当前位置:网站首页>【Verilog数字系统设计(夏雨闻)6-------模块的结构、数据类型、变量和基本运算符号2】
【Verilog数字系统设计(夏雨闻)6-------模块的结构、数据类型、变量和基本运算符号2】
2022-08-10 03:16:00 【周猿猿】
Verilog HDL中总共有19种数据类型。数据类型是用来表示数字电路硬件中的数据储存和传送元素的。先介绍4个最基本的数据类型,它们是:
reg型、wire型、integer型和parameter型
其他数据类型包括:large型、medium型、scalared型、time型、small型、tri型、trio型、tril型、triand型、trior型、 trireg型、vectored型、wand型和wor型。这14种数据类型除time型外都与基本逻辑单元建库有关,与系统设计没有很大的关系。
在一般电路设计自动化的环境下,仿真用的基本部件库是由半导体厂家和EDA工具厂家共同提供的。系统设计工程师不必过多地关心门级和开关级的VerilogHDL语法现象。
常量
在程序运行过程中,其值不能被改变的量称为常量。下面首先对在VerilogHDL语言中 使用的数字及其表示方式进行介绍。
数字
(1) 整数在Verilog HDL中,整型常量即整常数有以下4种进制表示形式:
- 二进制整数(b或B);
2)十进制整数(d或D); - 十六进制整数(h或H);
4)八进制整数(o或O)。
数字表达方式有以下3种:
1)<位宽><进制><数字>,这是一种全面的描述方式。
2)在<进制><数字>这种描述方式中,数字的位宽采用默认位宽(这由具体的机器系统决定,但至少32位)。
3)在<数字>这种描述方式中,采用默认进制(十进制)。
在表达式中,位宽指明了数字的精确位数。例如:一个4位二进制数的数字的位宽为4,一个4位十六进制数数字的位宽为16(因为每单个十六进制数就要用4位二进制数来表示)。
见下例:
8'b10101100 //位宽为8的数的二进制表示,'b表示二进制
8'ha2 //位宽为8的数的十六进制表示,'h表示十六进制
(2) X 和z值 在数字电路中 ,x代表不定值,z代表高阻值。 一个x可以用来定义十六进制数的4位二进制数的状态,八进制数的3位,二进制数的1位。 z 的表示方式同 x 类似 。 z 还有一种表达方式是可以写作“ ?”。 在使用 case 表达式时建议使用这种写法 ,以提高程序的可读性。 见下例:
4'b10x0 / / 位宽为4的二进制数从低位数起笫2位为不定值
4'b101z // 位宽为4的二进制数从低位数起第1位为高阻值
12'dz // 位宽为12的十进制数,其值为高阻值(第1种表达方式)
12'd? //位宽为12的十进制数,其值为高阻值(第2种表达方式)
8'h4x //位宽为8的十六进制数,其低4位值为不定值
(3) 负数 一个数字可以被定义为负数,只需在位宽表达式前加一个减号 ,减号必须写在数字定义表达式的最前面 。
注意 : 减号不可以放在位宽和进制之间 ,也不可以放在进制和具体的数之间 。 见下例:
-8 'd5 //这个表达式代表5的补数(用八位二进制数表示)
8'd-5 //非法格式
(4) 下画线 (underscore_) 下画线可以用来分隔开数的表达以提高程序可读性。 它不可以用在位宽和进制处 , 只能用在具体的数字之间 。 见下例:
16'b1010_1011_1111_1010 //合法格式
8'b_0011_1010 //非法格式
当常量不说明位数时,默认值是 32 位,每个字母用 8 位的 ASCII 值表示。 例:
10= 32'd10= 32'b1010
1 = 32'd1 = 32'b1
-1 = -32'd1 = 32'h FFFFFFFF
'BX = 32'BX = 32'BXXXXXXX---X
"AB" = 16'B01000001_01000010 //字符串AB,为十六进制数16'h4142
参数型
在 Verilog HDL 中用 parameter来定义常量 , 即用 parameter来定义一个标识符代表一个常量 ,称为符号常量, 即标识符形式的常量,采用标识符代表一个常量可提高程序的可读性和可维护性 。 parameter型数据是一种常数型的数据,其说明格式如下:
parameter 参数名1=表达式, 参数名2= 表达式,……,参数名n= 表达式;
parameter是参数型数据的确认符。 确认符后跟着一个用逗号分隔开的赋值语句表。 在 每一个赋值语句的右边必须是一个常数表达式。 也就是说,该表达式只能包含数字或先前已定义过的参数。 见下列:
parameter msb= 7; // 定义参数msb为常量7
parameter e=25, f=29; //定义两个常数参数
parameter r= 5. 7; //声明r为一个实型参数
parameter byte_size= 8, byte...:msb= byte_size-1; //用常数表达式赋值
arameter average_delay = (r十f)/2; //用常数表达式赋值
参数型常数经常用于定义延迟时间和变量宽度。在模块或实例引用时,可通过参数传递改变在被引用模块或实例中已定义的参数。下面将通过两个例子进一步说明在层次调用的电路中改变参数常用的一些用法。
【例3.1】模块Decode定义时用了两个参数类型变量:Width和Polarity,且都为1。在 Top模块中引用Decode实例时,可通过参数的传递来改变定义时已规定的参数值。即通过# (4,0),实例D1实际引用的是参数Width和Polarity分别为4与0时的Decode模块;通过# (5),实例D2实际引用的是参数Width为5,而Polarity仍为1时的Decode模块。这种利用参数编写模块的方法使得已编写的底层模块具有更大的灵活性。参数常用在表示门级模型的延迟,因此可通过参数传递表示不同的延迟。
moudule Decode(A,F);
parameter Width = 1, Polarity = 1;
....
endmodule
module Top;
wire[3:0] A4;
wire[4:0] A5;
wire[15:0] F16;
wire[31:0] F32;
Decode #(4,0) D1(A4,F16);
Decode #(5) D2(A5,F32);
endmodule
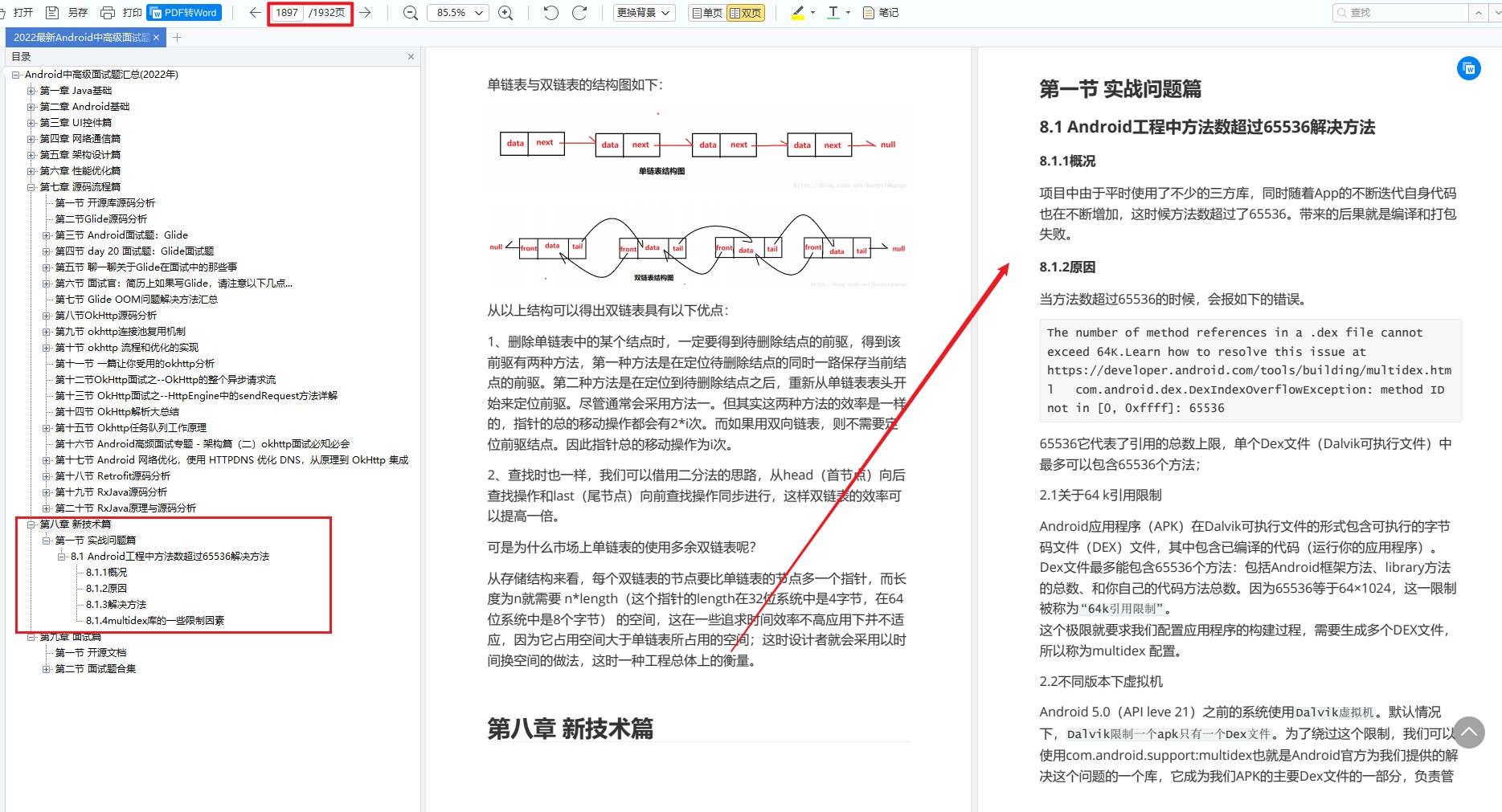
【例3.2】下面是一个由多层次模块构成的电路(见图3.2)。在一个模块中改变另一个模块的参数时,需要使用defparam命令。在做布线后仿真时,就是利用这种方法把布线延迟通过布线工具生成的延迟参数文件反标注(Back-annotate)到门级Verilog网表上。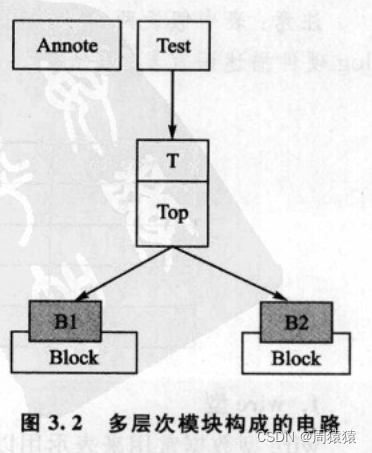
在模块Annotate中定义的参数值2和3可以通过模块Test中,经实例T对模块Top的引用,而在模块Top中,实例B1和B2对模块Block的引用,分别将参数值2和3传递到模块Block中用参数定义的地方(即原来在模块Block中定义的P=0,在实例B1和B2中分别被P=2和P=3替代)。
'include "Top.v"
'include "Block.v"
'include "Annotate.v"
module Test;
wire W;
Tpp T();
endmodule
module Top;
wire W;
Block B1();
Block B2();
endmodule
module Block;
Parameter P=0;
endmodule
module Annotate
defparam
Test.T.B1.P = 2,
Test.T.B2.P = 3;
endmodule
变量
变量是一种在程序运行过程中其值可以改变的址,在 Verilog HDL 中变最的数据类型有很多种,这里只对常用的几种进行介绍。
网络数据类型表示结构实体(例如门)之间的物理连接。 网络类型的变址不能储存值,而且它必须受到驱动器(例如门或连续赋值语句, assign) 的驱动 。 如果没有驱动器连接到网络类型的变量上,则该变量就是高阻的,即其值为 z。 常用的网络数据类型包括 wire 型和 tri 型。 这两种变量都是用于连接器件单元,它们具有相同的语法格式和功能。 之所以提供这两种名字来表达相同的概念,其目的是为了与模型中所使用的变量的实际情况相一致。 wire 型变世通常是用来表示单个门驱动或连续赋值语句驱动的网络型数据,tri 型变量则用来表示多驱动器驱动的网络型数据。 如果 wire 型或 tri 型变量没有定义逻辑强度(logic strength) ,在多驱动源的情况下,逻辑值会发生冲突 ,从而产生不确定值。 表 3. 1 为 wire 型和 tri 型变量的真值表。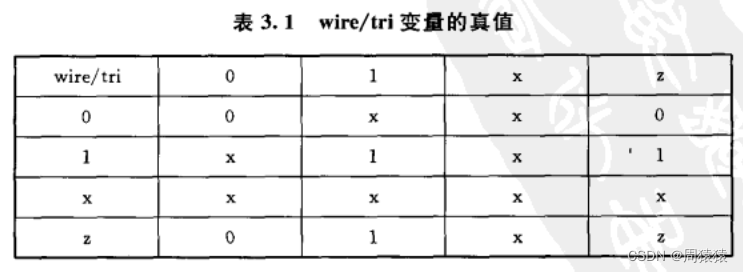
wire型
wire 型数据常用来表示用以 assign 关键字指定的组合逻辑信号。Verilog 程序模块中输入、输出信号类型默认时自动定义为wire型。wire型信号可以用做任何方程式的输入 , 也可以用做“assign“语句或实例元件的输出 。
wire型信号的格式同reg型信号的格式很类似。 其格式如下:
wire [n-1:0]数据名1 ,数据名2,…数据名i; //共有i条总线,每条总线内有n条线路 , 或wire [n, 1]数据名1 ,数据名2,…数据名i 。
wire是wire型数据的确认符; [n-1:0]和[n,1]代表该数据的位宽 , 即该数据有几位;最后跟着的是数据的名字。如果一次定义多个数据,数据名之间用逗号隔开。 声明语句的最后要用分号表示语句结束。看下面的几个例子:
wire a; //定义了一个1位的wire型数据
wire [7:0] b; //定义了一个8位的wire型数据
wire [4:1] c,d ; //定义了二个4位的wire型数据
reg型
寄存器是数据储存单元的抽象。 寄存器数据类型的关键字是 reg。 通过赋值语句可以改变寄存器储存的值,其作用与改变触发器储存的值相当。 Verilog HDL语言提供了功能强大的结构语句,使设计者能有效地控制是否执行这些赋值语句。 这些控制结构用来描述硬件触发条件 ,例如时钟的上升沿和多路器的选通信号。 在行为模块介绍这一节中 ,还要详细地介绍这些控制结构。 reg类型数据的默认初始值为不定值x。
reg型数据常用来表示“always“模块内的指定信号,常代表触发器。 通常,在设计中要由 "always“模块通过使用行为描述语句来表达逻辑关系 。 在“always“模块内被赋值的每一个信号都必须定义成reg型。
reg型数据的格式如下:
reg [n-1:0] 数据名1,数据名2,...,数据名i;
或
reg [n:1] 数据名1,数据名2,...,数据名i;
reg是reg型数据的确认标识符; [n -1:0]和[n: 1]代表该数据的位宽 , 即该数据有几位(bit) ;最后跟着的是数据的名字。 如果一次定义多个数据,数据名之间用逗号隔开。 声明语句的最后要用分号表示语句结束。 看下面的几个例子:
reg rega; //定义了一个1位的名为 rega 的 reg 型数据
reg [3,0] regb; //定义了一个 4 位的名为 regb 的 reg 型数据
reg [ 4 : 1] regc, regd; //定义了二个 4 位的名为 regc 和 regd 的 reg 型数据
对于reg型数据,其赋值语句的作用就如同改变一组触发器的存储单元的值。 在Verilog 中有许多构造(construct)用来控制何时或是否执行这些赋值语句。 这些控制构造可用来描述 硬件触发器的各种具体情况,如触发条件时用时钟的上升沿,或用来描述判断逻辑的细节,如 各种多路选择器。
reg型数据的默认初始值是不定值。 reg型数据可以赋正值, 也可以赋负值。 但当一个 reg型数据是一个表达式中的操作数时,它的值被当作是无符号值,即正值。 例如 , 当一个 4位的寄存器用做表达式中的操作数时,如果开始寄存器被赋以值-1,则在表达式中进行运算时,其值被认为是+15。
memory型
Verilog HDL 通过对 reg型变量建立数组来对存储器建模,可以描述RAM型存储器、ROM存储器和 reg 文件。 数组中的每一个单元通过 一个数组索引进行寻址 。 在 Verilog 语言中没有多维数组存在。 memory 型数据是通过扩展 reg 型数据的地址范围来生成的。 其格式如下:
reg [n-1:0] 存储器名[m-1,0];
或
reg [n:1] 存储器名[m:1];
在这里 , reg[n-1:0]定义了存储器中每一个存储单元的大小, 即该存储单元是一个 n 位 的寄存器;存储器名后的[m-1:0]或[m:1]则定义了该存储器中有多少个这样的寄存器; 最 后用分号结束定义语句。 下面举例说明:
reg [7:0] mema[255,0];
这个例子定义了一个名为 mema 的存储器,该存储器有 256 个 8 位的存储器。 该存储器 的地址范围是 0 到 255。
另外 , 在同一个数据类型声明语句里,可以同时定义存储器型数据和 reg 型数据。 见下例:
parameter wordsize= 16, //定义两个参数
memsize= 256;
reg [ wordsize-1:0] mem[memsize-1:0], writereg, readreg,
尽管memory 型数据和 reg型数据的定义格式很相似,但要注意其不同之处。 如一个由 n 个1位寄存器构成的存储器组是不同于一个 n 位的寄存器的。 见下例:
reg [n-1:0] rega; // 一个n位的寄存器
reg mema [n-1,0]; // 一个由n个1位寄存器构成的存储器组
一个 n 位的寄存器可以在一条赋值语句里进行赋值, 而一个完整的存储器则不行。 见下例:
rega =0; //合法赋值语句
mema =0; // 非法赋值语句
如果想对 memory 中的存储单元进行读写操作,必须指定该单元在存储器中的地址。 下面的写法是正确的:
mema[3]=0; //给 memory 中的第 3 个存储单元赋值为 0
进行寻址的地址索引可以是表达式,这样就可以对存储器中的不同单元进行操作。 表达式的值可以取决于电路中其他的寄存器的值。 例如可以用一个加法计数器来做RAM的 地址索引。
边栏推荐
- netstat和ss命令区别
- Example 043: Scope, class methods and variables
- 电子产品结构设计中的电磁兼容性(EMC)设计
- Dijkstra求最短路
- It's almost 35, still "did a little"?What happened to the test workers who had been in the industry for a few years?
- Camera partial update
- Mini Program Navigation and Navigation Parameters
- 量化投资学习——在FPGA上运行高频交易策略
- vite基础,vite中 `@`符号是不被支持,不用@符号,直接用层级(./,../等)
- NFG电商系统在元宇宙趋势下做什么?
猜你喜欢






随机推荐
Day16 charles的基本使用
Shell 文本三剑客 awk
【2022河南萌新联赛第(五)场:信息工程大学】【部分思路题解+代码解析】
三极管开关电路参数设计与参数介绍
嵌入式分享合集32
Flink CDC 2.0及其他数据同步工具对比
Dynamic Web Development Fundamentals
【IO复用】poll
zabbix添加监控主机和自定义监控项
@Autowired注解 --required a single bean, but 2 were found出现的原因以及解决方法
如何快速成为一名软件测试工程师?测试员月薪15k需要什么技术?
从8k到13k,我全靠这本《接口自动化测试——从入门到精通》
Classes and interfaces
ARP欺骗-教程详解
有关视频传输时粘包问题的一些解决方法
charles的功能操作
当我操作dms客户端的时候,我要操控好几个阿里云账号下的数据库,但是这边每次切换都会把我的登录记录删
Little rookie Hebei Unicom induction training essay
js原型和原型链以及原型继承
树的介绍、树的定义和基本术语、二叉树的定义和性质、二叉树的顺序表示与实现和链式表示与实现以及树的遍历方法以及两种创建方式