当前位置:网站首页>一站制造项目及Spark核心面试 ,220808,,,
一站制造项目及Spark核心面试 ,220808,,,
2022-08-09 07:06:00 【啊六六六】


 RANGE BETWEEN
RANGE BETWEEN
row BETWEEN
用到了默认的windowframe

比率求值,




直接用where datediff( nlogindate-logindate)=n-1来判断也ok吧?
set开启本地模式,dg,
每个用户最大连续登陆次数




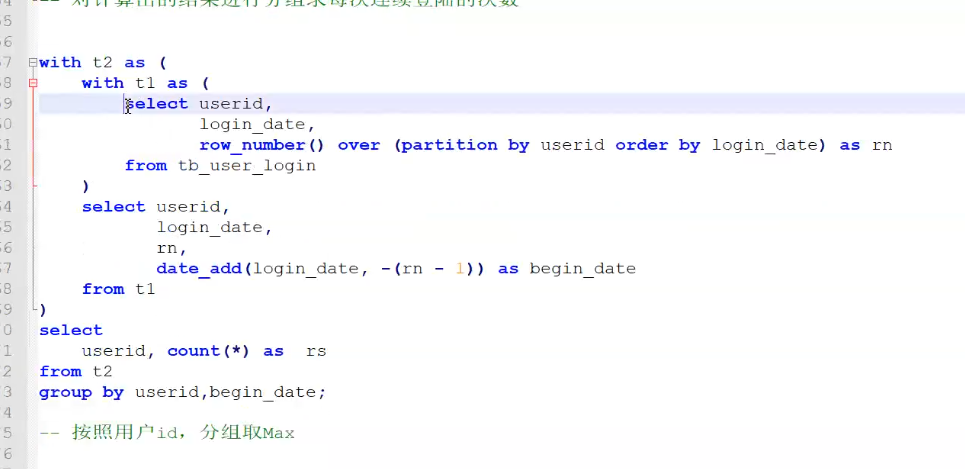

![]() ,
,
多看多练,规律sql题,,经验积累,,
把主讲的项目,写到最新日期吗?
对的,
项目时间 逆序放,
RDD设计类似于Hive中表



返回值是不是一个RDD

reduce 触发
reduceByKey 转换


日志下载,放在hdfs,historyserver下,映射,,
![]()
driver只会在,客户端/从节点
每个stage中最后一个rdd的分区数
Stage中最后一个或者最小RDD分区数

1-Spark不是纯内存式计算,Shuffle过程依旧是使用磁盘的
2-只要是计算,都是基于内存计算
3-Spark积极使用内存,窄依赖都在内存中完成、允许内存中缓存RDD,相比MR,大部分的中间结果都是在内存中直接传递的
Wordcount代码是唯一一个面试中写的代码
Wordcount SQL,DSL,RDD算子代码,怎么写????

举例子,设计个程序,spark资源管理???




reduceByKey、foldByKey,map端聚合,

![]()
设计谓词下推例子???



重新写代码,要么原有的上面修改,,
两年前:构建平台、平台产出价值
新需求:更好的管理,挖掘更多价值


RANGE BETWEEN???
row BETWEEN???

Wordcount SQL,DSL,RDD算子代码,怎么写????
![]()
设计谓词下推例子???
产品表(100万),商品详情表名称(10万),
SET hive.optimize.ppd=true,先过滤再join
(明天问老师??) spark set开启本地模式属性,dg,
边栏推荐
猜你喜欢






随机推荐
sklearn数据预处理
2017 G icpc shenyang Infinite Fraction Path BFS + pruning
The Integer thread safe
rsync:recv_generator: mkdir (in backup) failed:Permission denied (13) |failed to set times on '.'
当酷雷曼VR直播遇上视频号,会摩擦出怎样的火花?
Lottie系列二:高级属性
分布式id 生成器实现
2017icpc沈阳 G Infinite Fraction Path BFS+剪枝
常见的分布式事务解决方案
Unity first lesson
【sqlite3】sqlite3.OperationalError: table addresses has 7 columns but 6 values were supplied
SIGINT, SIGKILL, SIGTERM signal difference, summary of various signals
TCP段重组PDU
高德地图JS - 已知经纬度来获取街道、城市、详细地址等信息
Quectel EC20 4G module dial related
Important news丨.NET Core 3.1 will end support on December 13 this year
Better Scroll Y上下滚动无法上拉滚动解决办法
codeforces Valera and Elections (这思维题是做不明白了)
mysql 总结
SSL证书最长有效期13个月,还有必要一次申请多年吗?