtle
随机推荐
Mark!画出漂亮的神经网络图!神经网络可视化工具集锦搜集
Redis 性能影响 - 异步机制和响应延迟
为什么一般公司面试结束后会说「回去等消息」,而不是直接告诉面试者结果?
PROCEDURE :存储过程结构——《mysql 从入门到内卷再到入土》
2021DASCTF实战精英夏令营暨DASCTF July X CBCTF 4th
【SQL刷题】Day3----SQL必会的常用函数专项练习
Uniapp编译后小程序的代码反编译一些思路
Detailed explanation of the use of Oracle's windowing function (2)
微擎盲盒交友变现-vp_ph打开慢优化
第五届“强网杯”全国网络安全挑战赛(线上赛)
2022.8.8好题选讲(数论场)
Live Classroom System 08-Tencent Cloud Object Storage and Course Classification Management
Web Reverse Lilac Garden
如何保护 LDAP 目录服务中的用户安全?
Exploration and practice of the "zero trust" protection and data security governance system of the ransomware virus of Meichuang Technology
labelme - block drag and drop events
优化是一种习惯●出发点是'站在靠近临界'的地方
Using SylixOS virtual serial port, serial port free implementation system
labelme-5.0.1版本编辑多边形闪退
ThreadLocal全面解析(一)