当前位置:网站首页>【Data augmentation in NLP】——1
【Data augmentation in NLP】——1
2022-08-09 11:15:00 【临淮郡人】
前两周学校内上鉴萍老师的“智能工程计算实践”课程,讲到“真实场景下的应用“方面,讲了一些数据增强方法,觉得很有实际意义。因此在这里想深入学习一下。
本文为数据增强系列的第一篇,是阅读:Data Augmentation Approaches in Natural Language Processing: A Survey 一文的简要记录,大家有兴趣建议还是阅读原文。
0.前言
数据增强(Data augmentation)指的是通过增加“根据数据集数据轻微修改”的数据,或者“增加新和成的数据”来增加数据数量的方法。
数据增强是一种提升深度学习效果的方法,因为深度学习往往需要大量的数据,才能捕捉到其中的规律。
数据增强最初来自于CV社区,包括对图片的旋转和剪切等方式,随后便引入到NLP社区。但是注意到,NLP领域的数据增强其实很难,因为和图片不同的是,语言本身是离散的,结构化信息非常强,那么自动化过程的难度也有所差异。因此更好更有效的数据增强手段期望也期望被探索。
数据增强,既包括“基于规则的增强方法”,也包括“基于机器学习生成模型”的方法。但是在其中,需要关注增强数据的合理性(validity),例如,在机器翻译中,增强数据需要语义相似(similar semantics )的,而在文本分类中,生成数据和原数据对,应该有“相同”分类标签。
本文对根据对于训练集提供的“增强数据”的差异多少(diversity),将数据增强方法分为以下三个大类,包括paraphrasing, noising, and sampling
paraphrasing方法:
这一类方法对于原数据进行有限度的修改(bring limited changes),得到新数据,一般情况下“增强的样本”和“原样本”是语义相似的,Noising-based方法:
本方法是增加连续性或者离散型的噪音,这些噪音本身可能并没有明确含义,来获得更多的变化。加入“符合要求”的噪声,一般是为了增强模型鲁棒性(或者说是对抗鲁棒性?因为鲁棒性的含义比较广泛)。Sampling based 方法:
实际上已经掌握了原数据的分布,从分布中继续采样获得的增强数据,这些数据可以看作是全新的,且符合要求的。 Such methods output more diverse data and satisfy more needs of downstream tasks based on artificial heuristics and trained models.
(这个有点难吧?如何获得原数据的采样呢?)
1.主要方式
这里直接就上原文的图了,由于最近对“预训练”、“多任务”、“数据增强”、“迁移学习”等内容的内涵常常混淆,因此不做评论。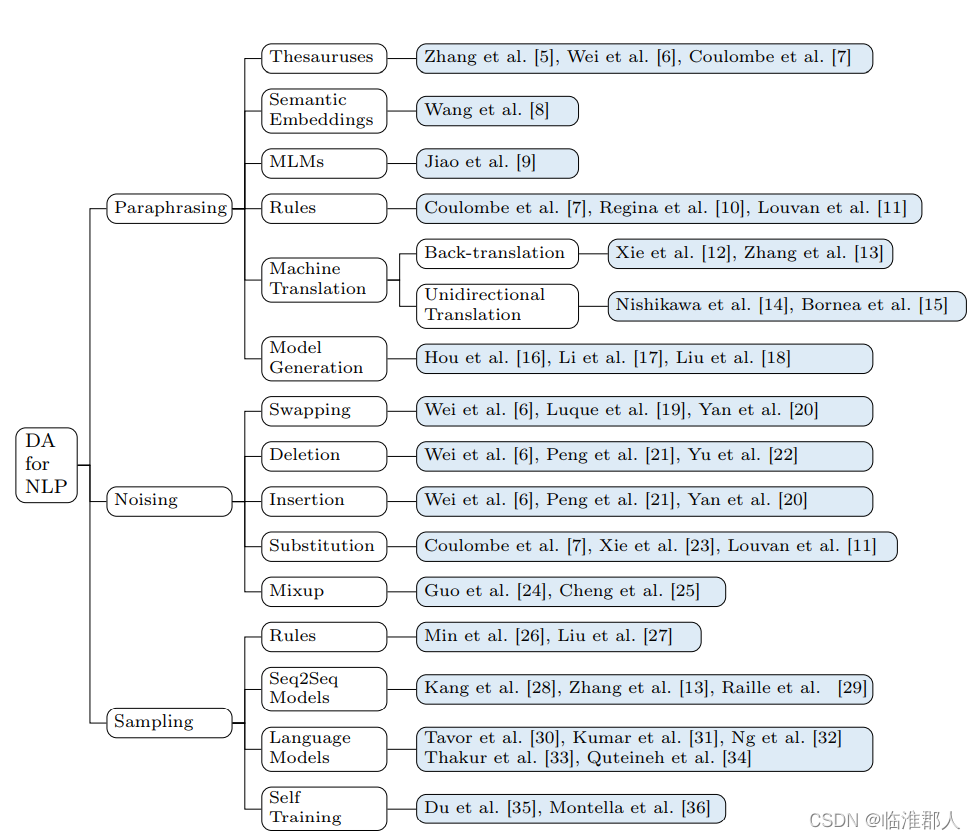
2.具体方法
2.1 Paraphrases:
Paraphrases may occur at several levels including lexical paraphrases(词语的), phrasal paraphrases(短语的,动词的), and sentential paraphrases(句子的)
2.1.1 Thesauruses 基于词典的
我们可以将一句话中的词进行同义词替换,这是最简单、直接的办法。我们可以利用外部的词典库,搜索近义词。列举的方法包括:
- 选取句子中可被替换的词,并在词典库搜索近义词,依据某种概率分布替换掉其中若干个相关词语。
- EDA (Easy Data Augmentation Techniques),直接从句子中的非停用词中替换若干次,或者通过extreme multi-label classification。
- 也可以将词语替换为上位词,或者依据词义难度,替换adv、adj、n、v
2.1.2 Semantic Embeddings
指通过一些词向量模型,来进行近义词语替换。比如Glove, Word2Vec, FastTexts等等,这里列举了一些方法:
- 直接用静态词向量,将原句子的词语的“余弦相似度”意义下的k-nearest,替换原句。
- 可以结合本方法与
Thesauruse(辞典)方法,使用本方法对词语表示,检索,但是内容来自于词典。
2.1.3 Language Models
基于语言模型的方法,一般指的是,通过“大型预训练模型”,由于语言模型对句子编码是动态的,因此这个方法在语义编码上,更好地缓解了“二义性”问题(ambiguity)。
具体的操作如下:
- 使用知识蒸馏方法:首先将句子使用Bert的tokenizer,并生成一个candidate set;根据词语是否为完整的词语,分别用word embedding(否),和Bert(是)来执行操作;后者将词语mask掉后,从candidate集合中,找到置信度较高的词语,进行预测。
- 其它人似乎也采用了类似的“先mask,再预测”的方法来生成新句子。
2.1.4 Rules
基于规则的方法,似乎回到了一开始基于规则的POS-tagging和dependency-tree parsing的年代。确实,基于规则的方法需要“人的观察”,可以完成词语级别、短语级别的替换。例如:
- 使用正则表达式,对句子中的一些模式进行识别,比如缩写(abbreviations) and 动词原形(prototypes of verbs), 情态动词(modal verbs), 否定(negation),当然基于规则的也可能需要依赖于词典。
- 利用句法分析工具,对得到的dependency-tree依据人为制定的转换语法( transformation grammar);或者直接剪裁(crop)、旋转操作(rotate)。
2.1.5 基于翻译的方法:
现在的NMT的水平其实已经非常高,而且翻译的API工具也很多。基于翻译的方式并不拘泥于词语、短语级别的替换。这一部分值得我好好看看
2.1.5.1 back translation回译法
回译法的运用比较多,比如CycleGan提出的Cycle-consistency其实也和回译法是类似的。
具体的,可以直接使用,也可以增加其它特征(feature):
- 直接来回翻译得到结果;
- 看作unsupervised的数据增强方法(?)
- 看作是style transfer任务,获得原数据的 formal expression
- 增加 a range of softmax temperature settings,来确保句子的diversity,又保持语义的相似性。
- 与adversarial training结合,
- 增加一个discriminator,
2.1.5.2 Unidirectional Translation单向翻译
这种方式一般在multilingual 的背景下出现。
比如:
- 用于unsupervised cross-lingual word embeddings任务中
2.1.6 模型生成(model generation)
与“翻译式”的数据增强不同,可以直接使用 Seq2Seq models的模型进行生成。这种方法生成的句子在 given proper training objects的时候diversity更好。
以下两个可以好好看看:
Kober et al. [68] use GAN to generate samples that are very similar to the original data. Liu et al. [18] employ a pre-trained model to share the question embeddings and the guidance for the proposed Transformer-based model. Then the proposed model could generate both context-relevant answerable questions and unanswerable questions.
其它在本节提到的,也可以好好看一下。
noise-based方法
这一类方法主要是为了加强模型的鲁棒性。与“句子改写”的方法相对比,基于噪声的方法是增加一些“不严重影响语义的噪声”。这类方法不仅仅是增加了数据,也是为了提高模型的鲁棒性。(不过鲁棒性的含义比较丰富,鲁棒性和泛化能力的区别,有待讨论)如下图所示,为5种主要的noise-based方法:
- 个人觉得实际上是对原数据的数值表示的附近,增加一些数据点,这些点实际上完全可能没有什么正确的语义,但是要求模型能够抵御“数值浮动”带来的影响。
2.2.1 交换
语言中词语顺序是非常重要的,对于词语顺序的交换可能会完全的改变一个句子的意思。但事实上,在一定程度内的交换,虽然形成不规范的句子,但是人还是能够读懂意思。依据作者的分类,交换包括word-level、instance-level、sentence-level swapping
这里的一些做法包括:
- 随机对句子内n个词语做两两位置交换,其中n和句子的长度成正比。
- 将句子切分为一些segment,然后对segment做交换。
- 如在情感分析的任务,有人将具有相同label的语句切分为两部分,然后互相交换。尽管这些句子并不通顺,或者语义上并不能读。
- 又如在legal documents任务上,有人将文档中的句子换位置,理由是句子的含义相对完整(而模型捕捉文档级别的含义显然还偏弱)
2.2.2 删除
对文本进行word或者sentence级别的删除。
- 对句子中的词语以一定概率随机删除;
- 删除句子中的slot value(?这是什么)
- 在legal documents任务,对文档中的句子以一定概率随机删除文档;
- 基于注意力分数删除一部分句子/词语。
删除和Mask其实挺像,但是我们把内容删除后,并不要求预测它们。
- 提问:删除了关键词语怎么办?
2.2.3 插入
在句子中增加一些词语。
- 对句子中的一些词语,寻找他们的同义词,并在句子的随机位置插入,重复若干次。
- 在句子中插入slot value;
- 还是legal documents任务,在具有相同label的文章中选取一些句子,并插入文档获得增强。
- 显然,无论是插入还是删除,非常有可能把原本的含义完全变化了,这对分类任务是十分不利的。因此,给出相关的建议:第一点,在词语级别上,可以使用一些与标签无关的外部资源(上面插入的是句子中的同义词);第二点,在文档层面上,插入同label的文档句子可能具有意义。
2.2.4 替换
增删改,三个都齐了。。本方法和2.1节的paraphrasing方法不同的是,替换的并不是词语的同义词,而是要避免数据具有语义的相似性。
例如:
- 用常见的英文拼写错误词语替换正常词语;
- 借鉴于word-dropout的思想,将句子中的一些词语替换为placeholder(其实有点像mask?没看文章内容)
- 借助于pseudo-IND parallel corpus embeddings
- 使用TF-IDF标准选择替换词。
- 在NER中,将具有相同token的词语随机互换。
- 在multilingual设定下,将词语换为其它语言的类似意义的词语(比如我们口语中经常这样。。)
- 对话中也有特定的增强方法,这里不是特别懂。
2.2.5 混合(Mixup)
混合指的是将一些数据的数值表达混合起来,最初也是来源于图像数据增强的方法。做法有:
1.wordMixup方法,在word embedding方法做二元插值;
2. senMixup方法,在Encoder的latent space做插值;
应用场景包括:
- 构建adversial sample和original sample
- text classification、NER等任务上
- Mixup-Transformer的模型上
2.3 基于采样(Sampling-based)的方法:
基于采样的方法需要我们知到样本的分布,并从中进行采样。本方法也包括基于规则和训练的模型,但是和paraphrasing的方法不同的是,本方式是task-specific的,并且需要更多的任务相关信息,包括数据的标签和格式等等。而基于paraphrasing的方法,只需要输入数据就行。
2.3.1 Rule based
这里可能就不要求生成语义相似的文本了,需要和任务具体的需求结合起来。
具体的不是很懂,感觉也先用不到。
2.3.2 Seq2Seq模型:
2.3.3 基于语言模型的:
由于语言模型本身是具有很强的记忆能力和知识(contain knowledge)的,因此也被用于进行数据增强。
例如:
- LAMBDA增强方法:通过一个在训练集上fine tune的GPT生成数据,并用一个filter过滤掉低质量的数据。
- 基于masked language model制作一个”corruption model“和一个”reconstruction model“,先用破坏模型将原始数据变为远离于当前数据流型的数据,再用重建模型恢复。(其实有点autoencoder那味道,但似乎其实应该不一样的)
- 其它还有一系列自回归的方法,如基于 DistilBERT、GPT的方法,这里由于不是特别明白目的,就先不看了。
2.3.4 自主学习的:
典型的方法包括将其它模型或者知识进行蒸馏或者迁移的。有点半监督的意思吧?Some methods train a model on the gold dataset to predict labels for unlabeled data。Some methods directly transfer exsiting models from other tasks to generate pseudo-parallel corpus. M
3.特点比较
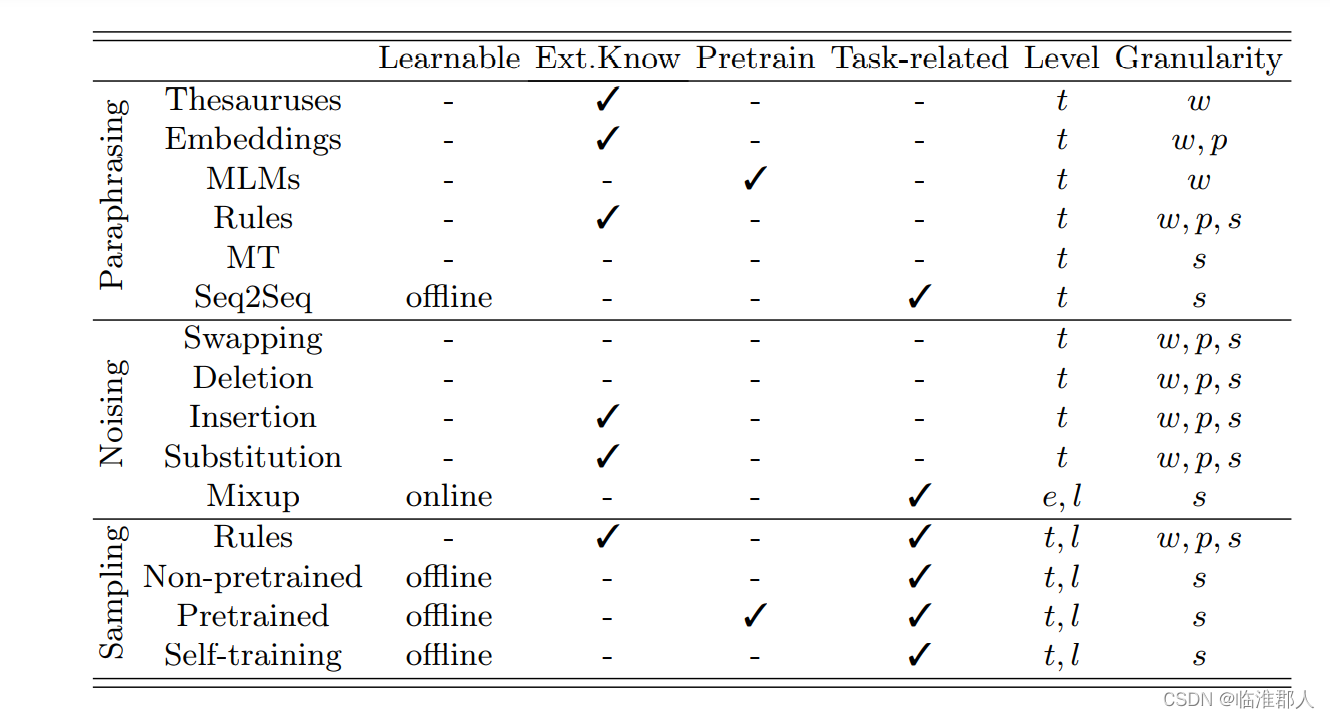
首先补充一点知识,就是online和offline这里,在线学习和离线学习,见链接:
https://blog.csdn.net/weixin_42267615/article/details/102973252
3.1 paraphrasing 方法
3.1.1 基于词典的方法
- 优势:
1.简单易用 - 局限性
1.句子中的词语(part of speech)和词语的替换选择比较有限;
2.方法造成句子的歧义(solve the ambiguity?不是特别明白)可能比较大;
3.替换太多后句子意思改变很大;
3.1.2 词嵌入表示
- 优势:
1.简单易用;
2.替换词的范围更加广,Higher replacement hit rate(不是很理解哦?) - 局限性:
1.方法造成句子的歧义(solve the ambiguity?不是特别明白)可能比较大
2.替换太多后句子意思改变很大
3.1.3 语言模型
优势:
1.本方法削弱了模糊性问题。alleviates the problem of ambiguity。
2.方法考虑了上下文的语义。
限制:
1.仍然局限于词语级别的替换,对句子整体含义的考量不多。
2.替换太多后句子意思改变很大(似乎是word-level的通病)
3.1.4 基于规则的(rules)
- 优势
1.简单易用;
2.由于规则是人指定的,较好的保持了原本的语义 - 局限性;
1.需要很大的人力以及人定的启发式规则;
2.变化的覆盖面低,种类有限。
3.1.5 翻译法:
- 优势:
1.简单易用;
2.适用性广;
3.好的翻译往往确保了正确的语法; - 限制:
1.由于机器翻译模型不具备“生成性”,因此其实多样性非常有限,而且对于结果的控制比较差
3.1.6 生成式模型:
优势:
1.多样性比较好;
2.适用性比较强、广泛限制:
1.训练模型难度很大;
2.要充分的训练数据;总体而言,基于规则的方法、人为知识的模型的变化性比较少,但是使用非常方便,基于模型、生成的在句子层面的语义保持和多样性方面比较好,但是本就需要大量数据,或者训练的难度比较大(MT,S2S)、需要大算力(LM)。其中,对于词语层面进行操作的方法,在替换词语太多的情况下显然容易改变句子含义;
另外注意,本节内容和2.3的比,实际上是一种”知识“的迁移,只要有原样本我们就可以生成新样本,不需要兼顾任务。
3.2 noise-based 方法
这些针对于数据表示基于引入“连续性”变化的方法,总体来说是为了增加模型的鲁棒性,因此和前者有很大的不同。
作者对"插入"和“替换”两个方法进行批注,认为这两个方法introduces new noisy information that may change the
original label,也就是说可能会改变监督分类,因此提出了两个建议:
- Use label-independent external resources at the word level.
- Use other samples with the same label as the original data at the sentence level.
但是我还是提出一点异议,因为交换和删除也可能很明显的改变语义。
而Mixup这种插值的方法其实有点迷惑,因为embedding和label空间似乎并没有很好的连续性,也没有这种相关性,因此提出一点疑问。
- 总体来说,这5个方法的优点是:
1.总体是增强了模型的鲁棒性;
2.部署非常方便。 - 缺点:
1.可能完全没有正确的句法结构和语义(Distorted syntax and semantics)
2.事实上单个方法的多样性也是比较有限的
3.3 基于抽样的方法:
3.3.1 基于规则
基于规则的好处和弊端也是显著的,和之前也是相同的。
- 优势
1.方便使用、部署; - 限制
1.需要大量的人工和启发式规则;
2.多样性不足,覆盖面不广。
3.3.2 基于生成式的模型:
和前面也是类似的:
- 优势:
1.多样性比较好;
2.适用性比较强、广泛 - 限制:
1.训练模型难度很大;
2.要充分的训练数据;
3.3.3 语言模型:
这里不知道为什么没有说到”word-level“的限制。
- 优势
1.适用性强Strong application. - 限制
1.模型训练本身需要大量数据与算力;
3.3.4 自主训练:
?其实这部分内容就没怎么理解。
优势:
1.和生成式模型(generative models)比,实现比较容易;
2. Suitable for data-sparse scenarios.
局限性:
1.需要大量无监督的数据
2.应用比较弱(Poor application)
以上几个优缺点,对这个application这个方面的评价,不适合能理解哦。
3.4 小结:
总体来说,有些方法不是基于模型学习而得的,那它们往往产生的样本相对单一,但比较容易部署,而模型学习的方法更加复杂、在句法和语义上的匹配性更高。
在“模型学习”的方法中,只有Mixup是“在线学习”方法。That is to say, the process of augmented data generation is independent of downstream task model training. Thus, Mixup is the only one that outputs cross-label and discrete embedding from augmented data.(不是特别理解哦,因此本方法就是cross-label?的了?)
事实上所有的非学习所得的模型,也都需要相应的补足,比如外部的知识库,包括语义词典semantic thesauruses like WordNet and PPDB, 手写的资源比如hand-made resources like misspelling dictionary in [7], 以及启发式的规则(artificial heuristics)。而预训练模型实际上在训练中记住了这些外部知识。
前两种方法往往是与任务无关的,在所有任务中都可以使用;而第三类方法和任务相关(没仔细看哦…),主要是这些方法需要满足一定的限制条件。
前两种方法由于也不考虑任务本身,因此也主要是在text层面做各种修改,除了Mixup方法涉及到了embedding的修改,而第三类方法需要对text and label level都进行学习。
基本是learnable的模型,对于数据增强的粒度和全局观更好,所有的non-learnable方法可以被用作词语级别和短语级别的数据增强,但是所有的可学习方法一般都用在语句级别的数据增强。
4.结语:
从这篇综述的结构上看,可以学习一下如何写一篇好综述而不是一味的抄袭别人的related work,或者说重复别人的综述。
一定要有自己的思考,本文在开头说到,别人的综述对分类不太合适,这其实是对问题的洞察还是不太深入,造成有的类别内容很细,有的却很粗略。或者说,别人的综述只是对某一类应用,比如说"text classification"所作的综述,对问题观察是不全面的。
综述上的结构:
- 本文是先整体介绍,包括相关概念、定义的梳理,重要性阐述、已有成果的梳理、分类法介绍,实际上是为自己的展开做铺垫。
- 对分类法中的具体内容进行展开,实际上也是本文的主体。
- a summary of common skills in DA methods to improve the quality of augmented data,
- 从应用的角度展开:analyzes the application of the above methods in NLP tasks
- introduces some related topics of data,这部分其实也很好,我之前对这里感到非常迷惑。
- 综述要避免综而不述,要能够lists some challenges we observe in NLP data augmentation,
- 最后做总结,首尾呼应,使得读者明确文章讲了什么。
5. 额外知识
5.1 模型的离线和在线学习:
离线学习
其实就是我一般看到的模型学习过程,现在训练集上学习,在验证集上验证效果,选取较好的模型,再在测试集上测试。
离线学习也通常称为批学习,是指对独立数据进行训练,将训练所得的模型用于预测任务中。将全部数据放入模型中进行计算,一旦出现需要变更的部分,只能通过再训练(retraining)的方式,这将花费更长的时间,并且将数据全部存在服务器或者终端上非常占地方,对内存要求高。
虽然看起来,离线学习的效果应该是比较好的。但是离线学习的缺点也是很明显的。离线学习的缺点:
- 模型训练过程低效
- 训练过程不易拓展于大数据场景。
- 模型无法适应动态变化的环境
在线学习
在线学习也称为增量学习或适应性学习,是指对一定顺序下接收数据,每接收一个数据,模型会对它进行预测并对当前模型进行更新,然后处理下一个数据。这对模型的选择是一个完全不同,更复杂的问题。
在网络异常检测中,网络异常通常包括各种网络故障、流量的异常表现和拥塞等,各种网络攻击层出不穷,数据是原数据中从未出现过的,因此要求新的在线学习方法能够自动地侦测当前要鉴别的流数据是原来数据中存在的还是新生成的 。在线学习算法具有实现简单、可拓展性强和算法性能优越等特点,适合用于海量数据处理。
以上是针对单任务的在线学习问题,比如自然语言处理、生物基因序列以及图片视频搜索等适合使用多任务学习。多任务可利用多个任务之间的相关性避免模型欠拟合,从而提高算法的泛化能力。主要包括有:
- 但是我也很有疑惑的,OOD现象不是在线学习的独有的特点,更具已有经验给出答案更是所有模型的特点啊。。
边栏推荐
- GOPROXY 中国代理
- PAT章节
- 百钱买鸡(一)
- ICML 2022 | Out-of-Distribution检测与深最近的邻居
- golang 三种指针类型具体类型的指针、unsafe.Pointer、uintptr作用
- 激光条纹中心提取——Steger
- This application has no explicit mapping for /error, so you are seeing this as a fallback
- People | How did I grow quickly from programmer to architect?
- MDK添加注释模板
- 【精华文】C语言结构体特殊情况分析:结构体指针 / 基本数据类型指针,指向其他结构体
猜你喜欢


随机推荐
PTA 找出不是两个数组共有的元素
排序--快排(图解)
MySQL传统方案和通过SSH连接哪个好?
sublime记录
The use of gdb tui
matlab fcnchk 函数用法
margin出bug---margin失效
PTA 矩阵运算
Numpy常用操作博客合集
激光条纹中心提取——灰度重心法
抗积分饱和 PID代码实现,matlab仿真实现
bat文件(批处理文件)运行时一闪而过解决方法
富媒体在客服IM消息通信中的秒发实践
程序员的专属浪漫——用3D Engine 5分钟实现烟花绽放效果
leetcode-搜索旋转排序数组-33
b站up主:空狐公子 --矩阵求导(分母布局)课程笔记
x86异常处理与中断机制(1)概述中断的来源和处理方式
Looper 原理浅析
mysql参数学习----max_allowed_packet
剖析STM32F103时钟系统