clean-fid: Fixing Inconsistencies in FID

The FID calculation involves many steps that can produce inconsistencies in the final metric. As shown below, different implementations use different low-level image quantization and resizing functions, the latter of which are often implemented incorrectly.
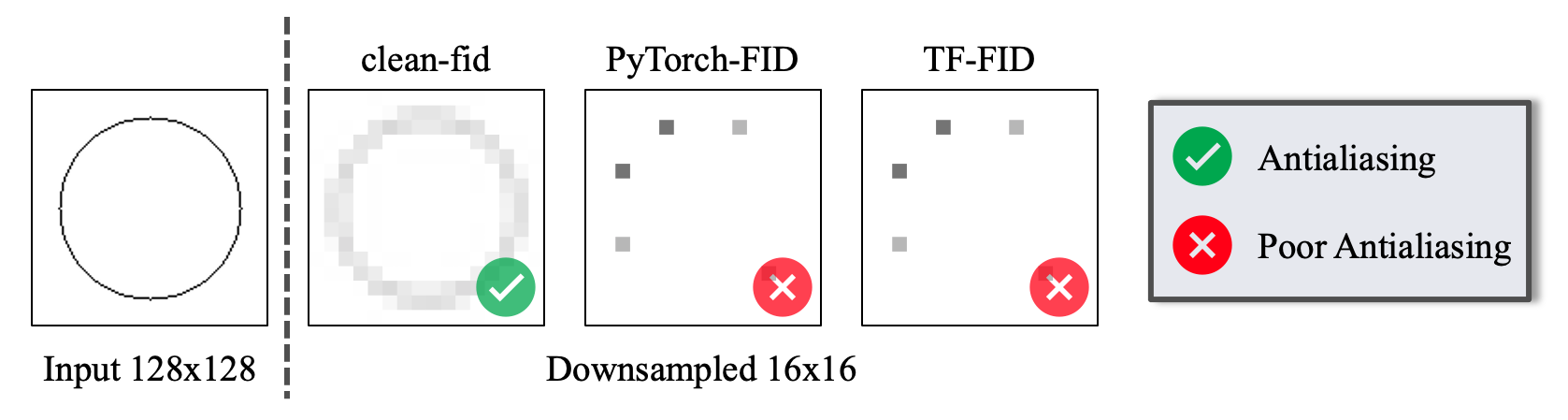
We provide an easy-to-use library to address the above issues and make the FID scores comparable across different methods, papers, and groups.
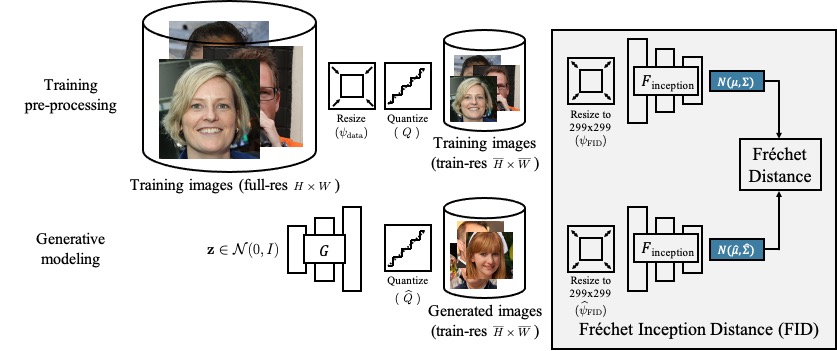
On Buggy Resizing Libraries and Surprising Subtleties in FID Calculation
Gaurav Parmar, Richard Zhang, Jun-Yan Zhu
arXiv 2104.11222, 2021
CMU and Adobe
Buggy Resizing Operations
The definitions of resizing functions are mathematical and should never be a function of the library being used. Unfortunately, implementations differ across commonly-used libraries. They are often implemented incorrectly by popular libraries.
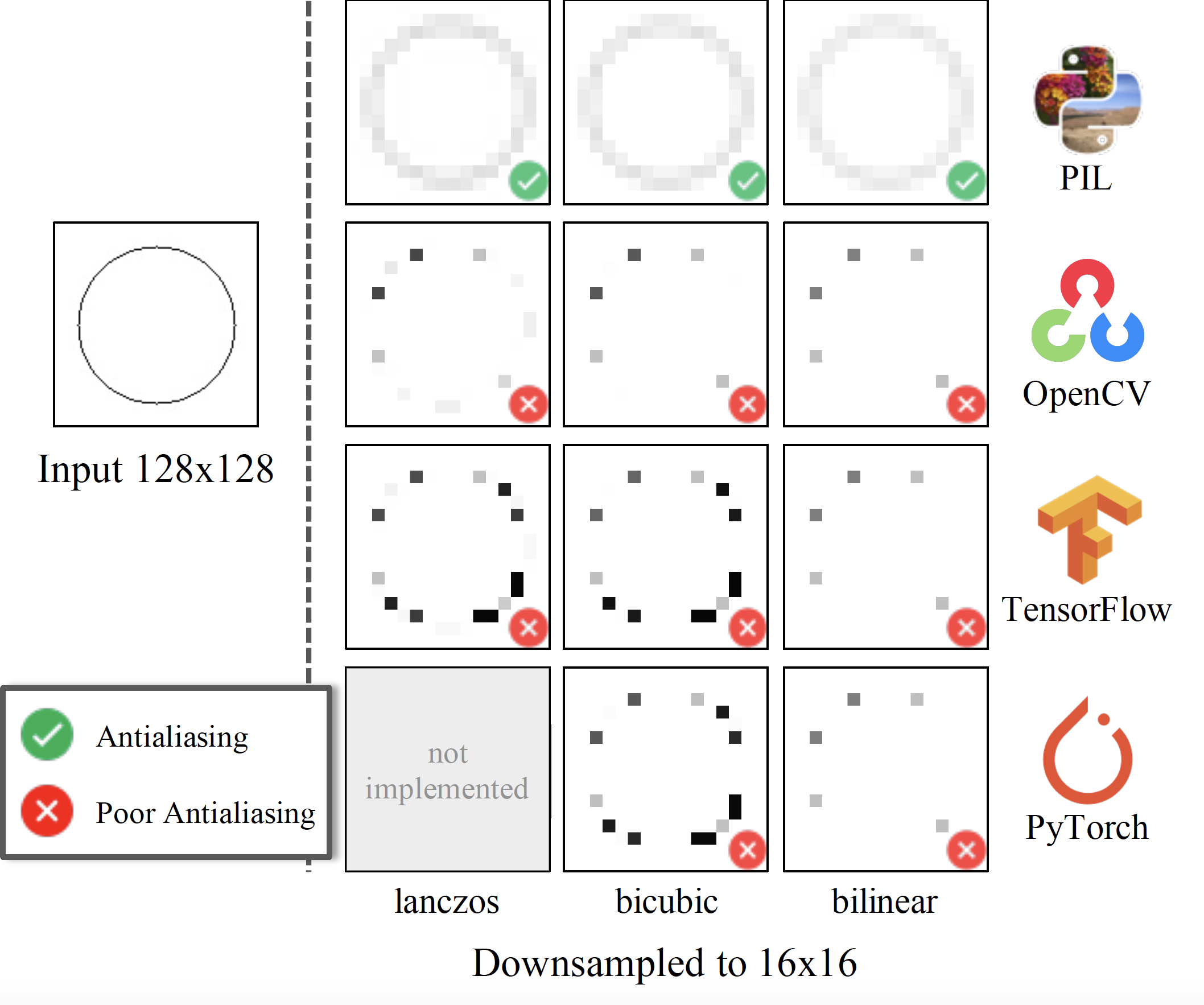
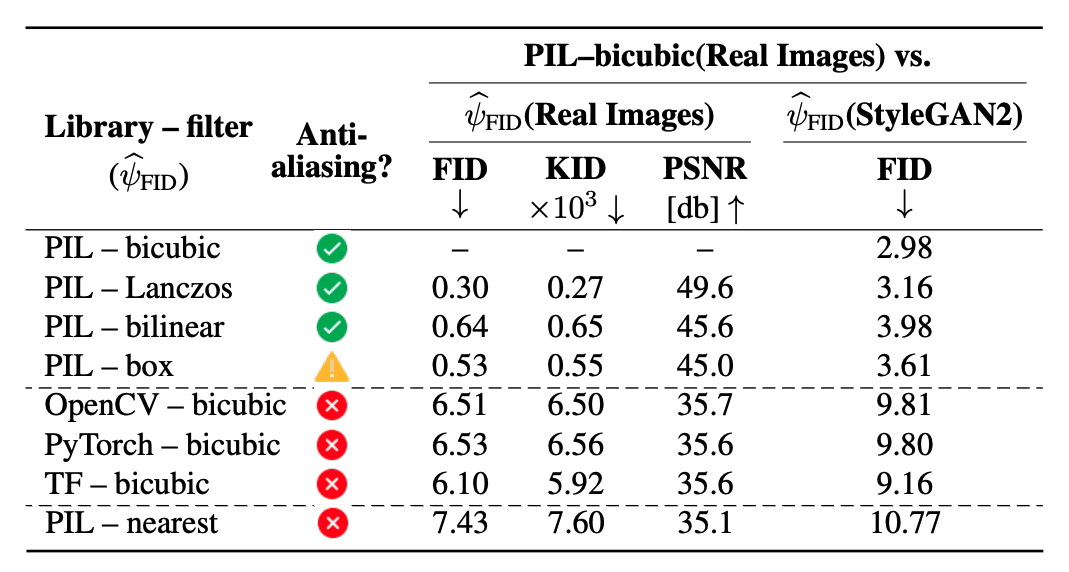
The inconsistencies among implementations can have a drastic effect of the evaluations metrics. The table below shows that FFHQ dataset images resized with bicubic implementation from other libraries (OpenCV, PyTorch, TensorFlow, OpenCV) have a large FID score (≥ 6) when compared to the same images resized with the correctly implemented PIL-bicubic filter. Other correctly implemented filters from PIL (Lanczos, bilinear, box) all result in relatively smaller FID score (≤ 0.75).
JPEG Image Compression
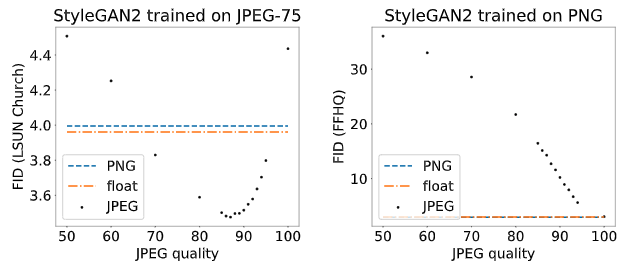
Image compression can have a surprisingly large effect on FID. Images are perceptually indistinguishable from each other but have a large FID score. The FID scores under the images are calculated between all FFHQ images saved using the corresponding JPEG format and the PNG format.

Below, we study the effect of JPEG compression for StyleGAN2 models trained on the FFHQ dataset (left) and LSUN outdoor Church dataset (right). Note that LSUN dataset images were collected with JPEG compression (quality 75), whereas FFHQ images were collected as PNG. Interestingly, for LSUN dataset, the best FID score (3.48) is obtained when the generated images are compressed with JPEG quality 87.
Quick Start
-
install requirements
pip install -r requirements.txt -
install the library
pip install clean-fid -
Compute FID between two image folders
from cleanfid import fid score = fid.compute_fid(fdir1, fdir2) -
Compute FID between one folder of images and pre-computed datasets statistics (e.g.,
FFHQ)from cleanfid import fid score = fid.compute_fid(fdir1, dataset_name="FFHQ", dataset_res=1024) -
Compute FID using a generative model and pre-computed dataset statistics:
from cleanfid import fid # function that accepts a latent and returns an image in range[0,255] gen = lambda z: GAN(latent=z, ... , <other_flags>) score = fid.compute_fid(gen=gen, dataset_name="FFHQ", dataset_res=256, num_gen=50_000)
Supported Precomputed Datasets
We provide precompute statistics for the following configurations
| Task | Dataset | Resolution | split | mode |
|---|---|---|---|---|
| Image Generation | FFHQ | 256,1024 | train+val |
clean, legacy_pytorch, legacy_tensorflow |
| Image Generation | LSUN Outdoor Churches | 256 | train |
clean, legacy_pytorch, legacy_tensorflow |
| Image to Image | horse2zebra | 128,256 | train, test, train+test |
clean, legacy_pytorch, legacy_tensorflow |
Using precomputed statistics In order to compute the FID score with the precomputed dataset statistics, use the corresponding options. For instance, to compute the clean-fid score on generated 256x256 FFHQ images use the command:
fid_score = fid.compute_fid(fdir1, dataset_name="FFHQ", dataset_res=256, mode="clean")
Create Custom Dataset Statistics
- dataset_path: folder where the dataset images are stored
- Generate and save the inception statistics
import numpy as np from cleanfid import fid dataset_path = ... feat = fid.get_folder_features(dataset_path, num=50_000) mu = np.mean(feats, axis=0) sigma = np.cov(feats, rowvar=False) np.savez_compressed("stats.npz", mu=mu, sigma=sigma)
Backwards Compatibility
We provide two flags to reproduce the legacy FID score.
-
mode="legacy_pytorch"
This flag is equivalent to using the popular PyTorch FID implementation provided here
The difference between using clean-fid with this option and code is ~1.9e-06
See doc for how the methods are compared -
mode="legacy_tensorflow"
This flag is equivalent to using the official implementation of FID released by the authors. To use this flag, you need to additionally install tensorflow. The tensorflow cuda version may cause issues with the pytorch code. I have tested this with TensorFlow-cpu 2.2 (`pip install tensorflow-cpu==2.2)
CleanFID Leaderboard for common tasks
FFHQ @ 1024x1024
| Model | Legacy-FID | Clean-FID |
|---|---|---|
| StyleGAN2 | 2.85 ± 0.05 | 3.08 ± 0.05 |
| StyleGAN | 4.44 ± 0.04 | 4.82 ± 0.04 |
| MSG-GAN | 6.09 ± 0.04 | 6.58 ± 0.06 |
Image-to-Image (horse->zebra @ 256x256) Computed using test images
| Model | Legacy-FID | Clean-FID |
|---|---|---|
| CycleGAN | 77.20 | 75.17 |
| CUT | 45.51 | 43.71 |
Building from source
python setup.py bdist_wheel
pip install dist/*
Citation
If you find this repository useful for your research, please cite the following work.
@article{parmar2021cleanfid,
title={On Buggy Resizing Libraries and Surprising Subtleties in FID Calculation},
author={Parmar, Gaurav and Zhang, Richard and Zhu, Jun-Yan},
journal={arXiv preprint arXiv:2104.11222},
year={2021}
}
Credits
PyTorch-StyleGAN2: code | License

 889 Dec 30, 2022
889 Dec 30, 2022
 64 Dec 29, 2022
64 Dec 29, 2022
 11 Sep 05, 2022
11 Sep 05, 2022
 0 Dec 14, 2021
0 Dec 14, 2021
 332 Dec 18, 2022
332 Dec 18, 2022
 27 Dec 20, 2022
27 Dec 20, 2022
 1 Feb 11, 2022
1 Feb 11, 2022
 4 Jun 16, 2022
4 Jun 16, 2022
 93 Nov 30, 2022
93 Nov 30, 2022
 160 Dec 09, 2022
160 Dec 09, 2022
 27 Jan 07, 2023
27 Jan 07, 2023
 1 Jan 18, 2022
1 Jan 18, 2022
 6 Jul 01, 2022
6 Jul 01, 2022
 111 Dec 23, 2022
111 Dec 23, 2022
 10 Dec 07, 2022
10 Dec 07, 2022
 87 Mar 06, 2022
87 Mar 06, 2022
 143 Dec 13, 2022
143 Dec 13, 2022
 2 Dec 11, 2021
2 Dec 11, 2021
 715 Nov 05, 2022
715 Nov 05, 2022