当前位置:网站首页>Deploying sbert model based on torchserve < semantic similarity task >
Deploying sbert model based on torchserve < semantic similarity task >
2022-04-23 02:29:00 【Weiyaner】
List of articles
This is a question about how to use TorchServe Deploy pre trained HuggingFace Sentence transformers Model guide .
Mission : semantic similarity ( Return to )
Algorithm model :Sentence BERT
Pre training model :TinyBERT_L6_ch
frame :torch 1.11
System environment :Ubuntu 20.04 ( Cloud server CPU)
1 Get the model
The channel of the model comes from 2 aspect
- Get the pre training model directly
stay huggingface transformers Official website , You can download the relevant pre training model . - Fine tuned model on task dataset
After fine tuning the local dataset , Save better models , Get the model and configuration file .
from sentence_transformers import SentenceTransformer
smodel = SentenceTransformer(model_dir_path)
smodel.save('model_name')
obtain :

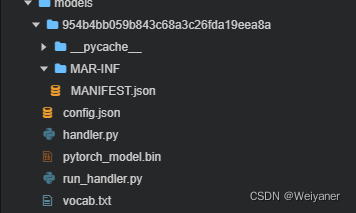
Mainly use the three files inside , Namely pytorch_model.bin,config.json,vocab.txt.
2 install torchserve
TorchServe from Java Realization , Therefore, the latest version of OpenJDK To run the .
apt install openjdk-11-jdk
If win Environmental Science , Refer to here for manual installation :https://blog.csdn.net/qq_41873673/article/details/108027074
Next , In order to ensure a clean environment , by TorchServe Create a new Conda Environment and activate .
conda create -n torchserve
source activate torchserve
Next install TorchServe The dependencies of .
conda install sentencepiece torch-model-archiver psutil pytorch torchserve torchvision torchtext
If you want to use GPU example , Additional software packages are required .
conda install cudatoolkit=10.1
Now the dependencies have been installed , Can be cloned TorchServe The repository .
git clone https://github.com/pytorch/serve.git
cd serve
Environment setting is complete , Next, continue to model encapsulation .
3 Encapsulate models and interfaces
Before encapsulating the model and interface, you need to prepare the model and interface files
3.1 Prepare the model
stay serve Create a new folder in the directory , Used to save the files related to the above three models .
mkdir Transformer_model/TinyBERT_L6_ch
mv pytorch_model.bin vocab.txt config.json Transformer_model/TinyBERT_L6_ch/
3.2 Prepare interface documents
Handler It can be TorchServe The name of the built-in processor or py Path to file , To handle customized TorchServe Reasoning logic . It is mainly divided into three parts , Namely preprocess,inference and postprocess, Represents the processing of data , Model reasoning and post-processing .
TorchServe The library supports the following handlers :image_classifier, object_detector, text_classifier, image_segmenter.
There is no supporting interface for semantic similarity tasks , Need to write based on personal data .
handler.py
import json
import zipfile
from json import JSONEncoder
import numpy as np
import os
class NumpyArrayEncoder(JSONEncoder):
def default(self, obj):
if isinstance(obj, np.ndarray):
return obj.tolist()
return JSONEncoder.default(self, obj)
class SentenceTransformerHandler(object):
def __init__(self):
super(SentenceTransformerHandler, self).__init__()
self.initialized = False
self.embedder = None
def initialize(self, context):
properties = context.system_properties
model_dir = properties.get("model_dir")
self.embedder = SentenceTransformer(model_dir)
self.initialized = True
def preprocess(self, data):
##
inputs = data[0].get("data")
if inputs is None:
inputs = data[0].get("body")
inputs = inputs.decode('utf-8')
inputs = json.loads(inputs)
sentences= inputs['queries']
return sentences
def inference(self, data):
query_embeddings = self.embedder.encode(data)
return query_embeddings
def postprocess(self, data):
return [json.dumps(data,cls=NumpyArrayEncoder)]
And then through run_handler.py call , As an interface
run_handler.py
from handler import SentenceTransformerHandler
_service = SentenceTransformerHandler()
def handle(data, context):
""" Entry point for SentenceTransformerHandler handler """
try:
if not _service.initialized:
print('ENTERING INITIALIZATION')
if data is None:
return None
data = _service.preprocess(data)
data = _service.inference(data)
data = _service.postprocess(data)
return data
except Exception as e:
raise Exception("Unable to process input data. " + str(e))
3.3 encapsulation
stay TinyBERT_L4_ch Under the folder , Execute the encapsulation command
Three model files
1. Model parameter file (torch) pytorch_model.bin
2. Model configuration file config.json
3. Thesaurus vocab.txt chinese 21128, english 30522
Two interface files :
1. handler.py Define interface functions
2. run_handler.py Call the interface class defined above , As handler Pass in
Encapsulate models and interfaces
torch-model-archiver --model-name sbert_tiny4ch \
--version 1.0 \
--serialized-file pytorch_model.bin \
--export-path /root/weiyan/serve/model_store \
--handler run_handler.py \
--extra-files "handler.py,config.json,vocab.txt" \
--runtime python3 -f
Encapsulate the command
torch-model-archiver --model-name sbert_tiny4ch --version 1.0 --serialized-file pytorch_model.bin --export-path /root/weiyan/serve/model_store --handler run_handler.py --extra-files "handler.py,config.json,vocab.txt" --runtime python3 -f
stay model-store Folder gets a sbert_tiny4ch.mar file .
4 Deployment model
4.1 start-up torchserve
stay serve Under the table of contents , Create a new folder , Store the configuration file config.properties, Record about the model path and file name .
mkdir Configs
vi sbert_tiny4_config.properties
sbert_tiny4_config.properties
model_store=/root/weiyan/serve/model_store
load_models=sbert_tiny4ch.mar
start-up torchserve
torchserve --ncs --start --ts-config sbert_tiny4_config.properties
Then print out a series of model information

If there is no error in the middle , Then the model deployment is successful .
4.2 Model reasoning
Use the relevant commands to view the model deployment
1.ping Connection status
curl http://localhost:8080/ping
{
"status": "Healthy"
}
2. Model loading
curl http://localhost:8081/models
{
"models": [
{
"modelName": "sbert_tiny4ch",
"modelUrl": "sbert_tiny4ch.mar"
}
]
}
4.3 Semantic similarity reasoning
because SBERT about querys the embeddings expression , So the output of the model is also embeddings, The similarity between the two can be calculated in the above handler.py In file , You can also get the reasoning result, that is embeddings after , Operate again .
Calculate the similarity after selecting here
sbert_tiny4ch.py
import requests
import json
from scipy import spatial
sentences = [' I go skiing '," I'm going skiing "]
data = {
'data':json.dumps({
'queries':sentences})}
print(data)
response = requests.post('http://localhost:8080/predictions/sbert_tiny4ch',data = data)
print(response)
if response.status_code==200:
vectors = response.json()
sim = 1 - (spatial.distance.cosine(vectors[0], vectors[1]))
print(' The similarity is :',sim)
Execute the script
python sbert_tiny4ch.py
Return the similarity result
{
'data': '{"queries": ["\\u4eca\\u5929\\u53bb\\u6ed1\\u96ea", "\\u6211\\u8981\\u53bb\\u6ed1\\u51b0"]}'}
<Response [200]>
The similarity is : 0.9452057554006862
Relevant error reports and solutions
Query results 404
Report errors
{
"code": 404,
"type": "ResourceNotFoundException",
"message": "Requested resource is not found, please refer to API document."
}
reason :
Wrong port used , There are three ports 8080,8081,8082, It's really not good. Try it all .
commonly ,:8080/predictions.
see models Use 8081.
ping Use 8080
Query results 503
prediction error , Generally, there is an error when encapsulating the model and interface , My experience is handler.py Among them process Wrong function , Cause problems in processing data , Naturally, there is no way to return the result of reasoning .
Generally, the models are tested locally before they are deployed online , So make sure there are no errors in the model file itself .
see logs
Running torchserve Under the directory of , Will generate a logs Folder , It automatically saves some logs, among model.logs Save the operation information of the model , Including the above errors Believe in information , You can go back to the log to see , What exactly is wrong with the model .
/tmp/models
Save the latest model file in the folder , That is to say
版权声明
本文为[Weiyaner]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230228265193.html
边栏推荐
- 数仓建表111111
- The 16th day of sprint to the big factory, noip popularization Group Three Kingdoms game
- 假如404页面是这样的 | 每日趣闻
- Heap overflow of kernel PWN basic tutorial
- 程序设计天梯赛 L1-49 天梯赛分配座位(模拟),布响丸辣
- JDBC cannot connect to MySQL, and the error is access denied for user 'root' @ '* * *' (using password: Yes)
- [untitled]
- 智能辅助功能丰富,思皓X6安全配置曝光:将于4月23日预售
- SO库依赖问题
- Niuke hand speed monthly race 48 C (I can't understand the difference. It belongs to yes)
猜你喜欢

Chinese scientists reveal a new mechanism for breaking through the bottleneck of rice yield

How to call out services in idea and display the startup class in services
Open3d point cloud processing

The importance of ERP integration to the improvement of the company's system
89 logistic regression user portrait user response prediction

SQL server2019 cannot download the required files, which may indicate that the version of the installer is no longer supported. What should I do

They are all intelligent in the whole house. What's the difference between aqara and homekit?
hack the box optimum靶机

Halo open source project learning (I): project launch
Rich intelligent auxiliary functions and exposure of Sihao X6 security configuration: it will be pre sold on April 23

随机推荐
PTA: 浪漫倒影 [二叉树重建] [深度优先遍历]
89 logistic regression user portrait user response prediction
SQL server2019 cannot download the required files, which may indicate that the version of the installer is no longer supported. What should I do
程序设计天梯赛 L1-49 天梯赛分配座位(模拟),布响丸辣
JDBC cannot connect to MySQL, and the error is access denied for user 'root' @ '* * *' (using password: Yes)
Dynamic batch processing and static batch processing of unity
Explain JS prototype and prototype chain in detail
MySQL JDBC编程
16、 Anomaly detection
LeetCode 349. Intersection of two arrays (simple, array) Day12
009_ Redis_ Getting started with redistemplate
MySQL C language connection
[XJTU计算机网络安全与管理]第二讲 密码技术
005_redis_set集合
Parental delegation model [understanding]
On LAN
牛客手速月赛 48 C(差分都玩不明白了属于是)
IAR embedded development stm32f103c8t6 Lighting LED
Consider defining a bean of type 'com netflix. discovery. AbstractDiscoveryClientOptionalArgs‘
Numerical remapping method (remap)