当前位置:网站首页>训练好的深度学习模型,多种部署方式
训练好的深度学习模型,多种部署方式
2022-08-09 07:03:00 【落难Coder】
简介
当我们辛苦收集数据、数据清洗、搭建环境、训练模型、模型评估测试后,终于可以应用到具体场景,但是,突然发现不知道怎么调用自己的模型,更不清楚怎么去部署模型!
将深度学习模型部署到生产环境面临两大挑战:
- 我们需要支持多种不同的框架和模型,这导致开发复杂性,还存在工作流问题。数据科学家开发基于新算法和新数据的新模型,我们需要不断更新生产环境。
- 如果我们使用英伟达GPU提供出众的推理性能。首先,GPU是强大的计算资源,每GPU运行一个模型可能效率低下。在单个GPU上运行多个模型不会自动并发运行这些模型以尽量提高GPU利用率。
能从数据中学习,识别模式并在极少需要人为干预的情况下做出决策的系统令人兴奋。深度学习是一种使用神经网络的机器学习,正迅速成为解决对象分类到推荐系统等许多不同计算问题的有效工具。然而,将经过训练的神经网络部署到应用程序和服务中可能会给基础设施经理带来挑战。多个框架、未充分利用的基础设施和缺乏标准实施,这些挑战甚至可能导致AI项目失败。
部署的不用需求
需求一: 简单的demo演示,只看看效果
caffe、tf、pytorch等框架随便选一个,切到test模式,拿python跑一跑就好,顺手写个简单的GUI展示结果;高级一点,可以用CPython包一层接口,然后用C++工程去调用
需求二: 要放到服务器上去跑,不要求吞吐和时延
caffe、tf、pytorch等框架随便选一个,按照官方的部署教程,老老实实用C++部署,例如pytorch模型用工具导到libtorch下跑。这种还是没有脱离框架,有很多为训练方便保留的特性没有去除,性能并不是最优的。另外,这些框架要么CPU,要么NVIDIA GPU,对硬件平台有要求,不灵活;还有,框架是真心大,占内存(tf还占显存),占磁盘。
需求三: 放到服务器上跑,要求吞吐和时延(重点是吞吐)
这种应用在互联网企业居多,一般是互联网产品的后端AI计算,例如人脸验证、语音服务、应用了深度学习的智能推荐等。由于一般是大规模部署,这时不仅仅要考虑吞吐和时延,还要考虑功耗和成本。所以除了软件外,硬件也会下功夫。
硬件上,比如使用推理专用的NVIDIA P4、寒武纪MLU100等。这些推理卡比桌面级显卡功耗低,单位能耗下计算效率更高,且硬件结构更适合高吞吐量的情况。
软件上,一般都不会直接上深度学习框架。对于NVIDIA的产品,一般都会使用TensorRT来加速。TensorRT用了CUDA、CUDNN,而且还有图优化、fp16、int8量化等。
需求四: 放在NVIDIA嵌入式平台上跑,注重延时。
比如PX2、TX2、Xavier等,参考上面,也就是贵一点。
需求五: 放在其他嵌入式平台上跑,注重延时
硬件方面,要根据模型计算量和时延要求,结合成本和功耗要求,选合适的嵌入式平台。
比如模型计算量大的,可能就要选择带GPU的SoC,用opencl/openglvulkan编程;也可以试试NPU,不过现在NPU支持的算子不多,一些自定义Op多的网络可能部署不上去;
对于小模型,或者帧率要求不高的,可能用CPU就够了,不过一般需要做点优化(剪枝、量化、SIMD、汇编、Winograd等)。在手机上部署深度学习模型也可以归在此列,只不过硬件没得选,用户用什么手机你就得部署在什么手机上。
上述部署和优化的软件工作,在一些移动端开源框架都有人做掉了,一般拿来改改就可以用了,性能都不错。
需求六: 上述部署方案不满足你的需求。
比如开源移动端框架速度不够——自己写一套。比如像商汤、旷世、Momenta都有自己的前向传播框架,性能应该都比开源框架好。只不过自己写一套比较费时费力,且如果没有经验的话,很有可能费半天劲写不好。
边栏推荐
猜你喜欢
错误:为 repo ‘oracle_linux_repo‘ 下载元数据失败 : Cannot download repomd.xml: Cannot download repodata/repomd.
高项 03 项目立项管理

力扣第 305 场周赛复盘
字节跳动笔试题2020 (抖音电商)
虚拟机网卡报错:Bringing up interface eth0: Error: No suitable device found: no device found for connection
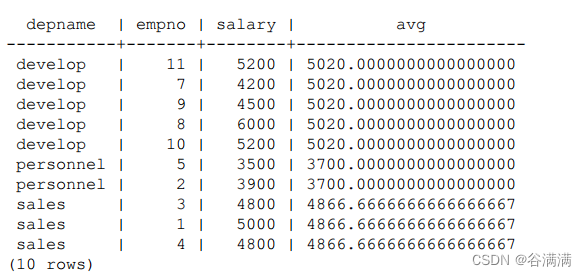
postgresql窗口功能
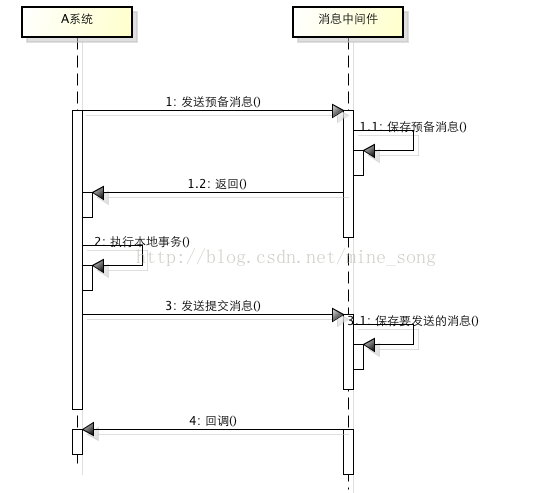
常见的分布式事务解决方案
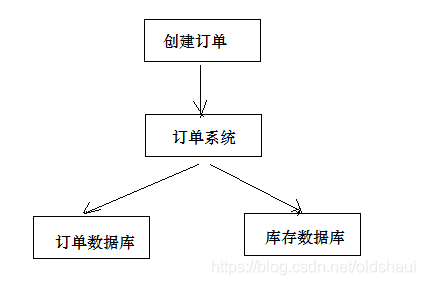
什么是分布式事务
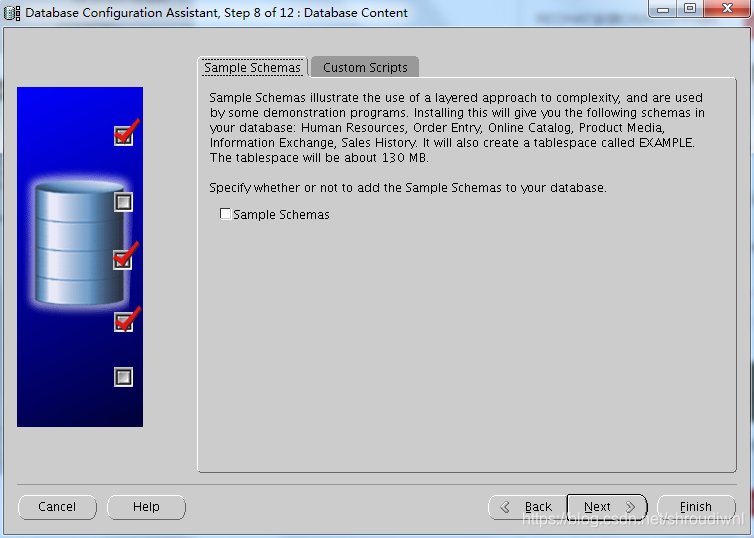
【Oracle 11g】Redhat 6.5 安装 Oracle11g
Zero shift of leetcode
随机推荐
神经网络优化器
买口罩(0-1背包)
高德地图JS - 已知经纬度来获取街道、城市、详细地址等信息
list与string转换
P7 Alibaba Interview Questions 2020.07 Sliding Window Algorithm (Alibaba Cloud Interview)
单例 DCL(double check lock) 饱汉模式和饿汉模式
imageio读取.exr报错 ValueError: Could not find a backend to open `xxx.exr‘ with iomode `r`
【Docker】Docker安装MySQL
codeforces Valera and Elections (这思维题是做不明白了)
多米诺骨牌
【nuxt】服务器部署步骤
灵活好用的sql monitoring 脚本 part7
io.lettuce.core。RedisCommandTimeoutException命令超时
【转载】Deep Learning(深度学习)学习笔记整理
The division principle summary within the collection
无重复的字符的最长子串
rsync:recv_generator: mkdir (in backup) failed:Permission denied (13) |failed to set times on '.'
Forest Program dfs+tanjar仙人掌
leetcode 之 零移位
Fragments