当前位置:网站首页>八股文之并发编程
八股文之并发编程
2022-08-11 05:35:00 【geekmice】
多线程创建方式(重点)
继承Thread类
(1)创建一个类继承Thread类,重写run()方法,将所要完成的任务代码写进run()方法中;
(2)创建Thread类的子类的对象;
(3)调用该对象的start()方法,该start()方法表示先开启线程,然后调用run()方法;
public class MyThread extends Thread {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " run()方法正在执行...");
}
}
public class TheadTest {
public static void main(String[] args) {
MyThread myThread = new MyThread();
myThread.start();
System.out.println(Thread.currentThread().getName() + " main()方法执行结束");
}
}
运行结果
main main()方法执行结束
Thread-0 run()方法正在执行...
实现runnable接口
(1)创建一个类并实现Runnable接口
(2)重写run()方法,将所要完成的任务代码写进run()方法中
(3)创建实现Runnable接口的类的对象,将该对象当做Thread类的构造方法中的参数传进去
(4)使用Thread类的构造方法创建一个对象,并调用start()方法即可运行该线程
public class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " run()方法执行中...");
}
}
public class RunnableTest {
public static void main(String[] args) {
MyRunnable myRunnable = new MyRunnable();
Thread thread = new Thread(myRunnable);
thread.start();
System.out.println(Thread.currentThread().getName() + " main()方法执行完成");
}
}
执行结果
main main()方法执行完成
Thread-0 run()方法执行中...
实现Callable接口
(1)创建一个类并实现Callable接口
(2)重写call()方法,将所要完成的任务的代码写进call()方法中,需要注意的是call()方法有返回值,并且可以抛异常
(3)如果想要获取运行该线程后的返回值,需要创建Future接口的实现类的对象,即FutureTask类的对象,调用该对象的get()方法可获取call()方法的返回值
(4)使用Thread类的有参构造器创建对象,将FutureTask类的对象当做参数传进去,然后调用start()方法开启并运行该线程。
public class MyCallable implements Callable<Integer> {
@Override
public Integer call() {
System.out.println(Thread.currentThread().getName() + " call()方法执行中...");
return 1;
}
}
public class CallableTest {
public static void main(String[] args) {
FutureTask<Integer> futureTask = new FutureTask<Integer>(new MyCallable());
Thread thread = new Thread(futureTask);
thread.start();
try {
Thread.sleep(1000);
System.out.println("返回结果 " + futureTask.get());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName() + " main()方法执行完成");
}
}
执行结果
Thread-0 call()方法执行中...
返回结果 1
main main()方法执行完成
使用线程池创建
(1)使用Executors类中的newFixedThreadPool(int num)方法创建一个线程数量为num的线程池
(2)调用线程池中的execute()方法执行由实现Runnable接口创建的线程;调用submit()方法执行由实现Callable接口创建的线程
(3)调用线程池中的shutdown()方法关闭线程池
public class MyRunnable implements Runnable {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " run()方法执行中...");
}
}
public class SingleThreadExecutorTest {
public static void main(String[] args) {
ExecutorService executorService = Executors.newSingleThreadExecutor();
MyRunnable runnableTest = new MyRunnable();
for (int i = 0; i < 5; i++) {
executorService.execute(runnableTest);
}
System.out.println("线程任务开始执行");
executorService.shutdown();
}
}
执行结果
线程任务开始执行
pool-1-thread-1 is running...
pool-1-thread-1 is running...
pool-1-thread-1 is running...
pool-1-thread-1 is running...
pool-1-thread-1 is running...
说一下 runnable 和 callable 有什么区别?
Runnable 接口 run 方法无返回值;Callable 接口 call 方法有返回值,是个泛型,和Future、FutureTask配合可以用来获取异步执行的结果
Runnable 接口 run 方法只能抛出运行时异常,且无法捕获处理;Callable 接口 call 方法允许抛出异常,可以获取异常信息
线程的 run()和 start()有什么区别?
每个线程都是通过某个特定Thread对象所对应的方法run()来完成其操作的,run()方法称为线程体。通过调用Thread类的start()方法来启动一个线程。
start() 方法用于启动线程,run() 方法用于执行线程的运行时代码。run() 可以重复调用,而 start() 只能调用一次。
start()方法来启动一个线程,真正实现了多线程运行。调用start()方法无需等待run方法体代码执行完毕,可以直接继续执行其他的代码; 此时线程是处于就绪状态,并没有运行。 然后通过此Thread类调用方法run()来完成其运行状态, run()方法运行结束, 此线程终止。然后CPU再调度其它线程。
run()方法是在本线程里的,只是线程里的一个函数,而不是多线程的。 如果直接调用run(),其实就相当于是调用了一个普通函数而已,直接待用run()方法必须等待run()方法执行完毕才能执行下面的代码,所以执行路径还是只有一条,根本就没有线程的特征,所以在多线程执行时要使用start()方法而不是run()方法。
为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
new 一个 Thread,线程进入了新建状态。调用 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。
而直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
总结: 调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。
什么是线程池?有哪几种创建方式?
在面向对象编程中,创建和销毁对象是很费时间的,因为创建一个对象要获取内存资源或者其它更多资源。在 Java 中更是如此,虚拟机将试图跟踪每一个对象,以便能够在对象销毁后进行垃圾回收。所以提高服务程序效率的一个手段就是尽可能减少创建和销毁对象的次数,特别是一些很耗资源的对象创建和销毁,这就是”池化资源”技术产生的原因。
线程池顾名思义就是事先创建若干个可执行的线程放入一个池(容器)中,需要的时候从池中获取线程不用自行创建,使用完毕不需要销毁线程而是放回池中,从而减少创建和销毁线程对象的开销。Java 5+中的 Executor 接口定义一个执行线程的工具。它的子类型即线程池接口是 ExecutorService。要配置一个线程池是比较复杂的,尤其是对于线程池的原理不是很清楚的情况下,因此在工具类 Executors 面提供了一些静态工厂方法,生成一些常用的线程池,如下所示:
(1)newSingleThreadExecutor:创建一个单线程的线程池。这个线程池只有一个线程在工作,也就是相当于单线程串行执行所有任务。如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它。此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
(2)newFixedThreadPool:创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。如果希望在服务器上使用线程池,建议使用 newFixedThreadPool方法来创建线程池,这样能获得更好的性能。
(3) newCachedThreadPool:创建一个可缓存的线程池。如果线程池的大小超过了处理任务所需要的线程,那么就会回收部分空闲(60 秒不执行任务)的线程,当任务数增加时,此线程池又可以智能的添加新线程来处理任务。此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说 JVM)能够创建的最大线程大小。
(4)newScheduledThreadPool:创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求。
线程池有什么优点
降低资源消耗:重用存在的线程,减少对象创建销毁的开销。
提高响应速度。可有效的控制最大并发线程数,提高系统资源的使用率,同时避免过多资源竞争,避免堵塞。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
附加功能:提供定时执行、定期执行、单线程、并发数控制等功能。
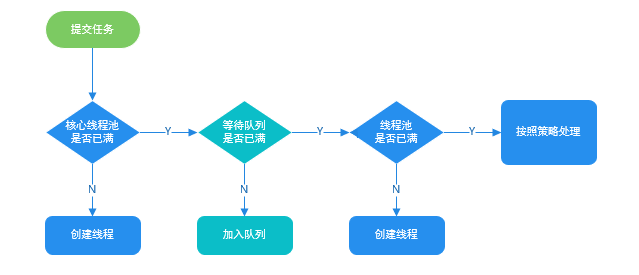
线程池ThreadPoolExecutor构造函数重要参数分析(重点)
ThreadPoolExecutor 3 个最重要的参数:
corePoolSize :核心线程数,线程数定义了最小可以同时运行的线程数量。
maximumPoolSize :线程池中允许存在的工作线程的最大数量
workQueue:当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,任务就会被存放在队列中。
ThreadPoolExecutor其他常见参数:
keepAliveTime:线程池中的线程数量大于 corePoolSize 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 keepAliveTime才会被回收销毁;
unit :keepAliveTime 参数的时间单位。
threadFactory:为线程池提供创建新线程的线程工厂
handler :线程池任务队列超过 maxinumPoolSize 之后的拒绝策略
线程池demo理解
import java.util.Date;
/** * 这是一个简单的Runnable类,需要大约5秒钟来执行其任务。 */
public class MyRunnable implements Runnable {
private String command;
public MyRunnable(String s) {
this.command = s;
}
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
processCommand();
System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
}
private void processCommand() {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
@Override
public String toString() {
return this.command;
}
}
编写测试程序,我们这里以阿里巴巴推荐的使用 ThreadPoolExecutor 构造函数自定义参数的方式来创建线程池。
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorDemo {
private static final int CORE_POOL_SIZE = 5;
private static final int MAX_POOL_SIZE = 10;
private static final int QUEUE_CAPACITY = 100;
private static final Long KEEP_ALIVE_TIME = 1L;
public static void main(String[] args) {
//使用阿里巴巴推荐的创建线程池的方式
//通过ThreadPoolExecutor构造函数自定义参数创建
ThreadPoolExecutor executor = new ThreadPoolExecutor(
CORE_POOL_SIZE,
MAX_POOL_SIZE,
KEEP_ALIVE_TIME,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < 10; i++) {
//创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
Runnable worker = new MyRunnable("" + i);
//执行Runnable
executor.execute(worker);
}
//终止线程池
executor.shutdown();
while (!executor.isTerminated()) {
}
System.out.println("Finished all threads");
}
}
corePoolSize: 核心线程数为 5。
maximumPoolSize :最大线程数 10
keepAliveTime : 等待时间为 1L。
unit: 等待时间的单位为 TimeUnit.SECONDS。
workQueue:任务队列为 ArrayBlockingQueue,并且容量为 100;
handler:饱和策略为 CallerRunsPolicy。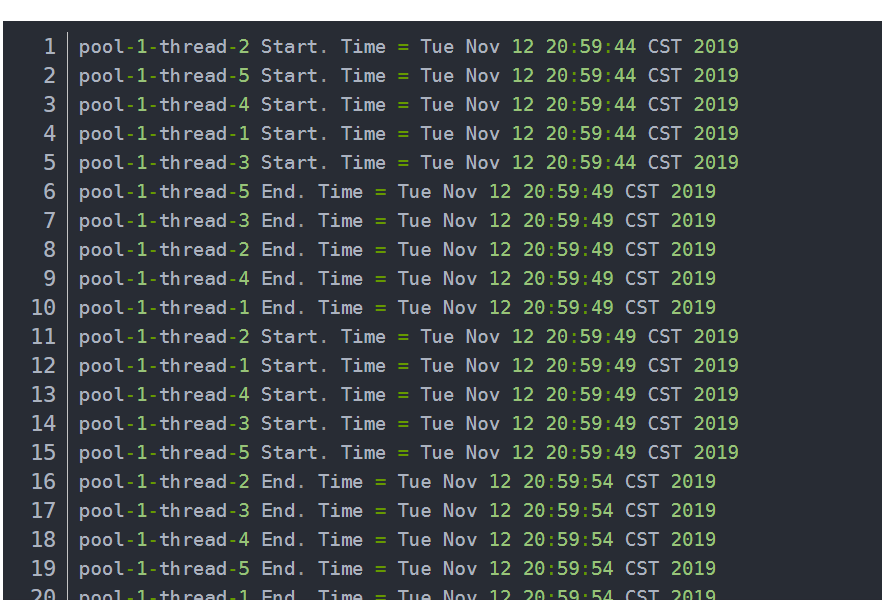
并发关键字(重点)
synchronized
在 Java 中,synchronized 关键字是用来控制线程同步的,就是在多线程的环境下,控制 synchronized 代码段不被多个线程同时执行。synchronized 可以修饰类、方法、变量。
说说自己是怎么使用 synchronized 关键字,在项目中用到了吗
synchronized关键字最主要的三种使用方式:
修饰实例方法: 作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁
修饰静态方法: 也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份)。所以如果一个线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁。
修饰代码块: 指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
总结: synchronized 关键字加到 static 静态方法和 synchronized(class)代码块上都是是给 Class 类上锁。synchronized 关键字加到实例方法上是给对象实例上锁。尽量不要使用 synchronized(String a) 因为JVM中,字符串常量池具有缓存功能!
单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗
public class Singleton {
private volatile static Singleton uniqueInstance;
private Singleton() {
}
public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
synchronized (Singleton.class) {
if (uniqueInstance == null) {
uniqueInstance = new Singleton();
}
}
}
return uniqueInstance;
}
}
另外,需要注意 uniqueInstance 采用 volatile 关键字修饰也是很有必要。
uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
为 uniqueInstance 分配内存空间
初始化 uniqueInstance
将 uniqueInstance 指向分配的内存地址
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
synchronized 和 Lock 有什么区别?
首先synchronized是Java内置关键字,在JVM层面,Lock是个Java类;
synchronized 可以给类、方法、代码块加锁;而 lock 只能给代码块加锁。
synchronized 不需要手动获取锁和释放锁,使用简单,发生异常会自动释放锁,不会造成死锁;而 lock 需要自己加锁和释放锁,如果使用不当没有 unLock()去释放锁就会造成死锁。
通过 Lock 可以知道有没有成功获取锁,而 synchronized 却无法办到。
synchronized、volatile、CAS 比较
(1)synchronized 是悲观锁,属于抢占式,会引起其他线程阻塞。
(2)volatile 提供多线程共享变量可见性和禁止指令重排序优化。
(3)CAS 是基于冲突检测的乐观锁(非阻塞)
synchronized 和 ReentrantLock区别
synchronized 是和 if、else、for、while 一样的关键字,ReentrantLock 是类,这是二者的本质区别。既然 ReentrantLock 是类,那么它就提供了比synchronized 更多更灵活的特性,可以被继承、可以有方法、可以有各种各样的类变量
synchronized 早期的实现比较低效,对比 ReentrantLock,大多数场景性能都相差较大,但是在 Java 6 中对 synchronized 进行了非常多的改进。
相同点:两者都是可重入锁
两者都是可重入锁。“可重入锁”概念是:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
主要区别如下:
ReentrantLock 使用起来比较灵活,但是必须有释放锁的配合动作;
ReentrantLock 必须手动获取与释放锁,而 synchronized 不需要手动释放和开启锁;
ReentrantLock 只适用于代码块锁,而 synchronized 可以修饰类、方法、变量等。
二者的锁机制其实也是不一样的。ReentrantLock 底层调用的是 Unsafe 的park 方法加锁,synchronized 操作的应该是对象头中 mark word
Java中每一个对象都可以作为锁,这是synchronized实现同步的基础:
普通同步方法,锁是当前实例对象
静态同步方法,锁是当前类的class对象
同步方法块,锁是括号里面的对象
volatile
对于可见性,Java 提供了 volatile 关键字来保证可见性和禁止指令重排。 volatile 提供 happens-before 的保证,确保一个线程的修改能对其他线程是可见的。当一个共享变量被 volatile 修饰时,它会保证修改的值会立即被更新到主存,当有其他线程需要读取时,它会去内存中读取新值。
从实践角度而言,volatile 的一个重要作用就是和 CAS 结合,保证了原子性,详细的可以参见 java.util.concurrent.atomic 包下的类,比如 AtomicInteger。
volatile 常用于多线程环境下的单次操作(单次读或者单次写)。
volatile 修饰符的有过什么实践?
synchronized 和 volatile 的区别是什么?
synchronized 表示只有一个线程可以获取作用对象的锁,执行代码,阻塞其他线程。
volatile 表示变量在 CPU 的寄存器中是不确定的,必须从主存中读取。保证多线程环境下变量的可见性;禁止指令重排序。
final
多线程应用
SpringBoot多线程定时任务
主启动类
@EnableScheduling
@SpringBootApplication
public class CronDemoApplication {
public static void main(String[] args) {
SpringApplication.run(CronDemoApplication.class, args);
}
}
定义类实现
SchedulingConfigurer
@Configuration
public class ScheduleConfig implements SchedulingConfigurer {
@Override
public void configureTasks(ScheduledTaskRegistrar scheduledTaskRegistrar) {
scheduledTaskRegistrar.setScheduler(Executors.newScheduledThreadPool(20));
}
}
定义定时器类
@Slf4j
@Component
public class CronApplication {
@Scheduled(cron = "0/1 * * * * ?")
public void runOne() throws InterruptedException {
log.info("runOne:start");
Thread.sleep(1000 * 10);
log.info("runOne:end");
}
@Scheduled(cron = "0/1 * * * * ?")
public void runTwo() throws InterruptedException {
log.info("runTwo:start");
Thread.sleep(1000 * 5);
log.info("runTwo:end");
}
}
- 注意如果定时器没执行需要检查
- 检查springboot启动类中是否有加
@EnableScheduling - 检查定时器类是否存在springboot容器中, 如果没有在类上添加
@Component
什么是 CAS
CAS 是 compare and swap 的缩写,即我们所说的比较交换。
cas 是一种基于锁的操作,而且是乐观锁。在 java 中锁分为乐观锁和悲观锁。悲观锁是将资源锁住,等一个之前获得锁的线程释放锁之后,下一个线程才可以访问。而乐观锁采取了一种宽泛的态度,通过某种方式不加锁来处理资源,比如通过给记录加 version 来获取数据,性能较悲观锁有很大的提高。
CAS 操作包含三个操作数 —— 内存位置(V)、预期原值(A)和新值(B)。如果内存地址里面的值和 A 的值是一样的,那么就将内存里面的值更新成 B。CAS是通过无限循环来获取数据的,若果在第一轮循环中,a 线程获取地址里面的值被b 线程修改了,那么 a 线程需要自旋,到下次循环才有可能机会执行。
java.util.concurrent.atomic 包下的类大多是使用 CAS 操作来实现的(AtomicInteger,AtomicBoolean,AtomicLong)。
CAS 的会产生什么问题?
1、ABA 问题:
比如说一个线程 one 从内存位置 V 中取出 A,这时候另一个线程 two 也从内存中取出 A,并且 two 进行了一些操作变成了 B,然后 two 又将 V 位置的数据变成 A,这时候线程 one 进行 CAS 操作发现内存中仍然是 A,然后 one 操作成功。尽管线程 one 的 CAS 操作成功,但可能存在潜藏的问题。从 Java1.5 开始 JDK 的 atomic包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。
2、循环时间长开销大:
对于资源竞争严重(线程冲突严重)的情况,CAS 自旋的概率会比较大,从而浪费更多的 CPU 资源,效率低于 synchronized。
3、只能保证一个共享变量的原子操作:
当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁。
边栏推荐
猜你喜欢
Basic use of Slurm

The ramdisk practice 1: the root file system integrated into the kernel
arcgis填坑_2
AUTOMATION DAY07( Ansible Vault 、 普通用户使用ansible)
Local yum source build
HCIP WPN实验
(1) Software testing theory (0 basic understanding of basic knowledge)
CLUSTER DAY01(集群及LVS简介 、 LVS-NAT集群 、 LVS-DR集群)
ETCD容器化搭建集群
局域网文件传输
随机推荐
华为防火墙-1-安全区域
SECURITY DAY03(一键部署zabbix)
ETCD单节点故障应急恢复
Threatless Technology-TVD Daily Vulnerability Intelligence-2022-7-18
arcgis填坑_3
Threatless Technology-TVD Daily Vulnerability Intelligence-2022-7-29
iptables 使用脚本来管理规则
SECURITY DAY04 (Prometheus server, Prometheus monitored terminal, Grafana, monitoring database)
(一)软件测试理论(0基础了解基础知识)
【LeetCode】306.累加数(思路+题解)
MoreFileRename批量文件改名工具
CLUSTER DAY02( Keepalived热备 、 Keepalived+LVS 、 HAProxy服务器 )
Deep Learning Matlab Toolbox Code Comments
VMware workstation 16 安装与配置
AUTOMATION DAY06( Ansible进阶 、 Ansible Role)
SECURITY DAY01(监控概述 、 Zabbix基础 、 Zabbix监控服 )
Basic use of Slurm
cloudreve使用体验
配置dns服务
lvm 多盘挂载,合并使用