当前位置:网站首页>西湖大学教授怎么看AI制药革命?|量子位智库圆桌实录
西湖大学教授怎么看AI制药革命?|量子位智库圆桌实录
2022-08-09 11:55:00 【QbitAl】
量子位智库 发自 凹非寺
量子位 | 公众号 QbitAI
一边是产学研屡屡传出新进展的计算生物。“地球上几乎所有已知蛋白质,均能被AlphaFold预测。”
另一边是投融资瞩目,但质疑声不断的AI制药赛道。“国外一笔331亿元订单顶传统药企一整年收入;国内市场规模保守估计2040亿。”
前者首要的落地场景,非AI制药莫属。而后者所面临的数据瓶颈、效率迭代等质疑,是否能通过计算生物来解决?两者究竟应该如何结合?
AlphaFold2传出新进展之后,能否对蛋白质类药物设计会带来革命性影响?
带着这些问题,量子位对撞派「AI制药&计算生物」专题邀请到西湖实验室人工智能药物设计核心实验室主任黄晶教授,与我们一起进行了深入交流。
Q1:大家都会只要一提到计算生物学,然后都会觉得无论是时间还是重要性来看,首要的落地场景应该是在 AI 制药。您同意吗?
A2:我非常同意。因为生物学最主要的落地场景就是制药。同样的类比,计算生物学的最主要的落地场景就是用计算来做药物。
从更宽广的一点的视角来说,计算生物学是以计算为主要手段来研究生物学。那么对于生物学这项科学的探索,最终基本归为两种,一种是理解生物学的基本过程,另一种就是开发手段想办法去调控这些生物学的基本过程。如果开发出来的手段如果能够满足比如说安全性、递送载体等要求,那这自然而然地就是一个药物,在最广泛的定义上的一个药物。
Q2:计算生物学对于 AI 制药来说,它会更多的集中在哪个部分,最大的意义会是什么呢?
A2:现在比较常见的应该是三个场景。最主要的一个是分子设计,不管是小分子还是大分子,比如说抗体或者是ADC等等。
用 AI 计算的手段来做理性的分子设计,某种程度上其实就是预测特定分子作用于特定靶点的效果,然后用实验来验证并进一步预测怎么对分子做修改能够达到更好的效果。除了对于靶点的效果,也可能是对于分子本身性质的修改,比如说修改蛋白,让它的稳定性更高,或者让它的免疫原性更低;对小分子的修改让他在体内能够待的更长的时间,让它的吸收和代谢性质变得更好。
这是在我看来,目前这个阶段计算生物学对于 AI 制药最大的贡献和最重要的一个落地场景,也有巨大的潜力。虽然在药物发现的整个pipeline上,后端的临床实验有大量的金钱、人力、物力和时间的投入,但是临床阶段的成功与否某种程度上完全取决于在临床前研究的分子性质如何。真正好的分子能够给临床方案的设计和开展提供足够的空间,也会减少制剂、生产等环节的复杂性。那么如果有更准确的分子性质预测和profiling,药物发现的成功率就取决于靶点本身或者对生物学过程理解的深刻程度。
这就会提到计算生物学对 AI 制药的另一个意义或者说另一个应用场景,实际上就是对于靶点的发现和理解。其实也不限于此,高水平的组学或者说计算生物学,能够在非常复杂的数据中看到更多的事情,不仅仅是特定蛋白、特定基因和一个疾病的相关性,而是能够真正帮助人们,辅以一些实验,来理解特定的生物学过程。我觉得对于靶点和疾病之间关系的理解,是计算生物学非常非常重要的一点。这一点也是在整个药物发现流程里最前面的一个,就是靶点的确认。
最后一个我认为现在大家做的很多的场景,也是技术比较成熟并值得去做的是药物重定向。我想在 AI 的帮助下,在计算的帮助下,大家可以把重定向做的更加精细,对于特定的疾病去做细分。也就是说我们的目标不是去开发一个新的小分子药物,而是找到小分子最能有效调控的特定生物学过程,甚至在特定人群中的生物学过程。这里可以分为几部分,一部分是说特定的小分子药物,在之前做的临床可能不是一个正确的适应症,或者说不是在对一个正确的人群做临床,那么它可能不成功;或者哪怕它临床成功,可能可以更适用于另外一个疾病或者另外一个人群。另一部分还有组合用药,这也是我想许多做计算生物学的人都想要的,如何去预测组合用药,甚至可以扩展到个性化用药,背后一定是大量的计算生物学作为支持。
Q3: 您刚刚提到了个性化制药,您能在技术上介绍一下他的技术流程和数据需求吗?因为其实现在尽管大家都有这样一个设想,但似乎并没有看到特别多的实践。
A3: 对,某种程度上同时需要技术进步和数据积累这两点。我们需要有很多高质量的数据。可以想象,我们拿到大量的药物分子,不管是在细胞层面或是说在动物层面,对各种基因表达的调控情况,然后利用这些数据建立计算模型,预测什么是最好的调控方法。这是一个很框架性的东西,概念非常简单,之所以现在很难看到真正落地的原因,是因为如同我们之前讲过的一样,要让这个流程成功,需要确保数据的质量,必须通过很多细微的技术改进和进步。很多人正在做这件事情,我相信在很短的将来,会有一系列重要的工作出来。这样的话产业界进来,他们的工程能力和资源调度能力也会更强。
Q4:那我们说回制药领域的计算手段。现在的AIDD之前还有一个CADD。那从这个 CADD 走到今天,用 AI 来做这个计算后最大的提升会在哪里?会不会有计算重点的转移?
A4:会的。之前所说的 CADD ,在各种不同的应用场景里面都有比较典型的、特制的计算工具。这些工具的预测准确性是不高的,就是说在每一个环节其实你都能找到工具,但是它的准确性都不高。比如说预测一个分子的logP,它可以很容易做,但是准确率不高。然后预测一个分子和靶点的结合能,比如说最常见的 docking (分子对接),准确性是不高的。某种程度上,分子对接只是用来产生猜想的工具。
从 CADD 到 AIDD 我觉得是有两个变化,一个变化是在一些关键的环节上面,我们真的有可能大幅度地提升预测的准确性,从而使得计算可以被信赖。另一点是 AI 制药可以提供一些理论或计算方法上的框架,使得我们可以综合地来考虑不同的事情,就是说我们可以把之前分散在药物设计不同阶段或者不同地方做的计算,统一在一个大的框架下面,然后实现一定程度上的端对端的预测。
Q5:您觉得计算生物有没有可能在制药领域开辟一块新的思路,或者说带来一些新的完全不同的药物呢?
A5:这方面,我没有看到这一点,我看到的是很多 AI 制药的公司在努力去跟随传统制药公司的思路。
回到蛋白药物上面来说, AlphaFold 确实带来了巨大的进步,但是它离蛋白质药物设计其实还是有一定距离的。它只是给蛋白质药物设计打开了新的大门,门后可能还有或长或短的路要走。真要做蛋白质设计的话,会有很多除了产生特定结构的序列之外需要考虑的事情,这是 AlphaFold 现在并不提供的。某种程度上说在蛋白质设计或者蛋白质药物设计这个行业之前是有绝对的垄断现象存在的,David Baker基本上是这个领域的寡头。Alphafold的推出使得全世界做蛋白质药物设计的人们某种程度上重新站在了同一个起跑线上,对行业来说应该是巨大的改变。但是具体的蛋白质设计概念其实之前已经由Baker、甚至更早的DeGrado他们建立好了。
在我看来,目前的 AI 不管是对于蛋白药物还是小分子药物,都还没有任何一个东西像AlphaFold 这么好。但是如我刚刚所说的,即使AlphaFold在我看来也不是说全新的东西。大家在没有AlphaFold之前,大家就知道我们可以怎样来设计全新的蛋白,新的技术进来让大家能够更有效率、更好的来做这件事情。
Q6:尽管大家会说这个计算生物它最重要的一个应用是 AI 制药。但其实他们又会说,对于 AI 制药来说,计算生物也只是其中的一个模块而已。那如果我们就只从技术的角度来说,除了计算生物学,AI制药还会它会包括需要哪些其他技术的一个配合呢?
A6:我从另一个角度来回答这一点,就是在 AI 制药的这个大的范围内,除了计算生物学的部分,还有哪一些?我想当然还有计算化学的部分。这里举个最简单的例子,药物的制剂是非常重要的东西,我们会看到AI非常强大的应用,怎么去预测,给定一个分子,什么是最好的辅料,什么是最好的配方。这是AI大有可为的一个地方,但更多地是一个基于化学的计算。当然也基于一定的生物学,因为制剂的目的是为了让分子在体内的吸收,然后它的分配、代谢达到一个最优的状态。所以这里面也有一些通常来说并不被认为是计算生物学的内容,但这是一个 AI 能起到非常重要作用的场景,是 AI 制药的一部分。
Q7:无论是计算生物还是计算化学,甚至包括有一些材料的设计,就是它底层可能都是跟一些物理模型有关,比如说包括结构,然后包括能量,底层都是同样的东西,然后可能再进一步在生物里面体现为这个分子动力学等等,您对这个观点会就是怎么看?
A7:对于这个观点我既赞同也不赞同。我赞同的是对于分子设计来说,不管是电池里面的一个高分子或者是一个多肽分子,他们都是有机分子,由碳氮氧氢这些构成。在这个层面上来考虑问题的话,当然他们需要共同的描述方法和动力学预测方法,可以整合在一个统一的计算框架下面来考虑问题。我自己做很多蛋白质的计算模型,在小分子层面,小分子和蛋白相互作用、蛋白之间相互作用在我们看来都是同样的事情。在这一点上,我的看法是它们可以用一致的模型描述,归根结底都是能量相互作用,然后面临的问题很有可能都是采样,在相空间中怎么去采样,然后怎么去算对自由能。
但是如果在一个更广阔的考虑来看,就是说计算生物学还包括更多更宏观的部分。那么比如说在基因水平上面,在转录组上面,这些层面上发生的事情在某种程度上是离原子分子的描述是很远的,我们还没有任何真正有效的计算手段能够在这里从上到下用所谓的多尺度来勾连在一起。在这个意义上说我不赞同,在基因水平上面的计算是自成体系的,即使也会使用能量或者熵这样的名词,但和分子体系里的概念是不相关的。当然他们也是非常重要的,有一整套理论和计算手段。
Q8:尽管 AI 制药这个概念现在其实还蛮火的,但其实现在比较明显的成果还是比较少的。您觉得是现在技术原因的限制,还是说有其他原因?
A8:坦白地说,我认为技术上面还是有比较多的缺陷。像很多 AI 制药的一些技术手段还没有被证明完全或者系统性地以可靠的方式比CADD 的手段更好,当然这一点是很多人在努力的方向。
某种程度上,我想这也说明,在技术上面还有很大的提升空间。我们能看到 AI 制药的潜力,是因为我们确实能看到一些特定的例子,可以利用 AI 达到之前从来不能达到的效果。但是要把它变成一个行业里面的标准方法,那需要它能够稳定可靠或者说持续性地达到很好的效果才行,我认为这需要一定的时间。
然后另外一方面,对于药物设计来说,我必须指出,我认为应该有很多的 AI 制药结果,是没有被外人所知道的。逻辑非常简单,如果一个制药公司掌握了非常非常好的 AI 制药技术和方法,它就慢慢地做新药好了,不需要去宣传自己是个 AI 制药公司或者去做一个 CRO 的服务。它就按照传统的流程去做药,然后借助AI保持比别人更高的效率,它作为制药公司成功就可以了。
这也是我之前回答那个问题,就说我认为 AI 制药的未来是什么?就是所有的制药公司都变成了,或者所有的成功制药公司都变成了现代意义上的 AI 制药公司。因为这变成了一个标准的手段,也不需要去宣传说这个靶点是 AI 或者计算找出来的。未来可能所有的靶点选择都包含很多的计算成分,所有的分子设计都是计算驱动。
Q9:AI 制药它有两个比较大的市面上的疑问。一个是关于数据方面的,就是大家会觉得数据好像基本上有价值的数据可能都在传统的制药厂里面,然后导致这个 AI 制药公司就不得不去依赖于和大厂合作 pipeline 的方式来发展自己。然后另一个方面也是大家会觉得制药行业它其实是一个比较漫长的结果导向的。但是 AI 模型它是需要非常快速地去不断地做迭代来更正模型的。所以数据缺乏和那个模型迭代算是大家可能对 AI 制药比较大的两个质疑点。就如果从技术来说,您对这两个问题觉得现在有比较好的解决方法了吗?
A9:对于数据缺乏的问题,我可能跟这个行业里面的大部分人有不同的观点。我不认为数据缺乏是一个很重要的事情,我也不认为所谓的数据都掌握在大药厂手里是一个很严重的事情。
大药厂确实掌握很多不对外公开发布的数据。但是这些数据都是在没有 AI 制药、没有深度学习这些概念之前产生的,这些数据到底有多好用?让他们能够适用于AI是需要巨大的努力,而不是拿来就能用的,需要做大量的清洗和处理。据我的理解,即使是一个大的制药公司,他们已有的数据也没有那么好用,这是第一点。
第二点是大的制药公司在数据上的优势是他们有非常完整的实验平台,可以在高标准下产生更多的数据。按照我的理解,他们也确实是在不停地出产新的数据来做 AI 制药。就是说沉淀的数据本身并不是那么重要,沉淀的产生数据的能力是重要的。
所以说如果给予新的制药公司和biotech很大的帮助。让他们也获得这些产生数据的能力,也可以产生足够多的内部数据,尤其是针对特定的管线或者特定的项目。也可以用新的技术手段,因为现在产生数据的技术手段也不一样了。就比如说以前获得一个小分子的亲和力数据,你要去做 ITC,滴定比较慢、化合物用量也高,而现在有更多高通量的方法大规模来做。
某种程度上我不认为大药厂在这上面有技术壁垒,但是投入是重要的,所有人都需要投入在数据的产出,而且是让数据能够有效地以被 AI 计算模型可应用的方法来产出。在这个意义上,我想讲的第三点,是说这里面确实需要一个快速的迭代和更新的能力。这一点本身是可以被建立起来的,是可以以更先进的手段建立起来的。有很多人在尝试更加自动化的实验手段,在某种程度上可编程的实验室,我认为将是 AI 制药的一个巨大的帮助和补充。
Q10:比如说最早的从微阵列这样的一个高通量的数据收集手段来看的话,您会觉得比如说计算生物学这一整条技术链上面都需要什么样的技术要素去做些配合呢?或者我们换一个说法,就是说计算生物学这一门学科,它都需要怎样的一些技术手段来共同促进这个学科的发展呢?
A10:我觉得本质上来说可能还是落实在计算本身。我自己的感觉,我认为这个领域里面很多人对于计算本身的理解和关注还是不够。我想所有的人都会同意,就是说用一个已有的,比如说在CV或者NLP 里面已经成熟的一个方法,把它转移到一个特定的生物学问题上面,把它应用在一个生物学场景。对于学术界来说,你可以发很好的 fancy 的论文;但是对于真正落地,肯定需要对于计算的部分有更多的创新,至少是更精细的调整和适应。
这一点可能是在我看来,目前AI制药落地里面最需要做的事情。我们也看到这个行业里做地比较好的公司,不管是晶泰还是深势,他们都在计算上面,在作为工程的计算上面投入巨大的人力和物力。
Q11:除了 AI 制药之外,您觉得计算生物学未来还会有哪些比较好的落地场景?或者甚至说在您的设想或者理论上来说的话,还会有哪些场景呢?
A11:因为我自己还是比较关注科学发现本身的问题。我一直非常期待,就是说计算生物学能够真正的产出hypothesis。在通常意义下,生物学的研究是hypothesis-driven,科学家想出一个假说,然后去设计各种各样的实验来证明这一点。我一直希望有一个AI 生物学发现的技术,就是说从数据出发,对于计算生物学来就是说由一个计算模型来提出假说,更重要的是提出验证这个hypothesis应该做哪几个实验分别是什么样的实验,实验结果是怎么样就证明了,是怎么样就证伪了。这是我一直期待的。
Q12:最后想问一下,比如说您和您的课题组现在的研究方向可能会集中在哪些方面?
A12:谢谢,我介绍一下我的工作,主要是分成三个方向。一个方向是计算模型。我们想把计算模型,尤其是蛋白质的计算模型做准。所谓计算模型,你可以想象就是说一个蛋白要真正能够被计算机来理解运算,它需要转变成一系列参数、一系列代码、一系列编码的方式。那么我们关注的点就是怎么去做计算模型,包括蛋白质以及有机小分子,怎么更好地从传统力场上来描述它,或者从 AI 的角度上来描述它,或者从AI与物理模型相结合的角度来描述它,这是我实验室的一个主要方向。
另一个我们做的事情是蛋白质的动力学。我们使用分子动力学模拟,特定关注的一个生命过程是物质的跨膜转运。这个过程是由细胞膜上的蛋白质来介导的,通过转运蛋白的构象变化来实现,所以我们特别关注这一类蛋白的动力学行为。
我们第三个方向是在药物设计,既包含算法发展,也做具体应用。目前的关注点是小分子药物,因为我认为小分子现在看起来还是最容易生产,因此对于特定的靶点能够做出来是影响最大的。为达到这一点我们的想法还是要在方法上面有所创新,方法上面的创新使我们能够对别人做不了做不成的靶点进行分子设计。我们也希望我们能够真正的去探索广大的化学空间,超越大家传统设计时用的虚拟筛选,去做一些完全不一样的东西。
我课题组所覆盖的这三个研究领域,希望他们互相之间可以帮助彼此。就是说在蛋白质动力学或者小分子药物设计上,我们碰到的问题能够帮助我们来研发更好的计算模型。另一方面,我们做出来的更好的模型和方法,以及对于靶点蛋白动力学的理解,也可以让我们在特定的药物设计课题上能够比其他的公司有竞争的优势。
目前我们实验室还有2-3个博士后的名额,希望感兴趣的同学可以联系我们(邮箱:[email protected])。最近我们和百图生科开展了一个合作的项目,试图在一个更基础的层面上来解决领域里面重要的问题。由百图提供实验数据,我们一起用没有人尝试过的实验数据和方法来评估和改进蛋白质的力场。这个项目相当于一个学术界和工业界联合的学术博士后,也希望借此看看有没有人才培养的创新方式。
One More Thing
基于行业深度调研(部分公司完整访谈,已在对撞派·圆桌实录中公开),量子位智库制作了这份《AI制药深度产业报告》。如果想要进一步了解技术潜能、产业现状、未来规模、玩家梯队等产业解析,欢迎扫码下载完整报告:
报告核心七大趋势解读如下:
关于量子位智库:
量子位旗下科技创新产业链接平台。致力于提供前沿科技和技术创新领域产学研体系化研究。面向前沿AI&计算机、生物计算、量子技术及健康医疗等领域最新技术创新进展,提供系统化报告和认知。通过媒体、社群和线下活动,帮助决策者更早掌握创新风向。
特别感谢:百图生科、答魔数据、段宏亮教授(浙江工业大学)、黄晶教授(西湖大学)、剂泰医药、晶泰科技、望石智慧、星亢原、西湖云谷智药、 英矽智能、星药科技、亿药科技(按首字母排序)。
边栏推荐
- Redis的下载安装
- How should the acceptance criteria for R&D requirements be written?| Agile Practices
- 人体解析(Human Parse)开源数据集整理
- MySQL事务隔离级别
- 微信一面:一致性哈希是什么,使用场景,解决了什么问题?
- "Digital Economy Panorama White Paper" Special Analysis of Banking Industry Intelligent Marketing Application Released
- 电解电容漏电流及均压
- Here comes the question: Can I successfully apply for 8G memory on a machine with 4GB physical memory?
- Redis的常用数据结构和底层实现方式
- Recommend a free 50-hour AI computing platform
猜你喜欢



![[现代控制理论]3_Phase_portrait 相图 相轨迹](/img/45/255a6a62f8be320c663f5fcad1ad1b.png)
随机推荐
[Interview high-frequency questions] Linked list high-frequency questions that can be gradually optimized
WPF implements a MessageBox message prompt box with a mask
未来装备探索:数字孪生装备
Common gadgets of Shell (sort, uniq, tr, cut)
Summary of learning stages (knapsack problem)
从零开始Blazor Server(9)--修改Layout
ZOJ1298(单源最短路径)
MySQL中的锁
【Untitled】
抗积分饱和 PID代码实现,matlab仿真实现
Information system project managers must memorize the core test sites (63) The main process of project portfolio management & DIPP analysis
_main C:/ti/ccs1011/ccs/tools/compiler/ti-cgt-c2000_20.2.1.LTS/lib/rts2800_fpu32.lib<ar在线升级跳转疑问
redis的缓存穿透、缓存雪崩、缓存击穿怎么搞?
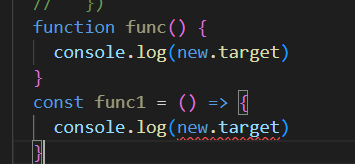
箭头函数和普通函数的常见区别
PM2 configuration file
MongoDB-查询中$all的用法介绍
TIC2000调用API函数Flash擦除片上FLASH失败
2022 Niu Ke Duo School (6) M. Z-Game on grid
电解电容漏电流及均压
从零开始Blazor Server(9)--修改Layout