VoiceFixer
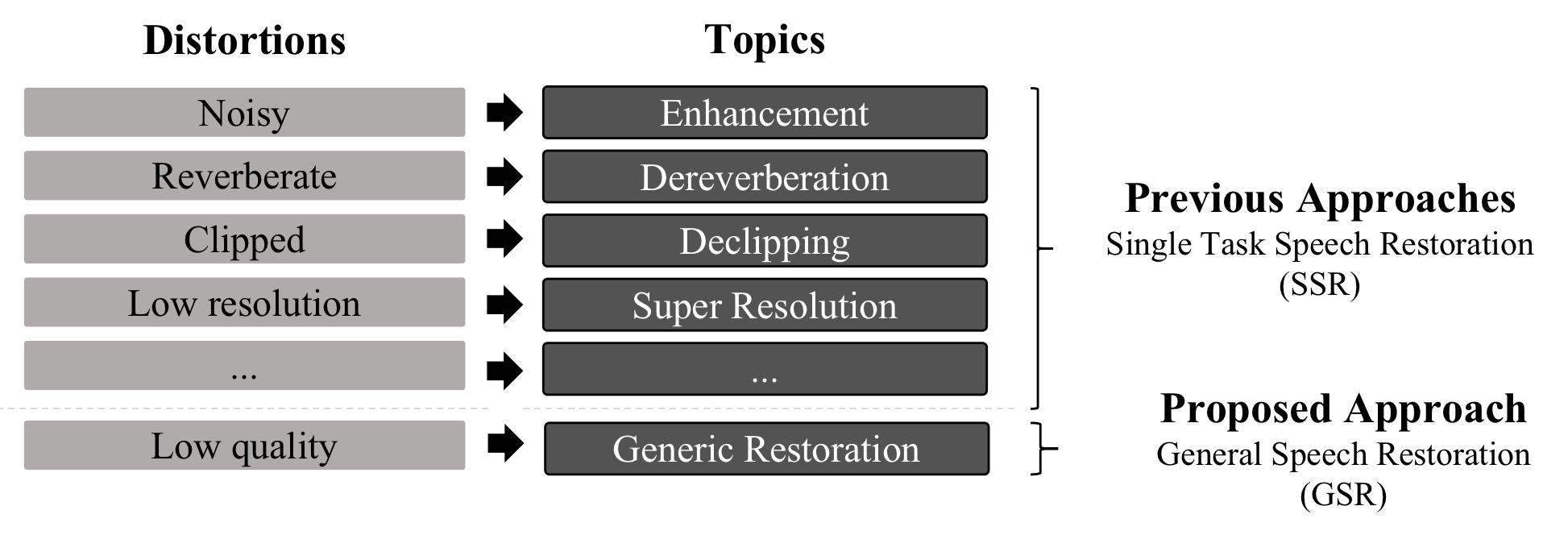
VoiceFixer is a framework for general speech restoration. We aim at the restoration of severly degraded speech and historical speech.
Paper
Usage
Environment
# Download dataset and prepare running environment
source init.sh
Train from scratch
Let's take VF_UNet(voicefixer with unet as analysis module) as an example. Other model have the similar training and evaluation logic.
cd general_speech_restoration/voicefixer/unet
source run.sh
After that, you will get a log directory that look like this
├── unet
│ └── log
│ └── 2021-09-27-xxx
│ └── version_0
│ └── checkpoints
└──epoch=1.ckpt
│ └── code
Evaluation
Automatic evaluation and generate .csv file for the results.
cd general_speech_restoration/voicefixer/unet
# Basic usage
python3 handler.py -c <str, path-to-checkpoint> \
-t <str, testset> \
-l <int, limit-utterance-number> \
-d <str, description of this evaluation> \
For example, if you like to evaluate on all testset. And each testset you intend to limit the number to 10 utterance.
python3 handler.py -c log/2021-09-27-xxx/version_0/checkpoints/epoch=1.ckpt \
-t base \
-l 10 \
-d ten_utterance_for_each_testset \
There are generally seven testsets:
- base: all testset
- clip: testset with speech that have clipping threshold of 0.1, 0.25, and 0.5
- reverb: testset with reverberate speech
- general_speech_restoration: testset with speech that contain all kinds of random distortions
- enhancement: testset with noisy speech
- speech_super_resolution: testset with low resolution speech that have sampling rate of 2kHz, 4kHz, 8kHz, 16kHz, and 24kHz.
Demo
Demo page
Demo page contains comparison between single task speech restoration, general speech restoration, and voicefixer.
Pip package
We wrote a pip package for voicefixer.
Colab
You can try voicefixer using your own voice on colab!



Project Structure
.
├── dataloaders
│ ├── augmentation # code for speech data augmentation.
│ └── dataloader # code for different kinds of dataloaders.
├── datasets
│ ├── datasetParser # code for preparing each dataset
│ └── se # Dataset for speech enhancement (source init.sh)
│ ├── RIR_44k # Room Impulse Response 44.1kHz
│ │ ├── test
│ │ └── train
│ ├── TestSets # Evaluation datasets
│ │ ├── ALL_GSR # General speech restoration testset
│ │ │ ├── simulated
│ │ │ └── target
│ │ ├── DECLI # Speech declipping testset
│ │ │ ├── 0.1 # Different clipping threshold
│ │ │ ├── 0.25
│ │ │ ├── 0.5
│ │ │ └── GroundTruth
│ │ ├── DENOISE # Speech enhancement testset
│ │ │ └── vd_test
│ │ │ ├── clean_testset_wav
│ │ │ └── noisy_testset_wav
│ │ ├── DEREV # Speech dereverberation testset
│ │ │ ├── GroundTruth
│ │ │ └── Reverb_Speech
│ │ └── SR # Speech super resolution testset
│ │ ├── GroundTruth
│ │ └── cheby1
│ │ ├── 1000 # Different cutoff frequencies
│ │ ├── 12000
│ │ ├── 2000
│ │ ├── 4000
│ │ └── 8000
│ ├── vd_noise # Noise training dataset
│ └── wav48 # Speech training dataset
│ ├── test # Not used, included for completeness
│ └── train
├── evaluation # The code for model evaluation
├── exp_results # The Folder that store evaluation result (in handler.py).
├── general_speech_restoration # GSR
│ ├── unet # GSR_UNet
│ │ └── model_kqq_lstm_mask_gan
│ └── voicefixer # Each folder contains the training entry for each model.
│ ├── dnn # VF_DNN
│ ├── lstm # VF_LSTM
│ ├── unet # VF_UNet
│ └── unet_small # VF_UNet_S
├── resources
├── single_task_speech_restoration # SSR
│ ├── declip_unet # Declip_UNet
│ ├── derev_unet # Derev_UNet
│ ├── enh_unet # Enh_UNet
│ └── sr_unet # SR_UNet
├── tools
└── callbacks
Citation

 78 Dec 12, 2022
78 Dec 12, 2022
 6 Oct 22, 2022
6 Oct 22, 2022
 612 Jan 04, 2023
612 Jan 04, 2023
 338 Dec 02, 2022
338 Dec 02, 2022
 5 Oct 24, 2022
5 Oct 24, 2022
 9 Dec 28, 2022
9 Dec 28, 2022
 75 Dec 19, 2022
75 Dec 19, 2022
 20 Nov 18, 2022
20 Nov 18, 2022
 65 Sep 13, 2022
65 Sep 13, 2022
 8 Aug 11, 2022
8 Aug 11, 2022
 12 Dec 14, 2022
12 Dec 14, 2022
 1 Jan 29, 2022
1 Jan 29, 2022
 11 Jun 13, 2022
11 Jun 13, 2022
 2 Mar 17, 2022
2 Mar 17, 2022
 29 Dec 05, 2022
29 Dec 05, 2022
 47 Aug 14, 2022
47 Aug 14, 2022
 73 Dec 11, 2022
73 Dec 11, 2022
 901 Jan 06, 2023
901 Jan 06, 2023
 88 Dec 23, 2022
88 Dec 23, 2022