当前位置:网站首页>3.1-分类-概率生成模型
3.1-分类-概率生成模型
2022-08-11 06:50:00 【一条大蟒蛇6666】
一、分类(Classification)
- 对于分类这个任务而言,同回归相似,同样是找一个函数 f,他的输入是一个对象 x,输出是一个类别 class n
- 这样的分类任务现实中有很多,比如:
- 信用评分
- 输入:收入,存款,职业,年龄,过去的财务状况
- 输出:接受或拒绝
- 医学诊断
- 输入:目前的症状、年龄、性别、过去的医疗记录
- 输出:哪种疾病
- 手写字符识别
- 输入:手写字符
- 输出:相对应的数字编码字符
- 人脸识别
- 输入:脸的图像
- 输出:与之相对应的人
- 信用评分
1.1 应用示例
- 下面以宝可梦分类为例,每一只宝可梦都可以用7种属性来描述:Total,HP,Attack,Defense,SP Atk,SP Def,Speed。下面我们将根据这些属性来预测一只宝可梦到底属于什么类别。
- 假如我们还没有学习如何采用分类的方法来解这个问题,此时我们通过回归的方法来硬解这个问题,看一看下面会出现什么情况。以二分类的问题为例:
- 如图回归模型会惩罚那些太正确,输出值太大的那些点,这样得到的结果反而是不好的。

- 理想的选择(Ideal Alternatives)
- 定义一个模型g(x),当输入x时,输出大于0就输出class 1,否则输出class 2
- loss函数用来统计在训练集中预测错误的次数
- 寻找最优解的方法有感知机(Perceptron),支持向量机(SVM),生成模型(Generative Model)

生成模型(Generative Model)
- 根据训练集来估测x发生的概率P(x),这就是生成模型。
- 先验概率(Prior):P(C1)和P(C2)是可以根据已有训练集先算出来的
高斯分布(Gaussian distribution):任何一只宝可梦都可以通过它们的一组属性向量来表示,下面我们取Defense,SP Def这两个属性组成的二维向量来表示一只宝可梦。由于测试集里的这只海龟我们无法知道它的先验概率P(x),因此我们假设已有的训练集是从一个高斯分布里采样得到的,那么现在我们就能估测这只海龟的先验概率是多少了。
对于高斯分布而言,它的输入是一个向量x,输出是一个抽样概率Font metrics not found for font: .,其函数的形状由均值𝝁和协方差矩阵𝜮确定








最大似然估计(Maximum Likelihood):由于每个点都是独立从高斯分布中采样出来的,而这79个点是又有可能从不同的高斯分布中采样出来。对不同的高斯分布而言,会有不同的相似度(Different Likelihood)。因此我们需要找到一个相似度Font metrics not found for font: .最高的高斯分布Font metrics not found for font: .
右图是我们实际计算出来的水系和一般系宝可梦的均值𝝁和协方差矩阵𝜮


二、预测
- 右图是我们根据模型在测试集上进行预测得到的准确率,2个参数的准确率为47%,7个参数的准确率为54%,很显然我们的模型效果非常差,需要继续进行优化。


- 修正模型(Modifying Model):比较常见的一个做法是不同的类可以共享同一个协方差矩阵𝜮,这样我们就可以通过减少模型的参数来降低方差(variance),从而得到一个更加简单的模型。其中u1和u2的算法没有变,而𝜮变成了之前𝜮1和𝜮2两者之间的加权平均和。结果从53%提高到了73%



三、总结
- 左图是分类这个任务的三步分析流程,右图是我们采用的概率分布模型不一定要是高斯分布,如果我们遇到一个二分类的问题,可以使用伯努利分布(Bernoulli distributions);如果假设所有维度都是独立的,那么可以使用朴素贝叶斯分类器(Naive Bayes Classifier)。


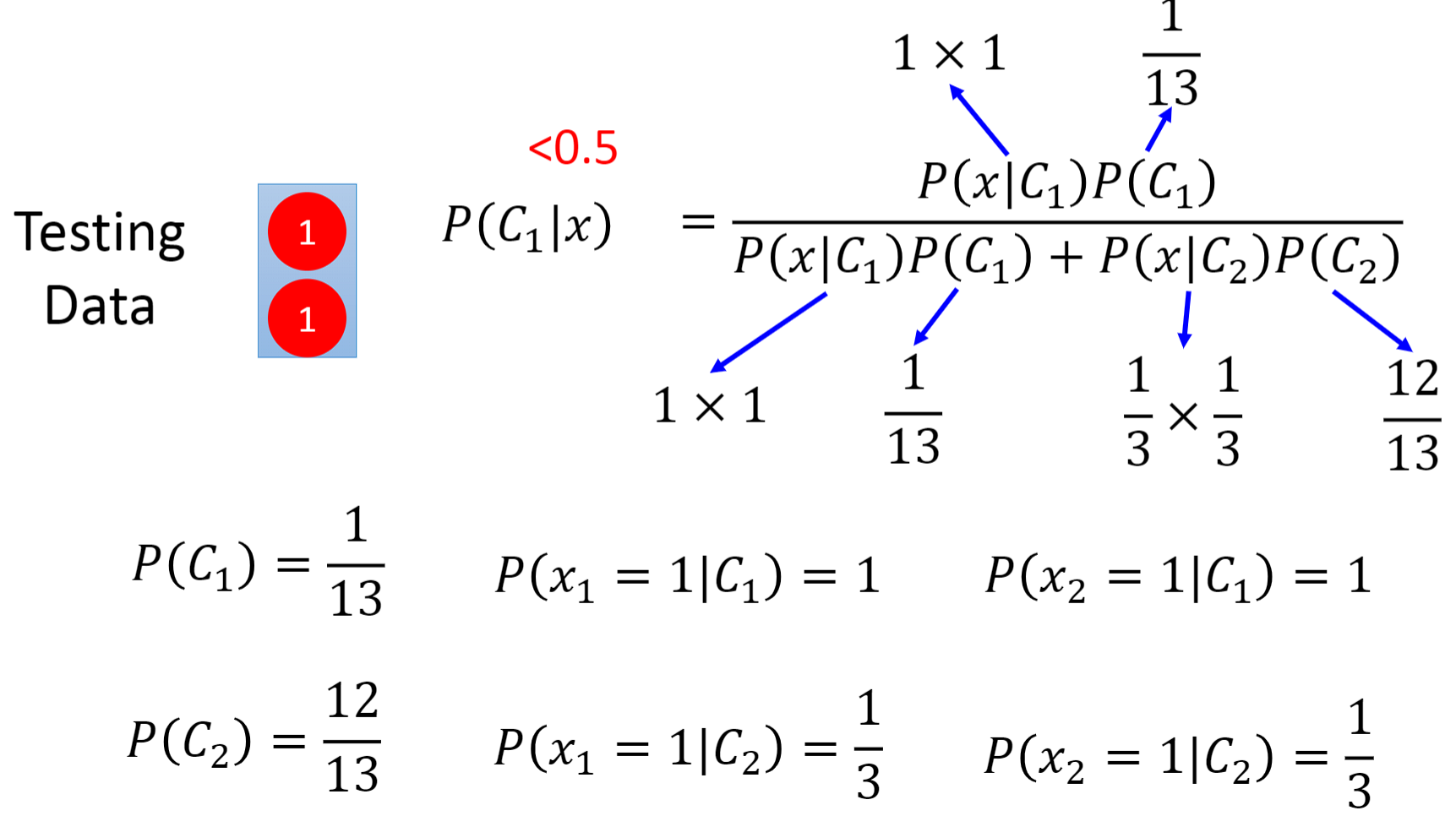
- 后验概率(Posterior Probability):在根据一大堆无聊的数学推导后,我们得到了最终的P(C1|x)的数学表达式。但是为了得到w和b,在生成模型中,我们估计了𝑁1,𝑁2, 𝜇1, 𝜇2, Σ这么多的参数,似乎有点舍近求远,我们为何不从一开始就直接去找w和b呢?下一章的逻辑回归我们会深入探讨这个问题。



边栏推荐
- 2021-08-11 for循环结合多线程异步查询并收集结果
- jar服务导致cpu飙升问题-带解决方法
- 年薪40W测试工程师成长之路,你在哪个阶段?
- Amazon API interface Daquan
- Trill keyword search goods - API
- Douyin share password url API tool
- Depth (relay supervision)
- 微信小程序功能上新(2022.06.01~2022.08.04)
- Redis source code-String: Redis String command, Redis String storage principle, three encoding types of Redis string, Redis String SDS source code analysis, Redis String application scenarios
- 1106 2019数列 (15 分)
猜你喜欢

Redis源码:Redis源码怎么查看、Redis源码查看顺序、Redis外部数据结构到Redis内部数据结构查看源码顺序
【推荐系统】:协同过滤和基于内容过滤概述
3.2-分类-Logistic回归
Tensorflow中使用tf.argmax返回张量沿指定维度最大值的索引

年薪40W测试工程师成长之路,你在哪个阶段?
Implementation of FIR filter based on FPGA (5) - FPGA code implementation of parallel structure FIR filter
1002 写出这个数 (20 分)
tf.reduce_mean()与tf.reduce_sum()

Edge provides label grouping functionality
我的创作纪念日丨感恩这365天来有你相伴,不忘初心,各自精彩
随机推荐
ROS 服务通信理论模型
2022-08-10 Group 4 Self-cultivation class study notes (every day)
Pico neo3 Unity打包设置
break pad源码编译--参考大佬博客的总结
【sdx62】XBL设置共享内存变量,然后内核层获取变量实现
1106 2019数列 (15 分)
Amazon API interface Daquan
opencv实现数据增强(图片+标签)平移,翻转,缩放,旋转
go-grpc TSL认证 解决 transport: authentication handshake failed: x509 certificate relies on ... ...
Redis源码:Redis源码怎么查看、Redis源码查看顺序、Redis外部数据结构到Redis内部数据结构查看源码顺序
1091 N-自守数 (15 分)
结合均线分析k线图的基本知识
TF中的One-hot
unable to extend table xxx by 1024 in tablespace xxxx
【Pytorch】nn.Linear,nn.Conv
【latex异常和错误】Missing $ inserted.<inserted text>You can‘t use \spacefactor in math mode.输出文本要注意特殊字符的转义
Tf中的平方,多次方,开方计算
3.2-分类-Logistic回归
cdc连sqlserver异常对象可能有无法序列化的字段 有没有大佬看得懂的 帮忙解答一下
TF通过feature与label生成(特征,标签)集合,tf.data.Dataset.from_tensor_slices