当前位置:网站首页>R-CNN Fast R-CNN Faster R-CNN总结
R-CNN Fast R-CNN Faster R-CNN总结
2022-08-09 14:57:00 【明天一定早睡早起】
Faster RCNN理论合集
他的视频总结的非常好!在CSDN也有博客。用户名:太阳花的小绿豆
这篇博客基本是在他的视频里面进行总结的。具体论文还没有看。
R-CNN
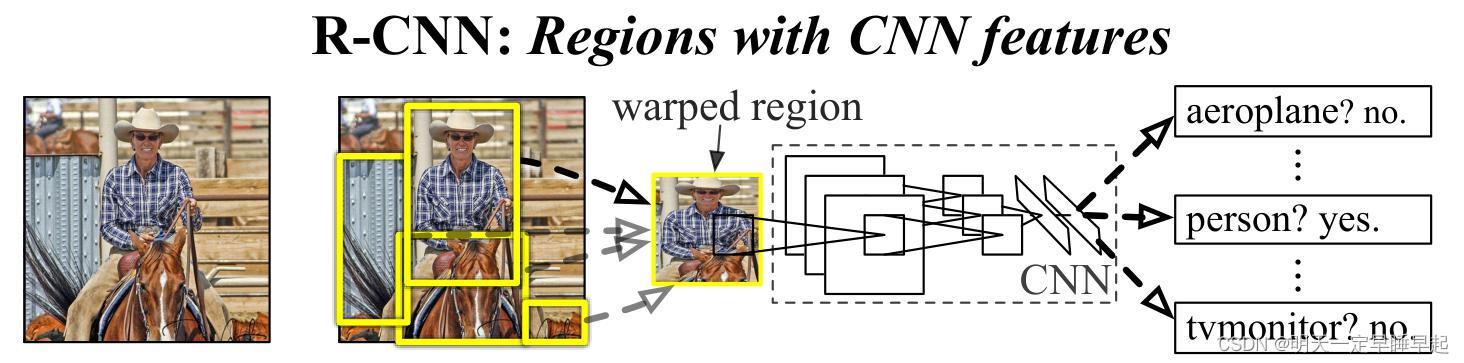
算法流程
RCNN算法流程可分为4个步骤
- 一张图像生成1K~2K个候选区域(使用Selective Search方法)
利用Selective Search算法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。 - 对每个候选区域,使用深度网络提取特征
将2000候选区域缩放到227x227pixel,接着将候选区域输入事先训练好的CNN网络获取特征。 - 特征送入每一类的SVM 分类器,判别是否属于该类
将特征送入SVM得到获得每个候选区域的不同类别的得分(概率),分别对每一类进行非极大值抑制剔除重叠建议框,得到该类中得分最高的一些建议框。
参考:NMS——非极大值抑制 - 使用回归器精细修正候选框位置
对NMS处理后剩余的建议框进一步筛选。分别用回归器对类别中剩余的建议框进行回归操作,最终得到x,y的偏移量以及w,h的缩放因子。最终得到每个类别修正后得分最高的bounding box。
存在的问题
R-CNN存在的问题:
- 测试速度慢:
测试一张图片约53s(CPU)。用Selective Search算法提取候选框用时约2秒,一张图像内候选框之间存在大
量重叠,提取特征操作冗余。 - 训练速度慢:
过程及其繁琐 - 训练所需空间大:
对于SVM和bbox回归训练,需要从每个图像中的每个目标候选框提取特征,并写入磁盘。对于非常深的网络,如VGG16,从VOC07训练集上的5k图像上提取的特征需要数百GB的存储空间。
FAST R-CNN

算法流程
Fast R-CNN算法流程可分为3个步骤
- 一张图像生成1K~2K个候选区域(使用Selective Search方法)
和RCNN第一步一致 - 将图像输入网络得到相应的特征图,将SS算法生成的候选框投影到特征图上获得相应的特征矩阵
区别于RCNN:- 没有将第一步生成的候选区域全部输入CNN提取特征,而是直接将整幅图像输入CNN提取特征,再将候选区域投影到特征矩阵。这样就不用重复计算候选区域的特征矩阵了。
- 候选区域也并非全部投影到特征矩阵,而是按照一定规则先进行筛选。
- 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果(分类结果以及边界框回归)
ROI池化使得FAST RCNN不限制图像输入的尺寸,而RCNN当中限定了输入图像必须是227x227。
ROI池化的步骤:- 输入特征图划分成NxN的区域。
- 每个区域求max pooling。
边界框回归器
边界框回归器输出候选边界框的回归参数 ( d x , d y , d w , d h ) (d_x, d_y, d_w, d_h) (dx,dy,dw,dh)
P x , P y , P w , P h P_x,P_y,P_w,P_h Px,Py,Pw,Ph分别为候选框的中心x,y坐标,以及宽高
G ^ x , G ^ y , G ^ w , G ^ h \hat{G}_x,\hat{G}_y,\hat{G}_w,\hat{G}_h G^x,G^y,G^w,G^h分别为最终预测的边界框中心x,y坐标,以及宽高
G x , G y , G w , G h G_x,G_y,G_w,G_h Gx,Gy,Gw,Gh分别为ground truth的中心x,y坐标,以及宽高
G ^ x = P w d x + P x G ^ y = P h d x + P y G ^ w = P w exp ( d w ) G ^ h = P h exp ( d h ) \hat{G}_x=P_wd_x+P_x\\ \hat{G}_y=P_hd_x+P_y\\ \hat{G}_w=P_w\exp(d_w)\\ \hat{G}_h=P_h\exp(d_h)\\ G^x=Pwdx+PxG^y=Phdx+PyG^w=Pwexp(dw)G^h=Phexp(dh)
Multi-task loss
L ( p , u , t u , v ) = 分 类 损 失 + 边 界 框 回 归 损 失 = L c l s ( p , u ) + λ [ u ⩾ 1 ] L l o c ( t u , v ) L(p,u,t^u,v)=分类损失+边界框回归损失=L_{cls}(p,u)+\lambda[u\geqslant1]L_{loc}(t^u,v) L(p,u,tu,v)=分类损失+边界框回归损失=Lcls(p,u)+λ[u⩾1]Lloc(tu,v)
p p p是分类器预测的softmax概率分布 p = ( p 0 . . . p k ) p=(p_0...p_k) p=(p0...pk)
u u u对应真实类别标签(采用one-hot编码)
t u t^u tu对应边界框回归器预测的回归参数 ( t x u , t y u , t w u , t h u ) (t^u_x, t^u_y, t^u_w, t^u_h) (txu,tyu,twu,thu)
v v v对应真实目标的边界框回归参数 ( v x , v y , v w , v h ) (v_x, v_y, v_w, v_h) (vx,vy,vw,vh),可以通过下面的公式逆推
G x = P w v x + P x G y = P h v x + P y G w = P w exp ( v w ) G h = P h exp ( v h ) G_x=P_wv_x+P_x\\ G_y=P_hv_x+P_y\\ G_w=P_w\exp(v_w)\\ G_h=P_h\exp(v_h)\\ Gx=Pwvx+PxGy=Phvx+PyGw=Pwexp(vw)Gh=Phexp(vh)
分类损失
修正分类。
L c l s ( p , u ) = − log ( p u ) L_{cls}(p,u)=-\log(p_u) Lcls(p,u)=−log(pu)
p p p是分类器预测的softmax概率分布 p = ( p 0 . . . p k ) p=(p_0...p_k) p=(p0...pk)
u u u对应真实类别标签(采用one-hot编码)
由于采用的是one-hot编码,非对应类别的标签都为0,化简即可得上述公式
边界框回归损失
修正边界框。
L l o c ( t u , v ) = ∑ i ∈ { x , y , w , h } s m o o t h L 1 ( t i u − v i ) L_{loc}(t^u,v)=\sum_{i\in\{x,y,w,h\}}smooth_{L_1}(t^u_i-v_i) Lloc(tu,v)=i∈{ x,y,w,h}∑smoothL1(tiu−vi)
s m o o t h L 1 ( x ) = { 0.5 x 2 , i f ∣ x ∣ < 1 ∣ x ∣ − 0.5 , o t h e r w i s e smooth_{L_1}(x)=\left\{ \begin{array}{lr} 0.5x^2,& if |x| <1\\ |x|-0.5,& otherwise\\ \end{array}{} \right. smoothL1(x)={ 0.5x2,∣x∣−0.5,if∣x∣<1otherwise
FASTER R-CNN
算法流程

Faster R-CNN算法流程可分为3个步骤
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
RPN (region proposal networ)
RPN生成的候选框会等比例放缩回输入图像,RPN结构如图所示
有几点需要知道:
- 在原文中使用的是ZF model,其Conv Layers中最后的conv5层输出的num_output=256,对应生成256张特征图,所以相当于feature map每个点都是256-dimensions。
- 对conv feature map做3x3卷积,且num_output=256。
- 假设在conv feature map中每个点上有k个anchor(论文k=9),而每个anhcor分为positive(前景)和negative(背景),所以每个点由256d feature通过两个1x1卷积分别转化为cls=2k个scores;而每个anchor都有(x, y, w, h)对应4个修正量,所以reg=4k个coordinates。
- 并不会选取所有anchor用于训练。训练程序会在合适的anchors中随机选取128个postive anchors+128个negative anchors进行训练。
anchor
三种尺度(面积) { 12 8 2 , 25 6 2 , 51 2 2 } \{128^2,256^2,512^2\} { 1282,2562,5122},由经验所得
三种比例 { 1 : 1 , 1 : 2 , 2 : 1 } \{ 1:1, 1:2, 2:1 \} { 1:1,1:2,2:1}
每个位置在原图上都对应有 3 × 3 = 9 3\times3=9 3×3=9个anchor
对于一张1000x600x3的图像,大约有60x40x9(20k)个anchor,忽略跨越边界的anchor以后,剩下约6k个anchor。对于RPN生成的候选框之间存在大量重叠,基于候选框的cls得分,采用非极大值抑制,IoU设为0.7,这样每张图片只剩2k个候选框。
RPN Multi-task loss
L ( { p i } , { t i } ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ i p i ∗ L r e g ( t i , t i ∗ ) L(\{p_i\},\{t_i\})=\frac{1}{N_{cls}}\sum_iL_{cls}(p_i,p_i^*)+\lambda\frac{1}{N_{reg}}\sum_ip_i^*L_{reg}(t_i,t_i^*) L({ pi},{ ti})=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
p i p_i pi表示第i个anchor预测为真实标签的概率
p i ∗ p_i^* pi∗当为正样本时为1,当为负样本时为0
t i t_i ti表示第i个anchor的边界框回归参数
t i ∗ t_i^* ti∗表示第i个anchor对应的ground truth bbox的边界框回归参数
N c l s N_{cls} Ncls表示一个mini-batch中所有样本数量,论文为256
N r e g N_{reg} Nreg表示中心点的个数,约2400
λ \lambda λ为超参数,论文为10
感觉和FAST R-CNN的loss差不多,都是分类损失+边界框回归损失。
Faster R-CNN Multi-task loss
这部分和fast r-cnn一致
L ( p , u , t u , v ) = 分 类 损 失 + 边 界 框 回 归 损 失 = L c l s ( p , u ) + λ [ u ⩾ 1 ] L l o c ( t u , v ) L(p,u,t^u,v)=分类损失+边界框回归损失=L_{cls}(p,u)+\lambda[u\geqslant1]L_{loc}(t^u,v) L(p,u,tu,v)=分类损失+边界框回归损失=Lcls(p,u)+λ[u⩾1]Lloc(tu,v)
边栏推荐
- At the beginning of the C language order 】 【 o least common multiple of three methods
- Linux安装mysql8.0详细步骤--(快速安装好)
- 【 Leetcode 】 433. The smallest genetic changes
- 防关联浏览器对亚马逊测评有多重要?
- [Deep Learning] Original Problem and Dual Problem (6)
- 【深度学习】目标检测之评价指标
- MouStart指纹浏览器怎么防关联
- 深入浅出最优化(3) 最速下降法与牛顿法
- 响应式布局总结
- 【深度学习】前向传播和反向传播(四)
猜你喜欢





![[Deep Learning] Original Problem and Dual Problem (6)](/img/96/7c08173fb6fc43899641f0a66f795d.png)


随机推荐
分类任务系列学习——总述
研究生工作周报
关于亚马逊测评你了解多少?
微信小程序自定义日期选择器(带标题的)
你知道亚马逊代运营的成本是多少吗?
面试合集
Hold face (hugging face) tutorial - Chinese translation - task summary
链游是什么意思 链游和游戏的区别是什么
关于亚马逊的坑你知道几个?
SNR signal-to-noise ratio
【研究生工作周报】(第八周)
hugging face tutorial-Chinese translation-pipeline-based reasoning
[Deep Learning] Original Problem and Dual Problem (6)
从数组到js基础结束
【Postgraduate Work Weekly】(Week 8)
抱抱脸(hugging face)教程-中文翻译-创建一个自定义架构
【深度学习】介绍六大类损失函数(九)
Region实战SVG地图点击
GoogLeNet
众所周知亚马逊是全球最大的在线电子商务公司。如今,它已成为全球商品种类最多的在线零售商,日活跃买家约为20-25亿。另一方面,也有大大小小的企业,但不是每个人都能赚到刀! 做网店的同学都知道,