当前位置:网站首页>VIT transformer详解
VIT transformer详解
2022-08-09 17:31:00 【樱花的浪漫】
1.VIT 整体架构

对图像数据构建patch序列
对于一个图像,将图像分为9个窗口,要将这些窗口拉成一个向量,比如一个10*10*3维的图像,我们首先要将这个图像拉成一个300维的向量。
位置编码:
位置编码有两种方式,第一种编码是一维编码,将这些窗口按照顺序,依次编码成1,2,3,4,5,6,7,8,9.第二种方式是二维编码,返回每个图像窗口的坐标。
最后,连接一层全连接,将图像编码和位置编码映射到计算更容易识别的编码。
那么,架构图中的0编码有什么作用呢?
我们一般在图像分类中加入0编码,图像分割与目标检测一般不需要加入,0patch主要用于特征整合,整合各个窗口的特征向量,因此,0 patch可以加在任何位置。
2.公式详解
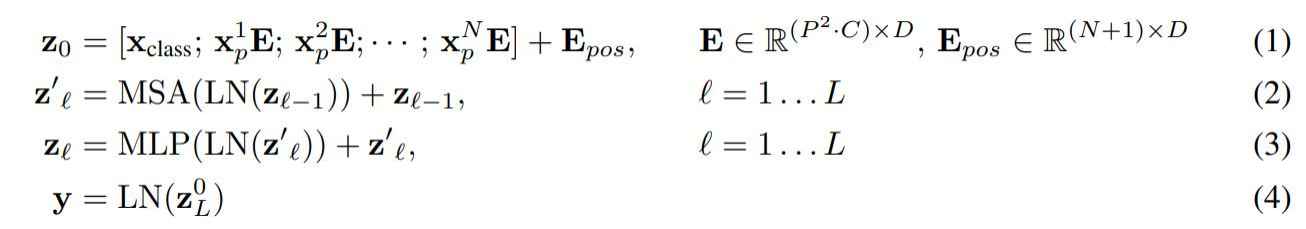
3.多头注意力的感受野
如图所示,纵轴表示注意力的距离,也相当于卷积的感受野,当只有一个head时,感受野比较小,也会有感受野大的情况出现,随着head数量的增多,感受野普遍都比较大,这说明了Transformer提取的是全局特征。

4.位置编码
结论:编码有用,但是怎么编码影响不大,干脆用简单的得了,2D(分别计算行和列的编码,然后求和)的效果还不如1D的,每一层都加共享的位置编码也没啥太大用

当然,这是分类任务,位置编码可能影响不大
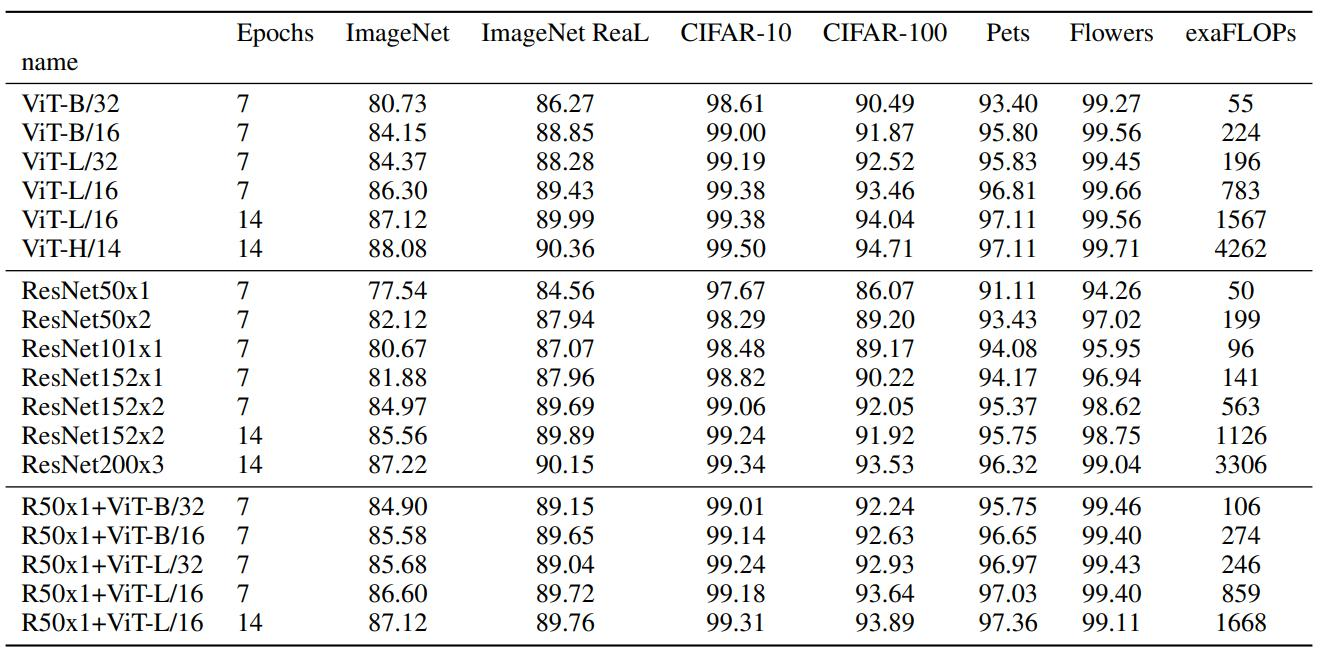
5.实验效果(/14表示patch的边长是多少)
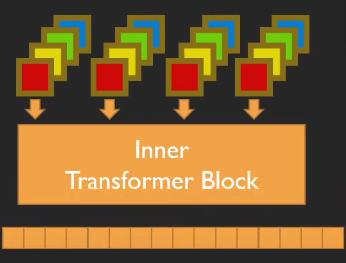
6.TNT:Transformer in Transformer
VIT中只针对pathch进行建模,忽略了其中更小的细节

外部transformer将原始图像分为一个个窗口,经过图像编码和位置编码生成一个特征向量。
内部transformer将外部transformer的窗口,在进一步重组为多个超像素,重组为新的向量,比如说:外部transformer将图像拆分为16*16*3的窗口,内部tranformer再将其拆分为4*4的超像素,此时小窗口大小为4*4*48,这样每一个patch就整合了多个channels的信息。新向量再通过全连接改变输出特征大小,此时内部组合后的向量与patch编码大小相同 ,将内部向量与外部向量再相加。


TNT的PatchEmbedding的可视化
对于蓝色的点表示TNT提取的特征,从可视化图像中可以看出,蓝色的点特征更离散,方差更大,更有利于分离,特征更鲜明,分布更多样性

实验结果
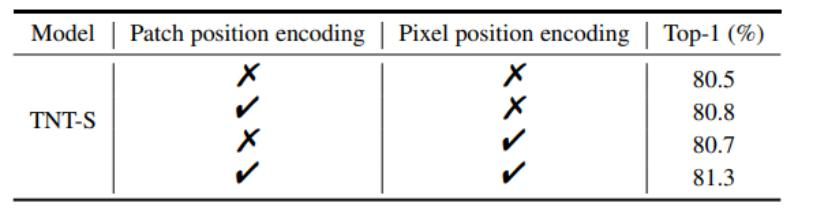
内外兼修,都加编码效果最好
边栏推荐
- 基于AWS构建云上数仓第一步:云平台的基础概念
- win10 uwp 模拟网页输入
- ASP.NET Core依赖注入之旅:针对服务注册的验证
- 华为发布「国产Copilot内核」PanGu-Coder,而且真的能用中文哦!
- Ark: Survival Evolved Open Server Port Mapping Tutorial
- ref的使用
- 释放数据价值的真正法宝,数据要素市场化开发迫在眉睫
- loadrunner script -- parameterization
- 集合框架Collection与Map的区别和基本使用
- The most complete architect knowledge map in history
猜你喜欢

Detailed explanation of JVM memory model and structure (five model diagrams)

对数学直观、感性的认知是理解数学、喜爱数学的必经之路,这本书做到了!

What are some good open source automation testing frameworks to recommend?

ARM Assembly Basics

A carnival of art and technology, cloud XR supports Anaya 2022 Sandbox Immersive Art Season

mysql如何查看所有复合主键的表名?

太厉害了!华为大牛终于把 MySQL 讲的明明白白(基础 + 优化 + 架构)
释放数据价值的真正法宝,数据要素市场化开发迫在眉睫

ref的使用

商业智能BI行业分析思维框架:铅酸蓄电池行业(一)
随机推荐
The difference between approach and method
redirect action
win10 uwp 无法附加到CoreCLR
shared usage in d
阿里云张新涛:支持沉浸式体验应用快速落地,阿里云云XR平台发布
mysql如何查看所有复合主键的表名?
发布sensor_msgs/Range数据
Flink运行架构
win10 uwp 活动磁贴
神秘的程序员(20-30)
基于AWS构建云上数仓第一步:云平台的基础概念
程序健壮性
毕昇编译器优化:Lazy Code Motion
C的一些琐碎
Uniapp 应用未读角标插件 Ba-Shortcut-Badge
Simple prohibition of garbage collection in d
API接口是什么?API接口常见的安全问题与安全措施有哪些?
ref的使用
混动产品助力,自主SUV市场格局迎来新篇章
JSDN blog system