当前位置:网站首页>[Data Architecture] Distributed Data Grid as a Solution for Centralized Data Monolith
[Data Architecture] Distributed Data Grid as a Solution for Centralized Data Monolith
2022-08-10 08:59:00 【51CTO】
Enterprise data architects should not build large centralized data platforms, but create distributed data grids.This change in approach requires a paradigm shift, said Zhamak Dehghani, chief technical advisor at ThoughtWorks, in a presentation and related article at QCon in San Francisco.As data becomes more pervasive, traditional data warehouse and data lake architectures become overwhelmed and unable to scale effectively.Dehghani believes that a distributed data grid approach can overcome these inherent inefficiencies by adopting domain-oriented data ownership.
"I propose that the next enterprise data platform architecture is a fusion of distributed domain-driven architecture, self-service platform design, and data product thinking."
Her presentations included some real-world examples, but focused on new management principles, accompanied by new language to support this mindset.For example, service over-ingestion, discovery and usage over-fetching and loading.
Dehghani sees three failure modes in traditional data platform architectures.First, they are centralized and monolithic; bringing all types of data together may work for small organizations, but it will ultimately fail for businesses with a large number of data sources and different data consumers.
Second, there is what Dehghani describes as "coupled pipeline decomposition".Generations of architects have decomposed data platform architecture into "pipelines of data processing steps".These pipeline steps are orthogonal to the axis of change, and new functionality requires updates to all steps.
Isolation and hyper-professional ownership are the ultimate failure modes.A centralized architecture naturally creates categories of data source teams providing data and consumer teams retrieving processed data.In the middle are data and machine learning experts.While the two external groups are domain-oriented, the central team must be domain-agnostic.
![[Data Architecture] Distributed data grid as centralizedThe solution of data-type monolith_artificial intelligence](/img/99/b22268e3e47db9e9caad58722e8709.png "86de3e826b6c5b0edc913d3f50613757.png")
Dehghani compares these challenges to those of an N-layer monolith, where new customer requirements require modification of all layers.Microservices are better aligned with changing elements, but require a different design approach.A similar, dramatic shift in thinking is required to successfully implement a data grid architecture.
"In order to decentralize the overall data platform, we need to reverse our view of data, its location and ownership. Domains do not need to flow data from domains to centrally owned data lakes or platforms, but need to host and serve its domain dataset in an easy-to-consume way."
The envisioned architecture focuses on domain data products as first-class components, each with appropriate ownership by teams that understand the domain.A single, rigid data pipeline is no longer a primary design concern, and data is not clearly divided into source and consumption patterns.Distributed teams are able to use the data they need and can feed their output back into the grid for use by other teams.
For such an architecture to be successful, data products must be discoverable, addressable, trustworthy, self-describing, interoperable, secure, and supported byGlobal access control constraints.These characteristics are the responsibility of individual data product owners, aided by joint governance and platforms that provide the data infrastructure.
![[Data Architecture] Distributed data grid as centralizedSolution for a single data-type data-type_java_02](/img/3d/846fec2760ec1c6f3ff63ad34e842a.png "efe69afe6fcaac15dfb5b021b6f1d3a6.png")
- Image Credit: Zhamak Dehghani
Data warehouses and data lakes can still exist in this architecture, but they are just another node in the grid, not a centralized monolith.If the team still needs the functionality done by the data warehouse and lake, then they should be free to accept it.Likewise, there is a correlation in the adoption of microservices and polyglot solutions.
Dehghani's QCon presentation "The Data Grid Paradigm Shift in Data Platform Architecture" will be released in the coming weeks.Her article "How to Migrate from a Single Data Lake to a Distributed Data Grid" is now available.She will also be a guest on the InfoQ Podcast.
边栏推荐
- ARM Architecture 3: Addressing and Exception Handling of ARM Instructions
- Rust learning: 6.3_ Tuples of composite types
- 【 WeChat applet 】 read page navigation
- [Learn Rust together | Advanced articles | RMQTT library] RMQTT message server - installation and cluster configuration
- Binary tree --- heap
- 多线程浅谈
- 浅析JWT安全问题
- DeepFake换脸诈骗怎么破?让他侧个身
- DAY25: Logic vulnerability recurrence
- js--------对象数组转换成二维数组(excel表格导出)
猜你喜欢







随机推荐
凭借这份阿里架构师的万字面试手册,逆风翻盘,斩获阿里offer
硬件工程师90天学习资料及笔记汇总20220730
J9数字论:关于DAO 特点的宏观分析
J9 Digital Theory: What kind of sparks will Web3.0+ Internet e-commerce cause?
1 活动时间与安排
DAY25: Logic Vulnerability
It is obvious that a unique index is added, why does it still generate duplicate data?
地平线:面向规模化量产的智能驾驶系统和软件开发
【OAuth2】十九、OpenID Connect 动态客户端注册
shell------常用小工具,sort,uniq,tr,cut
硬件工程师90天学习资料及笔记汇总
J9数字论:Web3.0+互联网电商会引起怎样的火花?
并查集学习
[Learn Rust together | Advanced articles | RMQTT library] RMQTT message server - installation and cluster configuration
PTA Exercise 2.1 Simple Calculator
明明加了唯一索引,为什么还是产生重复数据?
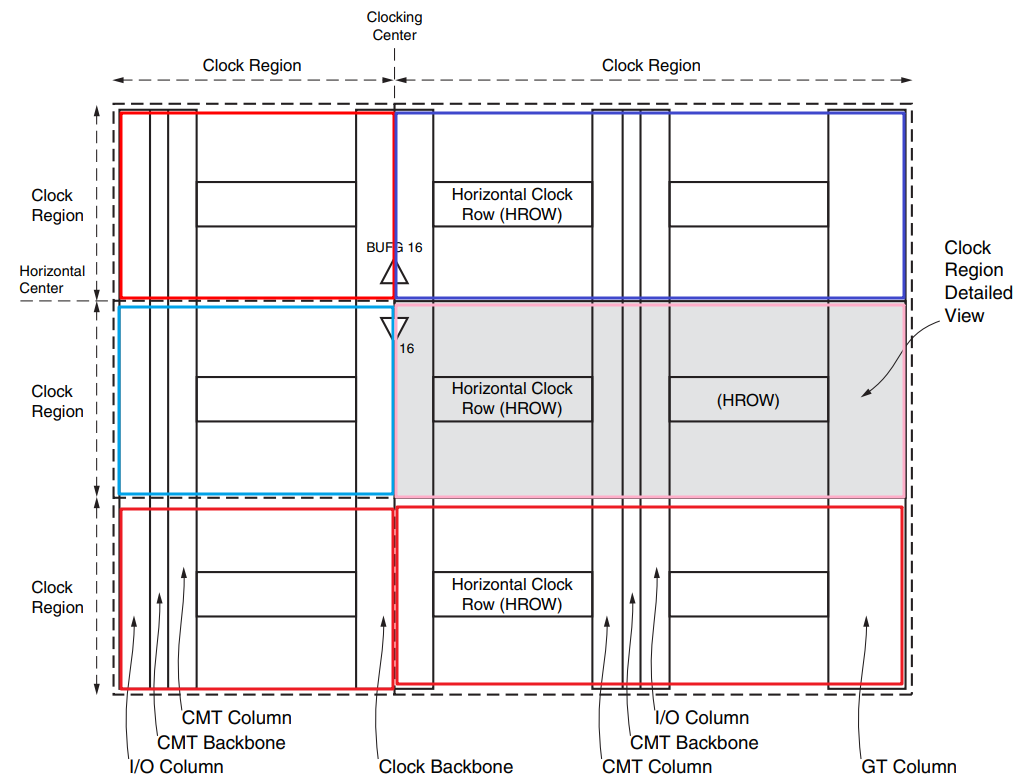
FPGA时钟篇(一) 7系列的时钟结构
Docker搭建Mysql一主一从
Compilation failure:找不到符号
Unity—UGUI control