当前位置:网站首页>从NPU-SLAM-EDA技术分析
从NPU-SLAM-EDA技术分析
2022-08-09 12:26:00 【wujianming_110117】
从NPU-SLAM-EDA技术分析
参考文献链接
https://mp.weixin.qq.com/s/XFtGmGJE9tWCbsPgaCyXJQ
https://mp.weixin.qq.com/s/eUGDEqnP5d1bnlerfabyVg
https://mp.weixin.qq.com/s/ExsUyaTLW2UDUhVmcyaQaw
https://mp.weixin.qq.com/s/KmpUJcFKL2mj6rs9cknODQ
https://mp.weixin.qq.com/s/k3BAnvt1UBwpgg-qNNv8pg
https://mp.weixin.qq.com/s/s7Od97ZctPDyWfn8I-J1LQ
什么是NPU?NPU都有哪些优势?
传统的CPU/GPU也可以做类似的任务,但是针对神经网络特殊优化过的NPU单元,性能会比CPU/GPU高得多。渐渐的,类似的神经网络任务也会由专门的NPU单元来完成。
NPU(嵌入式神经网络处理器/网络处理器)是一种专门应用于网络应用数据包的处理器,采用“数据驱动并行计算”的架构,特别擅长处理视频、图像类的海量多媒体数据。
NPU也是集成电路的一种,但区别于特殊用途集成电路(ASIC)的单一功能,网络处理更加复杂、更加灵活,一般可以利用软件或硬件依照网络运算的特性特别编程从而实现网络的特殊用途,在一块芯片上实现许多不同功能,以应用于多种不同的网络设备及产品。
NPU的亮点在于能够运行多个并行线程 —— NPU通过一些特殊的硬件级优化,比如为一些真正不同的处理核提供一些容易访问的缓存系统,将其提升到另一个层次。这些高容量内核比通常的“常规”处理器更简单,因为不需要执行多种类型的任务。这一整套的“优化”使得NPU更加高效,这就是为什么这么多的研发会投入到ASIC中的原因。
NPU的优势之一在于,大部分时间集中在低精度的算法,新的数据流架构或内存计算能力。与GPU不同,更关注吞吐量而不是延迟。
NPU处理器模块
NPU处理器专门为物联网人工智能而设计,用于加速神经网络的运算,解决传统芯片在神经网络运算时效率低下的问题。NPU处理器包括了乘加、激活函数、二维数据运算、解压缩等模块。
• 乘加模块用于计算矩阵乘加、卷积、点乘等功能,NPU内部有64个MAC,SNPU有32个。
• 激活函数模块采用最高12阶参数拟合的方式实现神经网络中的激活函数,NPU内部有6个MAC,SNPU有3个。
• 二维数据运算模块用于实现对一个平面的运算,如降采样、平面数据拷贝等,NPU内部有1个MAC,SNPU有1个。
• 解压缩模块用于对权重数据的解压。为了解决物联网设备中内存带宽小的特点,在NPU编译器中会对神经网络中的权重进行压缩,在几乎不影响精度的情况下,可以实现6-10倍的压缩效果。
NPU:手机AI的核心载体
大家都知道,手机正常运行离不开SoC芯片,SoC只有指甲盖大小,却“五脏俱全”,其集成的各个模块共同支撑手机功能实现,如CPU负责手机应用流畅切换、GPU支持游戏画面快速加载,而NPU就专门负责实现AI运算和AI应用的实现。
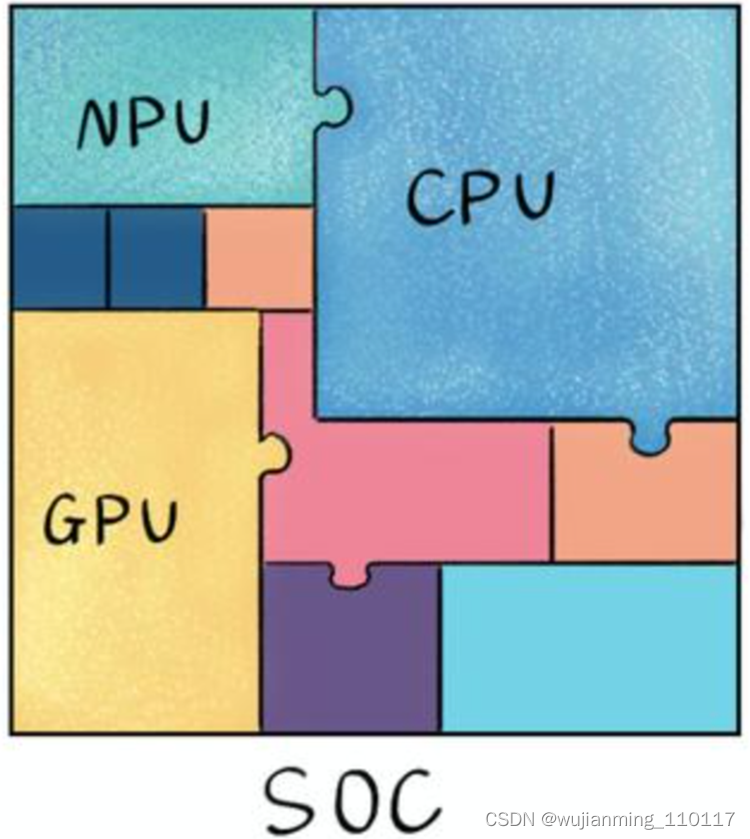
手机上带AI功能这事还得从华为说起,华为是第一个将NPU(neural-network processing units嵌入式神经网络处理器)用于手机上,更是第一个将NPU集成到手机CPU上的公司。
2017年,华为推出自研架构NPU,相比传统标量、矢量运算模式,华为自研架构NPU采用3D Cube针对矩阵运算做加速,因此,单位时间计算的数据量更大,单位功耗下的AI算力也更强,相对传统的CPU和GPU实现数量级提升,实现更优能效。
华为采用外挂的方式最早将寒武纪的NPU用于Mate10,一年之后,华为将寒武纪NPU的IP集成到了980上,又一年之后,华为抛弃了寒武纪在990上采用了自研的达芬奇NPU。
Galaxy中的NPU也是内置于移动处理器中,以利用先进的神经网络并为Galaxy S20/S20 +/S20 Ultra和Z Flip提供更高水平的视觉智能。NPU为场景优化器提供动力,增强了识别照片中内容的能力,并提示相机将其调整为适合主体的理想设置。现在,也比以前的Galaxy模型更准确。还使前置摄像头能够模糊自拍照的背景并创建散景效果。不仅如此,NPU还可以帮助设备上的AI Bixby Vision。
NPU与GPU的关系
GPU虽然在并行计算能力上尽显优势,但并不能单独工作,需要CPU的协同处理,对于神经网络模型的构建和数据流的传递还是在CPU上进行。同时存在功耗高,体积大的问题,性能越高的GPU体积越大、功耗越高、价格也昂贵,对于一些小型设备、移动设备来说将无法使用。因此,一种体积小、功耗低、计算性能高、计算效率高的专用芯片NPU诞生了。
NPU工作原理是在电路层模拟人类神经元和突触,并且用深度学习指令集直接处理大规模的神经元和突触,一条指令完成一组神经元的处理。相比于CPU和GPU,NPU通过突触权重实现存储和计算一体化,从而提高运行效率。
NPU是模仿生物神经网络而构建的,CPU、GPU处理器需要用数千条指令完成的神经元处理,NPU只要一条或几条就能完成,因此在深度学习的处理效率方面优势明显。实验结果显示,同等功耗下NPU的性能是GPU的118倍。
各芯片架构特点总结
• CPU —— 70%晶体管用来构建Cache,还有一部分控制单元,计算单元少,适合逻辑控制运算。
• GPU —— 晶体管大部分构建计算单元,运算复杂度低,适合大规模并行计算。主要应用于大数据、后台服务器、图像处理。
• NPU —— 在电路层模拟神经元,通过突触权重实现存储和计算一体化,一条指令完成一组神经元的处理,提高运行效率。主要应用于通信领域、大数据、图像处理。
• FPGA —— 可编程逻辑,计算效率高,更接近底层IO,通过冗余晶体管和连线实现逻辑可编辑。本质上是无指令、无需共享内存,计算效率比CPU、GPU高。主要应用于智能手机、便携式移动设备、汽车。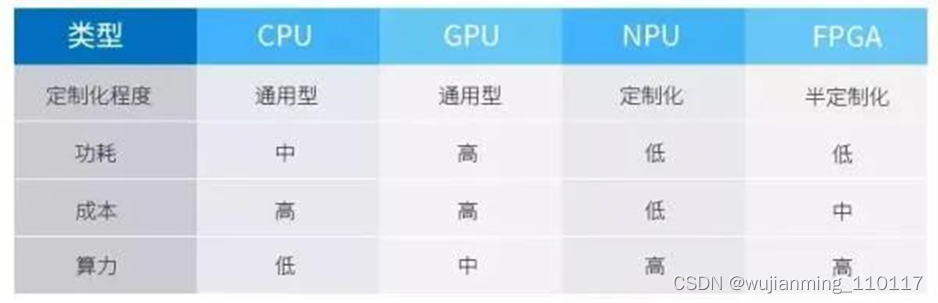
CPU/GPU/NPU/FPGA各自的特点
CPU作为最通用的部分,协同其他处理器完成着不同的任务。GPU适合深度学习中后台服务器大量数据训练、矩阵卷积运算。NPU、FPGA在性能、面积、功耗等方面有较大优势,能更好的加速神经网络计算。而FPGA的特点在于开发使用硬件描述语言,开发门槛相对GPU、NPU高。
可以说,每种处理器都有优势和不足,在不同的应用场景中,需要根据需求权衡利弊,选择合适的芯片。
NPU的实际应用场景
• 拍照时通过NPU实现AI场景识别,并利用NPU运算修图
• NPU判断光源和暗光细节合成超级夜景
• 通过NPU实现语音助手的运行
• NPU配合GPU Turbo预判下一帧实现提前渲染提高游戏流畅度
• NPU预判触控提高跟手度和灵敏度
• NPU判断前台后台网速需求差异配合实现Link Turbo
• NPU判断游戏渲染负载智能调整分辨率
• 把降低游戏时AI的运算负载交给NPU以省电
• NPU实现CPU和GPU的动态调度
• NPU辅助大数据广告推送
• 通过NPU实现输入法AI智能联想词的功能
相关信息
• APU:Accelerated Processing Unit, 加速处理器,AMD公司推出加速图像处理芯片产品。
• BPU:Brain Processing Unit, 地平线公司主导的嵌入式处理器架构。
• CPU:Central Processing Unit 中央处理器, 目前PC core的主流产品。
• DPU:Dataflow Processing Unit 数据流处理器,Wave Computing 公司提出的AI架构。
• FPU:Floating Processing Unit 浮点计算单元,通用处理器中的浮点运算模块。
• GPU:Graphics Processing Unit 图形处理器,采用多线程SIMD架构,为图形处理而生。
• HPU:Holographics Processing Unit 全息图像处理器, 微软出品的全息计算芯片与设备。
• IPU:Intelligence Processing Unit,Deep Mind投资的Graphcore公司出品的AI处理器产品。
• MPU/MCU:Microprocessor/Micro controller Unit,微处理器/微控制器,一般用于低计算应用的RISC计算机体系架构产品,如ARM-M系列处理器。
• NPU:Neural Network Processing Unit,神经网络处理器,是基于神经网络算法与加速的新型处理器总称,如中科院计算所/寒武纪公司出品的diannao系列。
• RPU:Radio Processing Unit 无线电处理器,Imagination Technologies 公司推出的集合集Wifi/蓝牙/FM/处理器为单片的处理器。
• TPU:Tensor Processing Unit 张量处理器,Google 公司推出的加速人工智能算法的专用处理器。目前一代TPU面向Inference,二代面向训练。
• VPU:Vector Processing Unit 矢量处理器,Intel收购的Movidius公司推出的图像处理与人工智能的专用芯片的加速计算核心。
• WPU:Wearable Processing Unit 可穿戴处理器,Ineda Systems公司推出的可穿戴片上系统产品,包含GPU/MIPS CPU等IP。
• XPU:百度与Xilinx公司在2017年Hotchips大会上发布的FPGA智能云加速,含256核。
• ZPU:Zylin Processing Unit,由挪威Zylin公司推出的一款32位开源处理器。
OPPO首个自研芯片NPU
OPPO未来科技大会(OPPO INNO DAY 2021)上,OPPO芯片产品高级总监姜波揭秘了其历时近两年研发的首个自研芯片马里亚纳 MariSilicon X。
OPPO芯片产品高级总监姜波在发布会上展示马里亚纳 MariSilicon X芯片
马里亚纳 MariSilicon X是一个影像专用NPU(神经网络处理器),采用台积电6nm工艺,AI算力高达18TOPS,比苹果最新的A15 15.8TOPS的AI性能还高,同时,MariSilicon X能效比达到了11.6TOPS/W。
作为一家手机终端公司,OPPO竟然在首个自研芯片上就挑战业内顶尖的6nm工艺,并且NPU的性能和能效比也达到了业界领先水平,这不禁让人好奇,OPPO自研芯片的决心从何而来?
从最直观的产品的层面看,马里亚纳 MariSilicon X将搭载在OPPO明年第一季度发布的Find系列旗舰手机上,会为消费者带来突破性的视频拍摄功能。
马里亚纳 MariSilicon X影像专用NPU
从技术层面细细解读,将会发现马里亚纳 MariSilicon X背后,藏着OPPO的计算摄影秘密,以及这家志在探索未来的企业对新十年技术发展趋势的判断。
为什么是影像专用NPU?
当市场的竞争更加激烈,智能手机的创新越来越难之时,全球手机出货量前五的手机厂商们都希望通过自研芯片,用更好的软硬协同,实现差异化的功能和体验,获得消费者的青睐。
差异化竞争的焦点,是消费者最容易感知的影像功能。自2018年开始,手机行业对于AI影像功能的关注只增不减。2020腾讯手机行业洞察白皮书指出,消费者对摄像头、电池的关注度显著提升,其中摄像头的关注度增长率仅次于操作系统。
手机影像系统是一个很长的链条,包括前端传感器、镜头、马达,承载图像处理的ISP芯片,以及后端标定和调优等过程。手机巨头们在整个影像系统上都争相布局,比如,OPPO过去十年,在定制图像传感器、摄像头模组、镜头方面有大量积累,还基于通用SoC平台积累了许多AI算法。
“手机业界已经发现在AI算力的支持下,AI算法已经超越传统ISP算法的效果。因此,目前主流的趋势是用AI算法替代传统算法。”拥有十多年图像处理领域丰富经验的爱芯元智ISP负责人、系统架构师张兴对雷峰网说,“手机厂商已经在拍照中享受到了AI算法带来的好处,包括超级夜景、AI美颜等功能,从趋势来看未来几年,AI拍照最火的几个功能会从拍照推向视频。这就需要一颗高效的芯片,将AI算法和传统ISP进行更好结合。”
将算力、AI与拍照和摄影融合,都代表着手机行业一个重要的趋势——计算摄影。所谓的计算摄影,是利用数字计算而非传统的光学处理的图像。比如超级夜景功能,利用高算力以及AI降噪算法等,将拍摄的多张照片合成为同一张,输出一张明亮清晰的照片。
从谷歌、苹果,到OPPO,整个手机业界的领导者都在通过计算摄影不断突破手机摄影能力的上限。
不过,通用SoC并不能完全满足计算摄影的需求。OPPO芯片产品高级总监姜波指出,“AI降噪算法在Find X3 Pro的芯片平台上,在功耗接近1.7瓦的时候,最多可以处理2帧图像,这意味着AI降噪只能应用到暗光拍照,没办法在最低要求是30fps的视频中应用。”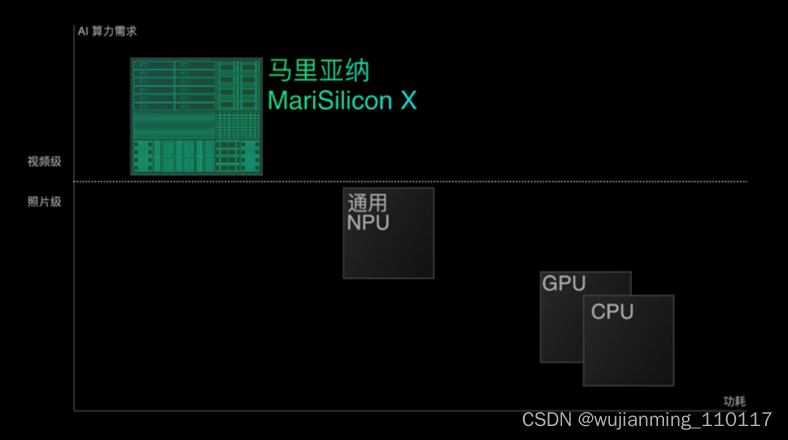
安谋科技高级产品经理柴卫华也说,“随着短视频的需求发展,手机也越来越重视视频拍摄的性能。要实时处理4K甚至8K视频的海量数据,呈现完美的影像效果,处理器性能、算法优异、存储带宽和与系统延迟都是挑战。”
通用SoC限制AI算法性能的同时,也限制了定制传感器和镜头性能的发挥。
原因主要有两方面,一方面,定制传感器的周期较短,但通用SoC的更新以年为周期,两者在时间上难以匹配。另一方面,采用定制传感器,整个图像处理链路需要进行优化增强,但定制传感器和通用SoC很难实现紧密耦合,也就难以发挥最大效益。
已经拥有定制传感器和AI算法积累的OPPO,想要进一步提升影像性能,在计算摄影将占主导地位的竞争中,自然需要一颗影像专用NPU帮助其实现影像链路的垂直整合,进一步实现突破。
“垂直整合最难的就是最开始对用户需求的判断,如果判断失误,会影响后续芯片设计以及所有的配合设计工作。”姜波说:“得益于OPPO在移动智能设备多年的经验,清楚知道消费者的真实需求。”
马里亚纳 MariSilicon X补足了OPPO在影像计算单元上的最后短板——缺乏可控的影像专用处理器。
之所以定位于影像专用,没有加入包括显示在内的更多功能,姜波说:“这是首款自研芯片,要集中在价值最大的功能点上。”
计算摄影如何突破手机摄影极限?
芯片的定位明确之后,具体参数定义也极为关键。这其中有两大关键挑战,一个自研芯片能够带来的性能和体验提升,一定要优于通用SoC;另一个是手机整机的功耗控制。
要解决这两大挑战,就不得不自研这个NPU上的几大核心IP。姜波透露,“刚开始,也评估了一些可以购买的第三方IP,但最终发现没有一个NPU可以与OPPO的场景算法结合,达到最优能耗功率,因此选择了从头开始自研NPU。”
张兴也持同样的观点,“要充分发挥NPU算力与ISP结合的价值,需要在设计的最初就将两个IP结合起来设计。如果是买来的IP,两者结合实现好的功能难度很大,即便实现,也会有大量的功耗和芯片面积的浪费。”
因此,马里亚纳 MariSilicon X中的两大关键IP,MariNeuro AI计算单元和MariLumi影像处理单元均是OPPO自研,分别负责提供高AI算力和更好的影像处理性能,也是计算摄影的关键。
AI算力部分,马里亚纳 MariSilicon X的int8性能高达18 TOPS。之所以要定义一款在终端如此高性能的NPU,原因就是前面提到的马里亚纳 MariSilicon X要有足够的性能带来比通用SoC更好的性能和体验,特别是将AI融入视频拍摄中。
“在视频应用领域,效果稍微好的AI降噪算法,实时处理[email protected]视频就需要10TOPS以上的算力,目前这种应用方案还比较少。”亿智电子创始人兼CEO陈峰指出。
如果没有能耗约束,实现高AI性能并不难,但手机处理器的设计,难点在于能耗比。

要实现高能耗比,芯片制程的选择、架构的设计、性能与功耗的取舍等都非常重要。这也是马里亚纳 MariSilicon X虽然是OPPO的首个自研芯片,但是选择了台积电先进的6nm工艺的关键原因。要知道,设计的芯片工艺越先进,对设计团队的要求越高。如果第一次就想成功,也需要一些运气,而OPPO的马里亚纳 MariSilicon X首次流片就成功。
另外,NPU提升能效比还有一个瓶颈——内存墙。在AI芯片发展几年之后,业界都意识到,NPU数据搬运消耗的能耗远高于数据处理。为此,马里亚纳 MariSilicon X集成奢侈的双层存储,包括万亿比特/秒(Tb/s)级读写速度的内存子系统,以及8.5GB/s的独立DDR带宽的方式,为AI的高效运算提供充分的内存读写支持,在有效减少数据搬运的同时提升能效比。
最终,马里亚纳 MariSilicon X在实现18TOPS高算力的同时,拥有11.6TOPS/W的极致能效比表现,运行OPPO AI降噪模型的速度是达到Find X3 Pro(骁龙888)的20倍,能效达到40倍,在业界属于领先水平。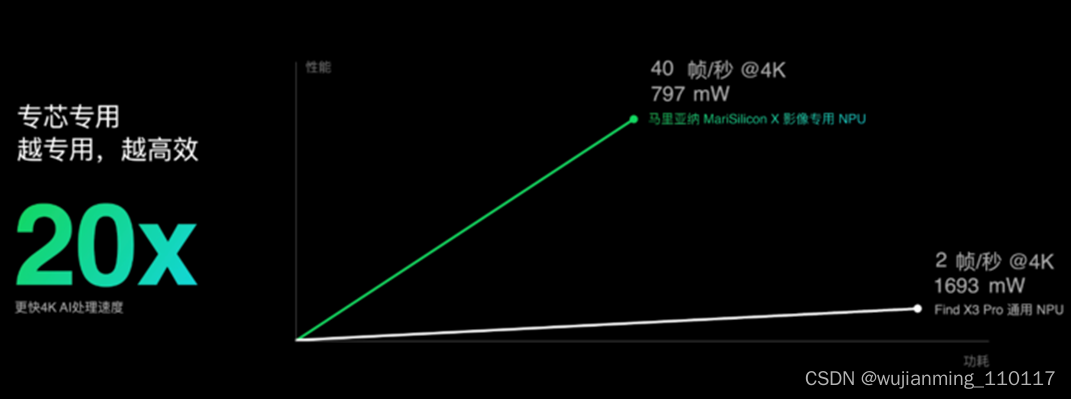
芯片行业有这样一句话,“算力代表一切。”
实现了高算力和极致能效比的兼顾,马里亚纳 X发挥自研MariNeuro和MariLumi联合设计的独特优势,最高支持人眼级别的20bit Ultra HDR,能覆盖100万:1的最大亮度范围,是目前行业主流HDR能力的4倍,比最新发布的旗舰通用SoC支持的18bit HDR更加极致。
传统来讲,HDR是在YUV里合成的,经过RGB和YUV的转换,会损失大量的图像信息。
马里亚纳 MariSilicon X帮助OPPO首次完成影像链路的垂直整合,就可以重塑转换链路,将处理节点前置在信息量100%的RAW域直接做实时计算,20bit RAW实时计算,能够带来画质的显著提升。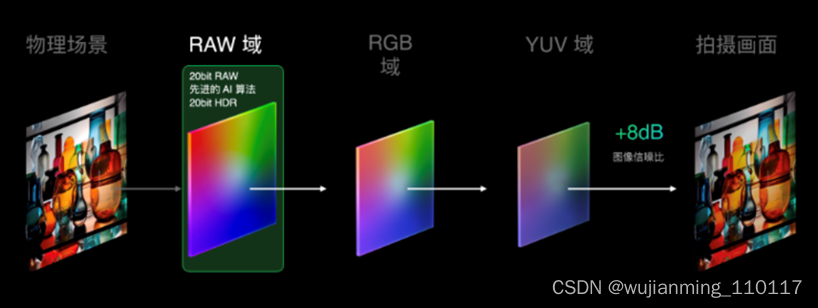
马里亚纳 MariSilicon X支持20bit HDR,高于最新旗舰SoC的18bit。通用SoC落后于马里亚纳 MariSilicon X的规格,是否会成为限制这款OPPO首个自研芯片发挥性能的瓶颈?姜波对雷峰网(公众号:雷峰网)解释,“由于马里亚纳 MariSilicon X是在手机SoC之前处理,NPU处理完HDR、AI降噪等之后就不需要再进行相应处理,不会限制MariSiliconX性能的发挥。”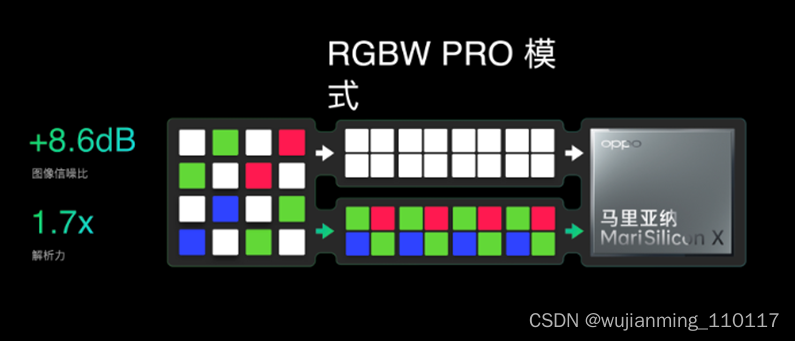
有了自研芯片,也能让OPPO充分发挥定制传感器的性能。马里亚纳 MariSilicon X充分发挥了RGBW的更强能力,通过双链路的设计和2x RAW计算,实现8.6 dB信噪比和1.7倍解析力提升。
“通过自研芯片和定制化传感器相互的化学反应和相互耦合,可以做到最大化发挥定制传感器的能力。”姜波指出。
对于计算摄影这个涵盖计算机图形学、计算机视觉和应用光学等多个学科领域的技术,OPPO的首款自研芯片能够基于算力,借助垂直整合,用计算摄影突破手机影像的极限。
自研芯片给OPPO手机带来的可能性
马里亚纳 MariSilicon X能够突破的极限,是让手机能够在弱光环境,用计算摄影实现4K+20bit RAW+AI+Ultra HDR夜景视频的新极限。

之所以把视频拍摄限在4K30帧,也是出于功耗的考量。视频的实时处理特性,难度远大于照片的先拍后算。视频基础的要求是30帧/秒,意味着每一帧的处理要有大概33毫秒,要实现视频AI功能,必须在33毫秒内处理完成,性能和功耗的约束是关键。”
同时,手机系统层级,功耗的控制也非常重要。
“现在把整个影像链路中,最耗功耗的HDR、AI降噪等算法都在马里亚纳MariSilicon X上处理,SoC不需要再进行处理,所以是节省功耗的。”姜波解释,“OPPO有一个功耗及格线,不能增加整体功耗,这是基本原则思路。”
OPPO展示了一段暗光视频拍摄的视频,可以明显看到,搭载马里亚纳 MariSilicon X的测试平台在暗光环境中视频的细节更多,画面解析力更高。

未来,OPPO的自研芯片还能实现更多视频拍摄的AI功能。这是因为,马里亚纳MariSilicon X设计之初就将AI和图像处理进行了很好融合,相比传统的ISP有更高灵活性,还有更高性能,用计算摄影突破手机影像功能的极限,而无损计算也是计算影像的必然趋势。
另外,从OPPO自研芯片的命名马里亚纳来看,OPPO还会在自研芯片的道路上不断探索,马里亚纳 MariSilicon X只是OPPO自研芯片的开始,未来OPPO还可能推出更多自研芯片,给终端用户带来更多惊喜。
OPPO自研芯片并不让人意外,让人有些意外的是,OPPO首款自研芯片就采用了台积电6nm工艺,首次流片就成功,定位影像专用的马里亚纳 X NPU在性能上兼顾了高性能和高能效。
当然,这是OPPO作为手机终端公司,在充分理解消费者需求,以及基于已有技术积累,对行业趋势判断,自研芯片的优势。
对于OPPO而言,虽然自研芯片一定会带来成本的增加,但OPPO更关注的是提升消费者体验,以及用计算摄影不断突破极限。对于消费者来说,在马里亚纳 MariSilicon X加持下,能够实现暗光视频拍摄突破的OPPO Find新旗舰,将会是一个非常值得关注产品。对于手机业界来说,OPPO硬实力的增加或许也会给行业的竞争带来更多压力,跟上无损计算摄影的趋势,也变得更加重要。
开始SLAM
主要从以下几个方面来介绍:
• 了解阶段
• 学习框架
• 进阶阶段
• 补充阶段
• 总结
开发者在第一阶段需要了解SLAM技术,知道大致原理和用途。
SLAM技术中取名字唯一值得推荐的就是SLAM这个名词本身。同时定位与地图构建(Simultaneous Localization and Mapping),在陌生环境,由于没有地图,只能通过探索,一边获取自己的相对位置,一边绘制当前环境的地图,当探索完该区域之后,就可以得到该未知区域的完整地图了。
除了SLAM,其它的一些名词大部分都晦涩难懂。站在一个新手的角度来说,一个贴切和容易理解的技术名词非常关键,一个不知所措的名词往往都会吓退新人,比如BA、李代数群、词袋。不排除其它学科的一些缩写和专有名词,但是这些名词完全无法用一句话解释用途,理解起来也非常不形象。
接下来是前端和后端,在计算机技术中前端通常指的是网页,后端通常指的是后台的服务器程序。而SLAM中恰恰又有前端和后端的概念,导致理解起来也有点费力气,一是因为之前就有惯性思维,二是感觉也不太贴切,虽然功能上有一个大概的影子,但是拿前端和后端去统称这两个过程有什么现实的意义吗?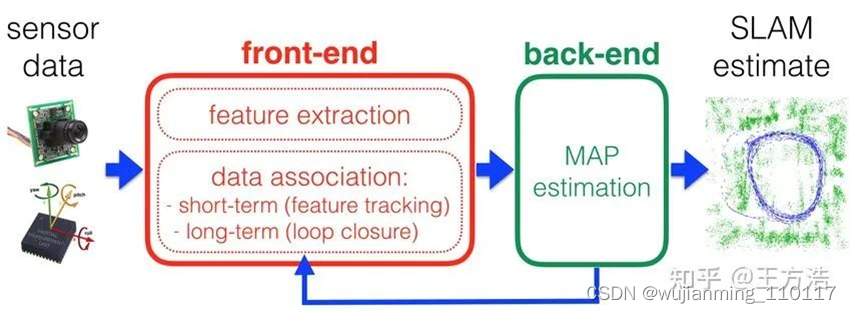
前端和后端的划分
以目前的理解前端是进行特征提取,获取相邻帧的位姿变换,而后端则是进行地图的拼接和位姿优化。这两个过程有点类似在线计算和离线计算的架构,也就是大数据的Lambda架构,实时计算的是相邻帧的位姿,然后再离线计算位姿的优化并且提供给在线使用。
因此了解阶段最主要的也是最重要的是理解SLAM的名词本身,并且知道SLAM的大致的原理,也就是通过相邻帧来获取相对位姿、计算相对位置,同时利用历史轨迹信息来建图,并且优化之前和现在的位姿。
第一阶段知道了SLAM的大概原理就成功了,千万不要再去刻意理解上述这些名词,有可能只是增加烦恼。
主要以Lidar SLAM为例子来说明。学习Lidar SLAM 之前,需要优先学习LEGO-LOAM框架,然后是Cartographer框架。其实如果开始只是了解SLAM的原理,直接跳到看框架可能觉得跨度有点大,建议一开始先学习框架,而不是看书,学习完整理论,学习数学之类,理由如下:
• 首先需要先清楚熟悉LEGO-LOAM的代码;
• 其次关于LEGO-LOAM的论文讲解,这点非常关键,比如以LEGO是代表积木,可以类似乐高积木来搭建SLAM系统,实际上LEGO是基于地面做优化(Lightweight and Ground-Optimized)。论文中也详细介绍了程序的每个步骤,以及原因和背景,这样在结合代码效果非常好;
• 最后,LEGO-LOAM是当前比较主流的开源Lidar SLAM算法,学习动力足,不是什么过时或者不实用的算法。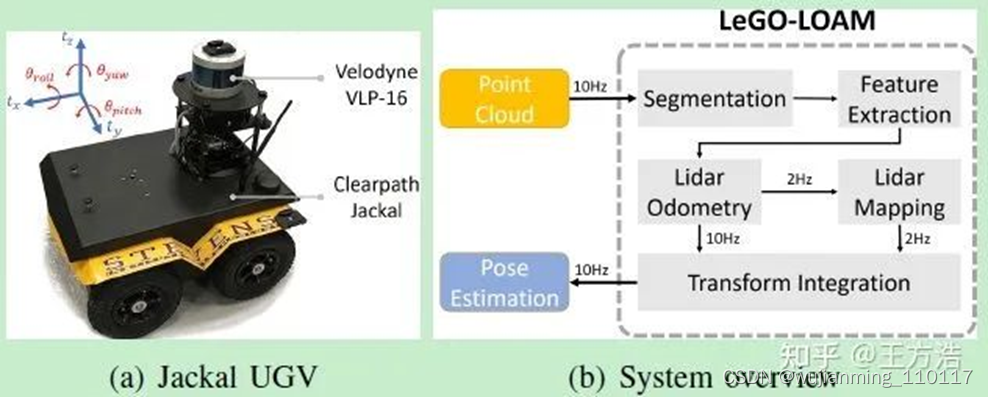
看完开源框架,基本上就对SLAM的整体框架有了一个大致的理解,比如上文所说的前端、后端以及如何提取特征、如何做Pose图优化、回环检测之类的。
由于本人目前仅限于前面两个阶段,因此这里主要是一些想法,后面如果有更进一步的学习会继续补充。
网上有集成了各种算法的OpenSLAM平台,里面集成了一些开源的SLAM算法。其实SLAM算法有点类似于编程,个人有很大的发挥空间,而不是按部就班的按照某几步操作就可以完成,比如提取特征,摄像机和Lidar提取的方式就不一样,而且如何提取特征也不一样。如何去除树叶,如何找到显著的特征,是基于传统的查找线和角特征,还是基于其它的算法,这些都没有成熟完善的方法论,都是基于经验和方法的结合,也就是个人的发挥占很大的因素。
SLAM和编程相比,虽然两者的实现起来都有很大的发挥空间,但是编程为什么更容易?之所以编程可以快速入门的原因,是因为有非常成熟的学习曲线,比如编程就是数据结构和算法。因此大部分人了解下编程语言,然后学习数据结构和算法,就可以很好地胜任编程了。所以SLAM学习网站可以不要一味的汇集各种SLAM算法,然后整成一个大杂烩,让个人去学习,而是应该把底层技术抽丝剥茧,总结成一些方法,然后分别去深入学习,等到使用时,再从这些方法中寻找合适的工具去组合。
比如特征提取,就有地面查找算法、聚类算法,这些算法什么时候适用于什么情况。如何做回环检测,如何进行Pose-Graph优化等。把这些单点的技术类似数据结构和算法总结出来,进行进一步的学习,然后再结合具体的场景去组合发挥出SLAM的威力,这可能是目前比较推荐的学习思路和方法。
关于《SLAM 14讲》这本书对初学者来说非常友好,对开发者理解的基础概念解决非常有用,也就是说虽然之前的知识都懂,但是没有联系起来;另外就是结构清晰,比如SLAM的前端、后端、回环检测,虽然这些知识前面都可以了解,看书之后可以加深印象和理解。
接下来就是根据模块把每个部分再进一步做深,比如前端就看匹配算法、后端就看优化算法、回环就看字典匹配等。当然还有一些开放问题,例如移动物体比较多的情况、环境变换的情况、长隧道等。
关于用NDT建图没有成功的原因:一是可能没有理解pose之类的计算;二是没有好的工具,特别是可视化工具,能够手工加入旋转之类方便理解。
实现了NDT之后,后面开始接触LEGO-LOAM,之前也是觉得高深莫测,但是一旦下定决心,并且熟悉了解4000行的代码量之后,接下来就容易多了,当然SLAM中名词混淆和刻意夸大优化算法公式之类的也是阻碍学习的重要原因之一,实际上这些优化算法都有对应的库可以实现,开始不用刻意理解。如果是后面涉及开发新的算法,可以在此基础上进一步学习。
最后侯捷老师说“使用一个东西却不知道原理,显得不太高明。”希望大家百尺竿头更进一步,也希望SLAM的学习曲线能够更加系统和专业。
后续也会对LEGO-LOAM做一些系统的笔记,并且尝试重构LEGO-LOAM的代码。
SLAM论文综述
• Past, Present, and Future of Simultaneous Localization And Mapping: Towards the Robust-Perception Age 2016年
• A critique of current developments in simultaneous localization and mapping 2016年
SLAM的定义、工作流程、算法以及相关技术在自动驾驶高精度定位、机器人自主导航等前沿热门领域的应用。此外,本文还为读者提供了SLAM学习知识树和更多扩展阅读材料。
什么是 SLAM?
SLAM 是 Simultaneous Localization And Mapping 的 缩写,一般翻译为:同时定位与建图、同时定位与地图构建。
SLAM 的典型过程是这样的:当某种移动设备(如机器人 / 无人机、手机、汽车等)从一个未知环境里的未知地点出发,在运动过程中通过传感器(如激光雷达、摄像头等)观测定位自身在三维空间中的位置和姿态,再根据自身位置进行增量式的三维地图构建,从而达到同时定位和地图构建的目的。
传统的视觉算法主要是对针对二维图像的处理,借助深度学习在分类识别方面取得了超越人眼精度的巨大成就,就像人眼是通过双眼立体视觉来感知三维世界一样,智能移动终端(比如智能手机、无人汽车、无人机、智能机器人)需要能够像人类一样利用 SLAM 算法来快速精确的感知、理解三维空间。
最近几年,以双目相机、结构光 / TOF 相机、激光雷达为代表的三维传感器硬件迭代更新迅猛,国内外已经形成了成熟的上下游产业链。三维视觉传感器也逐渐走入普通人的生活,在智能手机、智能眼镜等设备上应用越来越多,以手机为例,苹果、华为、小米、OPPO、VIVO 等手机大厂都在积极推动结构光 / TOF 相机在手机上的普及。
SLAM 技术为核心的三维视觉在学术界也是一个热门方向,从最近几年计算机视觉相关的顶级会议 CVPR, ICCV, ECCV,IROS, ICRA 录用论文来看,视觉定位、三维点云识别分割、单目深度估计、无人驾驶高精度导航、语义 SLAM 等相关论文占比越来越高。
因此 SLAM 技术在最近几年发展迅猛,广泛应用于增强现实感知、自动驾驶高精度定位、机器人自主导航、无人机智能飞行等前沿热门领域。
SLAM 学习知识树
SLAM 是涵盖图像处理、多视角视觉几何、机器人学等综合性非常强的交叉学科。
学习 SLAM 涉及线性代数矩阵运算、李群李代数求导、三维空间刚体变换、相机成像模型、特征提取匹配、多视角几何、非线性优化、回环检测、集束调整、三维重建等专业知识。SLAM 是强实践学科,需要具有一定的 C++ 编程能力,掌握 Linux 操作系统、Eigen, Sophus, OpenCV, Dbow, g2o, ceres 等第三方库,能够快速定位问题,解决 bug。
SLAM的定义及用途:
SLAM(Simultaneous localization and mapping)如名字所告诉:即同时定位(Localization)与建图(Mapping)。应用场景一般多见于机器人导航,场景识别等任务。
SLAM的主要过程:
跟踪运动中的相机,估算出其在每个时刻的位置和姿态(用一个包含旋转和平移信息的变量来表示:矩阵或者向量),并将相机在不同时刻获取的图像帧融合重建成完整的三维地图。
传统的SLAM可分为视觉前端和优化后端两大模块。
视觉前端:
视觉前端主要完成的任务为:利用运动中的相机在不同时刻获取到的图像帧,通过特征匹配,求解出相邻帧之间的相机位姿变换,并完成图像帧之间的融合,重建出地图。视觉前端是一个局部优化过程,由于进行优化的约束条件仅限于相邻图像帧,因此在相机运动的过程中,容易产生误差漂移。
视觉前端依赖于机器人搭载的传感器,常用的传感器有相机(单目相机、双目相机、TOF相机),IMU(惯性测量单元),激光雷达等。单纯通过视觉传感器(即相机)来完成的SLAM又称为视觉SLAM。同时,根据使用的视觉传感器的不同,视觉SLAM也具有不同的算法复杂度和优缺点。
使用单目相机作为视觉传感器,优点是成本低,硬件简单,缺点是算法复杂,对相机的运动具有一定的条件要求,因为其是通过SFM(Structure From Motion)算法完成深度信息的计算,因此如果相机在运动时仅仅发生了旋转而没有平移的话,则无法通过Triangulation(三角测量)来计算目标的深度信息。同时,单目相机需要通过相机在不同时刻获取到的图像帧作为类似双目信息的数据来进行深度重建,因此在初始时刻是无法得到深度信息的。此外,由于SFM算法计算出的深度信息并不是真实的深度信息,因为毕竟不是真正的双目深度重建。在双目相机中,在双目标定的时候已经通过标定板的信息完成了从像素尺度到真实尺度之间的映射。而SFM虽然也是通过相似三角形的关系计算出一个深度信息,但是该深度信息是一个相对值,并没有与真实尺度建立起联系。做法是:对于相机的初始平移,视为单位1。后续的平移,都是以这个单位进行换算的。而SFM重建出的深度,也是以这个单位来表示的。至于这个单位1对应的真实尺度,其实并不知道,只是人为地给定一个值而已(因为仅有一个单目视觉传感器是无法测量到真实距离的)。所以一般而言,对于单目SLAM,如果具有测量要求,一般都会与一个IMU配合使用,以获取真实尺度。
使用双目相机作为视觉传感器,优点是获取点云数据时,受物体表面材质的反光性质的影响比使用辅助光源的深度传感器方案(如TOF,结构光等)要小,同时其测量距离也相较其他方案要更远,深度图的分辨率更高。缺点是计算复杂度大(计算图像特征及完成特征匹配),同时对于特征的设计具有高鲁棒性的要求。这将导致双目视觉SLAM在建立稠密地图(dense map)和算法实时性上具有先天的劣势。
使用结构光方案的深度相机作为视觉传感器,与双目相机方案大同小异。原理都是利用了双目视差和三角测量,不同之处在于,结构光方案对图像的特征进行了编码,该编码特征在计算和匹配时相比双目相机方案的手工设计特征(如ORB,SIFT等)鲁棒性更好,计算更快,缺点是结构光对物体表面的材质敏感,如果是具有反射、透射性质的表面,或者是漫反射过强的表面,都会出现结构光编码信息的丢失,从而无法正确地匹配特征,导致深度信息的缺失。
使用TOF方案的深度相机作为视觉传感器,优点是帧率高,无需通过特征计算及匹配来获取深度信息,因此计算复杂度低,用于SLAM上具有更优的实时性。缺点同结构光方案,对物体表面的材质比较敏感。此外,TOF相机在图像分辨率和测量距离上,也同结构光方案,不如双目相机的方案。
在视觉前端中,主要的任务是完成对相机位姿的估计和建图,这时得到的还是一个局部优化的粗略结果,不可避免地包含噪声和误差,后续还需要通过后端优化,利用更多约束条件对其进行微调,以获得精确的位姿和地图。
估计相机位姿的常用算法是ICP(iterative closest point),简而言之就是寻找源点集中的每个点在目标点集中的最近邻点(用于判断最近点的距离可以在欧氏空间或特征空间中,可以是点到点的距离,也可以是点到面的距离)作为其对应点,建立起多组对应点。对于每组对应点,都用同一个仿射变换矩阵来描述这组对应点的坐标之间的关系(即旋转和平移关系),建立起一个超定方程组,求解出该仿射变换矩阵(之所以每组对应点之间都是同一个仿射变换矩阵,是因为这里描述的运动是一个刚体变换,源点集和目标点集都各自代表一个刚体对象)。计算出该仿射变换矩阵后,将其应用于源点集上,使源点集整体旋转平移到目标点集上,再计算变换后的各组对应点的坐标的总误差,如果小于给定阈值则停止迭代,如果大于给定阈值,则重复上述过程,直到两个点集的对齐(alignment)收敛。
在SLAM中的做法是,通过ICP来完成相邻帧之间的图像配准(前一帧作为目标点集,当前帧作为源点集),进而得到相邻帧之间的相机坐标系之间的旋转平移关系。通常以初始位置的相机坐标系作为全局坐标系,每一帧对应的相机坐标系相对于全局坐标系的旋转平移用于描述该帧对应的时刻的相机的位姿。由于所有相邻帧对之间的旋转平移都可以通过对该相邻帧对进行配准来得到,因此每一帧与第一帧之间的旋转平移也就都可以通过这些中间过程的旋转平移来计算得到,从而得到每一帧的相机位姿。
除了通过ICP算法直接对相邻帧的点云进行三维配准,图像配准还可以通过重投影算法来完成: 本质上是最小化重投影误差,即先将当前帧的点云投影到前一帧的相机坐标系中(投影使用的变换矩阵为需要优化的参数),再从前一帧的相机坐标系投影到前一帧的图像坐标系中;同时,前一帧的点云也重投影到其图像坐标系中。通过最小化该图像坐标系上这两个点集里所有对应点对的总误差,来得到当前帧和前一帧的相机坐标系之间的变换矩阵(也即相对位姿)。相邻帧的点云可以使用重投影算法来完成配准,相邻帧的RGB图像也可以使用重投影算法来完成配准,前者称之为几何位姿估计(geometric pose estimation),后者称之为光度位姿估计(photometric pose estimation)。
从配准对象不同的角度进行划分,位姿估计又可以分为frame to frame和frame to model两种方式。前者仅仅是利用相邻帧本身的信息完成图像配准,而后者则是利用当前帧与当前已重建的全局地图在前一帧中的投影来进行图像配准,由于用于配准的对象所包含的信息更多,因此配准效果相较于前者更优。
在经典的视觉SLAM算法中,特征计算使用的是人工设计的特征子和描述子,而近年来出现的一些视觉SLAM算法,则是利用了深度神经网络来提取图像帧的特征,在鲁棒性上相较于经典方法更优。
相机的位姿由一个旋转变换和一个平移变换来描述。由于相机位姿的求解是一个非线性优化问题,通常的一种求解思路是利用目标函数的梯度下降方向去寻找极值点,即通过不断地调整下降方向和搜索步长,以迭代的方式去逼近极值点。高斯牛顿法和LM算法(Levenberg-Marquardt method)就是其中的两种经典优化算法。而又因为这种迭代更新参数的策略要求参数对加法运算是闭合的,因此需要将不符合该性质的变换矩阵从李群形式转化为符合该性质的李代数形式,也即是使用一个无约束的向量来描述相机的旋转和平移运动。
在完成了位姿估计后,就可以通过每一帧的全局位姿,不断地将新的图像帧中的点云变换到全局坐标系中,与已重建的全局地图/模型完成融合(常见的融合方式是对在空间中非常接近的几个点进行加权融合,与相机的入射光线径向距离近的,与相机的光心距离近的,分配较大权重),逐帧地更新重建地图。对于稀疏SLAM(sparse SLAM)而言,在视觉前端中的建图部分至此就结束了。而对于稠密SLAM(dense SLAM)而言,此时得到的地图不仅是不够精确的,而且在可视化上式不够直观的,就是一群离散的点。所以对于稠密SLAM而言,还多了一个步骤,就是对地图/模型进行渲染。常用的两种表征模型是网格模型和面片模型,前者的代表为TSDF(Truncated Signed Distance Function),后者的代表为surfel(SURFace ELement)。
TSDF是将全局三维空间划分为一个三维网格,每个三维小格子储存其代表的三维空间位置距离相机光心的距离指示值。正数代表在物体表面的后面,负数代表在物体表面的前面,零值代表在物体的表面上,绝对值的大小表征距离物体表面的远近,超过-1和1的部分被截断为截断值。基于TSDF的稠密建图,是不断地利用位于不同帧的相机从不同视角获得的信息,从该视角将该帧的信息重投影到TSDF网格上,进而不断更新TSDF网格中各个三维小格子的指示值的过程。对于一个三维小格子而言,其指示值是从不同视角投影过来的信息共同作用的结果(加权求和)。得到了最终的TSDF网格后,就可以利用计算机图形程序完成地图的渲染,得到一个表面完整的三维模型。此外,利用光线追踪技术(ray casting),还可以得到在不同的位姿下,从该相机视角所看到的全局模型的轮廓。
surfel是一种类似于点云的表征方式。对于每一个三维点,除了三维空间坐标、RGB信息和表面法线信息之外,还包含了其表面半径、初始时间戳(timestamp)、最后更新的时间戳、以及权重值(和跟相机光心的距离有关,距离越远,权重越小)。每个surfel都描述了一个单位表面的信息,该单位表面是一个圆形表面,且对于一个surfel集合而言,其所有的单位表面刚好可以完整地覆盖重建物体的表面。基于surfel的稠密建图,其实就是将稀疏建图的点云表征方式换成surfel表征方式,在得到最终的全局地图的surfel信息后,再利用计算机图形程序完成地图的渲染,进而得到一个表面完整的三维模型。
稠密建图由于计算量较大且易于并行化,多搭配GPU使用。
优化后端:
SLAM的优化后端完成的工作主要是对视觉前端得到的不够准确的相机位姿和重建地图进行优化微调。可与视觉前端分开进行,作为一个离线操作,在近年来的一些SLAM方法中,也可以与视觉前端融为一体进行。
在视觉前端中,不管是进行位姿估计还是建图,都是利用相邻帧之间的关系来完成的,这种依赖局部约束且不停地链式进行的算法,必将导致优化误差逐帧累积,最终产生一个较大的误差漂移。因此,后端优化的思路就是从全局(整个相机运动过程)中选取一些关键帧,利用这些关键帧之间的关系建立起时间和空间跨度更大的、需要同时满足的全局约束,以优化之前得到的不够准确的各帧的相机位姿,实际上就是完成一个Bundle Adjustment。该全局优化问题可以通过建立和优化位姿图(pose graph)来求解。位姿图是以关键帧的全局位姿(被优化的参数)作为图的节点,以关键帧之间的相对位姿误差(对关键帧进行配准得到的相对位姿,与通过关键帧的全局位姿计算出的相对位姿,两者之间的误差)作为图的边的权重,通过令整个图的所有边的权重值总和最小,来优化得到每个图节点的值。这样可以使得本来单方向漂移的误差被摊到整个过程中,类似于完成对一个运动过程的估计的平滑(本质上的目的与卡尔曼滤波算法一致)。
图优化也是一个非线性优化问题,同样地,可以通过高斯牛顿法和LM算法来求解。
在完成了图优化后,关键帧的位姿得到了校正,因此就可以利用这些关键帧去对其相邻的数帧也进行位姿的校正。而在完成了所有帧的位姿校正后,也就可以利用这些校正后的位姿去重建更精确的地图。
在相机的运动过程中,有时候会重复地观测到以前观测过的区域(revisited areas),而由于视觉前端带来的误差漂移,会导致在再次对这些区域进行建图时,会与先前在同一区域建图的结果不重合,即出现了重影现象。因此在后端优化中,另一个重要的工作是进行闭环(loop closure)检测。所谓闭环检测,其实就是判断在相机的运动轨迹上,有没有观测到先前观测过的区域,而这些区域,就是闭环点。对闭环点的检测,也是通过对每一个到来的当前帧,都与各个历史关键帧进行比对来完成的:如果存在有一个历史关键帧与当前帧相似,即说明当前帧是一个闭环点。
用于闭环检测的常用算法主要有:词袋模型(bag-of-words model)和随机蕨算法(randomized fern method)。
词袋模型首先对一个图像帧上的描述子进行聚类:一个关于描述子的聚类称之为一个词,所有不同的词的集合称之为字典。对于在字典中和在单帧图像中出现频率较高的词,给予其较高的权重。当对比两个图像帧之间的相似度时,只要在这两个图像帧上,逐个词地进行权重对比即可,常用的用于衡量权重差异的尺度为L1范数。在逐词对比的过程中,首先需要从字典中按顺序检索出每一个用于帧间对比的词,这是通过K-D树来完成搜索的。
随机蕨算法是对一个图像帧进行稀疏编码(sparse encoding),即在图像帧的采样像素点上进行信息编码:一个像素点被称为一个蕨叶(fern),该像素点上的RGBD通道被称为该蕨叶上的一组节点(node),节点值都是binary的,即在每个节点上都有一个给定的阈值,该阈值将确定该节点值是0还是1。于是一个图像帧就可以用一个蕨丛来表征其信息。在随机蕨算法中,对于每个蕨叶都会建立起一个查找表,且查找表的每一行将对应这个蕨叶的一种编码结果。当每获取到一个新的图像帧,就将该图像帧的ID登记到描述其信息的蕨丛的各个蕨叶所对应的查找表的特定行上。如果有两个图像帧,其ID在超过某个给定阈值的数量的查找表里,都同时出现在同一行,则说明这两个图像帧相似,新获取到的这个图像帧是一个闭环点。反之,如果一个新获取到的图像帧,与所有的历史帧的相似度都足够小,则将该图像帧作为一个关键帧添加到关键帧的数据库中用于后续的闭环检测。随机蕨算法还可以在后端优化中完成位姿追踪失败后的重定位(re-localization):在关键帧数据库中检索与当前帧相似度最高的几个关键帧,并利用与当前帧的相似度作为权重,对这些关键帧对应的位姿进行加权求和,作为对当前帧的位姿的一个估计。
在检测出闭环点之后,就可以利用闭环点建立起一个跨度较大的全局约束,其实就是将视觉前端中的单向链式约束的头尾相连,并根据头尾相连处的位姿必须相等作为一个自洽条件,进而将这个约束条件反馈到闭合后的整个环式结构的优化中,使得每个历史帧的位姿优化不仅依赖于其过去的图像帧的约束,也依赖于其未来的图像帧的约束。这样的优化过程鲁棒性更好,因为对不同的优化方向作出贡献的噪声将借由多约束条件在一定程度上相互抵消,误差漂移现象也因此得到改善。
SLAM的发展:
SLAM近年来发展衍生出的一些其他类型的变种有:非刚性SLAM,多目标模型SLAM,动态SLAM,语义SLAM等。
SLAM的一些开源项目:
在项目代码方面,当前比较具有代表性的一些开源SLAM方案有:
Dense SLAM: KinectFusion, ElasticFusion,BundleFusion,InfiniTAM,MaskFusion
Semi-Dense SLAM: LSD-SLAM
Sparse SLAM: ORB-SLAM
SLAM的一些开发工具:
开发SLAM常用到的工具库主要包括:
OpenNI:用于与视觉传感器的交互操作;OpenCV:用于图像处理;PCL:用于点云处理;Eigen:用于矩阵运算;Sophus:用于李群李代数计算;Ceres Solver:用于非线性优化;g2o:用于图优化;DBoW:用于处理词袋模型;OpenGL:用于模型渲染;CUDA toolkit:用于并行计算,等等。
读懂EDA
EDA赛道热闹异常,先是合见工软获得11亿元人民币的Pre-A轮融资,后是华大九天登陆创业板,首日收盘暴涨129.43%。做EDA凭什么能拿到这么多钱?
EDA的作用和特征,EDA发展历史,EDA技术和应用的变革,国产EDA及背后的思考。
没有EDA,就没有芯片
EDA(Electronic Design Automation,电子设计自动化),是利用计算机辅助完成集成电路芯片的设计、制造、封测的大型工业工具。是最基础、最上游的领域,贯穿了集成电路产业链的每个环节。
简单地说,EDA就是芯片设计师的画笔和画板,就像操作文档要用Word,制作图片要用Photoshop一样,能高效设计、控制及管理数十亿电路元件在一颗芯片里协同工作。
EDA算法密集,融合了图形学、计算数学、微电子学、拓扑逻辑学、材料学及人工智能等多学科的算法技术,必须经过长时间技术积累和持续大规模研发投入,才能满足新工艺的应用需求。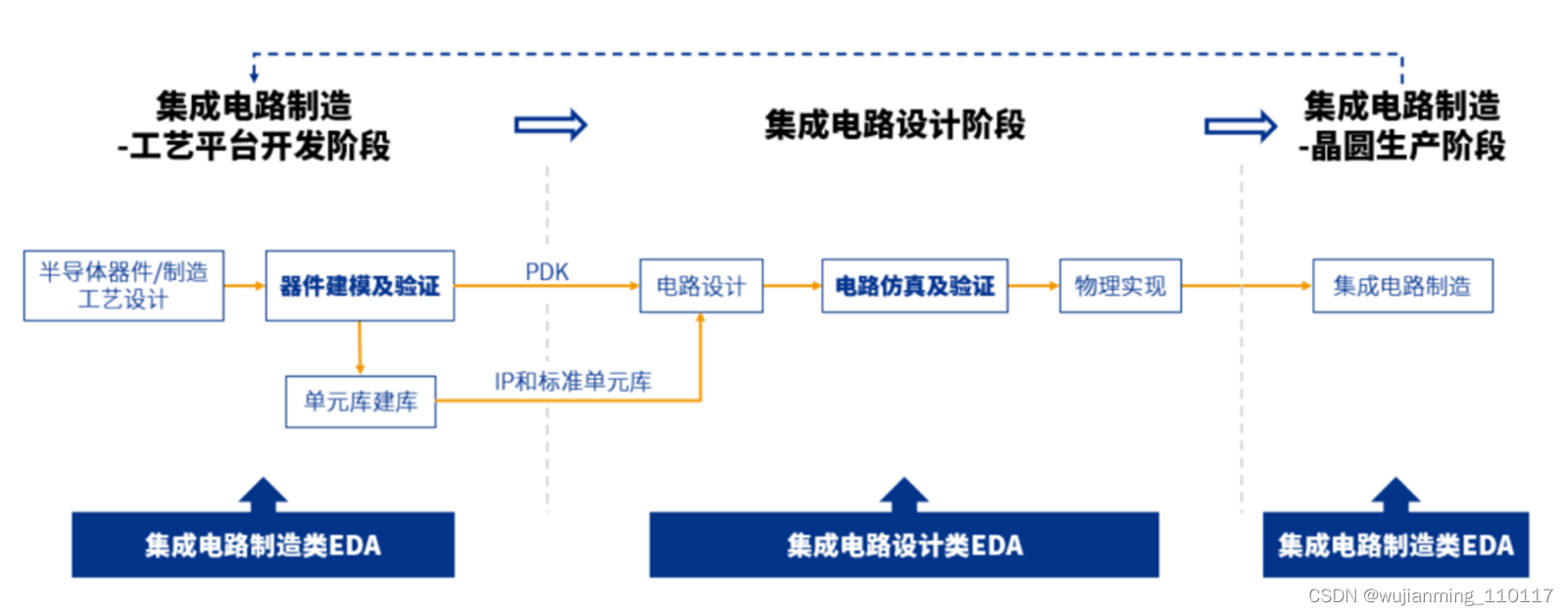
EDA支撑着集成电路设计和制造流程、关键环节,图源丨概伦电子招股书
EDA工具包括硬件和软件两部分。软件是工具的核心,分为仿真工具、设计工具、验证工具三种类型;硬件是用来加速仿真、验证速度的服务器和专用工具。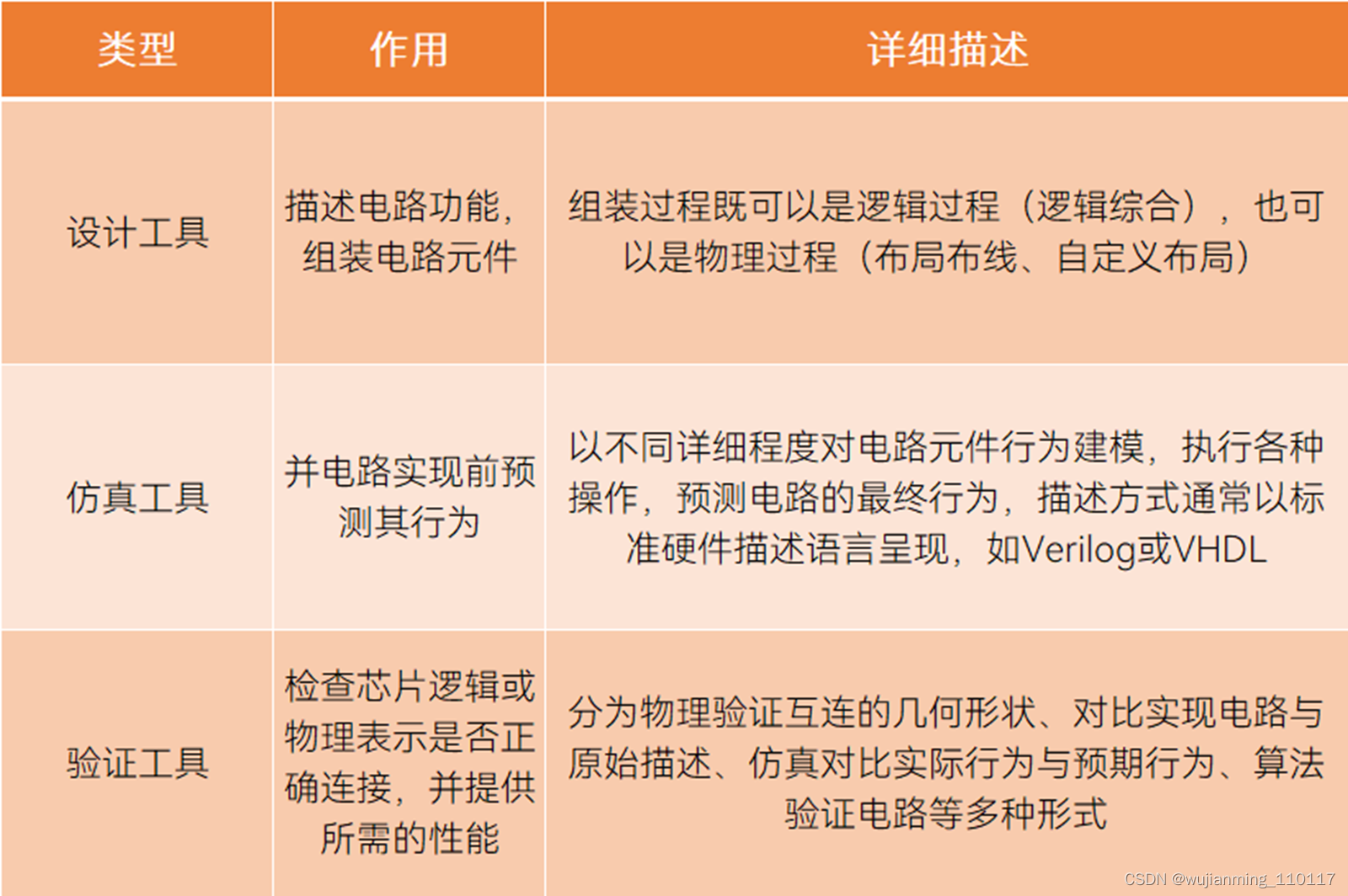
EDA软件工具的三种类型,制表丨果壳硬科技
资料来源丨新思科技
设计工具、仿真工具、验证工具在芯片设计流程中位置,资料来源丨IEEE Xplore
EDA非常重要,倘若出现问题,产业下游的集成电路、电子信息和数字经济都会崩溃。没有EDA,就不可能设计和制造当今的芯片。
芯片设计过程极为复杂,要求设计精细度很高,稍有偏差就会导致芯片报废,项目崩盘;同时,从90nm、65nm进化到3nm/2nm,制造成本攀升,所需设计步骤也越来越多,设计也越来越困难。
EDA能发挥计算机辅助设计(TCAD)、面向制造的设计 (DFM)、硅生命周期管理 (SLM)三大关键功用,保证最终产品的良率和性能。一方面,EDA将复杂的芯片设计流程拆分成高级综合、逻辑综合、原理图布局等若干步骤,并配备丰富的工具组件库和可复用的参考架构;另一方面,EDA能利用仿真、验证等工具在芯片生产前纠正错误。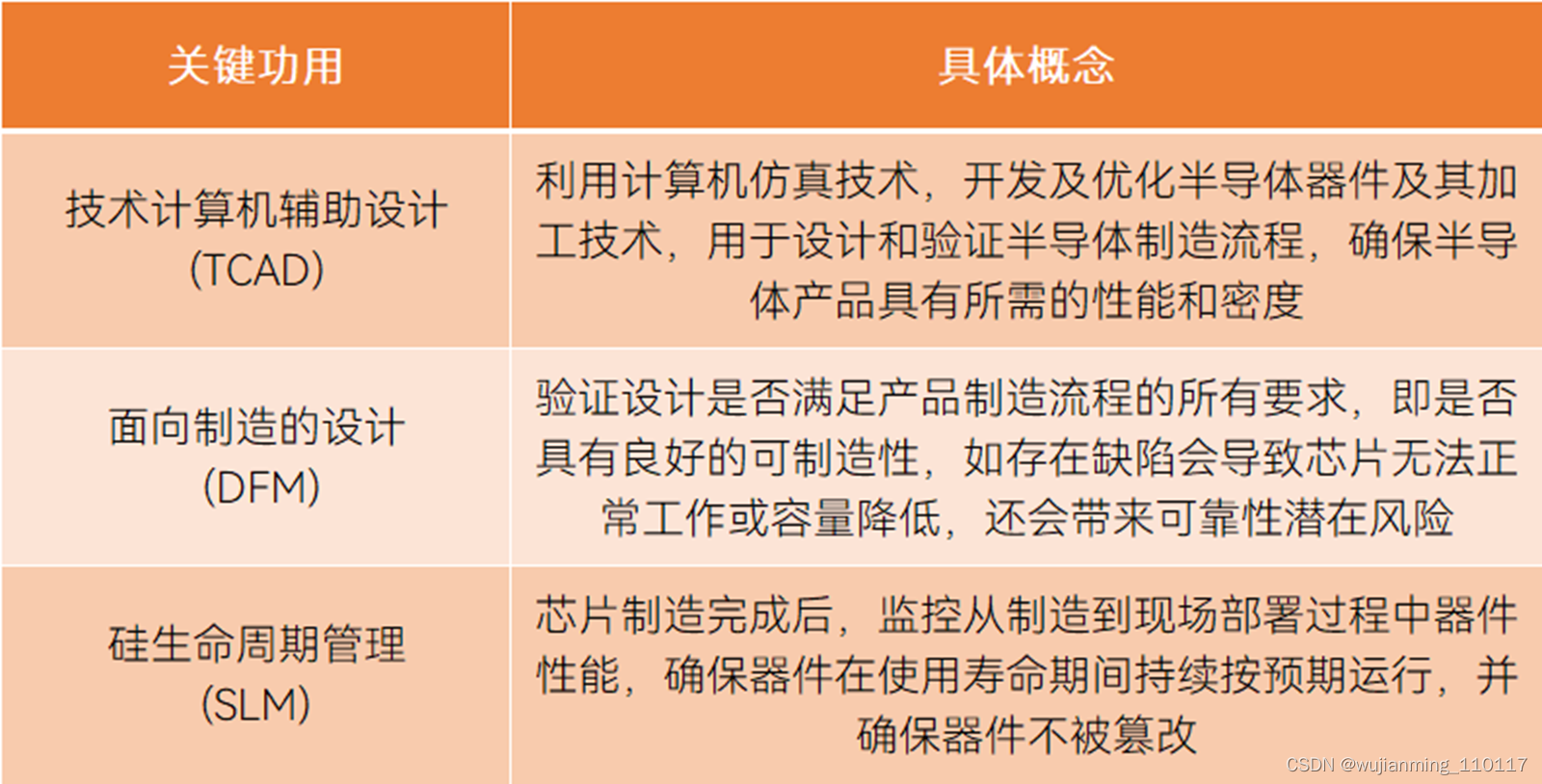
EDA拥有三个关键功用,制表丨果壳硬科技
EDA还与另一个细分市场密切挂钩——半导体知识产权(半导体IP核)。所谓IP核,就是半成品芯片,提供不同复杂度的预设计电路,分为软核、硬核、固核三类。鉴于IP核的使用和重复使用都依赖EDA工具,同时EDA和IP核还可以捆绑销售,通常业界将两者视为一个市场[4]。虽然EDA巨头都拥有自己的IP核产品,但随着市场扩大及IP供应商增加,现在的趋势是将EDA和IP核独立出来。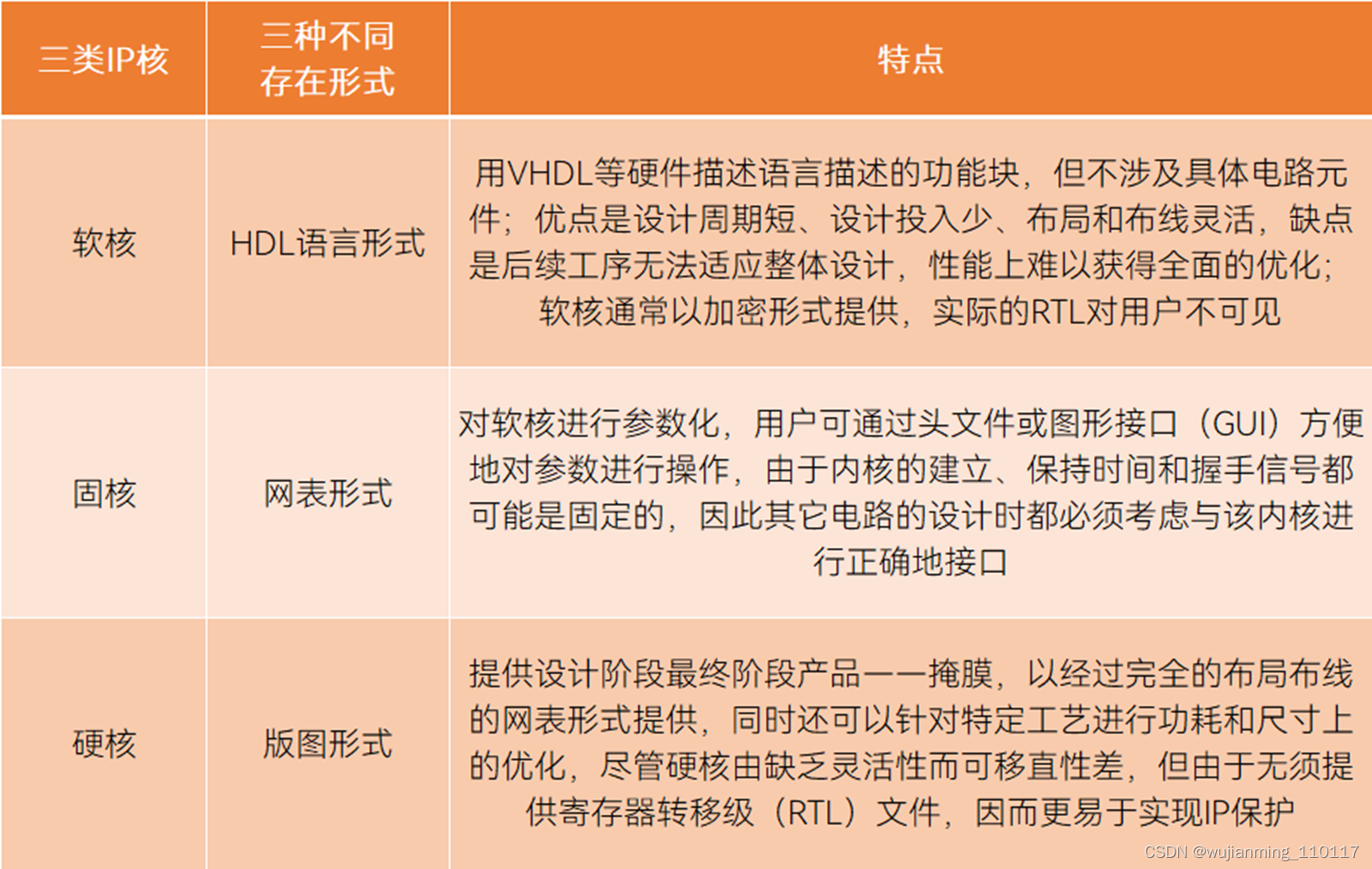
三种类型IP核,资料来源丨方正证券
EDA是跟着集成电路变迁的。经历了CAD/CAM(计算机辅助设计/计算机辅助制造)、CAE(计算机辅助工程)、ESDA(电子系统设计自动化)到EDA(电子设计自动化)四个阶段,阶段转换本质上是芯片描述抽象层级的变化,精度依次提升。
复盘EDA市场发展行径,与晶圆代工、数字芯片等发展历史非常类似,都是从玩家稀少到百花齐放,再到优胜劣汰,并购为仅剩12家、至多34家超大集合体的局面。
1964年~1978年,芯片晶体管密度低,集成度低,企业入局率低, Applicon、Calma和Computervision三家公司主导当时的CAD/CAM市场;
1979年~1992年,CAE成为新贵,相关企业参与率突然急剧上升,转折点在于ASIC(商用专用集成电路)的出现,让设计团队可以接触到以前为大型系统OEM预留的定制芯片,Daisy Systems、Mentor Graphics和Valid Logic三家公司主导当时的CAE市场;
90年代初,技术一路发展,高级语言描述开始应用,ESDA当道,并开启了行业并购,Synopsys(新思科技)、Cadence(官方译名楷登电子)、Mentor(现为Siemens EDA)成为新三巨头;[10]
2009年~2014年,巨头以外的EDA相关专利申请逐渐减少,市场垄断态势初现,小公司被收购,大公司在竞逐中被淘汰;
之后的几年至今,EDA行业继续整合,新思科技、楷登电子、西门子EDA收购许多小型初创公司,包括Forte、Jasper、Springsoft、EVE、Nimbic等,国内EDA融资潮起,一些老牌国产品牌开始挤进第二梯队。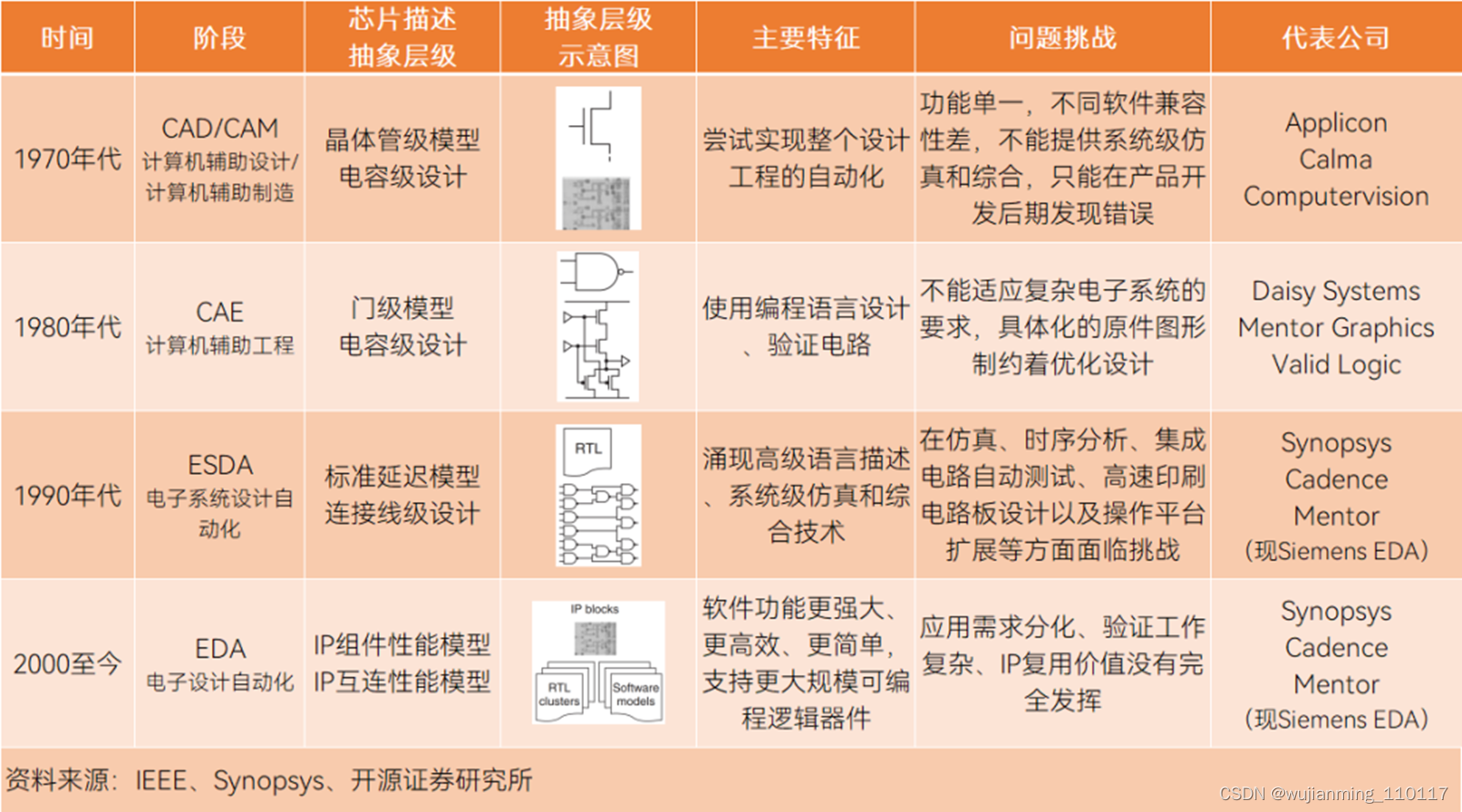
EDA发展阶段及特征,制表丨果壳硬科技
资料来源丨IEEE Design & Test of Computers
EDA不是好做的生意
EDA企业怎么赚钱?一般采取授权(License)的模式,即向客户销售指定版本的软件,并收取合同约定期间的授权费。
授权又分为固定期限授权和永久授权两种形式,可以简单理解为Office 365和Office 2021的关系。对换代要求低的客户大多数选择永久授权,对换代要求较高的客户选择固定期限授权。固定期限通常为1~3年,也可以选择在固定期内多次授权,相当于分期付款。
固定授权是国际更为通行的模式,国际先进大厂均采用此形式,2021年,全行业固定期限内一次授权方式营收占比达55%。这是因为芯片迭代迅速,要面对的物理现象、应用和工艺越来越复杂,这种方式能够获得EDA厂商对工具的实时更新、缺陷修复、技术支持及性能方面升级等。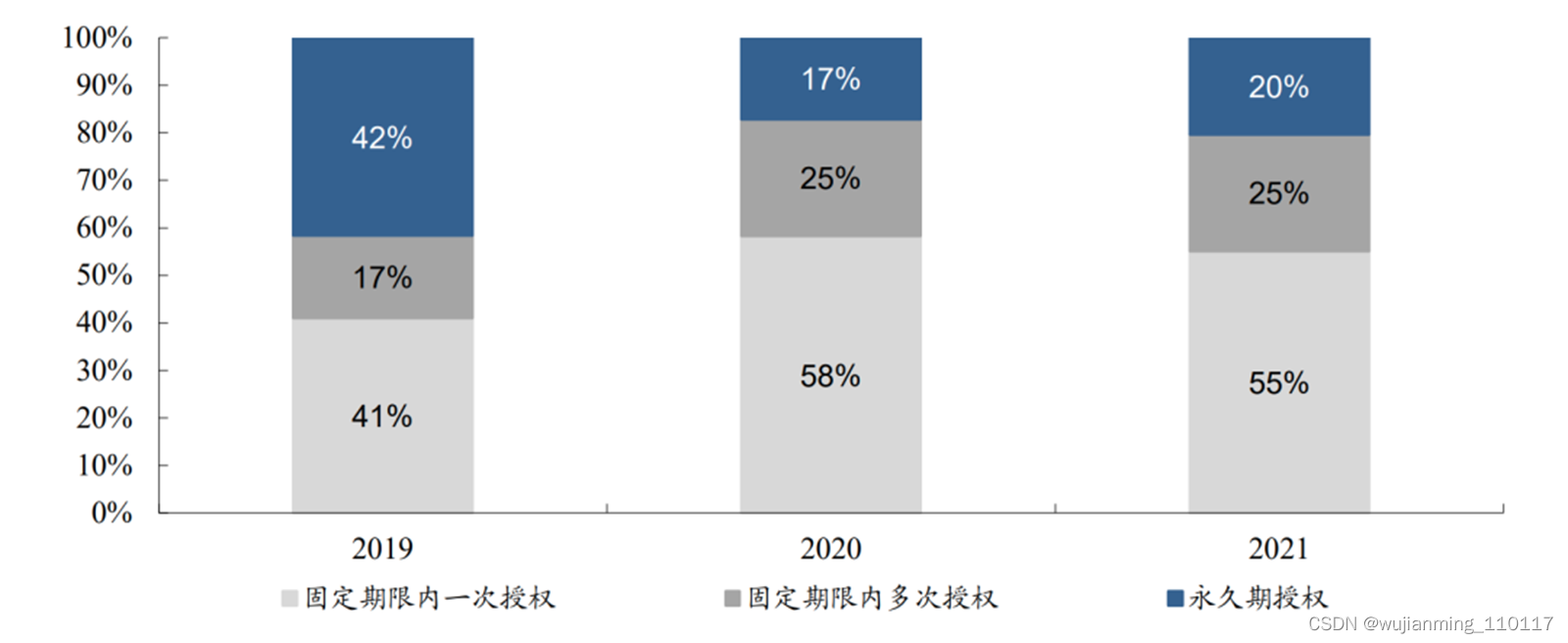
2019年~2021年公司EDA软件销售不同授权模式营收占比,图源丨东吴证券
EDA行业具有明显的可持续增长空间。2020年全球EDA市场营收115.7亿美元,2026年全球EDA市场营收213.6亿美元,年复合增长率10.9%。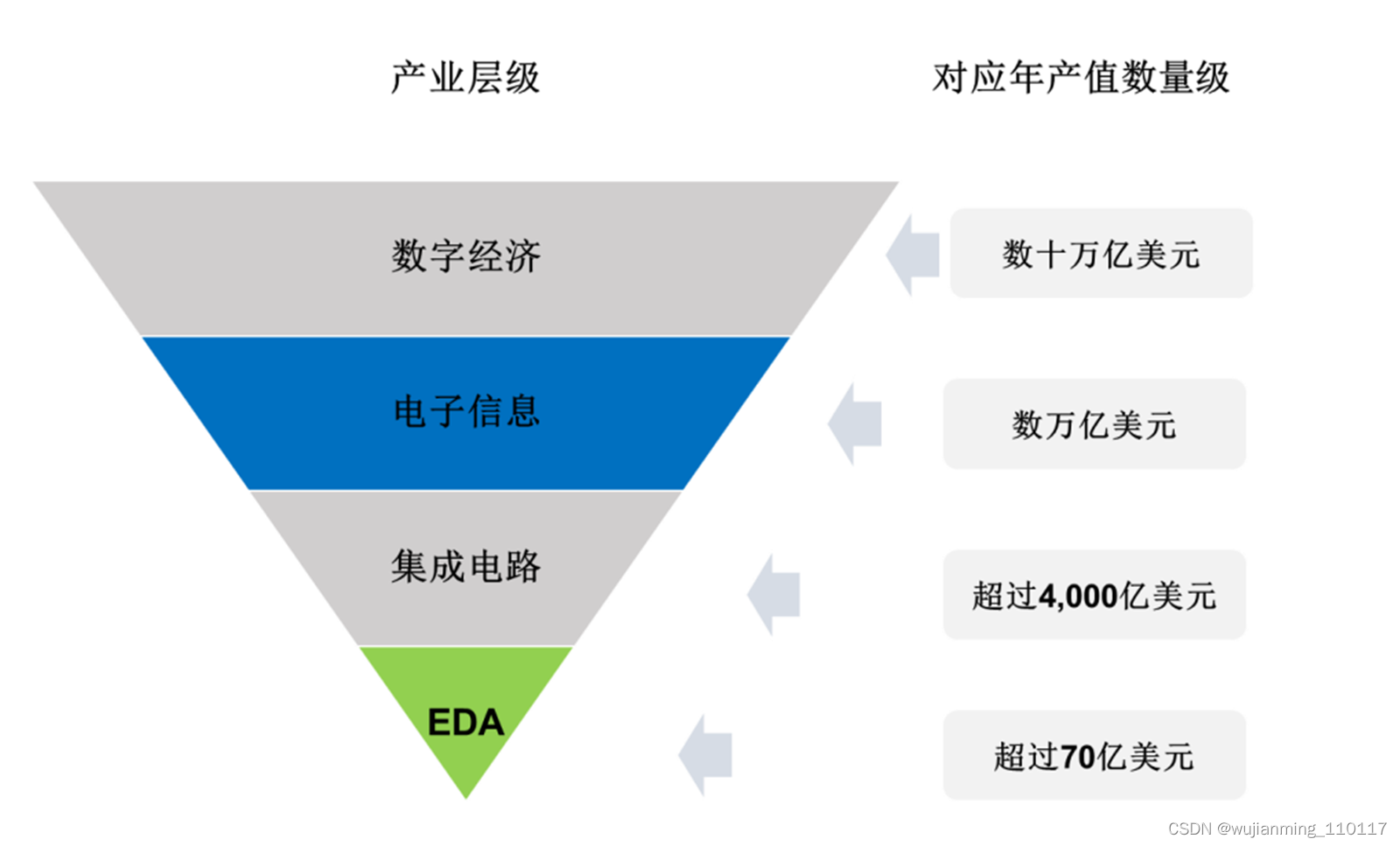
倒金字塔产业链结构,图源丨华大九天招股书
但EDA也绝对不是一门好做的生意。如今,整个市场分为三级竞争梯队,国产最高只做到第二梯队,且份额太小,根据SIA(美国半导体协会)数据,国内EDA/IP占全球市场仅1%。
• 第一梯队由新思科技、楷登电子、西门子EDA三家企业组成,处于绝对领先地位,占据全球78%的市场份额,在中国市场三巨头拥有超过95%的软件销量,拥有全流程EDA产品,业务遍布全球,科研实力雄厚;
• 第二梯队以美国ANSYS公司、Silvaco、Aldec、华大九天等为代表,拥有特定领域全流程产品,在局部领域技术较为领先;
• 第三梯队以Altium、概念工程集团(Concept Engineering)、概伦电子、Down Stream Technologies等为代表,这些企业主要布局点工具,缺少EDA特定领域全流程产品。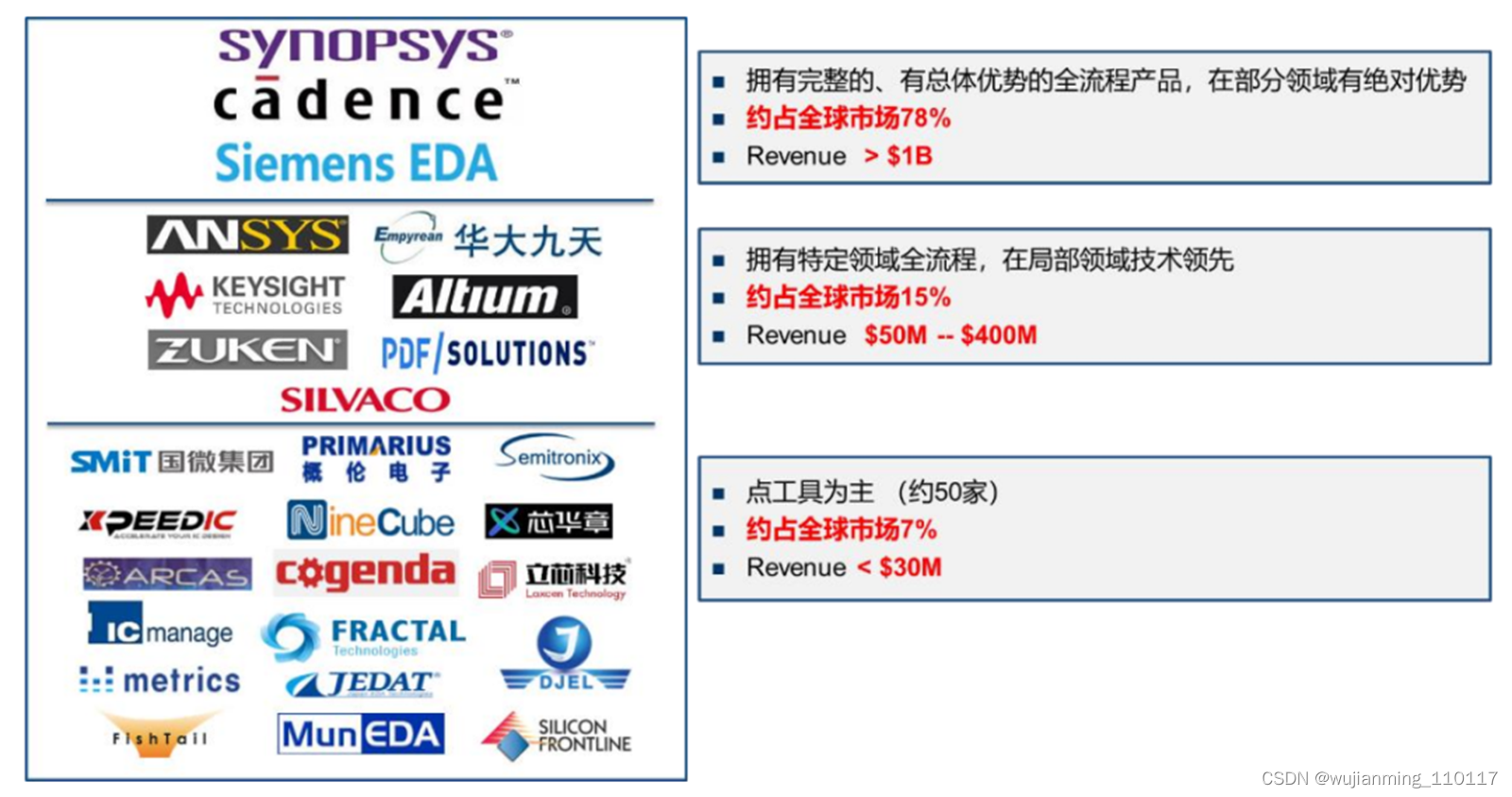
全球EDA行业简要格局,来源丨华大九天招股书
谁处于绝对领先地位,市场规则就由谁制定。但实际上,新思科技、楷登电子、西门子EDA三家公司在市场上的竞争也极为激烈,虽然三家公司整体运营思路相同,但策略也不尽相同。
新思科技在营收、业务等方面无疑是规模最大的EDA相关企业,但单从EDA产品线来看,楷登电子与新思科技持平,甚至在往年更胜新思科技一筹。从战略上来看,新思科技强化软件集成型产品发展,通过频繁并购平均发展旗下各产品线的产品实力。楷登电子实力底蕴扎实,并购动作相对较少也能保持EDA营收稳定增长。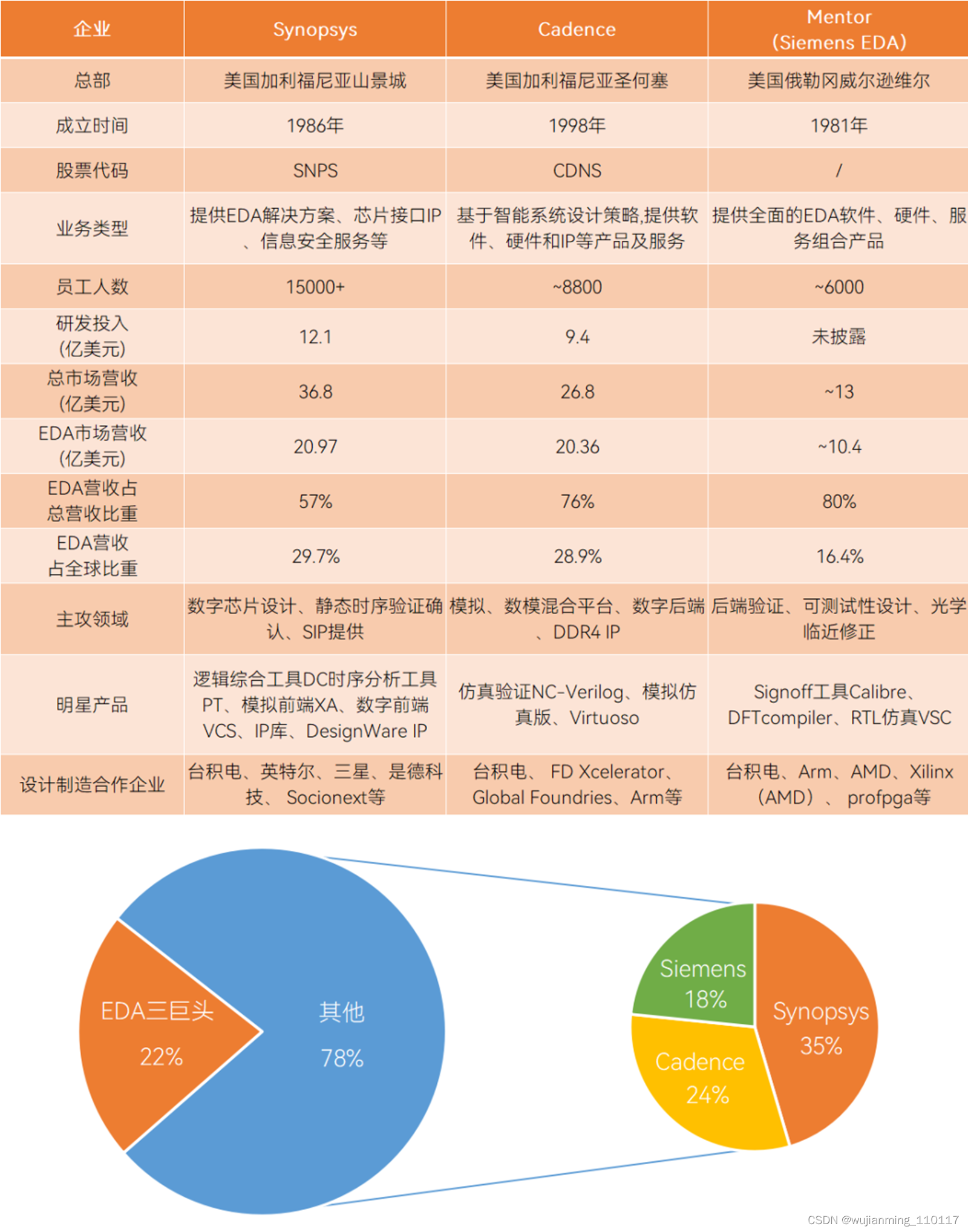
EDA三巨头基本情况对比,制表丨果壳硬科技
资料来源丨EDP Sciences,《军民两用技术与产品》,《中国集成电路》
国内EDA发展曲折缓慢,直到2008年后才开始崛起:早在1981年~1985年,国内便陆续开发ICCAD一级系统和二级系统;1993年,熊猫系统问世;但之后15年里,受“造不如买,买不如租”观念影响,国内EDA被拉开差距,彼时正值新思科技、楷登电子、西门子EDA上升期;2008年,EDA重新成为重点,华大集团将EDA部门独立出来,名为华大九天;2010年,概伦电子成立;2021年12月,概伦电子科创板上市;2022年7月,华大九天创业板上市。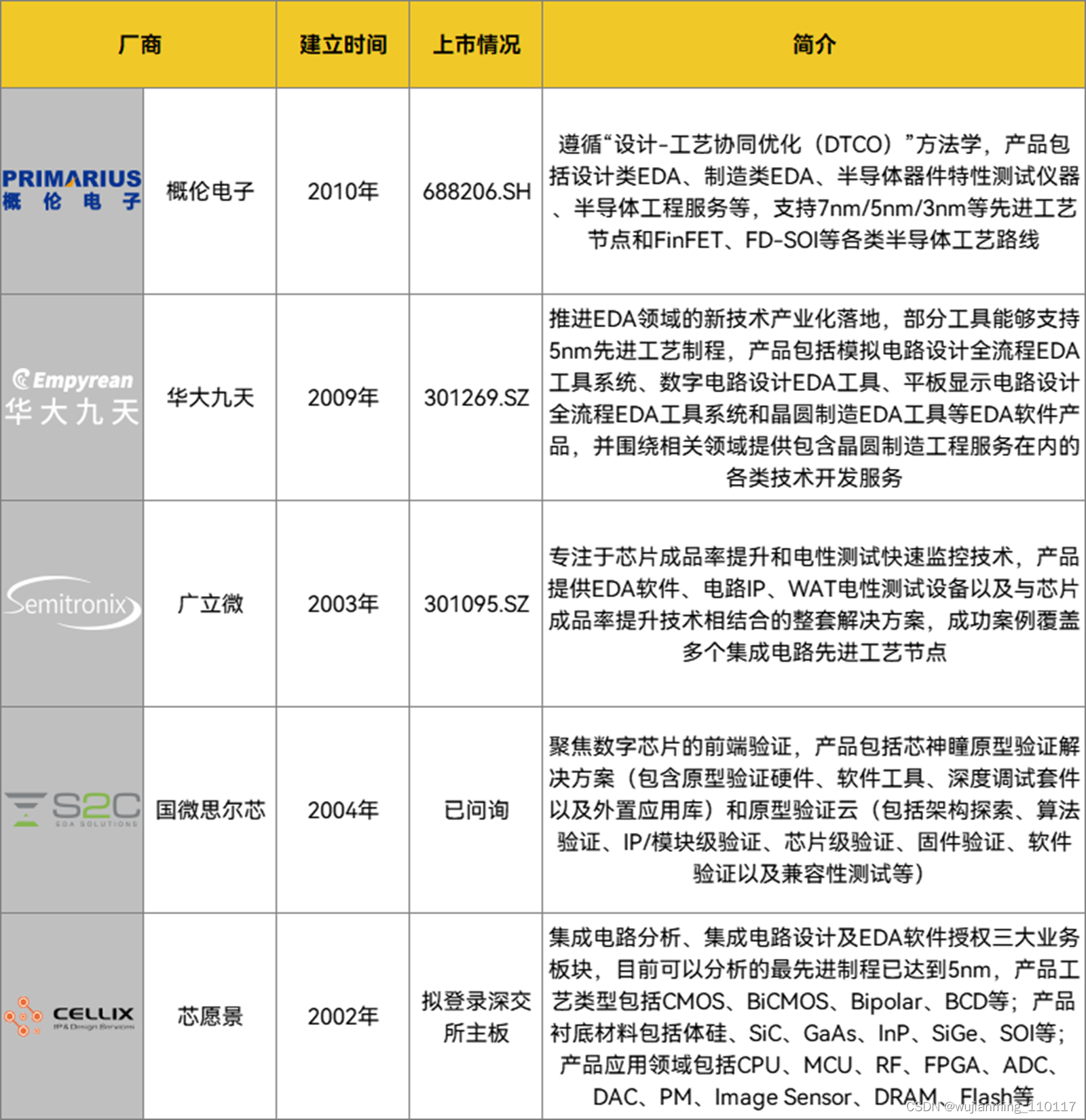
国内EDA二级市场情况不完全统计,制表丨果壳硬科技
在国产替代风潮下,近两年EDA一级市场非常活跃,融资金额一度达到11亿元人民币。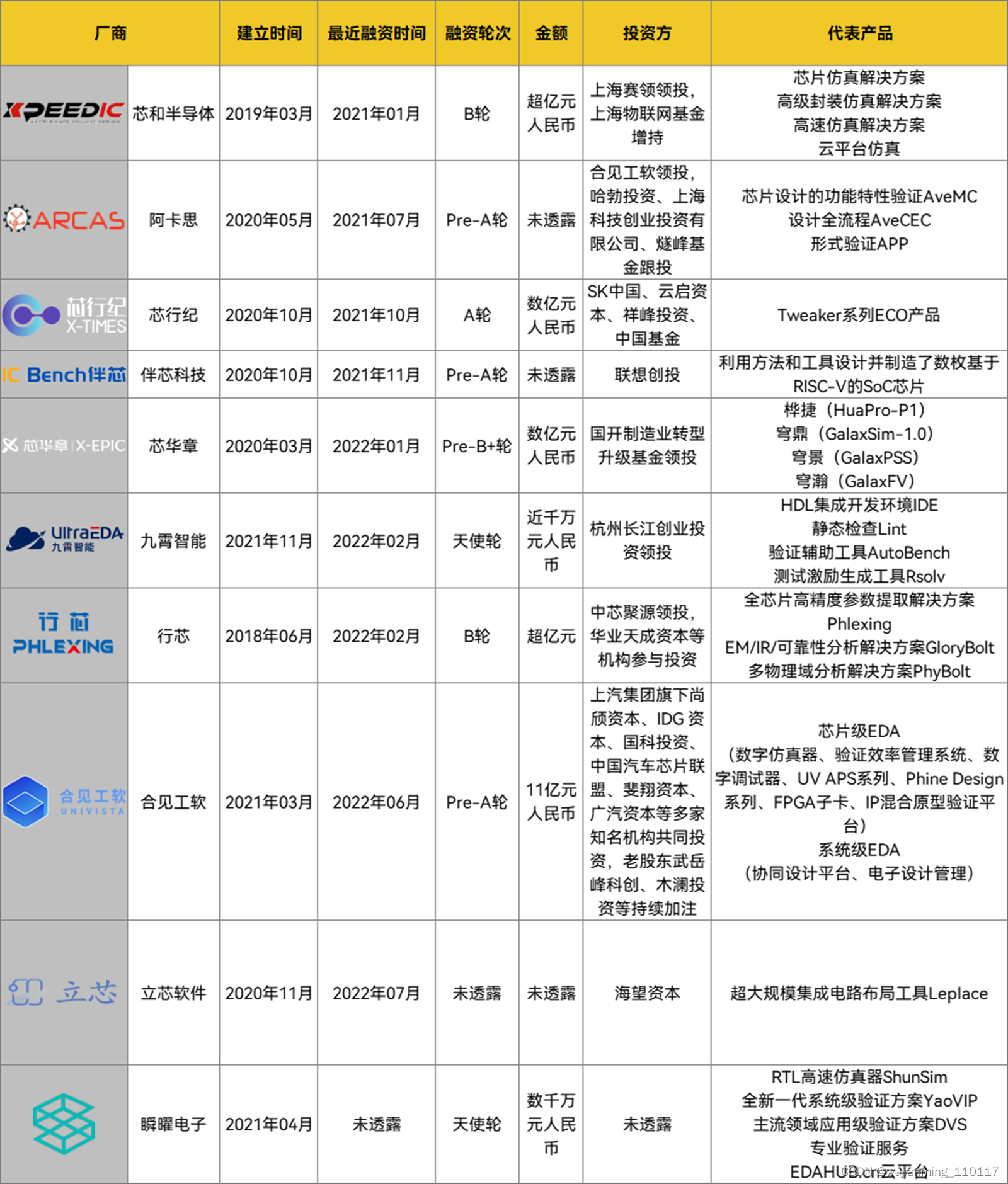
近两年内国内EDA一级市场情况不完全统计,制表丨果壳硬科技
仍然需要指出的是,国产EDA以点工具为主,工具链不完整,三巨头则覆盖了产业链的各个方面。另外,国产EDA目前尚不能满足尖端制程的要求,由于EDA处在最上游位置,因此EDA必须比芯片的工艺更先进。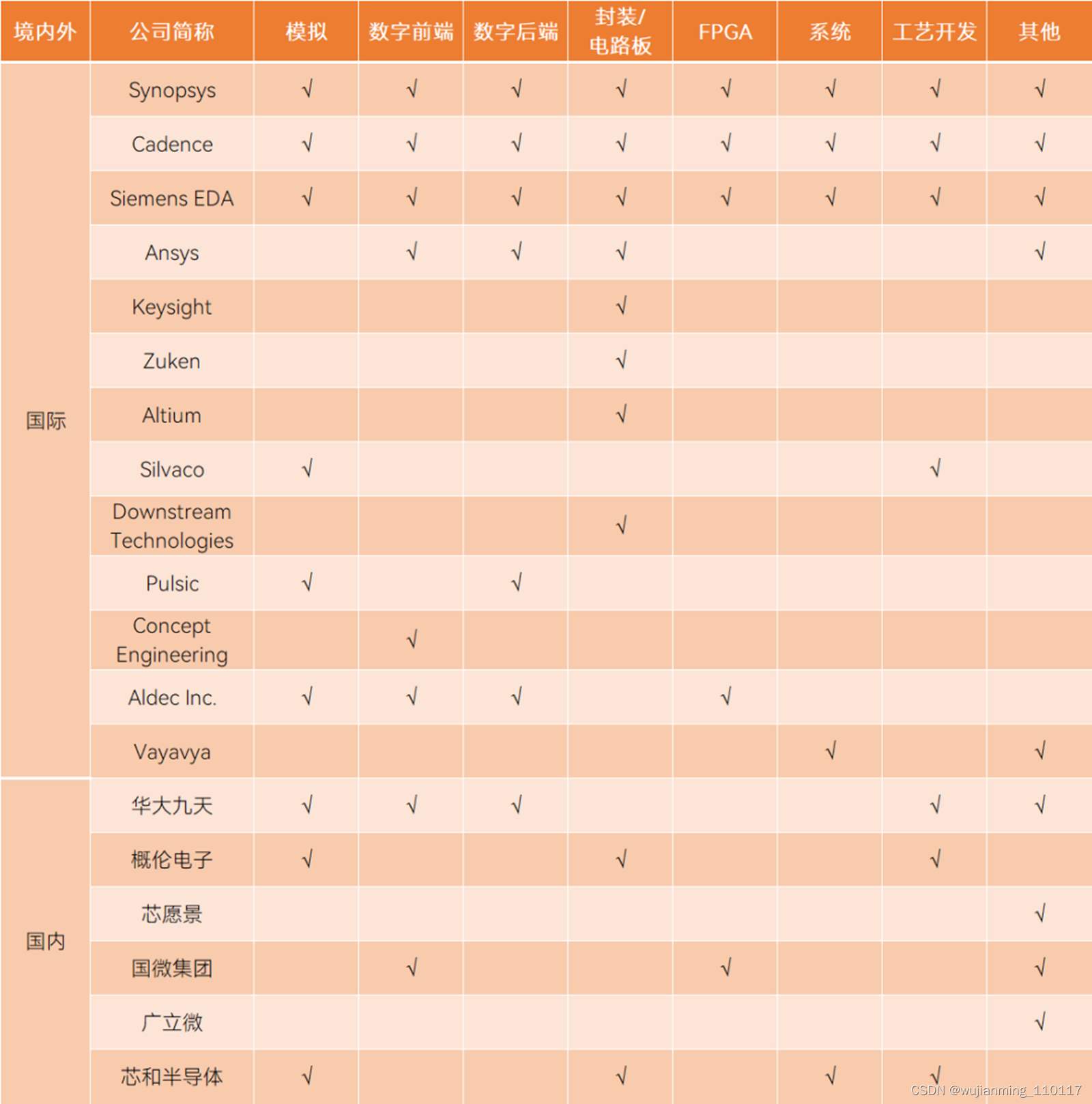
国内外EDA支持工具链对比,制表丨果壳硬科技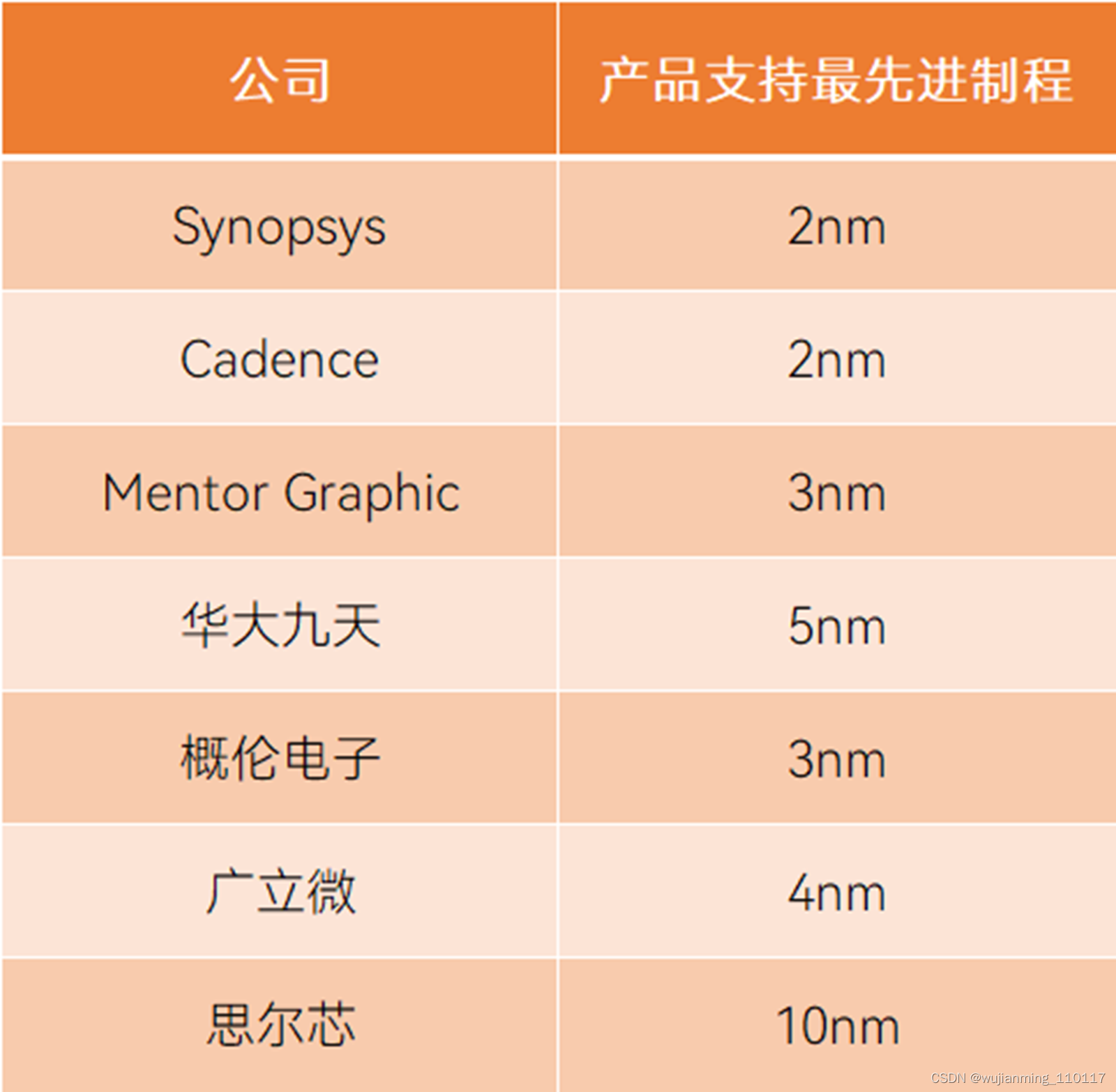
国内外企业EDA产品支持制程对比,资料来源丨头豹
夹缝求生,还能怎么走
在高度垄断之下,国产EDA究竟有哪些还能走的路?果壳硬科技团队认为有如下几点:
• 投入打在关键点上
EDA需要的投入金额惊人。新思科技和楷登电子十年来净利率大多数年份不超过15%,但却从未因公司经营状况不加而降低研发投入强度,研发占比全部高于30%,甚至部分时间研发占比超过40%。对于较小的EDA公司,这个数字可能会更高。
高额投入意味着三家巨头竖起了专利高墙,专利围城导致国产处境极为尴尬。近两年,所有半导体公司都开始建立一系列自己的知识产权,希望与竞争对手保持安全距离[24],国产也需要自己的专利。
通过统计三巨头在EDA关键技术专利数量和分布情况来看,发展程度、重点和专长上没有太大差异,但研究基本集中在“验证”“仿真”“布线”三个主题上,“时序分析”和“综合”两个部分研究还不多,这意味着“时序分析”“综合”是能拉开技术差距的部分[18]。另外,“验证”占芯片设计总成本70%以上,是国产EDA正在突破的领域。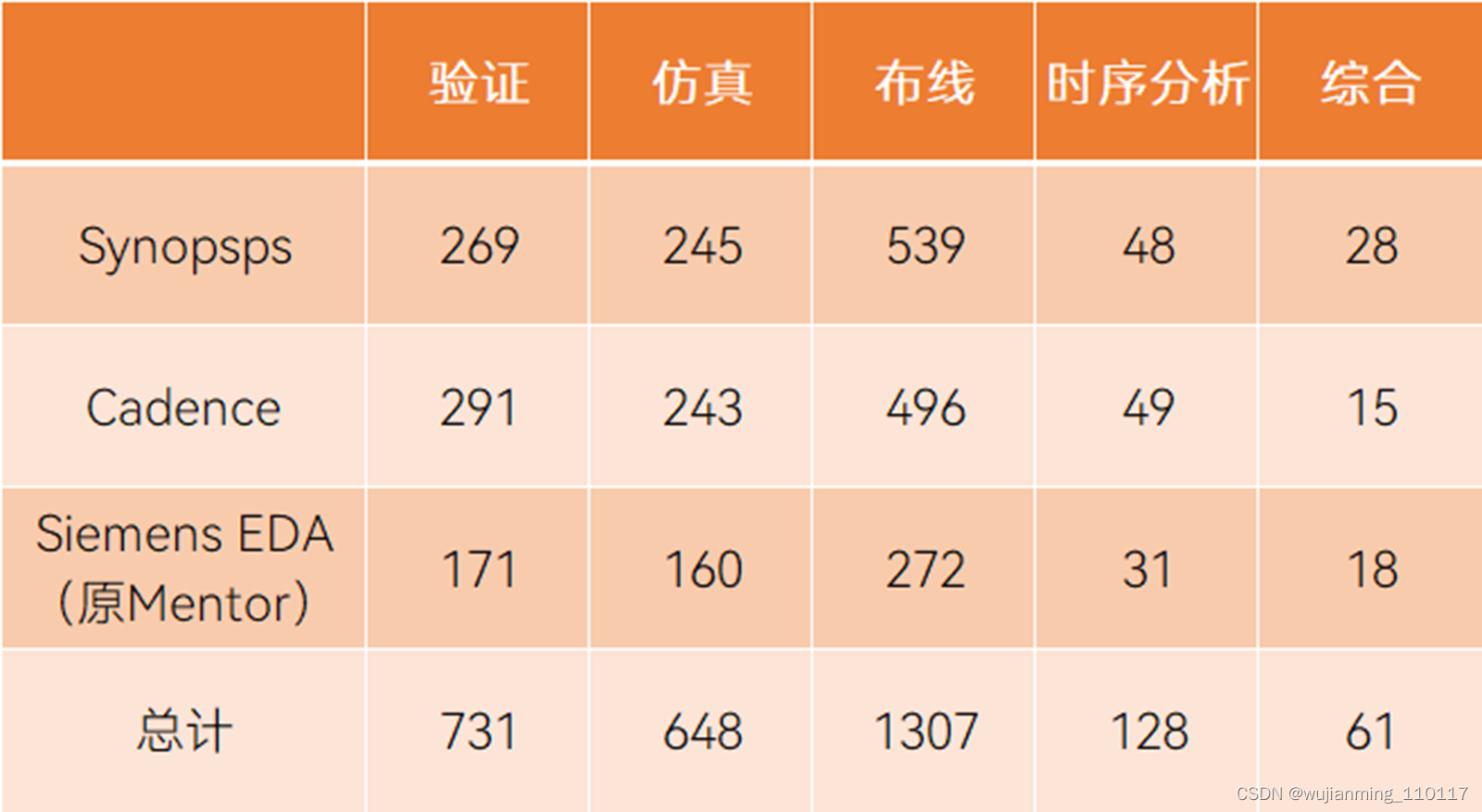
三大巨头关键技术专利数量和分布情况,信息来源丨EDP Sciences
• 发展Chiplet是关键点
传统芯片是将所有器件放在单一裸晶(Die)上,功能越多芯片尺寸越大,Chiplet(小芯片)是将大尺寸多核心分散到多个微小裸芯片上,如不同类型的处理器、模拟组件、存储器等,再用3D立体堆栈的方式,像搭积木一样组合在一起。
Chiplet有多重要?AMD、英特尔、英伟达等头部IC设计企业都推出过基于Chiplet技术的产品,苹果也准备在下一代高端处理器中采用Chiplet技术[27]。为了让Chiplet更好发展,Arm、AMD、Meta、英特尔、谷歌云、微软、高通、三星、日月光和台积电还发起了UCIe产业联盟。
实现Chiplet,EDA是关键。目前来说,Chiplet的最大问题是如何将部件组合在一起,谁来将这些部件组合在一起,国产EDA可就这些问题进行研究。
• 做更好用的EDA工具
以软件为核心的EDA,好用,让更多人能用才是王道。
近年来,随着芯片设计基础数据量和系统运算能力上升,AI(人工智能)和云技术开始深入EDA。这种模式也逐渐被行业认可,用户的使用习惯也随之改变。另外,传统SoC设计需要在RTL级别下使用硬件描述语言进行逻辑、验证,后来EDA逐渐开始支持C/C++/SystemC,学习晦涩难懂的语言不再是硬性要求。
这种变化得益于设计方法学的进化,最终目的在于提升设计效率、确保设计正确性、提升芯片生产良率、加速设计流程,国产EDA也应当遵循这种模式进行发展。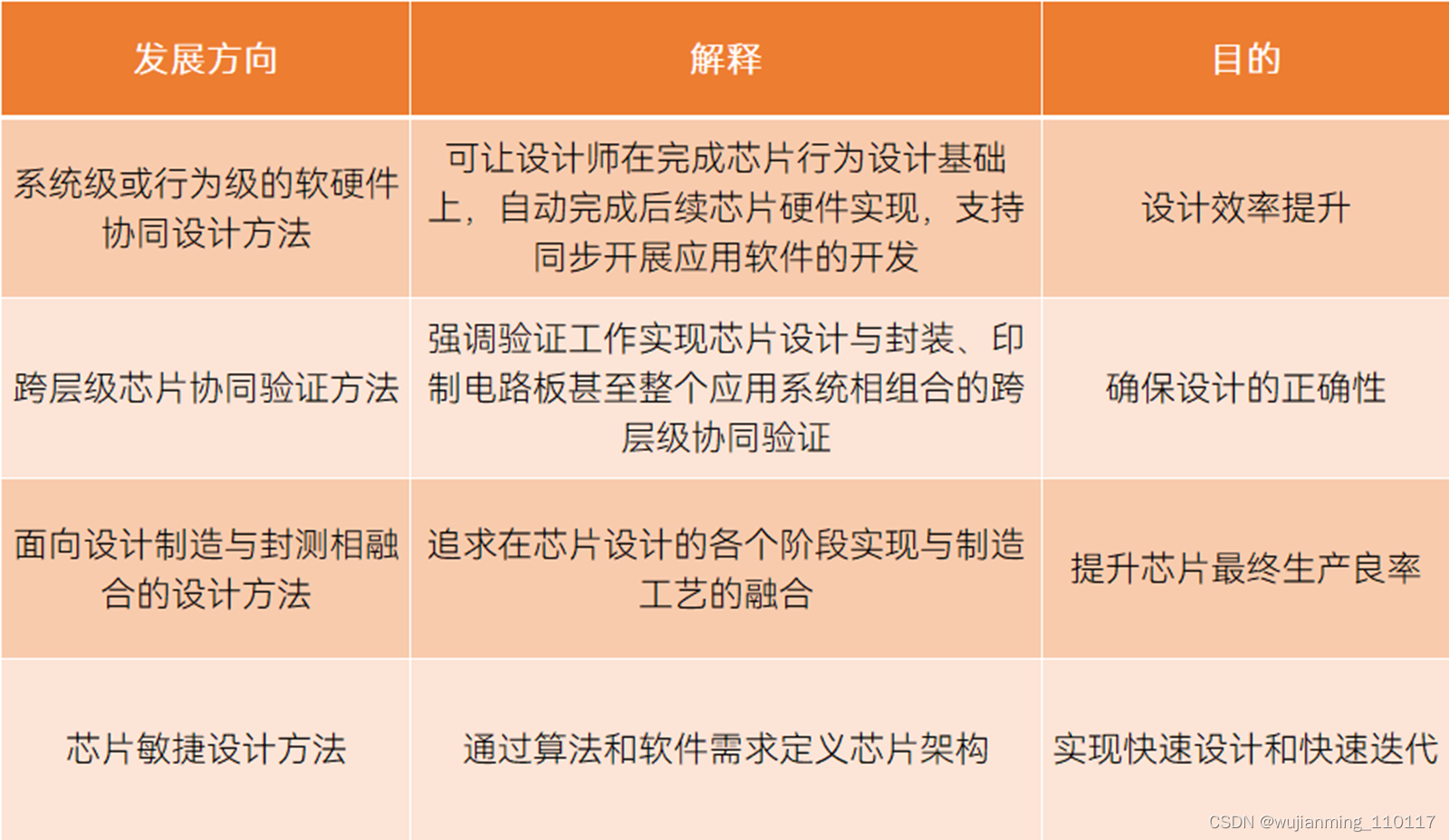
EDA工具在设计方法学层面的发展方向,资料来源丨华大九天招股书[16]
• 开源化增强EDA领域研究
近几年,开源风潮盛行,诞生了开放的硅知识产权生态系统。开源EDA工具能快速引导国产EDA找到方向,同时还能为科学发展创造了全新生态系统。
开源EDA有五大可行性:其一,能够快速识别最新基准测试结果,从而可以快速确定新的EDA解决方案,推动技术发展;其二,开源工具能够加速EDA研究,可以在现有开源工具和组件的基础上以更快的速度实现迭代,降低进入门槛;其三,由于EDA改进可能会被下游工具所掩盖,完整开源的EDA工具能够确保改进坚持到最后;其四,具有标准I/O格式交换的开源工具,能够在开源工具和闭源工业间形成健康的生态系统,加快学术界和工业界知识传播;其五,开发者社区能够发现更多后门或漏洞,能够带来更值得信赖的设计过程。
• 各种力量应该拧成一股绳
EDA贯穿芯片整个产业链,各个工具也环环相扣。三巨头均不同程度地采取收购整合方式,实现全流程工具的覆盖。国内目前仅有华大九天一家公司实现部分设计全流程方案,整体市场仍然呈现碎片化、地理化分散。

EDA工具的两种突破方案对比,图源丨华福证券
推进整合并非易事,何况国产EDA仍处在初期,不具备大规模并购条件。因此,国内可采取更为特色化的整合形式,通过行业龙头牵动行业合作,加之政府扶持,因势利导,形成合理的互惠模式。具体拥有三种销售形式:
• 捆绑销售:采取多个公司点工具的捆绑式销售,并让工具之间产生关联;
• 定制开发合作:大型EDA厂商向小型厂商定制开发,后者完成开发后,双方共享产权和技术,实现合作共赢;
• 产业孵化:先发展起来的EDA厂商为有技术基础的初创企业导入业界资源。
另外,人才和团队、技术和产品、市场和生态、资金与政策、法律与规范、软件与硬件六大因素对EDA来说缺一不可,但现今EDA领域人才短缺,技术覆盖不全面,生态建设不完整。这背后需要政府主导、资本市场助力,发挥了产学研集成效应,带动集成电路发展。
当国内力量都拧成一股绳时,继而可构建自主的标准化。现如今,EDA所设领域广泛,体系和功能繁杂,标准化工作涉及的范围也很广,国内可进一步推进自己的标准化工作。[34]
当各种资源整合在一起,占领市场必然会水到渠成。
参考文献链接
https://mp.weixin.qq.com/s/XFtGmGJE9tWCbsPgaCyXJQ
https://mp.weixin.qq.com/s/eUGDEqnP5d1bnlerfabyVg
https://mp.weixin.qq.com/s/ExsUyaTLW2UDUhVmcyaQaw
https://mp.weixin.qq.com/s/KmpUJcFKL2mj6rs9cknODQ
https://mp.weixin.qq.com/s/k3BAnvt1UBwpgg-qNNv8pg
https://mp.weixin.qq.com/s/s7Od97ZctPDyWfn8I-J1LQ
边栏推荐
猜你喜欢

又有大厂员工连续加班倒下/ 百度搜狗取消快照/ 马斯克生父不为他骄傲...今日更多新鲜事在此...
The batch size does not have to be a power of 2!The latest conclusions of senior ML scholars
win10编译x264库(也有生成好的lib文件)

1-hour live broadcast recruitment order: industry big names share dry goods, and enterprise registration opens丨qubit·viewpoint
2022年非一线IT行业就业前景?
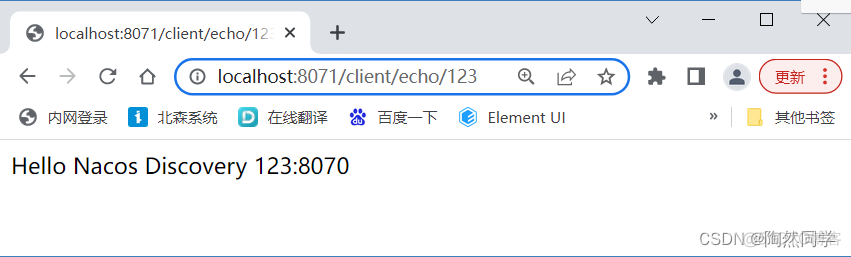
【微服务~远程调用】整合RestTemplate、WebClient、Feign
h264 protocol
Ten minutes to teach you how to use VitePress to build and deploy a personal blog site

无需精子卵子子宫体外培育胚胎,Cell论文作者这番话让网友们炸了
无重复字符的最长子串
随机推荐
Do you know the difference between comments, keywords, and identifiers?
00后写个暑假作业,被监控成这笔样
Go-based web access parameters
腾讯发布第二代四足机器人Max,梅花桩上完成跳跃、空翻
非科班AI小哥火了:他没有ML学位,却拿到DeepMind的offer
激光熔覆在农机修复强化中的应用及研究方向
已解决IndentationError: unindent does not match any oute r indentation Level
自定义VIEW实现应用内消息提醒上下轮播
生成上传密钥和密钥库
正则引擎的几种分类
JVM常用监控工具解释以及使用
Scala Advanced (7): Collection Content Summary (Part 1)
工作任务统计
Rust from entry to proficient 04 - data types
大佬们,请教一下,我看官方文档中,sqlserver cdc只支持2012版之后的,对于sqlser
Adalvo收购其首个品牌产品Onsolis
WebView injects Js code to realize large image adaptive screen click image preview details
ABP 6.0.0-rc.1的新特性
西湖大学教授怎么看AI制药革命?|量子位智库圆桌实录
Flutter入门进阶之旅(四)文本输入Widget TextField