当前位置:网站首页>Dolphin scheduler integrates Flink task pit records
Dolphin scheduler integrates Flink task pit records
2022-04-23 13:42:00 【Ruo Xiaoyu】
1、 About Flink pack
flink The task is finished , After the local operation and debugging are normal , I pack and submit to Dolphinscheduler Platform to test . An error is reported shortly after the operation :
[taskAppId=TASK-10-108-214]:[138] - -> java.lang.NoClassDefFoundError: org/apache/flink/streaming/connectors/kafka/FlinkKafkaConsumer
at com.bigdata.flink.FlinkKafka.main(FlinkKafka.java:30)
Caused by: java.lang.ClassNotFoundException: org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer

Look at the log details , We can see that the task is ready to submit , But I can't find it in the environment FlinkKafkaConsumer.
flink run -m yarn-cluster -ys 1 -yjm 1G -ytm 2G -yqu default -p 1 -sae -c com.bigdata.flink.FlinkKafka flink-job/bigdata-flink.jar
My way of packing is through IDEA Menu Build Artfacts… Hit the jar The file is very small , And the dependency package has not been hit .
So I changed my way :
- To configure pom file
<build>
<!--<pluginManagement>-->
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<version>1.8</version>
<executions>
<execution>
<id>add-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>src/main/scala</source>
<source>src/test/scala</source>
</sources>
</configuration>
</execution>
<execution>
<id>add-test-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-test-source</goal>
</goals>
<configuration>
<sources>
<source>src/test/scala</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.1.5</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>2.11.8</scalaVersion>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>utf-8</encoding>
</configuration>
<executions>
<execution>
<phase>compile</phase>
<goals>
<goal>compile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<appendAssemblyId>false</appendAssemblyId>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!-- It is specified here that main Method entrance class -->
<mainClass>com.bigdata.flink.FlinkKafka</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>assembly</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
<!--</pluginManagement>-->
</build>
- perform maven Under the package command ; You can see the results of this packaging method jar The package contains the required dependent packages .
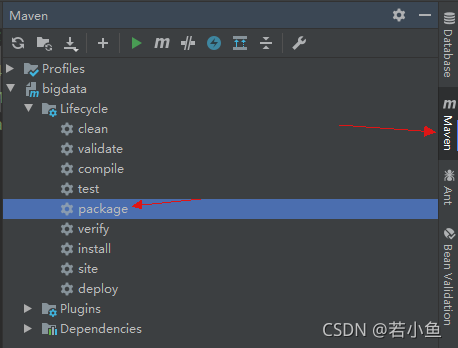
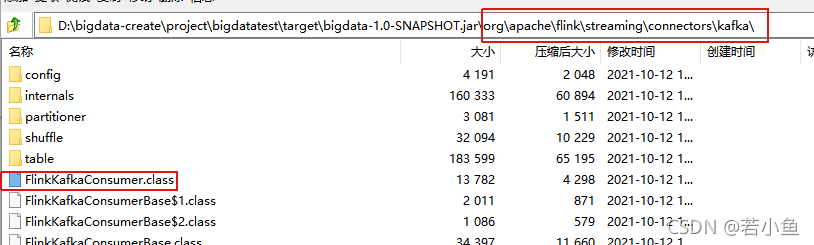
2、HADOOP_CLASSPATH Environment variable configuration
After the problem of environmental dependence is solved , In the process of implementation, there is HADOOP_CLASSPATH Error reporting of environment variables .
taskAppId=TASK-10-112-218]:[138] - ->
------------------------------------------------------------
The program finished with the following exception:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment" section of the official Apache Flink documentation.
at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:372)
at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222)
at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:114)
at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:812)
at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:246)
at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1054)
at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1132)
at org.apache.flink.runtime.security.contexts.NoOpSecurityContext.runSecured(NoOpSecurityContext.java:28)
at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1132)
Caused by: java.lang.IllegalStateException: No Executor found. Please make sure to export the HADOOP_CLASSPATH environment variable or have hadoop in your classpath. For more information refer to the "Deployment" section of the official Apache Flink documentation.
It needs to be revised this time worker nodal flink file .
- find flink/bin/flink file
- Add... To the first line
export HADOOP_CLASSPATH=`hadoop classpath`
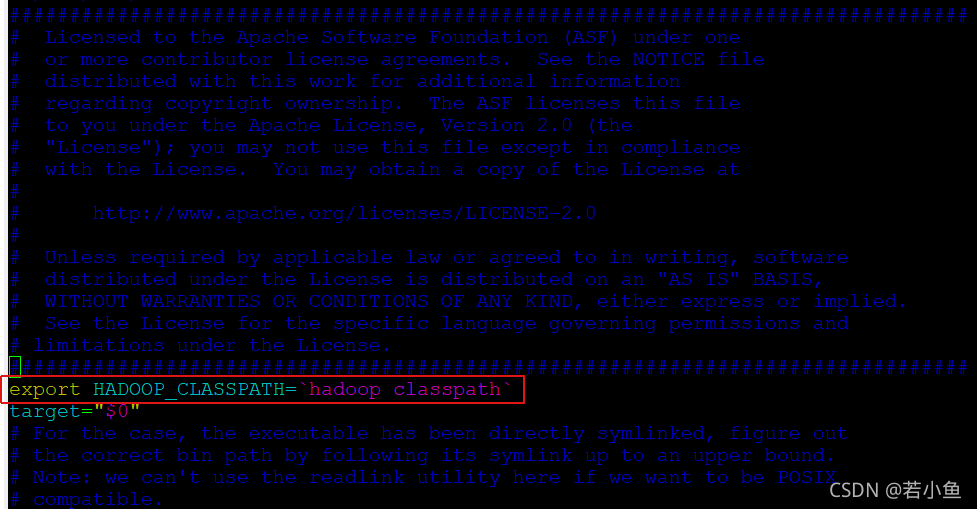
- There is no need to restart the cluster machine , Direct rerun flink The task is just .
版权声明
本文为[Ruo Xiaoyu]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230602186560.html
边栏推荐
- Cross carbon market and Web3 to achieve renewable transformation
- 爱可可AI前沿推介 (4.23)
- TIA博途中基於高速計數器觸發中斷OB40實現定點加工動作的具體方法示例
- torch. Where can transfer gradient
- Utilisation de GDB
- @Excellent you! CSDN College Club President Recruitment!
- innobackupex增量备份
- Window function row commonly used for fusion and de duplication_ number
- Set Jianyun x Feishu Shennuo to help the enterprise operation Department realize office automation
- MySQL5. 5 installation tutorial
猜你喜欢
![[point cloud series] Introduction to scene recognition](/img/1f/c64712b03ae5b235b5dd3347c3e86a.png)
[point cloud series] Introduction to scene recognition

@Excellent you! CSDN College Club President Recruitment!

SAP ui5 application development tutorial 72 - animation effect setting of SAP ui5 page routing

Machine learning -- PCA and LDA

AI21 Labs | Standing on the Shoulders of Giant Frozen Language Models(站在巨大的冷冻语言模型的肩膀上)
【视频】线性回归中的贝叶斯推断与R语言预测工人工资数据|数据分享

TIA博途中基於高速計數器觸發中斷OB40實現定點加工動作的具體方法示例

Campus takeout system - "nongzhibang" wechat native cloud development applet

联想拯救者Y9000X 2020

Android clear app cache
随机推荐
Core concepts of microservice architecture
Xi'an CSDN signed a contract with Xi'an Siyuan University, opening a new chapter in IT talent training
innobackupex增量备份
SHA512 / 384 principle and C language implementation (with source code)
Oracle database combines the query result sets of multiple columns into one row
Oracle and MySQL batch query all table names and table name comments under users
爱可可AI前沿推介 (4.23)
Window analysis function last_ VALUE,FIRST_ VALUE,lag,lead
[point cloud series] full revolutionary geometric features
AI21 Labs | Standing on the Shoulders of Giant Frozen Language Models(站在巨大的冷冻语言模型的肩膀上)
Filter and listener of three web components
The interviewer dug a hole for me: how many concurrent TCP connections can a single server have?
联想拯救者Y9000X 2020
Example interview | sun Guanghao: College Club grows and starts a business with me
[Journal Conference Series] IEEE series template download guide
Super 40W bonus pool waiting for you to fight! The second "Changsha bank Cup" Tencent yunqi innovation competition is hot!
Oracle view related
零拷贝技术
Error 403 in most cases, you or one of your dependencies are requesting
[point cloud series] multi view neural human rendering (NHR)