当前位置:网站首页>基于布朗运动的文本生成方法-LANGUAGE MODELING VIA STOCHASTIC PROCESSES
基于布朗运动的文本生成方法-LANGUAGE MODELING VIA STOCHASTIC PROCESSES
2022-08-09 06:54:00 【just do it now】
标题:LANGUAGE MODELING VIA STOCHASTIC PROCESSES
文章:https://arxiv.org/abs/2203.11370
代码:https://github.com/rosewang2008/language_modeling_via_stochastic_processes
本篇文章可谓是开放域对话的又一开山制作,众所周知,开放域对话是无状态的,不能像任务式对话那样进行状态的追踪,也即不可控性。本文则提出了一种基于布朗桥的文本生成方法,对对话过程进行编码,构建布朗桥来控制对话的过程。
1. 基于布朗桥过程的编码器
首先训练一个编码器,将句子从文本空间X映射到隐空间Z, 记为f:X->Z。在隐空间中的移动轨迹应遵循布朗桥运动。也就是说,该轨迹的起点和终点固定,设为z0和zT则在时间点 t 时, zt 服从以下正态分布:
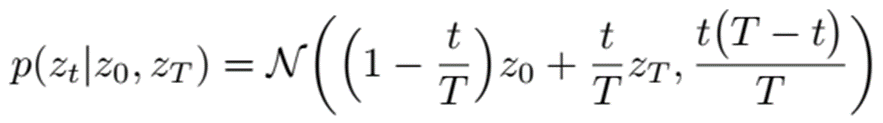
其均值是z0和zT之间随时间变化的线性插值。方差部分,可以直观理解为:在靠起点和终点处方差较小,而中间部分则方差较大(如下图左侧所示)。

- 怎样训练一个编码器来拟合这个过程呢?
对于句子序列,从中随机采样顺序(但未必相邻)的三个句子(x0,xt,xT)优化目标为:使得f(x0)遵循布朗桥运动轨迹。其目标函数可以写为:

可以理解为:使得(x0,xt,xT)更加接近布朗桥过程,而其他负样本三元组与布朗桥过程的差异变大。其中,函数d(.)用于度量编码器预测结果到布朗桥轨迹的距离

2. 基于GPT微调解码器生成
用上述编码器得到隐空间中的布朗桥轨迹后,需要再使用一个解码器,以该轨迹为条件生成对应的文本。对于该解码器的训练,直接对GPT2进行微调。
在 inference 时,给定隐空间起点z0与终点zT,只需随机采样一个两点之间的布朗桥过程,然后用上述解码器进行生成即可,如下图所示:

3. 结果
RQ1:Can Time Control model local text dynamics?
Section 4.1 investigates this question using a sentence ordering prediction task: given two sentences from the same document, we evaluate whether different models can predict their original order.

RQ2: Can Time Control generate locally coherent text?
Section 4.2 investigates this question using the text-infilling task: given prefix and suffix, we evaluate how well different models can fill in between.

RQ3: Can Time Control model global text dynamics?
Section 4.3 investigates this question on text generation for Wikipedia city articles by examining the length of generated sections.

RQ4: Can Time Control generate long coherent documents?
Section 4.4 investigates this question on forced long text generation: we evaluate how well models preserve global text statistics (such as typical section orders and lengths) when forced to extrapolate during generation.


边栏推荐
猜你喜欢
网络学习总结
INSTALL_RPATH and BUILD_RPATH problem in CMake
95后,刚工作2-3年就年薪50W+ ,才发现打败我们的,从来不是年龄···
C语言实现顺序栈和链队列
Fragments
报错:FSADeprecationWarning: SQLALCHEMY_TRACK_MODIFICATIONS adds significant overhead and will be disab
install flask
无重复的字符的最长子串

Teach you how to make the Tanabata meteor shower in C language - elegant and timeless (detailed tutorial)

pycharm环境包导入到另外一个环境
随机推荐
网络学习总结
leetcode 之盛水问题
AD的library中 库文件后缀有.intlib .schlib .pcblib 的区别
AD picture PCB tutorial 20 minutes clear label shop operation process, copper network
分布式事务产生的原因
错误:为 repo ‘oracle_linux_repo‘ 下载元数据失败 : Cannot download repomd.xml: Cannot download repodata/repomd.
力扣第 305 场周赛复盘
高项 03 项目立项管理
Example of using the cut command
事务总结
简单使用Lambda表达式
排序第三节——交换排序(冒泡排序+快速排序+快排的优化)(5个视频讲解)
eyb:Redis学习(2)
XxlJobConfig distributed timer task management XxlJob configuration class, replace
简单工厂模式
找出数组中不重复的值php
codeforces Valera and Elections (这思维题是做不明白了)
pycharm环境包导入到另外一个环境
95后,刚工作2-3年就年薪50W+ ,才发现打败我们的,从来不是年龄···
长沙学院2022暑假训练赛(一)六级阅读