当前位置:网站首页>Share some unknown and super easy-to-use API functions in sklearn module
Share some unknown and super easy-to-use API functions in sklearn module
2022-04-22 10:11:00 【AI technology base】

author | Junxin
source | About data analysis and visualization
I believe that for many machine learning enthusiasts , Training models 、 Verify the performance of the model, etc. generally sklearn Some functions and methods in the module , Today, Xiaobian will talk to you about the less well-known in this module API, Not many people may know , But it's very easy to use .
Extreme value detection
There are extreme values in the data set , This is a very normal phenomenon , There are also many extreme value detection algorithms on the market , and sklearn Medium EllipticalEnvelope The algorithm is worth trying , It is especially good at detecting extreme values in data sets satisfying normal distribution , The code is as follows
import numpy as np
from sklearn.covariance import EllipticEnvelope
# Randomly generate some false data
X = np.random.normal(loc=5, scale=2, size=100).reshape(-1, 1)
# Fitting data
ee = EllipticEnvelope(random_state=0)
_ = ee.fit(X)
# New test set
test = np.array([6, 8, 30, 4, 5, 6, 10, 15, 30, 3]).reshape(-1, 1)
# Predict which extreme values are
ee.predict(test)output
array([ 1, 1, -1, 1, 1, 1, -1, -1, -1, 1])In predicting which data are extreme results , In the end “-1” Corresponding to the extreme value , That is to say 30、10、15、30 These results
Feature screening (RFE)
In modeling , We screened out important features , about Reduce the risk of over fitting as well as Reduce the complexity of the model Are of great help .Sklearn Recursive feature elimination algorithm in module (RFE) It can achieve the above purpose very effectively , Its main idea is to return through the learner coef_ Property or feature_importance_ Attribute to get the importance of each feature . Then remove the least important feature from the current feature set . In the rest of the feature set Keep repeating this step of recursion , Until the required number of features is reached .
Let's take a look at the following sample code
from sklearn.datasets import make_regression
from sklearn.feature_selection import RFECV
from sklearn.linear_model import Ridge
# Randomly generate some false data
X, y = make_regression(n_samples=10000, n_features=20, n_informative=10)
# New learner
rfecv = RFECV(estimator=Ridge(), cv=5)
_ = rfecv.fit(X, y)
rfecv.transform(X).shapeoutput
(10000, 10) We use Ridge() The regression algorithm is a learner , By means of cross validation, the 10 A redundant feature , Retain other important features .
Drawing of decision tree
I believe that for many machine learning enthusiasts , The decision tree algorithm is familiar , If we can chart it at the same time , You can more intuitively understand its principle and context , Let's take a look at the following example code
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier, plot_tree
import matplotlib.pyplot as plt
%matplotlib inline
# New dataset , The decision tree algorithm is used for fitting training
df = load_iris()
X, y = iris.data, iris.target
clf = DecisionTreeClassifier()
clf = clf.fit(X, y)
# Charting
plt.figure(figsize=(12, 8), dpi=200)
plot_tree(clf, feature_names=df.feature_names,
class_names=df.target_names);output

HuberRegressor Return to
If there are extreme values in the data set, the performance of the finally trained model will be greatly reduced , In most cases , We can find these extreme values through some algorithms and remove them , Of course, there is also an introduction here HuberRegressor Regression algorithm provides us with another idea , Its treatment of extreme values is to give these extreme values when training and fitting Less weight , In the middle of epsilon The parameter to control should be the number of extreme values , The more obvious the value, the stronger the robustness to extreme values . Please see the following picture for details
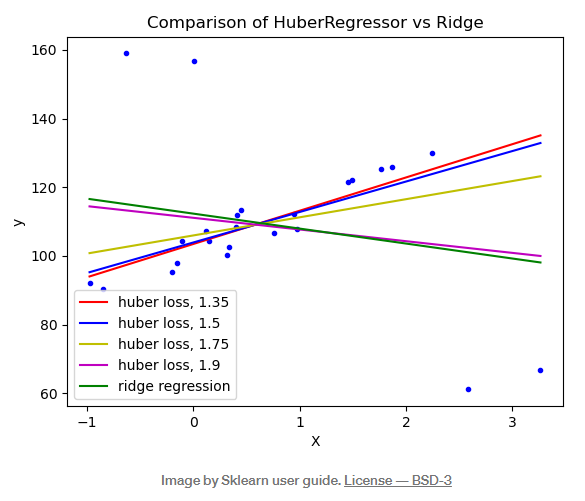
When epsilon The value is equal to the 1.35、1.5 as well as 1.75 When , The interference from extreme values is relatively small . The specific use method and parameter description of the algorithm can refer to its official document .
https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.HuberRegressor.html
Feature screening SelectFromModel
Another feature filtering algorithm is SelectFromModel, Different from the recursive feature elimination method mentioned above to screen features , It is used more in the case of large amount of data, because it has Lower computing costs , As long as the model has feature_importance_ Property or coef_ Properties can be similar to SelectFromModel Algorithm compatible , The sample code is as follows
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import ExtraTreesRegressor
# Randomly generate some false data
X, y = make_regression(n_samples=int(1e4), n_features=50, n_informative=15)
# Initialize model
selector = SelectFromModel(estimator=ExtraTreesRegressor()).fit(X, y)
# Screen out important models
selector.transform(X).shapeoutput
(10000, 9)
Go to
period
return
Gu
technology
Powerful Gensim The library is used for NLP Text analysis
information
Classmate he is on the hot search again , Why this time ?
technology
This paper introduces an exploratory plug-in for efficiency burst meter
technology
use Python Building a speech synthesis system

Share

Point collection

A little bit of praise

Click to see
版权声明
本文为[AI technology base]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204220958589606.html
边栏推荐
- IOS development - Database - Introduction to basic knowledge (01)
- Beyond iterm! Known as the next generation terminal artifact, powerful!
- Nacos
- linux7静默安装oracle11g
- SQL 数据库
- SQL 关系型数据库管理系统
- [SQL Server] SQL overview
- Memory management-
- 二极管工作原理
- Beyond iterm! Known as the next generation terminal artifact, I can't put it down after using it!
猜你喜欢







随机推荐
L2-033 简单计算器 (25 分)
leetcode771. 宝石与石头
作文以记之 ~ 目标和
[moistening C language] Beginner - start from scratch - 5 (modular design - function, value transmission and address transmission)
最通俗易懂的依赖注入之服务容器与作用域
Nacos
Android被爆安全漏洞 根源是苹果的无损音频编解码器
Memory management-
自学编程千万别再傻傻地读理论书,程序员:这都是别人玩剩下的
获取浏览器网址 地址
Shell gets random number and echo - E '\ 033 [word background color; font color M string \ 033 [0m'
SQL 数据类型
Cloud leopard intelligence, a DPU chip head enterprise, joined the openeuler community to help Digital China infrastructure
Review of QT layout management
oracle19. 3 upgrade to 19.6
UVC camera 封装类
You need to specify one of MySQL_ ROOT_ PASSWORD, MYSQL_ ALLOW_ EMPTY_ PASSWORD and MYSQ
TextView设置指定字符显示颜色
【SQL server】SQL 概览
openEuler Kernel 技术解读 | 内核中断子系统介绍