当前位置:网站首页>机器学习(二)线性回归
机器学习(二)线性回归
2022-08-11 07:38:00 【ViperL1】
一、简单线性回归
1.原理
原型公式:  为一条直线
为一条直线
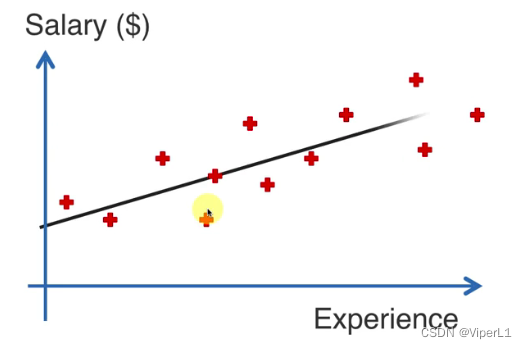
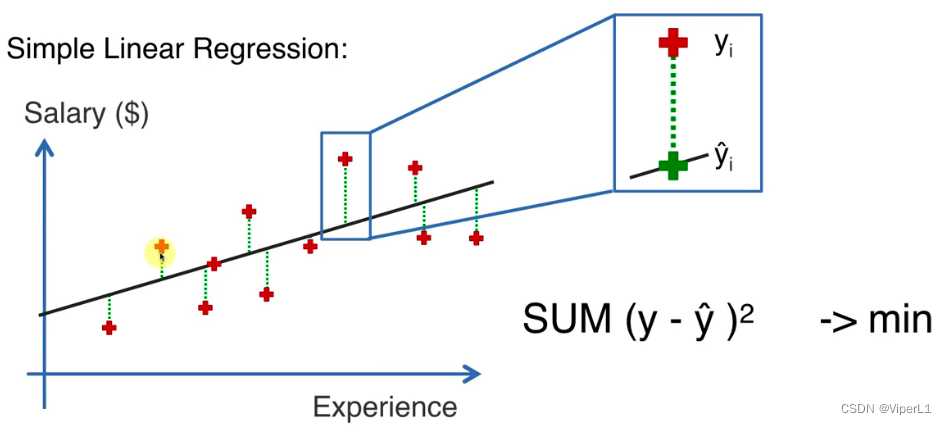
拟合:使误差(垂直差)平方和最小
使用平方和是因为取的是欧氏距离
2.Python中的处理
①设置工作路径
②数据预处理
引入常用库、读入数据(自变量+因变量)、分成训练集和测试集
③创建和使用回归器
from sklearn.liner_model import LinerReggression --导入线性回归类
regressor = LinerRegression() --线性回归对象
regressor.fit(x_train,y_train) --拟合模型
y_pred = regressor.predict(x_test) --预测 参数为自变量矩阵④图像绘制
import matplotlib.pyplot as plt --导入标准绘图库
plt.scatter(x_train,y_train,color = 'red') --绘制点(x轴数据,y轴数据,着色)
plt.plot(x_train,regressor.predict(x_train), color = 'blue') --绘制线
plt.title('测试数据与预测数据对比') --标题
plt.xlable('工作年限') --x轴标签
plt.ylable('薪水') --y轴标签
plt.show() --显示图像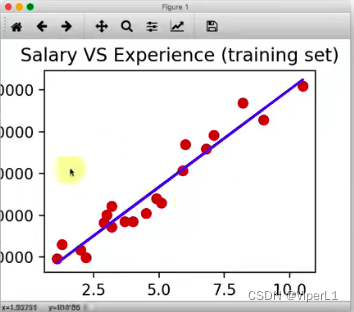
二、多元线性回归
1.原理
原型公式: 多项式
多项式
限定条件: ①数据是线性的
②数据要有同样的方差
③数据要呈现多元正态分布
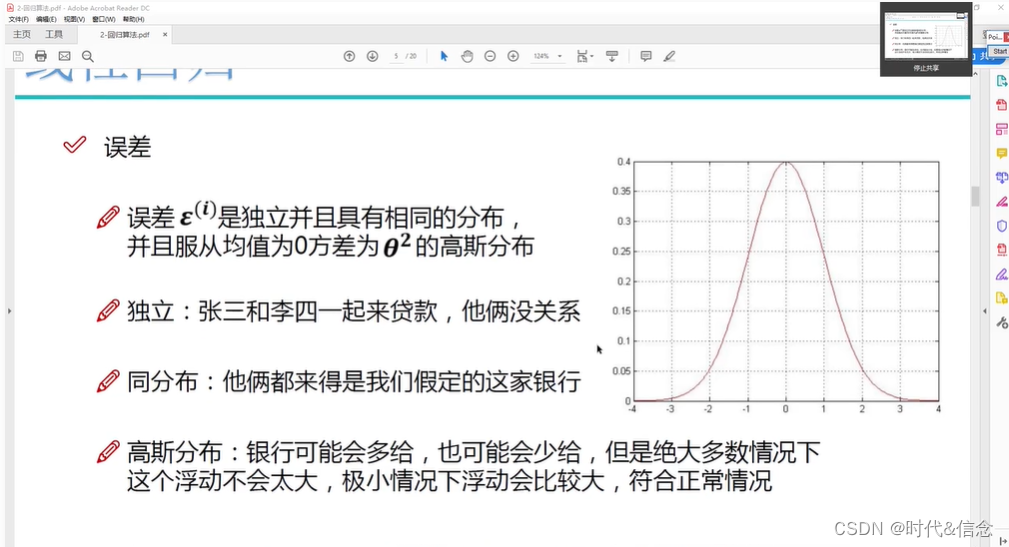
④误差相互独立
⑤无多重共线性(自变量不和其他自变量呈线性关系)
虚拟变量:将标签进行编码

虚拟变量的陷阱:如示例中的情况,纽约州和加州存在互斥关系,其关系可以表达为: ,即两者存在线性关系,不符合 ⑤(无多重共线性)。过多的参数可能造成参数维度溢出,从而造成过度拟合。
,即两者存在线性关系,不符合 ⑤(无多重共线性)。过多的参数可能造成参数维度溢出,从而造成过度拟合。
为解决此问题,进行拟合时,必须省略掉编码组中的一组数据。
2.建立多元线性回归模型
①All-in:将所有数据应用在模型之中
②反向淘汰:
step1:定义自变量对模型影响力的门槛
step2:使用All-in对模型进行拟合
step3:使用自变量计算P值(影响力);若此自变量大于门槛值,则执行step4;否则算法终止
step4:移除P值最高的自变量
step5:循环step3->step5,直至所有P值小于门槛值
③顺向选择:
step1:定义自变量对模型影响力的门槛
step2:对每个自变量进行简单线性回归拟合,选取其中P值最低的自变量
step3:将选取的自变量加入模型,再将剩下的自变量加入模型运算,得到其P值;选取其中最低的P值,若其低于门槛值,则将其加入模型。
step4:循环step3->step4,直至所有剩下的自变量的P值大于门槛值
④双向淘汰:
step1:设置两个门槛值
step2:进行顺向选择
step3:进行反向淘汰
step5:循环step2->step3,直至满足两个门槛值
⑤信息量比较:
step1:对所有可能的模型进行打分(N个自变量的模型个数为: )
)
step2:选择打分最高的模型
3.Python处理
①数据预处理
其中标签项需要进行分类数据处理
from sklearn.preprocessing import LabelEncoder,OneHotEncoder --导入库
labelencoder_x=LabelEncoder --编码器对象
x[:,3] = labelencoder_x.fit_transform(x[:,3]) --创建对象
onehotenccoder = OneHotEncoder(categorical_features = [0]) --创建对象
x = onhotencoder.fit_transform(x).toarry() --转换处理虚拟变量陷阱(实际上库里自带此功能)
x = x[:,1:] --去除x的第0列②创建回归器并进行拟合
from sklearn.linear_model import LinearRegression --引入库
regressor = LinearRegression() --创建对象
regressor.fit(x_train,y_train) --拟合
y_pred = regressor.predict(x_test) --预测③统计显著性处理
示例为反向淘汰算法
import statsmodels.formula.api as sm --导入库
x_train = np.append(arr = np.ones(40,1),values = x_train,axis=1)
--添加一列(为常数项b0乘1,作为一个自变量)
--np->numpyx_opt = x_train[:,[0,1,2,3,4,5]] --最佳选项初始化
regressor_OLS = sm.OLS(endog=y_train,exog=x_opt).fit() --因变量,自变量(并进行拟合)
regressor_OLS.summary() --找出最大P值
x_opt = x_train[:,[0,1,3,4,5]] --剔除2
regressor_OLS = sm.OLS(endog=y_train,exog=x_opt).fit()
regressor_OLS.summary()
--反复剔除
边栏推荐
- Do you know the basic process and use case design method of interface testing?
- 1101 B是A的多少倍 (15 分)
- 8、Mip-NeRF
- cdc连sqlserver异常对象可能有无法序列化的字段 有没有大佬看得懂的 帮忙解答一下
- 3.1-分类-概率生成模型
- 线程交替输出(你能想出几种方法)
- 1101 How many times B is A (15 points)
- 关于#sql#的问题:怎么将下面的数据按逗号分隔成多行,以列的形式展示出来
- Evolution and New Choice of Streaming Structured Data Computing Language
- leetcode: 69. Square root of x
猜你喜欢
2022 China Soft Drink Market Insights

年薪40W测试工程师成长之路,你在哪个阶段?
关于#sql#的问题:怎么将下面的数据按逗号分隔成多行,以列的形式展示出来
My creative anniversary丨Thank you for being with you for these 365 days, not forgetting the original intention, and each is wonderful

JRS303-数据校验
1081 Check Password (15 points)
机器学习总结(二)
软件测试常用工具的用途及优缺点比较(详细)
TF中的条件语句;where()

测试用例很难?有手就行
随机推荐
流式结构化数据计算语言的进化与新选择
3.2-分类-Logistic回归
go sqlx 包
Hibernate 的 Session 缓存相关操作
查找最新人员工资和上上次人员工资的变动情况
机器学习总结(二)
2022 China Soft Drink Market Insights
易观分析联合中小银行联盟发布海南数字经济指数,敬请期待!
Two state forms of Service
CSDN21天学习挑战赛——封装(06)
1003 I want to pass (20 points)
零基础SQL教程: 基础查询 05
matplotlib
TF中的条件语句;where()
tf中矩阵乘法
1106 2019 Sequence (15 points)
2022-08-10 mysql/stonedb-slow SQL-Q16-time-consuming tracking
pyqt5实现仪表盘
1.1-Regression
【LeetCode】Summary of linked list problems