当前位置:网站首页>ETCD cluster fault emergency recovery - to recover from the snapshot
ETCD cluster fault emergency recovery - to recover from the snapshot
2022-08-11 06:59:00 【!Nine thought & & gentleman!】
系列文章目录
文章目录
前言
如果整个etcdAll nodes of the cluster are down,And restart via regular node,Unable to complete main selection,集群无法恢复.This article provides cluster recovery guidance for this situation.If the local data has been corrupted,only through historysnapshot进行恢复(前提是保存有snapshot数据)
一、Overall recovery process
The overall recovery process is as follows
二、集群故障恢复
2.1 环境信息
使用本地的vmstation创建3个虚拟机,信息如下
| 节点名称 | 节点IP | 节点配置 | 操作系统 | Etcd版本 | Docker版本 |
|---|---|---|---|---|---|
| etcd1 | 192.168.82.128 | 1c1g 20g | CentOS7.4 | v3.5 | 13.1 |
| etcd2 | 192.168.82.129 | 1c1g 20g | CentOS7.4 | v3.5 | 13.1 |
| etcd3 | 192.168.82.130 | 1c1g 20g | CentOS7.4 | v3.5 | 13.1 |
模拟数据,and view the data
export ETCDCTL_API=3
ETCD_ENDPOINTS=192.168.92.128:2379,192.168.92.129:2379,192.168.92.130:2379
for i in {
1..100};do etcdctl --endpoints=$ETCD_ENDPOINTS put "/foo-$i" "hello";done
etcdctl --endpoints=$ETCD_ENDPOINTS get / --prefix --keys-only|wc -l
进行snapshot备份
export ETCDCTL_API=3
ETCD_ENDPOINTS=192.168.92.128:2379
etcdctl --endpoints=$ETCD_ENDPOINTS snapshot save snapshot.db
备份文件为snapshot.db
2.2 Select a node to restore backup data
2.2.1 从snapshot数据恢复
mv /data/etcd /data/etcd.bak
export ETCDCTL_API=3
ETCD_ENDPOINTS=192.168.92.128:2379
etcdctl --endpoints=$ETCD_ENDPOINTS snapshot restore snapshot.db --name=etcd1 --initial-cluster etcd1=http://192.168.92.128:2380 --initial-advertise-peer-urls http://192.168.92.128:2380 --data-dir=/data/etcd

2.2.2 etcd1The node needs to adjust the startup parameters,启动脚本如下
[[email protected] /]# cat start_etcd_with_force_new_cluster.sh
#! /bin/sh
name="etcd1"
host="192.168.92.128"
cluster="etcd1=http://192.168.92.128:2380"
docker run -d --privileged=true -p 2379:2379 -p 2380:2380 -v /data/etcd:/data/etcd --name $name --net=host quay.io/coreos/etcd:v3.5.0 /usr/local/bin/etcd --name $name --data-dir /data/etcd --listen-client-urls http://$host:2379 --advertise-client-urls http://$host:2379 --listen-peer-urls http://$host:2380 --initial-advertise-peer-urls http://$host:2380 --initial-cluster $cluster --initial-cluster-token tkn --initial-cluster-state new --force-new-cluster --log-level info --logger zap --log-outputs stderr
关键参数如下
- –data-dir /data/etcd,Needs to be loaded from the currently saved data directory
- –force-new-cluster,Force start the cluster
- –initial-cluster-state new,启动一个新集群,跟–force-new-cluster配合使用
- –initial-cluster $cluster,Only configure this node,Form a single node cluster
2.2.3 查看数据是否一致
export ETCDCTL_API=3
ETCD_ENDPOINTS=192.168.92.128:2379
etcdctl --endpoints=$ETCD_ENDPOINTS get / --prefix --keys-only|wc -l

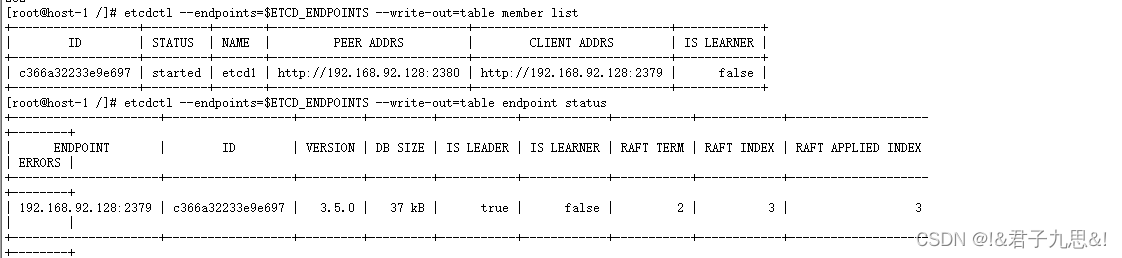
2.2.4 Verify that the cluster is up
export ETCDCTL_API=3
export ETCD_ENDPOINTS=192.168.92.128:2379
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table member list
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table endpoint status
2.2 添加第二个节点
2.2.1 添加第2nodes into the cluster
export ETCDCTL_API=3
export ETCD_ENDPOINTS=192.168.92.128:2379
etcdctl --endpoints=$ETCD_ENDPOINTS member add etcd2 --peer-urls=http://192.168.92.129:2380

At this time due to the overall cluster is2个节点,第2个节点没有启动,因此不符合raft协议,第1nodes will be down,Need to be as soon as possible2个节点启动,The entire cluster can return to normal.
2.2.2 删除第2个节点的数据
mv /data/etcd /data/etcd.bak
mkdir -p /data/etcd/
备份数据(以防万一),and create an empty data directory,Join the cluster at startup,并同步数据
2.2.2 启动第2个节点
第2The startup script for each node is as follows
[[email protected] /]# cat start_etcd.sh
#! /bin/sh
name="etcd2"
host="192.168.92.129"
cluster="etcd1=http://192.168.92.128:2380,etcd2=http://192.168.92.129:2380"
docker run -d --privileged=true -p 2379:2379 -p 2380:2380 -v /data/etcd:/data/etcd --name $name --net=host quay.io/coreos/etcd:v3.5.0 /usr/local/bin/etcd --name $name --data-dir /data/etcd --listen-client-urls http://$host:2379 --advertise-client-urls http://$host:2379 --listen-peer-urls http://$host:2380 --initial-advertise-peer-urls http://$host:2380 --initial-cluster $cluster --initial-cluster-token tkn --initial-cluster-state existing --log-level info --logger zap --log-outputs stderr
关键参数如下
- –data-dir /data/etcd,Needs to be loaded from the currently saved data directory
- –initial-cluster-state existing,Join an existing cluster
- –initial-cluster $cluster,只配置2个节点,形成一个2节点集群
2.2.3 查看集群状态
export ETCDCTL_API=3
export ETCD_ENDPOINTS=192.168.92.128:2379,192.168.92.129:2379
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table member list
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table endpoint status
etcdctl --endpoints=$ETCD_ENDPOINTS get / --prefix --keys-only|wc -l
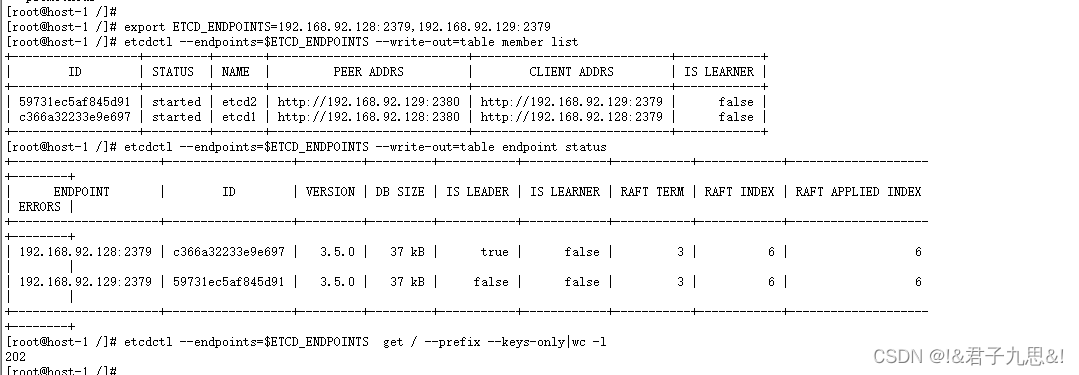
说明
1、etcd的raftWhen the agreement is selected as the master,会考虑数据的offset,offset越大,Tends to get the votes of the leader,因此在这种情况下,会选择etcd1作为主
2.3 添加第三个节点
2.2.1 添加第3nodes into the cluster
export ETCDCTL_API=3
export ETCD_ENDPOINTS=192.168.92.128:2379
etcdctl --endpoints=$ETCD_ENDPOINTS member add etcd3 --peer-urls=http://192.168.92.130:2380

At this time due to the overall cluster is3个节点,已经有2个节点正常,So add the3A node does not affect the current master election situation.
2.2.2 删除第3个节点的数据
mv /data/etcd /data/etcd.bak
mkdir -p /data/etcd/
备份数据(以防万一),and create an empty data directory,Join the cluster at startup,并同步数据
2.2.2 启动第3个节点
第2The startup script for each node is as follows
[[email protected] /]# cat start_etcd.sh
#! /bin/sh
name="etcd3"
host="192.168.92.130"
cluster="etcd1=http://192.168.92.128:2380,etcd2=http://192.168.92.129:2380,etcd3=http://192.168.92.130:2380"
docker run -d --privileged=true -p 2379:2379 -p 2380:2380 -v /data/etcd:/data/etcd --name $name --net=host quay.io/coreos/etcd:v3.5.0 /usr/local/bin/etcd --name $name --data-dir /data/etcd --listen-client-urls http://$host:2379 --advertise-client-urls http://$host:2379 --listen-peer-urls http://$host:2380 --initial-advertise-peer-urls http://$host:2380 --initial-cluster $cluster --initial-cluster-token tkn --initial-cluster-state existing --log-level info --logger zap --log-outputs stderr
关键参数如下
- –data-dir /data/etcd,Needs to be loaded from the currently saved data directory
- –initial-cluster-state existing,Join an existing cluster
- –initial-cluster $cluster,配置3个节点,形成一个3节点集群
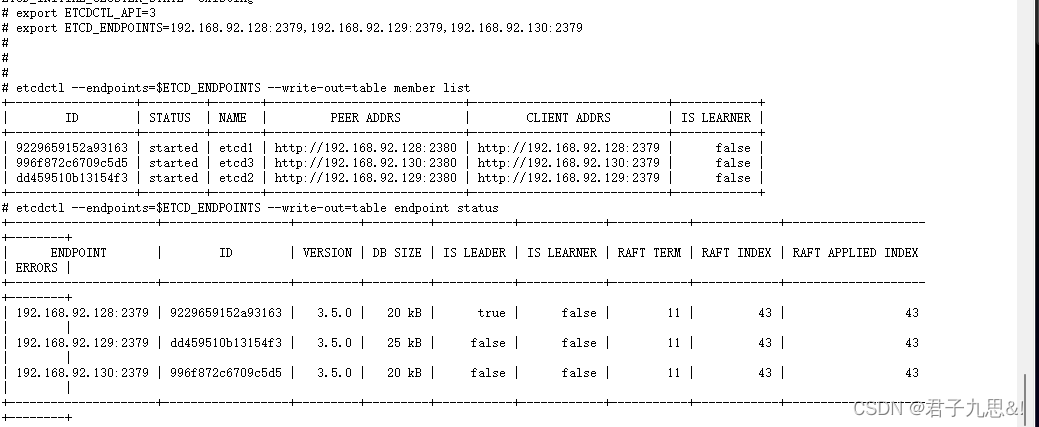
2.2.3 查看集群状态
export ETCDCTL_API=3
export ETCD_ENDPOINTS=192.168.92.128:2379,192.168.92.129:2379,192.168.92.130:2379
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table member list
etcdctl --endpoints=$ETCD_ENDPOINTS --write-out=table endpoint status
2.4 调整第1startup parameters for each node
第1The startup parameters of each node are adjusted as follows,Otherwise every time1After a node restarts,A cluster will be recreated,明显是不合适的.
[[email protected] /]# cat start_etcd.sh
#! /bin/sh
name="etcd1"
host="192.168.92.128"
cluster="etcd1=http://192.168.92.128:2380,etcd2=http://192.168.92.129:2380,etcd3=http://192.168.92.130:2380"
docker run -d --privileged=true -p 2379:2379 -p 2380:2380 -v /data/etcd:/data/etcd --name $name --net=host quay.io/coreos/etcd:v3.5.0 /usr/local/bin/etcd --name $name --data-dir /data/etcd --listen-client-urls http://$host:2379 --advertise-client-urls http://$host:2379 --listen-peer-urls http://$host:2380 --initial-advertise-peer-urls http://$host:2380 --initial-cluster $cluster --initial-cluster-token tkn --initial-cluster-state existing --log-level info --logger zap --log-outputs stderr
并重启etcd1节点
总结
snapshotis backed up data,It is also the final means of data. 由于snapshotBackups are generally periodic,There will be some data loss.因此最好的选择,Restoring from existing data should be prioritized
边栏推荐
- mysql数据库安装教程(超级超级详细)
- No threat of science and technology - TVD vulnerability information daily - 2022-8-4
- 程序集与反射技术(C#)
- VMware workstation 16 安装与配置
- 无胁科技-TVD每日漏洞情报-2022-7-31
- UE4打包工程失败问题记录
- 2022年全国职业技能大赛网络安全竞赛试题B模块自己解析思路(4)
- AUTOMATION DAY06( Ansible进阶 、 Ansible Role)
- 无胁科技-TVD每日漏洞情报-2022-8-3
- 无胁科技-TVD每日漏洞情报-2022-8-6
猜你喜欢




随机推荐
What should I do if I forget the user password in MySQL?
无胁科技-TVD每日漏洞情报-2022-8-1
Lua 协同程序(coroutine)
Vulnhub靶机--Chronos
勒索病毒eking.devos.mkp.makop.lockbit.eight.locked.roger等剖析及中毒文件恢复
Content Size Fitter的使用
无胁科技-TVD每日漏洞情报-2022-7-19
unity小技巧
ETCD单节点故障应急恢复
AUTOMATION DAY07( Ansible Vault 、 普通用户使用ansible)
无胁科技-TVD每日漏洞情报-2022-7-25
C# 基础之字典——Dictionary(一)
Threatless Technology-TVD Daily Vulnerability Intelligence-2022-8-6
【力扣】判断子序列
Threatless Technology-TVD Daily Vulnerability Intelligence-2022-8-2
buildroot设置dhcp
ramdisk实践1:将根文件系统集成到内核中
Vulnhub靶机--born2root
AUTOMATION DAY06( Ansible进阶 、 Ansible Role)
mysql数据库安装教程(超级超级详细)