当前位置:网站首页>工业检测深度学习方法综述
工业检测深度学习方法综述
2022-08-11 08:52:00 【视觉菜鸟Leonardo】
1、概述
工业缺陷现阶段存在缺陷样本匮乏、缺陷的可视性低、形状不规则、类型未知等问题,部分工业缺陷检测方法采用的异常检测的思路。
异常检测主要关注输入图像是否为异常实例,工业缺陷检测更关注像素层面的检出任务。但在像素层面上,异常与正常模式的差别更加细微,检测难度也大幅增加,直接使用异常检测方法很难满足工业缺陷检测的需求。
文章按照实际情况中的数据样本的标注和使用情况,划分出3种任务设置:缺陷模式已知、缺陷模式未知、少量缺陷标注。
本文主要致力于解决无监督、半监督方向 。
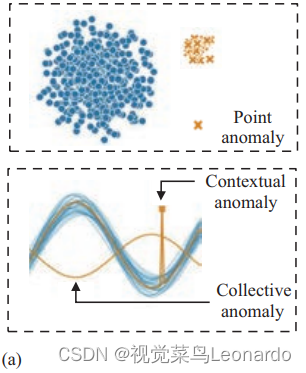
缺陷的概念可以类比到异常。异常指超出预期模式范围的数据。根据数据之间是否存在上下文关系,可以将异常分为点异常、上下文异常和集群异常。点异常被称为离群值(outliers),描述数值上偏离正常样本的独立数据。上下文异常描述数据点,其数值属于正常范围,但不符合局部上下文规律。集群异常描述一系列相关数据的集合,集合中每一个实例的数值在单独考察时都处于正常值域,但集合整体的相关性特征不服从正常模式。(三种异常情况在图a中标示清楚)
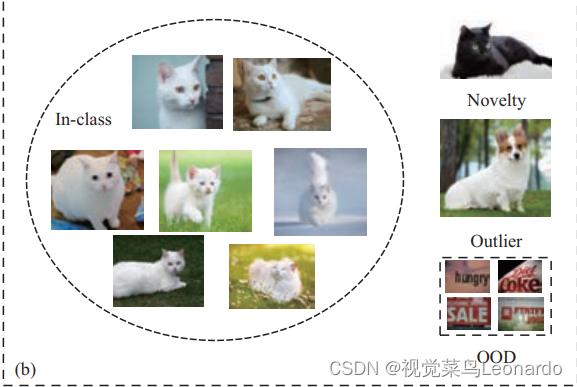
如图b所示,在图像分类任务中,基于白猫样本定义猫类。白狗即使颜色相近,但因语义类别不同而属于离群值;黑猫属于猫类,语义类别相同,但是颜色属性没有在训练集中出现过,属于新颖点(novelty);分布外数据(OOD)关注数据集合的分布差异,文本数据集与自然场景中帽的数据集的分布呈现明显差异。
在图c的工业缺陷检测中,正常样本包括多类产品,缺陷可被视为其外观上的“异常”。但是工业缺陷所占的图像区域更小。一般的图像异常检测往往仅需要区分正常与异常样本,但是工业检测更关注于检测图像中的异常像素。
文章将工业缺陷分为表面缺陷和结构缺陷。表面缺陷主要表现在产品表面的局部位置,表现为纹理突变、异常区域、反规律模式或者图案错误(表面裂纹、色块、织物、商标文字印刷错误)。
而缺陷区域的像素值与周围背景的差异项可将其类比为离群值或集群异常:离群值型缺陷像素值通常与正常图像有明显差异;集群异常缺陷的像素值与周围正常区域属于同一范围;结构缺陷主要由产品整体的结构错误所致,包括形变、错位、缺损和污染,例如铁丝弯曲、二极管的边缘缺损或者处于错误的位置。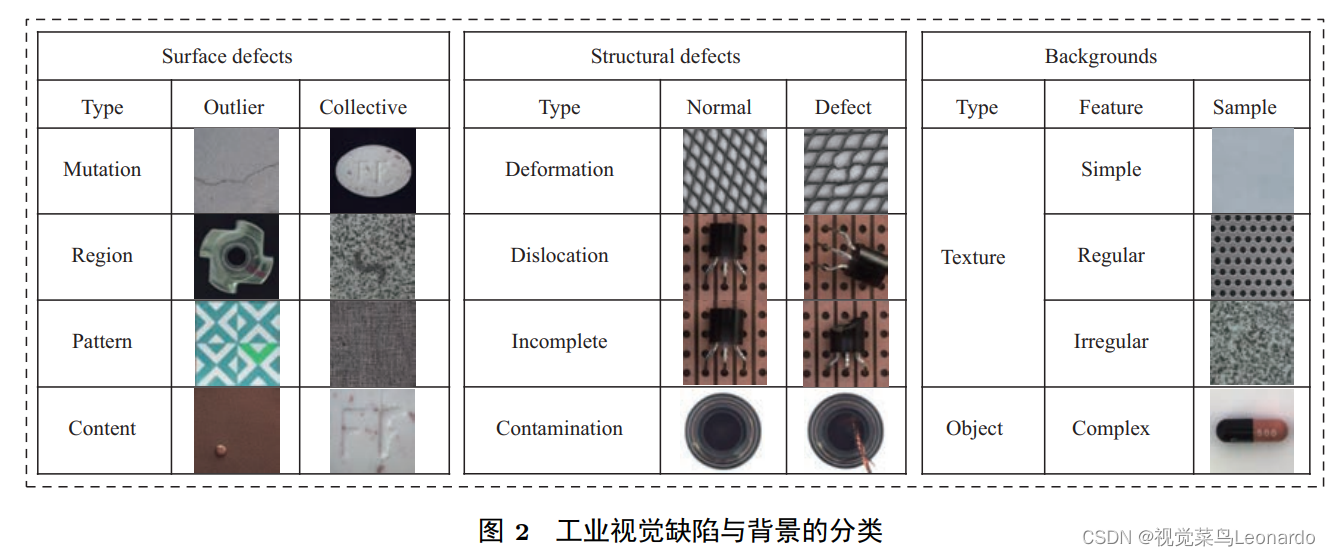
工业视觉缺陷检测任务一般包括分类和定位,如图3,对于一个待测图像实例,分类任务首先将其分为正常样本或者缺陷样本。若缺陷类型已知,可以进一步对缺陷类型进行判别。
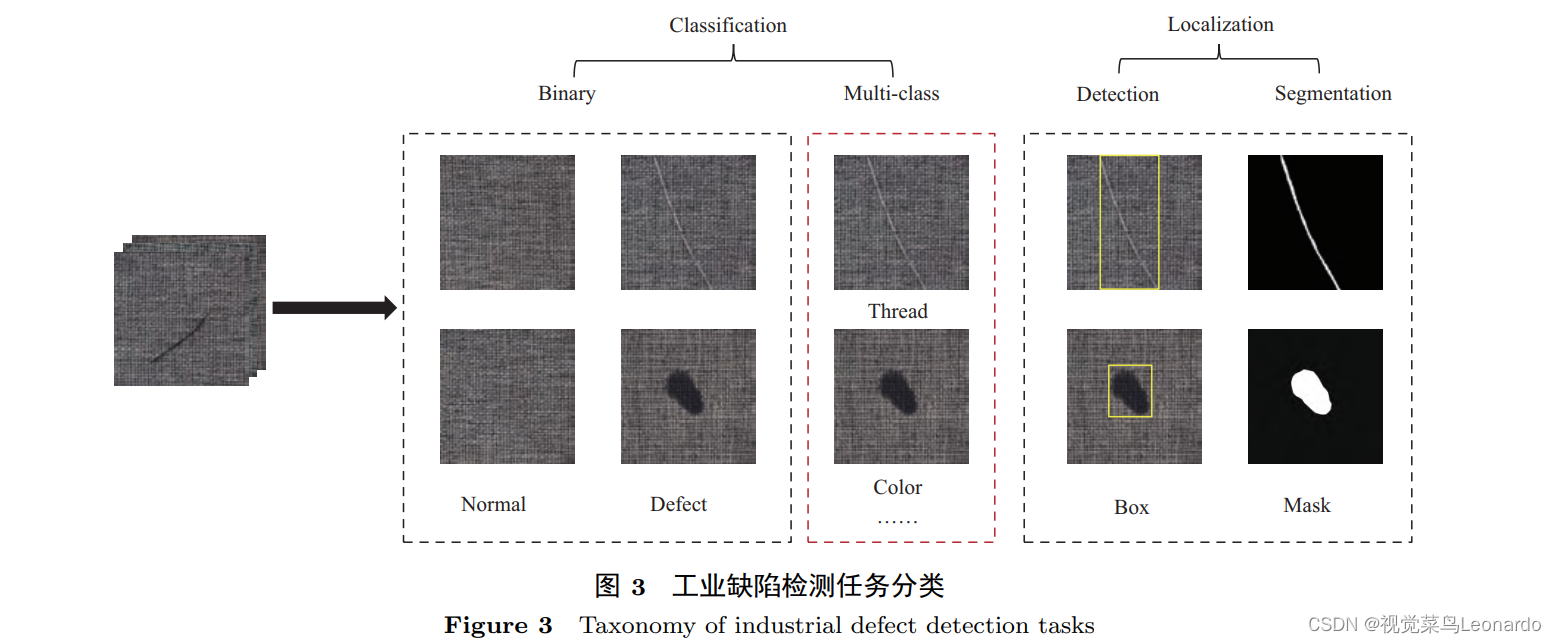
定位的目标是找到缺陷在图像中的具体区域,根据缺陷区域的描述方式可一分为检测和分割(可同时进行)。实际场景更普遍使用的是缺陷分割方法。
2、难点
2.1 数据难点
(1)样本匮乏:数据数量有限、缺陷数量少、缺陷标注成本高
(2)未知性与主观性:通过人为归纳的缺陷无法覆盖全部,往往会出现无法识别的新的缺陷类型
(3)可视性低:缺陷不易发现,正负样本差别小
(4)种类繁多:缺陷形式多样
(5)背景复杂:结构与纹理复杂,风格迥异,模型需要容纳所有正常样本之间的类内差异
(6)高精度:减少漏检,某些更需要检测出人眼难以观测的细微缺陷
(7)低开销:高速、实时。
2.2研究概述
缺陷模式已知:有监督深度学习方法,需要充足而精确的样本标注,涵盖分类、检测、分割。
缺陷模式位未知:无监督深度学习,根据比较对象维度的不同,可分为图像维度与特征维度比较相似度,并基于方法的原理进一步细分。
少量缺陷标注场景:更贴合实际工业情况,训练集中包含比例不均衡正负样本,且只有少量的缺陷样本具有精确或者不精确的标注。可以根据具体的数据标注情况,分别采用小样本、半监督、弱监督等方法处理。 自监督学习属于无监督学习的一种,从无标注数据中挖掘自身的监督信息。文章从构建监督信息的角度对自监督方法予以归纳。
文章从三个角度出发:(1)数据增强与合成为数据贪婪的检测模型提供足够的训练集
(2)模型压缩与加速技术面向落地使用中的低存储开销与实时性需求
(3)阈值设置旨在找到推理阶段最合适的分类边界。
3、检测算法
3.1 缺陷模式已知
3.1.1传统方法
从图像的角度, 由于工业缺陷往往表现在图像中像素突变的区 域, 对于金属等背景简单的产品, 边缘检测方法可简单有效地定位缺陷区域. 常用的边缘检测算子包 括 Prewitt, Sobel 和 Canny 等. 但是该方法难以处理复杂的背景或低信噪比的缺陷, 且对成像条件要 求较高.
从频域的角度, 突变型缺陷在频谱中往往表现出高频特征. 因此对于具有简单或周期性背景的产品, 可用傅里叶变换 、Gabor 变换、小波变换等方法转换到频域来检测.
然而, 区域型 工业缺陷的内部往往较为平稳, 因此基于边缘检测的方法通常仅能检测到缺陷边界. 不过, 大面积缺 陷会影响图像的统计特性, 因此可以利用灰度变化差异性、灰度直方图 、颜色特性等基于统计 的方法进行表征.基于上述缺陷描述符, 还可进一步利用 SVM、随机森林 [19] 等传统机器学习方法进行分类.
3.1.2 深度学习方法
工业缺陷数据集存在严重的不均衡现象,有人提出利用标签膨胀解决样本不均衡问题,然后采用半监督数据扩增方式,根据特征图的相应强度裁剪含缺陷的图像块,为模型提供充分而均衡的训练集。
在实际应用中, 不仅需要判断图像是否存在缺陷, 还需要确定缺陷的位置。多使用检测框架进行调整,来符合工业数据的检测。但是缺陷本身的无规则性,形状和尺度变化范围较大,检测的方法仅能输出缺陷的包围盒,难以准确地对复杂缺陷的位置与形态进行描述。为了得到像素级的缺陷定位结果,逐步考虑使用分割的方法。
现实情况下难以提供充足且均衡的含标数据集,即使利用数据增强也无法彻底解决该问题。利用数据合成的方式生成人造缺陷样本极其标注,用于训练有监督的方法。
3.2 缺陷模式未知
无监督方法借鉴的异常检测的思路,对易于获取与描述的正常样本进行建模。缺陷被定义为正常范围之外的模式。无监督下的任务目标通常是判断待测样本是否包含缺陷或者对缺陷区域进行像素级别的分割定位。
3.2.1 传统方法
当缺陷模式未知时, 传统方法主要依靠正常样本呈现出的图像特征进行比较, 或基于传统机器学 习模型对正常样本进行描述。
3.2.2 深度学习方法
基于无监督设置的深度学习方法仅需要易于获取的正常样本用于模型训练, 无需使用真实缺陷样 本.此类方法的核心思想是构建出一个与待测样本最相近 的 “模板” 与之比较, 根据像素或特征的差异性实现缺陷的检出与定位。文章根据比较维度不同将方法分为基于图像相似度的方法和基于特征相似度的方法。
(1)基于图像相似度的方法
基于图像相似度的方法在图像像素层面进行比较, 其核心思想是重建出与输入样本最相近的正常 图像, 两者仅在缺陷区域存在差别.生成图与输入图像的差异图可表示缺陷存在的概率, 既可以 用于判断整图是否包含异常, 也可以取阈值来得到缺陷的分割结果.此类方法常使用自编码模型与生 成式模型, 如图 6 所示, 包括自编码器 (auto-encoder, AE)[69]、变分自编码器 (variational auto-encoder, VAE)[70]、生成对抗模型 (generative adversarial networks, GAN)[71] 等,
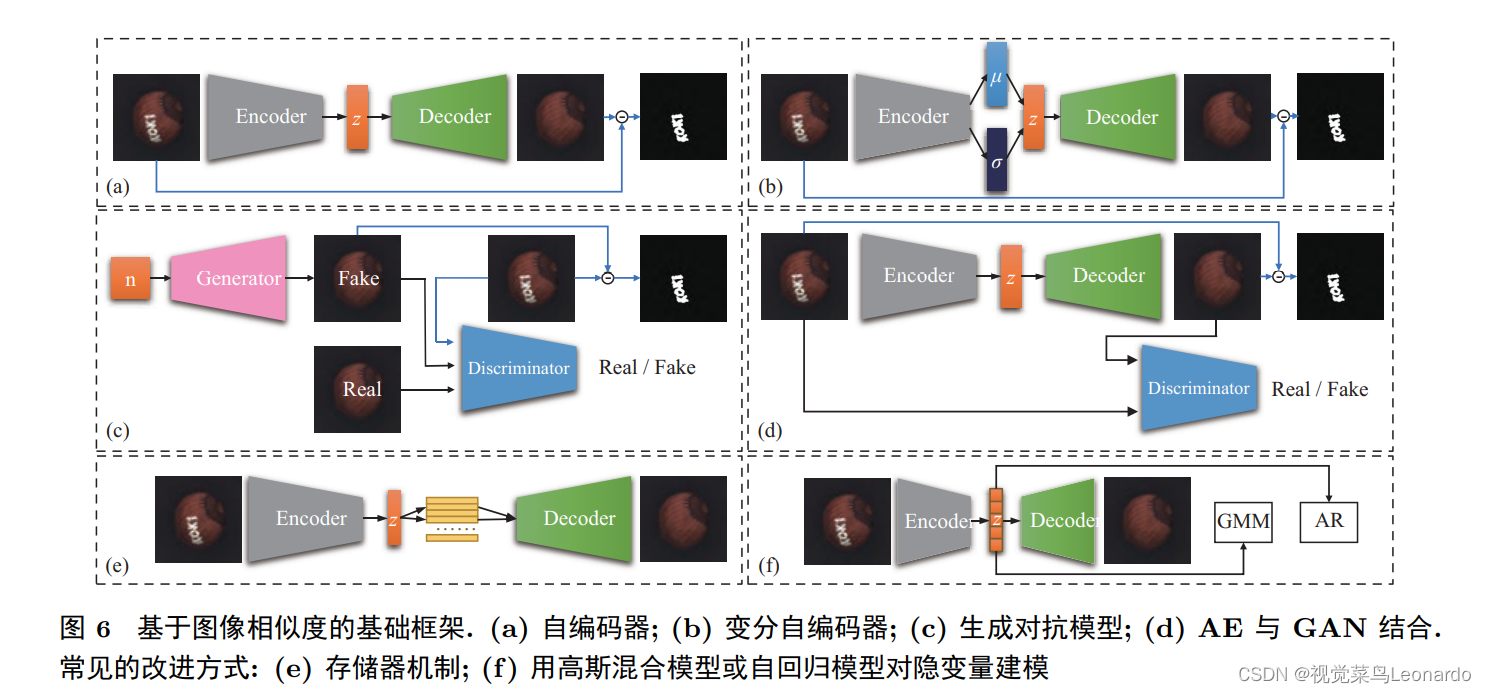
(i)基于图像重建的方法
此方法仅在正常样本上训练模型,使其能学习到足以用来重建出正常样本的分布特征。此类方法假设: 由于模型的参数仅由正常样本训练得到, 模型只能较好 地重建正常样本, 而在缺陷样本的缺陷区域则会产生较大的重建误差. 由于此类方法大多采用重建误差实现缺陷的检出与定位, 重建图像的质量对缺陷检测性能影响巨大, 因而大部分研究者们尝试从提 升重建质量的角度改进方法, 使得重建图像与输入图像的像素仅在缺陷区域存在明显差异, 而在正常 区域几乎一致.
然而,基于图像重建的方法的假设并不完全可靠, 即使仅在正常样本上训练, 模型仍然可能将未 见过的缺陷完整重建。原因主要有两点: AE 等模型具有较大的容量; 缺陷与正常区域的 特征差别不明显。
(ii)基于图像恢复的方法
基于图像恢复的方法将缺陷视为噪声,将图像恢复视为去噪过程。此 类方法的核心思想是在正常图像上加入缺陷后, 训练网络模型将其恢复为对应的原始图像. 常用的模 型包括 AE 和 U-Net 等. 训练完成后, 模型具有根据上下文消除缺陷的能力. 测试阶段利用恢复图像 和输入图像的重建误差进行缺陷分割. 由于模型的输入与输出不对等, 此类方法能一定程度上避免恒 等映射的问题.
基于图像恢复的方法显式地约束模型, 使其将缺陷还原为正常像素. 该过程可以促进模型更好地 学习图像的上下文信息, 因此还能有助于检测结构缺陷.此类方法对人工缺陷的设计具有较高的 要求, 不仅希望尽可能接近真实缺陷的分布, 而且需要具有足够的多样性, 否则容易过拟合到特定的 缺陷形态上.
(2)基于特征相似度的方法
基于图像相似度的方法非常直观, 具有较强的可解释性. 然而, 现有方法往往难以实现理想的重建效果.
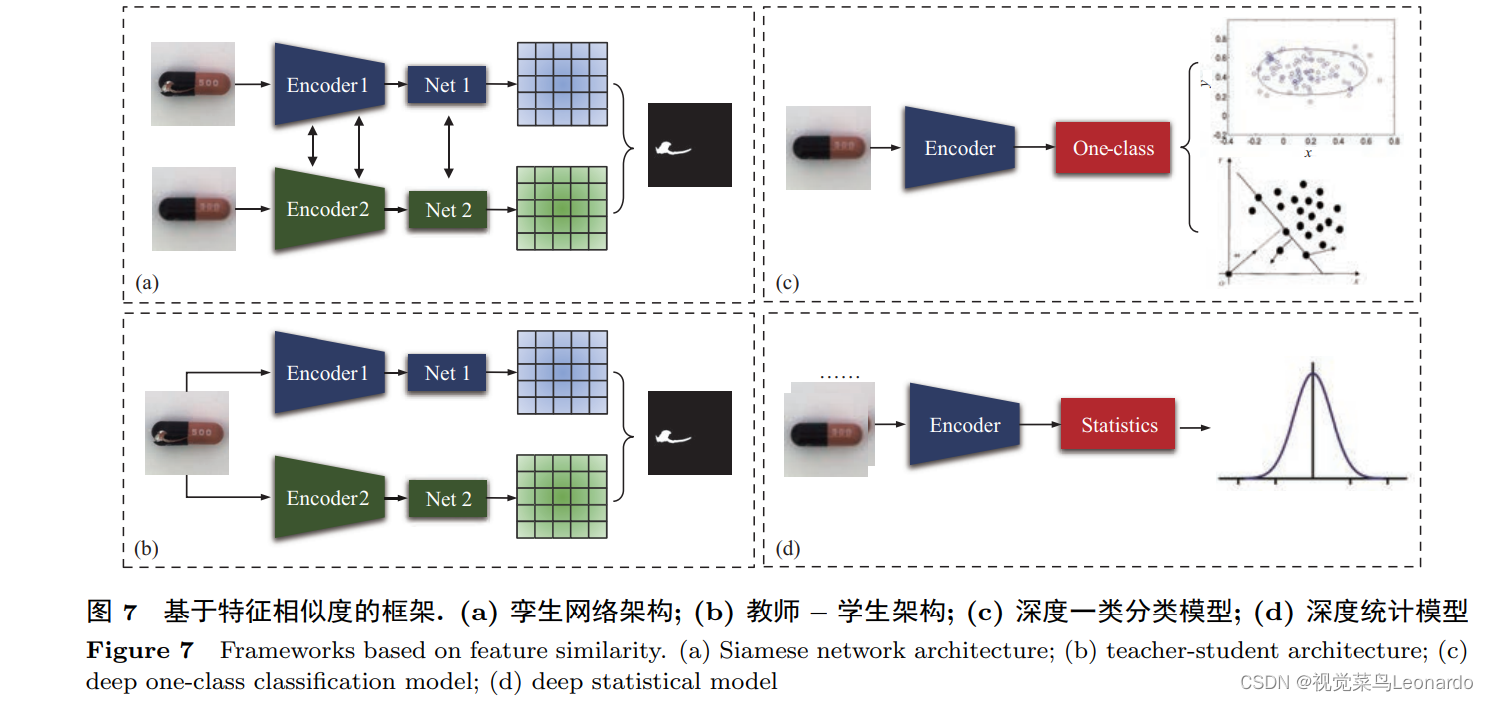
3.3 少量缺陷标注
面对样本稀少、数据不均衡、标注不精确等问题,尝试基于小样本、半监督和弱监督的设置来设计更合理的方法。
3.3.1 小样本学习
小样本学习用于改善样本稀少时模型的性能,解决思路:
(1)网络优化:样本稀少往往会造成两大难题: 当训练轮次受限时, 模型难以快速充分地学习特 征; 当模型在训练集上充分训练时, 又容易导致过拟合的问题. 一方面, 对于过拟合问题, 可以选择更 加合理的网络结构、度量方式和损失函数来抑制, 如, 利用正则项提升模型的泛化性; 另一方面, 合理 的网络设计与稳定的优化过程有助于网络快速收敛 [91] , 使模型在小型数据集上也能有良好的性能. 然 而, 网络与优化过程的设计具有一定的挑战性.
(2)数据扩增:数据扩增是从训练数据的角度提升模型的训练效果与泛化性. 其思想是充分利用 所给数据, 基于对缺陷的特点, 有针对性地设计相应的缺陷数据与正常样本叠加进行缺陷样本的扩充. 面向深孔零件铜丝数据, Tao 等 [141] 利用仿射变换、高斯模糊以及添加椒盐噪声等方法进行缺陷样本 的生成; 面向织物表面数据, Yang 等[112] 通过生成随机掩模与正常样本叠加模拟真实缺陷模式进行缺 陷样本的扩充; 面向多类别工业产品数据, Lin 等 [142] 从缺陷样本中裁剪出缺陷部位与随机正常样本 进行组合叠加进行缺陷数据的扩增. 该类方法易于实现, 但针对某一具体场景设计的缺陷形式难以泛 化到其他场景, 不能从根本上解决小样本问题.
(3)知识迁移:一般情况下, 使用正负样本失衡的训练集对模型从零开始训练极易导致模型失效, 过拟合到训练集中数量较多的一方. 在工业缺陷检测中, 这种失衡的训练数据会导致模型产生大量的 漏检. 为了避免这种现象, 常采用基于知识迁移的方法, 具体可分为迁移学习与元学习.
基于迁移学习的方法指将用于其他任务的模型的知识迁移到工业缺陷检测任务中, 即用少量数 据对预训练模型进行微调.
基于元学习的方法的目标是训练一个初始模型, 其可以利用少量数据快 速地收敛到新任务中, 从而能进行快速的调整.
3.3.2 半监督学习
文章提出了一种新的半监督设置:利用少量有标注数据来实现大量无标注数据 的缺陷分割, 而在训练时综合利用所有数据.
3.3.3 弱监督学习
神经网络可解释性的方法也被用在弱监督的设置中. 此类方法通常利用图像级别的标注训练分 类模型, 然后使用 CAM [11], Grad-CAM [12] 等方法找到特征图中对分类结果贡献最大的区域, 从而实 现缺陷定位. Mayr 等 [156] 基于 Resnet50 的骨干网络设计二分类网络, 基于 CAM 的思想, 利用分类 结果生成缺陷的激活图, 从而得到分割结果. Venkataramanan 等 [95] 利用 VAE 中的注意力机制实现 了弱监督设置下的分割, 为了提升分割性能, 训练时还对注意力图施加约束. 在其无监督设置的基础 上, 增加一个二分类分支来判断样本是否存在缺陷. 训练时, 对正常与异常分类的分数梯度回传, 扩展 正常注意力, 抑制异常注意力. 在推理阶段, 通过注意力图实现分割, 通过分类器实现图像级的分类. 即使只使用少量粗粒度标注的缺陷样本, 也能有效提升模型的性能. 基于弱监督的方法利用粗粒度的标注实现了比无监督更高的性能, 同时与有监督设置所需的精确 标注样本相比, 标注成本更低. 这种权衡在实际情况中具有较大的实用性, 因此, 基于弱监督的方法在 工业缺陷检测领域中也非常值得研究.
3.3.4 自监督学习
自监督学习属于无监督学习的一种, 利用无标 注数据本身自动设计监督标签, 接着借助类似有监督学习的范式训练模型.根据监督信息和代理任务设计方式的不同, 主要可以分为 3 种: 基于图像复 原的方法、基于缺陷合成的方法和基于图像变换的方法.
基于图像复原的方法挖掘图像内在属性与内容的关联性, 主要思想是显式地训练模型将经过变换 的输入图像复原为原始正常图像, 从而在测试阶段, 正常区域的像素基本不变, 而异常区域被擦除, 进 而根据重建误差实现缺陷的检测与分割.考虑采用更加通用的复原任务 , 即直接 在图像中叠加掩膜, 训练网络根据周围信息复原掩膜中的内容. 在测试时, 网络可以输出复原的图像, 然后基于重建误差实现缺陷的检测与分割.
基于缺陷合成的方法通过在正常图像上构造缺陷, 得到缺陷样本及其图像或像素级精确的标签, 从而可以利用对比学习或有监督的方式训练模型.
基于图像变换的方法通过代理任务训练判别式模型,其假设模型能够正确判别正常样本的变换方 式, 而无法预测异常样本的变换方式.
4、辅助技术
数据扩增旨在利用合成等手段增加样本的 多样性, 以提升有监督和自监督方法的性能; 轻量化技术关注模型在实际部署时的时间与空间复杂度, 帮助模型在低功耗设备上达到实时检测的水平; 阈值设置是区分正常与异常样本的关键, 合适而可控 的阈值设置有助于方法实现较高的实际性能。
4.1 数据增强与合成
常用的图像扩增方法包括对原始的缺陷样本采用裁切、旋转、扭曲、仿 射变换等. 这些方 法可以改变缺陷的形状, 但是缺陷依旧处于原有背景, 而缺乏足够的多样性, 且存在图像失真的问题.
由于可以自动学习缺陷的分布, 生成足够逼真的图像, 基于 GAN 的方法被自然地用于缺陷合成, 但是其难以生成复杂而多变的缺陷样式.Defect-GAN 模拟缺陷的制造与修复过程, 不仅可以控制合成缺陷的位置与种类, 而且利 用自适应的噪声添加实现了多样化的缺陷合成.利用该方法合成的缺陷样本有效促进了缺陷 检测模型的训练.
4.2 模型压缩与加速
采用了更加轻量的网络模型, 来提升方法的实用性.
采用更高效的计算单元. 利用 深度可分离卷积替代了传统的卷积操作, 显著降低了模型的计算复杂度。减少模 型结构或计算过程的冗余. 剪枝通过去除大型网络中冗余的神经元与连接, 在不影响性能的前提下, 得到一个更轻量而高效的网络
4.3 阈值设置
大部 分基于图像或特征距离度量的无监督方法对缺陷发生概率的表达往往基于异常分数, 因此难以直接确 定分界面. 这些方法的实际性能对阈值敏感, 促使阈值设置的问题成为迫在眉睫的待解难题。
使用验证集来设置阈值的方法,验证集中只包含正常样本:
最大缺陷分数法. 设定阈值最简单的方法, 是将验证集上预测的最大异常分数作为阈值, 从而保 证模型对验证集上的正常样本恰好不会产生误检. 但由于不同种类的缺陷的分数范围不一致, 该方法 过于保守, 可能会导致在测试时产生大量漏检
p 分位数法. 如果验证集不够纯净, 上述方法会导致阈值过高. 为了提升对验证集的鲁棒性, 设置 阈值时考察模型在验证集上输出的异常分数的整体分布, 并允许存在一定数量的异常像素点. 具体而 言, 预先设置一个 p 分位数, 以该分位数选择一个阈值, 使 p% 的像素点分类为无异常部分.
k-Sigma 阈值法. 为了一定程度上预测假阳性率, 该方法考察模型在验证集上输出的异常分数, 并将其用均值为 µ、标准差为 σ 的高斯分布建模, 然后将阈值定义为 t = µ + kσ. 如果可以假定此分 布完全遵循高斯分布, 则可以选择 k 以在验证集上满足一定的假阳性率, 并推广到测试数据. 然而在 实际情况中, 数据很难恰好呈现高斯分布.
最大缺陷面积法. 上述方法仅考虑单个像素的层面, 但事实上, 缺陷图中可能存在被误检为缺陷 的小面积噪点. 因此, 可预先设置最大缺陷面积, 当分割结果的连通域小于该面积时, 则将其滤除. 阈 值同样设置为验证集恰好不被检出缺陷区域的异常分数.
边栏推荐
猜你喜欢
基础SQL——DDL
Continuous Integration/Continuous Deployment (2) Jenkins & SonarQube
万字长文带你了解多态的底层原理,这一篇就够了
Unity3D - modification of the Inspector panel of the custom class

Notable NFT development trends in 2022
2022年值得关注的NFT发展趋势
小目标检测3_注意力机制_Self-Attention
轻量级网络(一):MobileNet V1,V2, V3系列
Alibaba Sentinel - Slot chain解析
如何在移动钱包中搭建一个小程序应用商店
随机推荐
IPQ4019/IPQ4029 support WiFi6 MiniPCIe Module 2T2R 2×2.4GHz 2x5GHz MT7915 MT7975
Kotlin算法入门求自由落体
关于ts的一些泛型关键字用法
Getting Started with Kotlin Algorithms Calculating Prime Factors
[wxGlade learning] wxGlade environment configuration
企业服务器主机加固现状分析
基于consul的注册发现的微服务架构迁移到servicemesh
mysql添加用户以及设置权限
idea 方法注释:自定义修改method的return和params,void不显示
关于ts中的指针问题call,bind, apply
Getting Started with Kotlin Algorithm to Calculate the Number of Daffodils
欧拉函数(用欧拉筛法求欧拉函数)
One network cable to transfer files between two computers
装饰器模式:Swift 实现
Kotlin算法入门求回文数数算法优化二数字生成规则
框架外的PHP读取.env文件(php5.6、7.3可用版)
Birth of the Go language
Audio and video + AI, Zhongguancun Kejin helps a bank explore a new development path | Case study
JUC Concurrent Programming
基于C#通过PLCSIM ADV仿真软件实现与西门子1500PLC的S7通信方法演示