当前位置:网站首页>深度学习模型的两种部署:ONNX与Caffe
深度学习模型的两种部署:ONNX与Caffe
2022-08-09 01:00:00 【子燕若水】
主流的模型部署有两种路径,以TensorRT为例,一种是Pytorch->ONNX->TensorRT,另一种是Pytorch->Caffe->TensorRT。个人认为目前后者更为成熟,这主要是ONNX,Caffe和TensorRT的性质共同决定的
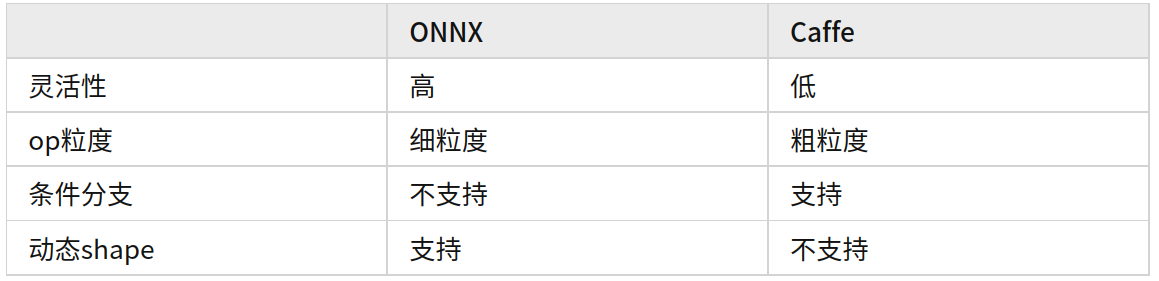
上面的表列了ONNX和Caffe的几点区别,其中最重要的区别就是op的粒度。举个例子,如果对Bert的Attention层做转换,ONNX会把它变成MatMul,Scale,SoftMax的组合,而Caffe可能会直接生成一个叫做Multi-Head Attention的层,同时告诉CUDA工程师:“你去给我写一个大kernel“(很怀疑发展到最后会不会把ResNet50都变成一个层。。。)

因此如果某天一个研究员提了一个新的State-of-the-art的op,很可能它直接就可以被转换成ONNX(如果这个op在Pytorch的实现全都是用Aten的库拼接的),但是对于Caffe的工程师,需要重新写一个kernel。
细粒度op的好处就是非常灵活,坏处就是速度会比较慢。这几年有很多工作都是在做op fushion(比如把卷积和它后面的relu合到一起算),XLA和TVM都有很多工作投入到了op fushion,也就是把小op拼成大op。
TensorRT是NVIDIA推出的部署框架,自然性能是首要考量的,因此他们的layer粒度都很粗。在这种情况下把Caffe转换过去有天然的优势。
除此之外粗粒度也可以解决分支的问题。TensorRT眼里的神经网络就是一个单纯的DAG:给定固定shape的输入,执行相同的运算,得到固定shape的输出
tensor i = funcA();
if(i==0)
j = funcB(i);
else
j = funcC(i);
funcD(j);对于上面的网络,假设funcA,funcB,funcC和funcD都是onnx支持的细粒度算子,那么ONNX就会面临一个困难,它转换得到的DAG要么长这样:funcA->funcB->funcD,要么funcA->funcC->funcD。但是无论哪种肯定都是有问题的。
而Caffe可以用粗粒度绕开这个问题
tensor i = funcA();
coarse_func(tensor i) {
if(i==0) return funcB(i);
else return funcC(i);
}
funcD(coarse_func(i))因此它得到的DAG是:funcA->coarse_func->funcD
当然,Caffe的代价就是苦逼的HPC工程师就要手写一个coarse_func kernel。。。(希望Deep Learning Compiler可以早日解放HPC工程师)
作者:立交桥跳水冠军
链接:https://zhuanlan.zhihu.com/p/272767300
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
边栏推荐
猜你喜欢










随机推荐
在 ASP.NET Core 中上传文件
笔记&代码 | 统计学——基于R(第四版) 第二章数据可视化
笔记&代码 | 统计学——基于R(第四版) 第九章一元线性回归
jetson nano 开机闪一下然后黑屏
Sencha Touch延迟加载模块提高程序启动时性能
Use jdbc to handle MySQL's utf8mb4 character set (transfer)
makefile文件编译
LeetCode精选200道--字符串篇
如何仿造一个websocket请求?
轻量级神经网络SqueezeNext--考虑硬件提速
JD.com was abused on three sides. Regarding redis, high concurrency, and distributed, I am confused.
MySQL5.7安装教程图解
js 实现数字跳动
425 Can‘t open data connection for transfer of “/“
docker搭建redis主从复制,容器无法启动?
【信号去噪】基于Sage-Husa自适应卡尔曼滤波器实现海浪磁场噪声抑制及海浪磁场噪声的产生附matlab代码
4-6 Matplotlib库 饼图
WPF效果第一百九十四篇之伸缩面板
轻量级学习网络--ShuffleNet v1:Group conv的改进与channel shuffle的提出
tf.pad()--填充操作