当前位置:网站首页>Deep learning notes - semantic segmentation and data sets
Deep learning notes - semantic segmentation and data sets
2022-04-23 04:57:00 【Whisper_ yl】


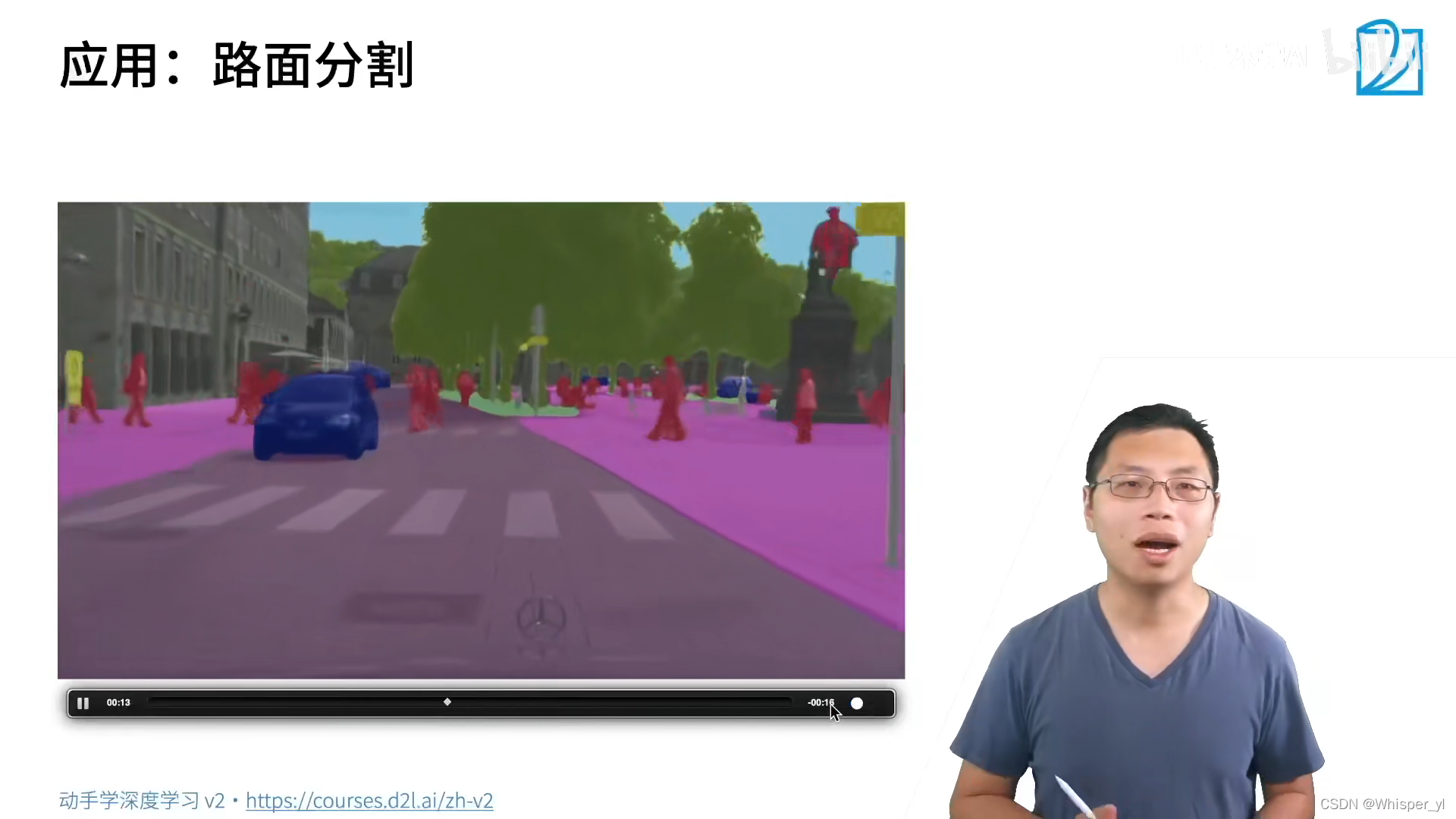
 Semantic segmentation only cares about which class the pixel belongs to , Instance segmentation concerns which instance of which class the pixel belongs to ( It can be considered as an evolutionary version of target detection ).
Semantic segmentation only cares about which class the pixel belongs to , Instance segmentation concerns which instance of which class the pixel belongs to ( It can be considered as an evolutionary version of target detection ).
import os
import torch
import torchvision
from d2l import torch as d2l
import matplotlib.pyplot as plt
d2l.DATA_HUB['voc2012'] = (d2l.DATA_URL + 'VOCtrainval_11-May-2012.tar',
'4e443f8a2eca6b1dac8a6c57641b67dd40621a49')
voc_dir = d2l.download_extract('voc2012', 'VOCdevkit/VOC2012')
# Read all input images and labels into memory
def read_voc_images(voc_dir, is_train=True):
""" Read all VOC Image and label """
txt_fname = os.path.join(voc_dir, 'ImageSets', 'Segmentation',
'train.txt' if is_train else 'val.txt')
mode = torchvision.io.image.ImageReadMode.RGB
with open(txt_fname, 'r') as f:
images = f.read().split()
features, labels = [], []
for i, fname in enumerate(images):
features.append(torchvision.io.read_image(os.path.join(
voc_dir, 'JPEGImages', f'{fname}.jpg')))
labels.append(torchvision.io.read_image(os.path.join(
voc_dir, 'SegmentationClass', f'{fname}.png'), mode))
return features, labels
train_features, train_labels = read_voc_images(voc_dir, True)
# Before drawing 5 An input image and its label
n = 5
imgs = train_features[0:n] + train_labels[0:n]
imgs = [img.permute(1, 2, 0) for img in imgs]
d2l.show_images(imgs, 2, n)
plt.show()
# list RGB Color value and class name ( Each label corresponds to pixel Of RGB value )
VOC_COLORMAP = [[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]]
VOC_CLASSES = ['background', 'aeroplane', 'bicycle', 'bird', 'boat',
'bottle', 'bus', 'car', 'cat', 'chair', 'cow',
'diningtable', 'dog', 'horse', 'motorbike', 'person',
'potted plant', 'sheep', 'sofa', 'train', 'tv/monitor']
# Find the class index of each pixel in the label
def voc_colormap2label():
""" Build from RGB To VOC Mapping of category indexes """
colormap2label = torch.zeros(256 ** 3, dtype=torch.long)
for i, colormap in enumerate(VOC_COLORMAP):
colormap2label[
(colormap[0] * 256 + colormap[1]) * 256 + colormap[2]] = i
return colormap2label
def voc_label_indices(colormap, colormap2label):
""" take VOC In the tag RGB Values map to their category index """
colormap = colormap.permute(1, 2, 0).numpy().astype('int32')
idx = ((colormap[:, :, 0] * 256 + colormap[:, :, 1]) * 256
+ colormap[:, :, 2])
return colormap2label[idx]
y = voc_label_indices(train_labels[0], voc_colormap2label())
print(y[105:115, 130:140], VOC_CLASSES[1])
# Use random clipping in image augmentation , Crop the same area of the input image and label
def voc_rand_crop(feature, label, height, width):
""" Randomly crop features and label images """
rect = torchvision.transforms.RandomCrop.get_params(
feature, (height, width))
feature = torchvision.transforms.functional.crop(feature, *rect)
label = torchvision.transforms.functional.crop(label, *rect)
return feature, label
imgs = []
for _ in range(n):
imgs += voc_rand_crop(train_features[0], train_labels[0], 200, 300)
imgs = [img.permute(1, 2, 0) for img in imgs]
d2l.show_images(imgs[::2] + imgs[1::2], 2, n)
plt.show()
# Custom semantic segmentation dataset class
# When doing small batch training , You need to make the picture the same size , So we need to crop, Don't be casual resize
class VOCSegDataset(torch.utils.data.Dataset):
""" One for loading VOC Custom datasets for datasets """
def __init__(self, is_train, crop_size, voc_dir):
# I want to use it later ImageNet Upper pre-train model
self.transform = torchvision.transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
self.crop_size = crop_size
features, labels = read_voc_images(voc_dir, is_train=is_train)
self.features = [
# do RGB Normalization
self.normalize_image(feature)
for feature in self.filter(features)]
self.labels = self.filter(labels)
self.colormap2label = voc_colormap2label()
print('read ' + str(len(self.features)) + ' examples')
def normalize_image(self, img):
return self.transform(img.float() / 255)
# If the picture is better than crop_size If your height and width are smaller , Then discard
def filter(self, imgs):
return [img for img in imgs if (
img.shape[1] >= self.crop_size[0] and
img.shape[2] >= self.crop_size[1])]
def __getitem__(self, idx):
feature, label = voc_rand_crop(self.features[idx], self.labels[idx],
*self.crop_size)
return (feature, voc_label_indices(label, self.colormap2label))
def __len__(self):
return len(self.features)
# Reading data sets
crop_size = (320, 480)
voc_train = VOCSegDataset(True, crop_size, voc_dir)
voc_test = VOCSegDataset(False, crop_size, voc_dir)
batch_size = 64
train_iter = torch.utils.data.DataLoader(voc_train, batch_size, shuffle=True,
drop_last=True,
num_workers=d2l.get_dataloader_workers())
for X, Y in train_iter:
print(X.shape)
print(Y.shape)
break
# Integrate all components
def load_data_voc(batch_size, crop_size):
""" load VOC Semantic segmentation dataset """
voc_dir = d2l.download_extract('voc2012', os.path.join(
'VOCdevkit', 'VOC2012'))
num_workers = d2l.get_dataloader_workers()
train_iter = torch.utils.data.DataLoader(
VOCSegDataset(True, crop_size, voc_dir), batch_size,
shuffle=True, drop_last=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(
VOCSegDataset(False, crop_size, voc_dir), batch_size,
drop_last=True, num_workers=num_workers)
return train_iter, test_iter版权声明
本文为[Whisper_ yl]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230453143607.html
边栏推荐
- Special topic of data intensive application system design
- Pixel mobile phone brick rescue tutorial
- vscode ipynb文件没有代码高亮和代码补全解决方法
- Knowledge points sorting: ES6
- View, modify and delete [database] table
- Learning Android II from scratch - activity
- AQS源码阅读
- The 8 diagrams let you see the execution sequence of async / await and promise step by step
- 和谐宿舍(线性dp / 区间dp)
- 负载均衡简介
猜你喜欢
![[WinUI3]编写一个仿Explorer文件管理器](/img/3e/62794f1939da7f36f7a4e9dbf0aa7a.png)
[WinUI3]编写一个仿Explorer文件管理器
![[2022 ICLR] Pyraformer: Low-Complexity Pyramidal Attention for Long-Range 时空序列建模和预测](/img/7c/51ac43080d9721f1bdc1cd78cd685b.png)
[2022 ICLR] Pyraformer: Low-Complexity Pyramidal Attention for Long-Range 时空序列建模和预测

Flink's important basics

泰克示波器DPO3054自校准SPC失败维修
DIY 一个 Excel 版的子网计算器

Detailed explanation of the differences between TCP and UDP
COM in wine (2) -- basic code analysis
![Solve valueerror: argument must be a deny tensor: 0 - got shape [198602], but wanted [198602, 16]](/img/99/095063b72390adea6250f7b760d78c.png)
Solve valueerror: argument must be a deny tensor: 0 - got shape [198602], but wanted [198602, 16]

拼了!两所A级大学,六所B级大学,纷纷撤销软件工程硕士点!

Record the ThreadPoolExecutor main thread waiting for sub threads
随机推荐
[WinUI3]編寫一個仿Explorer文件管理器
What are the redis data types
Use model load_ state_ Attributeerror appears when dict(): 'STR' object has no attribute 'copy‘
Teach you how to build the ruoyi system by Tencent cloud
Innovative practice of short video content understanding and generation technology in meituan
Unity3D 实用技巧 - 理论知识库(一)
Progress of innovation training (IV)
Record the ThreadPoolExecutor main thread waiting for sub threads
MySQL -- execution process and principle of a statement
JS détermine si la chaîne de nombres contient des caractères
HRegionServer的详解
List remove an element
What's the difference between error and exception
Innovation training (II) task division
Learning Android from scratch -- baseactivity and activitycollector
负载均衡简介
Thoughts on a small program
Progress of innovation training (III)
Download PDF from HowNet (I don't want to use CAJViewer anymore!!!)
C list field sorting contains numbers and characters