当前位置:网站首页>Depth deterministic strategy gradient (ddpg)
Depth deterministic strategy gradient (ddpg)
2022-04-23 02:56:00 【Live up to your youth】
Basic concepts
Discrete action & Continuous action
Discrete actions are actions that can be classified , For example, go to 、 Next 、 Left 、 Right 、 Jump and so on , Generally, multi classification activation function is used softmax These actions mean . If there are only two actions , You can use sigmoid Activation function .
A continuous action is a continuous value , Like speed 、 angle 、 Force, etc. denote the exact value . Continuous action is not classifiable , Generally, activation functions of return value type are used to represent them , such as tanh function .

Pictured , If we want to use reinforcement learning to train a strategy to control the manipulator , The upper shaft can be in [0, 2 π \pi π] Turn between , The lower axis can be in [0, π \pi π] Turn between , Then its action space will be a multi-dimensional continuous space .
DDPG
DQN The algorithm uses neural networks to approximate the representation of Q- function , Successfully solved the problem of high-dimensional state space . however DQN Can only handle discrete 、 Low dimensional action space , For many in life, there is continuity 、 Control tasks in high-dimensional action space ,DQN Unable to deal with .
DDPG The algorithm is proposed to solve such a problem , You can be DQN An improved version of the algorithm . stay DQN in , use ϵ − g r e e d y \epsilon-greedy ϵ−greedy Strategy or Boltzamann Distribute strategies to select actions a; and DDPG A neural network is used to fit the strategy function , Direct output action a, It can deal with the output of continuous action and high-dimensional action space . therefore ,DDPG It can be regarded as a continuous action space DQN.
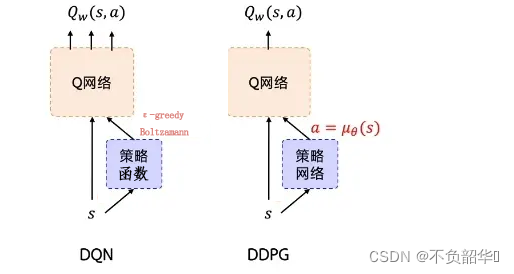
DDPG The training process is as follows , Be similar to DQN,DDPG Added policy network (Actor).DDPG It has two parts , A strategic network (Actor), A value network (Critic). Strategy network output action , Value networks judge actions . Both have their own ways to update information . The strategy network is updated by gradient calculation formula , And the value network is updated according to the target value .DDPG Update and of value network DQN similar , Here is the update of the policy network in detail .

Strategy gradient formula :

This formula is easy to understand , For example, for the same state , We output two different actions a1 and a2, Two feedback results are obtained from the state estimation network Q value , Namely Q1 and Q2, hypothesis Q1>Q2, Take action a1 You can get more rewards . So what is the idea of a strategy gradient ? Is to increase a1 Probability , Reduce a2 Probability , in other words ,Actor I want to get as big as possible Q value . So our Actor Loss can be simply interpreted as feedback Q The greater the value, the smaller the loss , Feedback received Q The smaller the value, the greater the loss .
DDPG The algorithm is as follows :

版权声明
本文为[Live up to your youth]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204220657127089.html
边栏推荐
- 重大危险源企业如何保障年底前完成双预防机制数字化建设任务
- The interface request takes too long. Jstack observes the lock holding
- Face longitude:
- Specific field information of MySQL export table (detailed operation of Navicat client)
- 《信息系统项目管理师总结》第六章 项目人力资源管理
- Essential qualities of advanced programmers
- Winsock programming interface experiment: implementation of ipconfig
- 基于Scrum进行创新和管理
- 《信息系统项目管理师总结》第四章 项目成本管理
- Shell learning notes -- shell processing of output stream awk
猜你喜欢

L2-006 树的遍历(中后序确定二叉树&层序遍历)
![Niuke white moon race 5 [problem solving mathematics field]](/img/be/ca059bd1c84eaaaefa3266f9119a6b.png)
Niuke white moon race 5 [problem solving mathematics field]

windows MySQL8 zip安装

Those years can not do math problems, using pyhon only takes 1 minute?
BLDC double closed loop (speed PI + current PI) Simulink simulation model
![[wechat applet] set the bottom menu (tabbar) for the applet](/img/e2/98711dfb1350599cbdbdf13508b84f.png)
[wechat applet] set the bottom menu (tabbar) for the applet
【Hcip】OSPF常用的6种LSA详解
Configuring Apache Web services for servers such as Tianyi cloud

Opencv fills the rectangle with a transparent color
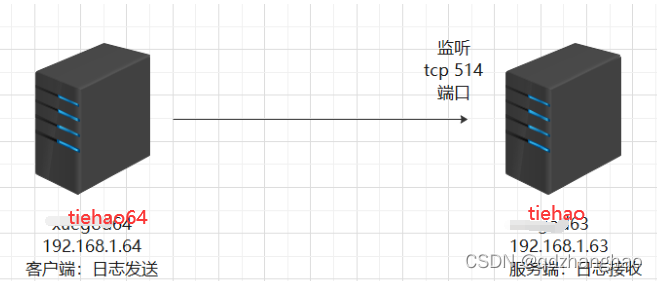
Log cutting - build a remote log collection server
随机推荐
Traversal of l2-006 tree (middle and later order determination binary tree & sequence traversal)
The usage of case when and select case when is very easy to use
Airtrack cracking wireless network password (Dictionary running method)
【Hcip】OSPF常用的6种LSA详解
Domestic lightweight Kanban scrum agile project management tool
Guangcheng cloud service can fill in a daily report regularly every day
Linux redis - redis ha sentinel cluster construction details & redis master-slave deployment
机器学习(周志华) 第十四章概率图模型
Get together to watch (detailed version) eat a few cents a day
Kubernetes - detailed explanation of pod
VirtualBox virtual machine (Oracle VM)
JZ35 replication of complex linked list
L2-006 树的遍历(中后序确定二叉树&层序遍历)
Gavl021, gavl281, AC220V to 5v200ma small volume non isolated chip scheme
If MySQL / SQL server judges that the table or temporary table exists, it will be deleted
The way to conquer C language
Niuke white moon race 5 [problem solving mathematics field]
Interim summary (Introduction + application layer + transportation layer)
Difference between relative path and absolute path (often asked in interview)
Regular object type conversion tool - Common DOM class