当前位置:网站首页>轻量级网络(一):MobileNet V1,V2, V3系列
轻量级网络(一):MobileNet V1,V2, V3系列
2022-08-11 08:11:00 【陶将】
轻量级网络(一):MobileNet V1,V2, V3系列
文章目录
在实际应用中,不仅要关注模型的精度,还需要关注模型的速度。在既要精度又要速度的考量中,轻量化网络应运而生。轻量级网络拥有不差于笨重模型的性能,但相比于笨重模型,有更少的参数和计算量,对硬件更友好。轻量级网络发展至今,已经涌现了SqueezeNet系列,MobileNet系列,ShuffleNet系列,EfficientNet等等系列。这篇文章仅仅阐述MobileNet从V1到V3的发展历程。
MobileNet V1
MobileNet V1版本的主要创新点在于将标准卷积替换为深度可分离卷积。深度可分离卷积相比于标准卷积,能够有效地减少计算量和模型参数。如下表所示,使用深度可分离卷积的MobileNet,相比于使用标准卷积的MobileNet,在ImageNet数据集上的精度下降了1.1%,但是模型参数减少了约7倍,加乘计算量减少了约9倍。
卷积计算量
标准卷积
假设一个标准卷积的输入特征图 F F F为 D F × D F × M D_{F} \times D_{F} \times M DF×DF×M,输出特征图 G G G为 D F × D F × N D_{F} \times D_{F} \times N DF×DF×N,其中是 D F D_{F} DF表示特征图的宽和高, M M M和 N N N是特征图的通道数目。假设卷积核为 K K K,尺寸为 D K × D K × M × N D_{K} \times D_{K} \times M \times N DK×DK×M×N,其中 D K D_{K} DK是卷积核宽和高。
那么一个标准的卷积运算,stride设为1,padding使得输出特征图长宽和输入特征图一样,那么标准卷积的计算量 D K ⋅ D K ⋅ M ⋅ N ⋅ D F ⋅ D F D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F} DK⋅DK⋅M⋅N⋅DF⋅DF
深度可分卷积
深度可分卷积(depthwise separable convolution )是一种可分解卷积形式,它将标准卷积分解为一个**深度卷积(depthwise convolution)**和一个 1 × 1 1 \times 1 1×1卷积,其中 1 × 1 1 \times 1 1×1卷积被称为pointwise convolution。深度卷积的filters尺寸大小为 D K × D K × 1 × M D_{K} \times D_{K} \times 1 \times M DK×DK×1×M,它在每一个输入通道上应用一个单独的fliter,pointwise convolution利用 1 × 1 1 \times 1 1×1卷积将深度卷积的输出通道融合起来。这样分解,能够有效地减少计算量和减少模型大小。
假设一个深度可分卷积的输入特征图为 D F × D F × M D_{F} \times D_{F} \times M DF×DF×M,其输出特征图为 D F × D F × M D_{F} \times D_{F} \times M DF×DF×M,其中是 D F D_{F} DF表示特征图的宽和高, M M M和 N N N是特征图的通道数目。
- 深度卷积: 卷积核为 D K × D K × 1 × M D_{K} \times D_{K} \times 1 \times M DK×DK×1×M,那么输出特征图大小为 D F × D F × M D_{F} \times D_{F} \times M DF×DF×M。
- 1*1卷积:卷积核为 1 × 1 × M × N 1 \times 1 \times M \times N 1×1×M×N,最后的输出为 D F × D F × M D_{F} \times D_{F} \times M DF×DF×M。
深度可分卷积的计算量是深度卷积和pointwise convolution的计算量之和,为 D K ⋅ D K ⋅ M ⋅ D F ⋅ D F + M ⋅ N ⋅ D F ⋅ D F D_{K} \cdot D_{K} \cdot M \cdot D_{F} \cdot D_{F} + M \cdot N \cdot D_{F} \cdot D_{F} DK⋅DK⋅M⋅DF⋅DF+M⋅N⋅DF⋅DF。
下述公式计算深度可分卷积的计算量和标准卷积的计算量的比率,可以看出深度可分卷积是标准卷积的 1 N + 1 D K 2 \frac{1}{N} + \frac{1}{D_{K}^{2}} N1+DK21。一般情况下,卷积核大小为 3 × 3 3 \times 3 3×3,为 D K 2 = 9 D_{K}^{2} = 9 DK2=9,卷积核的通道数 N N N的取值一般会大于9,那么 1 N + 1 D K 2 > 1 9 \frac{1}{N} + \frac{1}{D_{K}^{2}} > \frac{1}{9} N1+DK21>91。
深度可分卷积 标准卷积 = D K ⋅ D K ⋅ M ⋅ D F ⋅ D F + M ⋅ N ⋅ D F ⋅ D F D K ⋅ D K ⋅ M ⋅ N ⋅ D F ⋅ D F = 1 N + 1 D K 2 \frac{深度可分卷积}{标准卷积}=\frac{D_{K} \cdot D_{K} \cdot M \cdot D_{F} \cdot D_{F} + M \cdot N \cdot D_{F} \cdot D_{F}}{D_{K} \cdot D_{K} \cdot M \cdot N \cdot D_{F} \cdot D_{F}}= \frac{1}{N} + \frac{1}{D_{K}^{2}} 标准卷积深度可分卷积=DK⋅DK⋅M⋅N⋅DF⋅DFDK⋅DK⋅M⋅DF⋅DF+M⋅N⋅DF⋅DF=N1+DK21
MobileNet V1的网络架构图如下所示: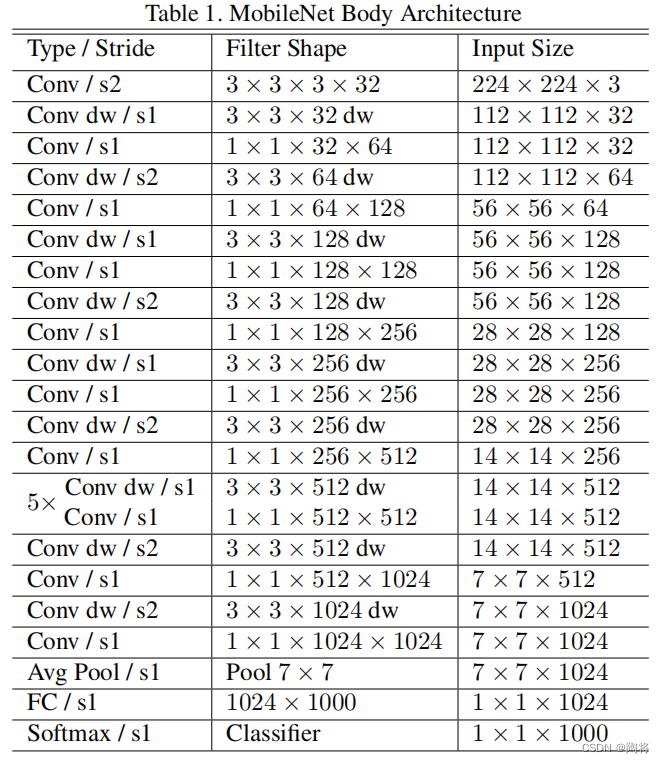
模型瘦身
从上述深度可分卷积和标准卷积计算量的对比,我们发现MobileNet架构相比于其他卷积网络结构具有较少的参数和计算量,但是仍然有很多场景需要更小更快的模型。为了得到更小的模型,论文里面引入两个超参,宽度倍增器(width multiplier, α \alpha α)和分辨率倍增器(Resolution Multiplier, ρ \rho ρ),对模型进行瘦身。宽度倍增器作用的是每层的通道数,分辨率倍增器作用的是输入图像的分辨率大小。
宽度倍增器
α \alpha α被称为宽度倍增器(width multiplier),作用是对网络瘦身。对于某一层,定义宽度倍增器 α \alpha α,那么输入通道数 M M M则变成 α M \alpha M αM,输出通道数 N N N将变成 α N \alpha N αN。 α ∈ ( 0 , 1 ] \alpha \in \left(0, 1 \right] α∈(0,1],一般取 1 , 0.75 , 0.5 , 0.25 1, 0.75, 0.5 , 0.25 1,0.75,0.5,0.25,当时 α = 1 \alpha =1 α=1是基础版MobileNet,当 α < 1 \alpha < 1 α<1时是缩减版mobileNet。缩减后的深度可分卷积的计算量如下公式所示,计算量缩减了 α 2 \alpha^{2} α2倍。
D K ⋅ D K ⋅ α M ⋅ D F ⋅ D F + α M ⋅ α N ⋅ D F ⋅ D F D_{K} \cdot D_{K} \cdot \alpha M \cdot D_{F} \cdot D_{F} + \alpha M \cdot \alpha N \cdot D_{F} \cdot D_{F} DK⋅DK⋅αM⋅DF⋅DF+αM⋅αN⋅DF⋅DF
分辨率倍增器
ρ \rho ρ被称为分辨率倍增器(Resolution Multiplier),输入大小增大/缩小 ρ \rho ρ倍,那么网络中的每一层也随之增大/缩小 ρ \rho ρ倍。 ρ ∈ ( 0 , 1 ] \rho \in \left(0, 1 \right] ρ∈(0,1],网络的输入分辨率一般取 224 , 192 , 160 , 128 224, 192, 160 , 128 224,192,160,128。当时 ρ = 1 \rho =1 ρ=1为基础版MobileNet,当 ρ < 1 \rho < 1 ρ<1时为缩减版mobileNet。缩减后的深度可分卷积的计算量如下公式所示,可见计算量缩减了 ρ 2 \rho^{2} ρ2倍。
D K ⋅ D K ⋅ α M ⋅ ρ D F ⋅ ρ D F + α M ⋅ α N ⋅ ρ D F ⋅ ρ D F D_{K} \cdot D_{K} \cdot \alpha M \cdot \rho D_{F} \cdot \rho D_{F} + \alpha M \cdot \alpha N \cdot \rho D_{F} \cdot \rho D_{F} DK⋅DK⋅αM⋅ρDF⋅ρDF+αM⋅αN⋅ρDF⋅ρDF
MobileNet V2
MobileNet V2 的创新点在于带有线性瓶颈的反残差模块( the inverted residual with linear bottleneck)。在论文中,作者发现在低维空间使用非线性函数会损失一些信息,但在高维空间,损失相对少一些。因此,引入反残差(Inverted Residuals)的概念,先升维再做卷积,相对能够较好地保存特征。升维会增加计算量,因此需要降维,又因为非线性会损失信息,所以采用线性的方式进行降维,被称为线性瓶颈(Linear Bottlenecks)。
Bottleneck residual block
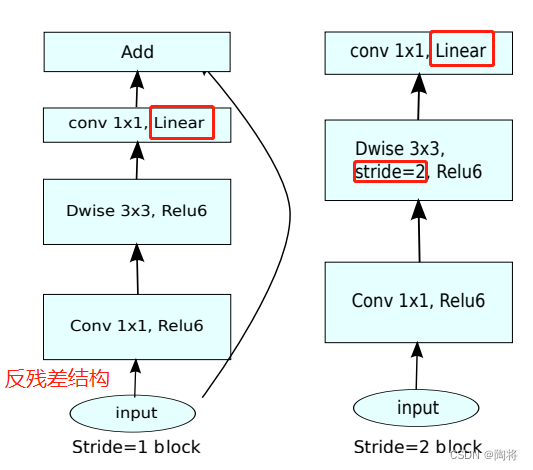
MobileNetV2和MobileNetV1相比,如上图所示,保留了深度卷积和 1 × 1 1 \times 1 1×1卷积,增加了 1 ∗ 1 1*1 1∗1卷积的线性层,MobileNet V2的基础组件称为Bottleneck residual block。不过 1 × 1 1 \times 1 1×1卷积是在输入之后,深度卷积之前,目的是为了扩张维度。实验验证,使用 1 × 1 1 \times 1 1×1线性卷积的目的是为了阻止非线性破坏过多的信息。strides为1时,借鉴残差结构,不过不同于残差结构通道数的先降后升,MobileNetV2则是先升通道后降通道数。
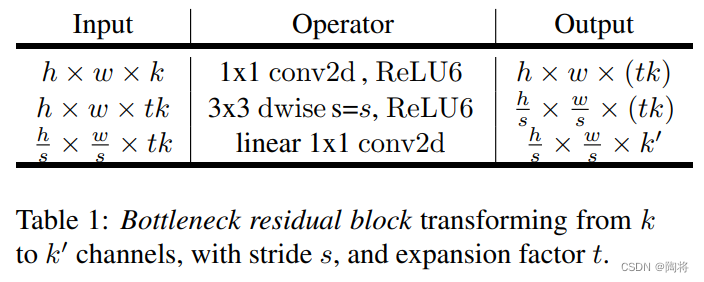
假设输入特征图大小为 h × w × k h \times w \times k h×w×k,首先经过一个 1 × 1 1 \times 1 1×1大小的卷积,输出特征图的大小为 h × w × ( t k ) h \times w \times \left(tk\right) h×w×(tk),其中 t t t是膨胀系数,MobileNet V2网络架构中取 t = 6 t=6 t=6。随后紧接一个 3 × 3 3 \times 3 3×3大小的卷积,步数为 s s s,输出特征图大小为 h s × w s × ( t k ) \frac{h}{s} \times \frac{w}{s} \times \left( tk \right) sh×sw×(tk),最后经过一个 1 × 1 1 \times 1 1×1大小的线性卷积,得到最后的输出,输出特征图大小为 h × w × k ′ h \times w \times {k}' h×w×k′。
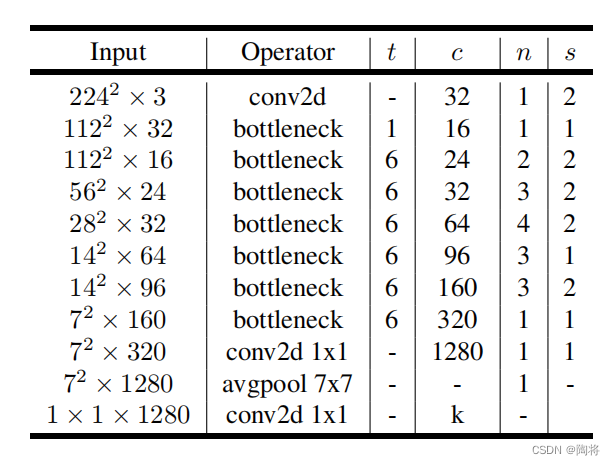
模型架构
MobileNet V2的网络架构如下图所示,其实 t t t为膨胀系数, c c c是通道数, n n n是重复次数, s s s是步数。
MobileNet V3
MnasNet在MobileNet V2 Bottleneck block的基础上加入SE模块引入轻量级注意力,如上图所示,为了将注意力应用到最大表示上,SE模块用在膨胀的深度可分卷积后。MobileNet V3网络架构中包括MnasNet和MobileNet V2基础块。
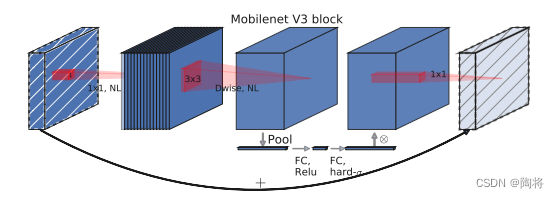
MobileNet V3网络架构的构造包含两个步骤:首先,由platform-aware NAS和NetAdapt算法复合网络搜索搜索基本架构;然后再引入几个新组件改进模型性能,形成最终模型。platform-aware NAS通过优化每一个网络块搜索全局网络结构,NetAdapt算法搜索每一层的filter数量。MobileNet V3中引入了一个新的非线性函数,h-swish(swish的改进版),它能够更快阶段,并且量化更友好。MobileNet V3 在保持准确率的前提下,重新设计了计算昂贵的网络开端和末端层,减少延迟。这个具体见论文。
s w i s h x = x ⋅ σ ( x ) h − s w i s h [ x ] = s R e L U 6 ( x + 3 ) 6 swish \; x = x \cdot \sigma \left( x \right) \\ h-swish\left[ x \right] = s \frac{ReLU6\left( x + 3 \right)}{6} swishx=x⋅σ(x)h−swish[x]=s6ReLU6(x+3)
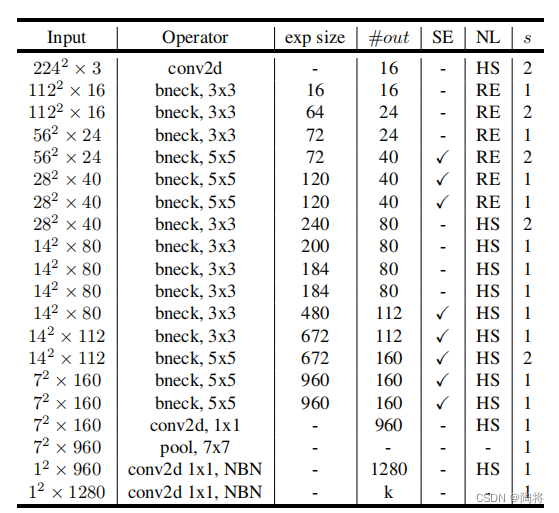
MobileNet V3有两个模型:MobileNetV3-Large 和 MobileNetV3-Small。大小模型的网络结构分表如下表所示,它们分别针对高和低资源用例。其中SE表示在block中是否包括Squee-And-Excite。NL是非线性类型,其中HS表示h-swish,RE表示ReLU。NBN表示没有BN操作。
MobileNetV3-Large网络结构如下所示:
MobileNet V3 small网络结构如下所示: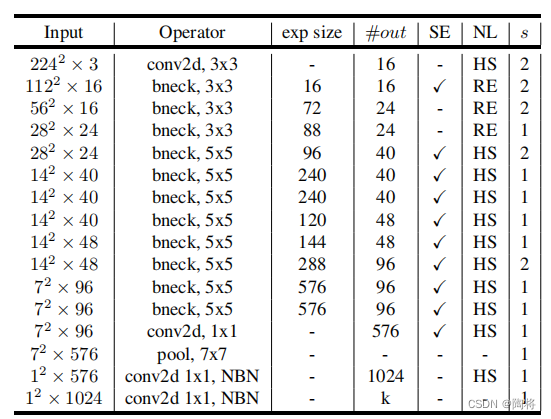
MobileNet V1,V2,V3对比
以下是MobileNetV1-V3各网络在ImageNet-1k上的top-1精度和参数两对比。
| Network | Top-p1 | Params |
|---|---|---|
| MobileNetV1 | 70.6 | 4.2M |
| MobileNetV2 | 72.0 | 3.4M |
| MobileNetV2(1.4) | 74.7 | 6.9M |
| MobileNetV3-Large(1.0) | 75.2 | 5.4M |
| MobileNetV3-Large(0.75) | 73.3 | 4.0M |
| MobileNetV3-Small(1.0) | 67.4 | 2.5M |
| MobileNetV3-Small(0.75) | 65.4 | 2.0M |
参考
边栏推荐
- 4.1ROS运行管理/launch文件
- 记录一些遇见的bug——Lombok和Mapstruct的冲突导致,A component required a bean of type ‘com.XXX.controller.converter.
- 一根网线两台电脑传输文件
- leetcode: 69. Square root of x
- Redis source code-String: Redis String command, Redis String storage principle, three encoding types of Redis string, Redis String SDS source code analysis, Redis String application scenarios
- FPGA 20个例程篇:11.USB2.0接收并回复CRC16位校验
- The easiest trick to support quick renaming of various files
- 优炫数据库支持多列分区吗?
- Distributed Lock-Redission - Cache Consistency Solution
- Redis source code: how to view the Redis source code, the order of viewing the Redis source code, the sequence of the source code from the external data structure of Redis to the internal data structu
猜你喜欢



随机推荐
【LeetCode】链表题解汇总
软件测试常用工具的用途及优缺点比较(详细)
Hibernate 的 Session 缓存相关操作
Redis source code-String: Redis String command, Redis String storage principle, three encoding types of Redis string, Redis String SDS source code analysis, Redis String application scenarios
Kotlin算法入门计算质因数
Pico neo3 Unity Packaging Settings
Kotlin算法入门计算素数以及优化
JRS303-Data Verification
[Recommender System]: Overview of Collaborative Filtering and Content-Based Filtering
Find the latest staff salary and the last staff salary changes
迷你图书馆系统(对象+数组)
进阶-指针
The easiest trick to support quick renaming of various files
go sqlx 包
C Primer Plus(6) 中文版 第1章 初识C语言 1.1 C语言的起源 1.2 选择C语言的理由 1.3 C语言的应用范围
leetcode: 69. Square root of x
支持各种文件快速重命名最简单的小技巧
About # SQL problem: how to set the following data by commas into multiple lines, in the form of column display
Swagger简单使用
借问变量何处存,牧童笑称用指针,Go lang1.18入门精炼教程,由白丁入鸿儒,go lang类型指针(Pointer)的使用EP05