当前位置:网站首页>文本三剑客——awk 截取+过滤+统计
文本三剑客——awk 截取+过滤+统计
2022-08-11 05:32:00 【欢喜躲在眉梢里】
目录
一、awk是什么?
awk是一种编程及数据操作语言(其名称来自于创始人lfred Aho、Peter Weinberger 和 Brian Kernighan 姓氏的首字母)
(Gawk is the GNU Project's implementation of the AWK programming language.
gawk - pattern scanning and processing language)三个作者首字母的组合。
1、GNU是什么?
GUN is not uninx。
GUN是一个项目,它的宗旨是构建一个不是uninx的操作系统,项目发起人理查德.斯德尔曼。
操作系统:内核+应用程序+库+解析器等。
内核kernel---linux
2、相关命令选项
awk -F ":":表示接分隔符为":"
~/^luo/:模糊查找以/luo/开头的。并且以luo开头的用户名的长度大于1的。
[[email protected] lianxi]# useradd luoziyao
useradd:用户“luoziyao”已存在
[[email protected] lianxi]# awk -F ": " '$1~/^luo/ && length($1>4) {print $1,$3}' /etc/passwd
luoziyao 20213、awk有什么用
过滤+截取+统计
4、awk用在哪里
文本处理(截取和统计)
充值记录:bill.txt
feng 100
feng 200
feng 350
li 200
ma 100000
li 239
li 890
zhang 100
zhang 350
ma 1000
统计每个用户一共充值了多少钱?--》求和,分类统计。
[[email protected] lianxi]# awk '{name[$1]+=$2}END{for (i in name) print i,name[i]}' bill.txt
li 1329
feng 650
zhang 450
ma 101000①name[$1]+=$2 拿$1字段做key,让$2做value,如果数组里有key,就累加,如果没有,初始值是0+value。
②END{for (i in name) print i,name[i]}:END是文件里所有的行都处理完了,最后去执行END部分里的命令。for循环取遍历name数组里的元素(item),i 取name数组里的key,输出key和对应的value。
字段:field --一段文字被分隔符隔开,形成很多段比较短的文字
luoziyao:x:2021:2024::/home/luoziyao:/bin/bash
=====
列: --字段:column
行: row line record
记录:record
一行就是一条记录。
====
二、awk 命令的简要处理流程
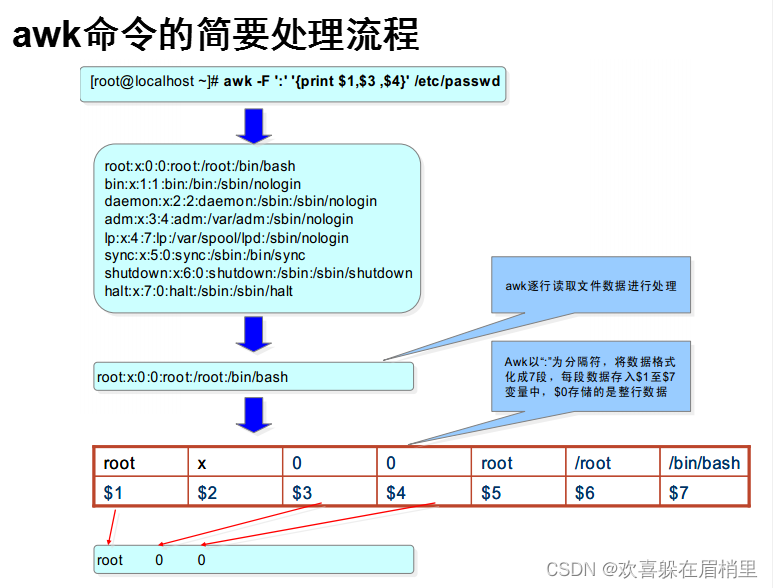
awk -F ":":表示接分隔符":",将数据格式化成几段。
$0表示存储的是整行数据。
[[email protected] lianxi]# awk -F ":" '{print $1,$3,$7}' /etc/passwd1、分隔符
(1)输入分隔符:input field separate
默认是空白(空格和tab键)
awk -F 【分隔符】
awk -FS : 输入分隔符变量
(2)输出分隔符:output field separate
默认是一个空格
OFS=: 输出分隔符变量
比如:OFS="#':表示以"#"进行分隔
例如:
①输出分隔符以逗号隔开为默认。输出结果为空格隔开。
[[email protected] lianxi]# awk -F ":" '{print $1,$3,$7}' /etc/passwd|head
root 0 /bin/bash
bin 1 /sbin/nologin②输出分隔符没有进行分隔,结果输出的也没有没有分隔。
[[email protected] lianxi]# awk -F ":" '{print $1$3$7}' /etc/passwd|head
root0/bin/bash
bin1/sbin/nologin
daemon2/sbin/nologin
adm3/sbin/nologin③ 输出分隔符以空格隔开,输出的结果也没有分开。
[[email protected] lianxi]# awk -F ":" '{print $1 $3 $7}' /etc/passwd|head
root0/bin/bash
bin1/sbin/nologin
daemon2/sbin/nologin④ OFS=:output field separate 指定输出分隔符为"#"。
[[email protected] lianxi]# awk -F ":" 'OFS="#"{print $1,$3,$7}' /etc/passwd|head
root#0#/bin/bash
bin#1#/sbin/nologin三、awk命令的内置变量
| 名称 | 用途 |
| NF | 每行$0的字段数,The number of field in the current input record |
| NR | 当前处理的行号,The total number of input record seen so far |
| FS | 当前的输入分隔符,默认是空白字符(空格和tab),field separate |
| OFS | 当前的输出分隔符,默认是空格字符(空格),output field separate |
$NF:最后一个字段
$(NF-1):倒数第2个字段
扩展:cat -n 、nl:以行号的形式输出。
[[email protected] lianxi]# cat -n /etc/passwd|head
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
.........
[[email protected] lianxi]# nl /etc/passwd|head
1 root:x:0:0:root:/root:/bin/bash
2 bin:x:1:1:bin:/bin:/sbin/nologin
3 daemon:x:2:2:daemon:/sbin:/sbin/nologin
4 adm:x:3:4:adm:/var/adm:/sbin/nologin
........................w:查看连接到你的机器上的有哪些机器。
查看连接到你机器的机器,并且截取出第一个字段。
[[email protected] lianxi]# w|awk '{print $1,$NF}'
14:58:29 0.05
USER WHAT
root -bash
root w四、awk命令的完整语法
1、格式
awk 'BEGINK{commands}pattern{commands}END{commands}' file1

练习:①、截取出/etc/passwd中第三个字段大于500,并且小于1000的那部分内容。
[[email protected] lianxi]# awk -F ":" 'BEGIN{print "####start####"} $3>500&&$3<1000{print $1,$3}END{print "####end####"}' /etc/passwd|head
####start####
polkitd 999
chrony 998
zabbix 997
nginx 996
grafana 995
####end####②、查找/etc/passwd文件中包含feng的内容或者字段3大于1005的,并打印出每行的字段数、行号、第一个字段和第一个字段的长度、倒数第二个字段、第三个字段。
[[email protected] lianxi]# cat /etc/passwd|awk -F: 'BEGIN{num=0;print"开始统计/etc/passwd文件"}$1 ~/feng/ || $3 > 1005 {print NR,NF,$1,length($1),$(NF-1),$NF,$3,num++}END{print "统计结束",num}'③、截取以feng开头的2次以上,并且第三个字段大于2000的,或者最后一个字段是含有bash的,然后打印出行号、每行的字段数,字段1、字段3以及字段1的长度、倒数第二个字段,最后一个字段。
[[email protected] shell]# awk -F: 'BEGIN{num=0;print "start"} $1 ~ /^feng{2,}/ && $3 >2000 || $NF ~ /bash/ {print NR,NF,$1,$3,length($1),$(NF-1),$NF;num++} END{print "行数:"num}' /etc/passwd
1 7 root 0 4 /root /bin/bash
20 7 angel 1000 5 /home/angel /bin/bash
21 7 aj 1001 2 /home/aj /bin/bash
22 7 qiantao 1002 7 /home/qiantao /bin/bash
23 7 yalin 1003 5 /home/yalin /bin/bash
24 7 jj 1004 2 /home/jj /bin/bash
25 7 aojiao 1005 6 /home/aojiao /bin/bash
30 7 sc 1006 2 /home/sc /bin/bash
31 7 sl1 1007 3 /home/sl1 /bin/bash
...........
行数:57④、who的用法:
who命令用于显示系统中有哪些使用者正在上面,显示的资料包含了使用者 ID、使用的终端机、从哪边连上来的、上线时间、呆滞时间、CPU 使用量、动作等等。
[[email protected] lianxi]# who|awk '{print "username:"$1" time:"$3}'
username:root time:2022-07-07
username:root time:2022-07-07
username:root time:2022-07-07
[[email protected] lianxi]# who|awk '{print "username:"$1", uid:"$3}'
username:root, uid:2022-07-07
username:root, uid:2022-07-07
username:root, uid:2022-07-07
[[email protected] lianxi]# who|awk '{print "username:"$1", uid:"$3}' /etc/passwd|head -5
username:root:x:0:0:root:/root:/bin/bash, uid:
username:bin:x:1:1:bin:/bin:/sbin/nologin, uid:
username:daemon:x:2:2:daemon:/sbin:/sbin/nologin, uid:
username:adm:x:3:4:adm:/var/adm:/sbin/nologin, uid:
username:lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin, uid:[[email protected] lianxi]# awk -F: '/bash/{print "username:"$1", uid:"$3}' /etc/passwd|head -5
username:root, uid:0
username:angel, uid:1000
username:aj, uid:1001
username:qiantao, uid:1002
username:yalin, uid:1003
[[email protected] shell]# awk -F: '{print "username:"$1", uid:"$3}' /etc/passwd|head -5
username:root, uid:0
username:bin, uid:1
username:daemon, uid:2
username:adm, uid:3
username:lp, uid:4⑤、截取出每个人所对应的语文和Linux成绩。
[[email protected] shell]# cat grade.txt
id name chinese math english//linux
1 cali 80 80 80//88
2 rose 90 70 90//78
3 tom 70 100 85//22
4 jenny 100 60 90//95
[email protected] shell]# awk -F"[ /]+" '{print $2,$3,$6}' grade.txt
name chinese linux
cali 80 88
rose 90 78
tom 70 22
jenny 100 952、 awk 中 gsub和tr命令的使用
1、gsub:替换
格式:gsub(r,s [, t]): For each substring matching the regular expression r in the string t,substitute,substitue the string s,and return the number of substituions。
练习:将$5对应的字符串里查找“/”字符串,并将其替换成" "空格。
[[email protected] shell]# awk '{gsub("/"," ",$5); print $2,$3,$5}' grade.txt
name chinese englishlinux
cali 80 8088
rose 90 9078
tom 70 8522
jenny 100 90952、 tr命令:字符转换和删除
① tr:translate or delete characters 将字符进行转换和删除。
练习:tr '/' "\t":进行替换,将“/”替换成"\t";"\t";table键
[email protected] shell]# cat grade.txt|tr '/' "\t"
id name chinese math english linux
1 cali 80 80 80 88
2 rose 90 70 90 78
[[email protected]lhost shell]# cat grade.txt|tr '//' "\t"
id name chinese math english linux
1 cali 80 80 80 88
2 rose 90 70 90 78
.........将a替换为8,将b替换为9。
[[email protected] shell]# echo aaaaaabbbbcccc123 |tr ab 89
8888889999cccc123
[[email protected] shell]# echo aaaaaabbbbccccbbbcc123 |tr ab 89
8888889999cccc999cc123②tr -s:替换并去重。
-s :suqeeze -repreats:压缩连续的相同(重复)的字符串为一个字符串。
#将“/”替换为空格并压缩
[[email protected] shell]# cat grade.txt|tr -s "/" " "
id name chinese math english linux
1 cali 80 80 80 88
2 rose 90 70 90 78
3 tom 70 100 85 22
4 jenny 100 60 90 95[[email protected] shell]# cat grade.txt |tr -s "/" " "|awk '{print $2,$3,$NF}'
name chinese linux
cali 80 88
rose 90 78
.........③ tr -d:删除字符串 delete,delete character in SET1 ,do not translate
格式: tr [OPTION.....SET1 [SET2]
SET1和SET2字符串一一对应替换
练习:①删除”%“的那一列。
[[email protected] shell]# df|tr -d "%" #删除”%“的那一列
文件系统 1K-块 已用 可用 已用 挂载点
/dev/mapper/centos-root 17811456 7714488 10096968 44 /
devtmpfs 485780 0 485780 0 /dev
tmpfs 497948 0 497948 0 /dev/shm五、awk命令的操作符

1、awk中的操作符
~:模糊匹配
~/ /:模糊匹配
//里面写查找的内容
~ /\<luoziyao$\>/:其中$表示以什么结束。
[[email protected] shell]# awk -F: '$1 ~ /\<luoziyao$\>/{print $1,$3}' /etc/passwd
luoziyao 2021其中NR==1表示第一行。
[[email protected] shell]# awk 'NR==1{print NR,$0}END{print NR,$0}' /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
88 luoziyao1:x:2022:2025::/home/luoziyao1:/bin/bashn, --interval seconds: 指定间隔时间。Specify update interval. The command will not allow
-d, --differences [permanent]:以高亮显示。Highlight the differences between successive update
[[email protected] shell]# watch -n 2 -d "ifconfig|awk 'NR==5{print $5}'"
watch -n 2 -d " ifconfig |egrep -A8 "^ens33"|awk '/RX p/||/TX p/{print \$5}'"2、shell里的变量在awk里传递参数的问题
①echo $$:查看当前进程(bash)的进程号。
[[email protected] ~]# echo $$
7894②PROCINFO:是awk的内置数组,用来存储进程的相关信息。
[email protected] ~]# awk '{print PROCINFO["pid"],PROCINFO["ppid"]}' /etc/passwd
10940 10923
10940 10923
10940 10923③在shell中引用变量。
\$1:需要进行转义,在awk中,引用shell变量时不需要进行转义,需要加$符号:$s来引用变量,但是位置变量需要进行转义:如:\$1.
[[email protected] ~]# sg=renhaodong
[[email protected] ~]# awk -F: "/$sg/{print \$1}" /etc/passwd
renhaodong④流控:following control。
if:if(condition )statement
单分支:
[[email protected] ~]# awk -F: '{if($1 ~ /renhaodong/) print "haoge"}' /etc/passwd
haoge
[[email protected] ~]# awk -F: '{if($1 ~ /renhaodong/) print "haoge";else print "dage"}' /etc/passwd
dage
dage
dage
dage多分支:
[email protected] ~]# awk -F: '{if($1 ~ /renhaodong/) print "haoge";else if($3>5000)print "dageda"; print "dage"}' /etc/passwd
dage
dage
dage
dage小练习:①、将/etc/passwd下uid=0为超级用户,大于1并且小于等于999的为系统用户,大于1000的为普通用户。
[[email protected] ~]# awk -F: '{if($3==0) print "超级用户";else if($3>1&&$3<100)print " 系统用户"; print "普通用户"}' /etc/passwd
超级用户
系统用户
系统用户
系统用户
系统用户
系统用户
系统用户②、简单版:
[[email protected] ~]# awk -F: 'BEGIN {num=0;num2=0;num3=0}{if($3==0)num++;else if ($3>1&&$3<1000)num2++;else num3++}END{print "超级用户的数量:"num",系统用户的数量:"num2",普通.户的数量:"num3""}' /etc/passwd
超级用户的数量:1,系统用户的数量:26,普通用户的数量:62
[[email protected] ~]# awk -F: '{if($3==0)num++;else if ($3>1&&$3<1000)num2++;else num3++}END{print "超级用户的数量:"num",系统用户的数量:"num2",普通用户的数量:"num3""}' /etc/passwd
超级用户的数量:1,系统用户的数量:25,普通用户的数量:63
[[email protected] ~]# awk -F: '{if($3==0){num++;print $3,$1"是超级用户"}else if ($3>1&&$3<1000)num2++;else num3++}END{print "超级用户的数量:"num",系统用户的数量:"num2",普通用户 的数量:"nm3""}' /etc/passwd
0 root是超级用户
超级用户的数量:1,系统用户的数量:25,普通用户的数量:63升级版:
[[email protected] ~]# awk -F: 'BEGIN{num1=0;num2=0;num3=0}{if ($3 == 0) {num1++;print "超级用户"}else if ($3>=1&&$3<=999) {num2++;print "系统用户"}else {num3++;print "普通用户"}}END{print "一共有超级用 户:"num1,"一共有系统用户:"num2,"一共 普通用户:"num3}' /etc/passwd
普通用户
普通用户
普通用户
普通用户
普通用户
普通用户
......
一共有超级用户:1 一共有系统用户:26 一共 普通用户:623、awk的for循环格式
for (i=0;i<10;i++) {print $i;}
for (i in array) {print array[i]} --->直接从数组的下标里读一个值,取完所有的值,遍历。
python里字典 key:value
练习:
[[email protected] ~]# awk -F: '{split($6,home_dir,"/")}END{for (i in home_dir)print i,home[i]}' /etc/passwd
1
2
3
[[email protected] ~]# awk -F: '{split($6,home_dir,"/")}END{for (i in home_dir)print i,home_dir[i]}' /etc/passwd
1
2 home
3 renhaodong
[[email protected] ~]# awk -F: '{split($6,home_dir,"/");for (i=2;i<4;i++) print i,home_dir[i]}' /etc/passwd
2 root
3
2 bin
3
2 sbin
....
[[email protected] ~]# awk -F: '{split($6,home_dir,"/");for (i in home_dir) print i,home_dir[i]}' /etc/passwd
1
2 root
1
2 bin
1
......4、 awk中的函数
①length:统计长度
[[email protected] ~]# awk -F: 'length($1) >6 {print $1}' /etc/passwd|head②split:将一段字符串根据根据分隔符号,对文本进行分割,存放到数组里,使用for循环取遍历读取数组里的内容。
[[email protected] ~]# awk -F: '{ if (length($1) >6) print substr($1,3,6)}' /etc/passwd|head
utdown
erator
stemd-
[[email protected] ~]# python
Python 2.7.5 (default, Nov 16 2020, 22:23:17)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> sg = "wangshuai wangzixiang mahaoliang tanghaoming zengkaijie"
>>> sgs = sg.split()
>>> sgs
['wangshuai', 'wangzixiang', 'mahaoliang', 'tanghaoming', 'zengkaijie']
>>> mn = "aojiao/xieshan/tanxue/shiyuqian/chenyulin/luo"
>>> mns = mn.split("/")
>>> mns
['aojiao', 'xieshan', 'tanxue', 'shiyuqian', 'chenyulin', 'luo']③gsub:替换
substr: 截取部分字符串
例如:截取$1中长度大于6的。
[[email protected] ~]# awk -F: '{ if (length($1) >6 ) print $1}' /etc/passwd |head
shutdown
operator
systemd-network
..........
[[email protected] ~]# awk -F: '{ if (length($1) >6 ) print substr($1,1)}' /etc/passwd |head
shutdown
operator
systemd-network
........
如果$1的长度大于6,从第一个开始截取6个
[[email protected] ~]# awk -F: '{ if (length($1) >6) print substr($1,1,6)}' /etc/passwd|head
shutdo
operat
system
polkit
postfi
.......④ toupper:转换成大写
[[email protected] ~]# awk -F: '{print toupper($1)}' /etc/passwd
ROOT
BIN
DAEMON
ADM
LP
SYNC
SHUTDOWN⑤ tolower:转换成小写
[[email protected] ~]# awk -F: '{print tolower($1)}' /etc/passwd5、awk中的单个创建
①、创建用户:useradd
[[email protected] shell]# awk '{system("useradd " $1)}' name.txt
useradd:用户“yuanrundong”已存在
useradd:用户“hepang”已存在
useradd:用户“shiyuqian”已存在
useradd:用户“tanxue”已存在②、根据一个文件里的内容,批量新建用户和设置密码
第一种:awk指令进行创建。
[[email protected] shell]# awk '{system ("useradd "$2);system("echo "$3"|passwd "$3" --stdin")}' nameadd.txt
useradd:用户“yuanrundong1”已存在
passwd:未知的用户名 11232dbs。
useradd:用户“hepang”已存在
passwd:未知的用户名 234ndf。
useradd:用户“shiyuqian”已存在第二种:写脚本进行创建。
[[email protected] shell]# cat nameadd1.txt
#!/bin/bash
username=($(awk '{print $2}' nameadd.txt))
userpwd=($(awk '{print $3}' nameadd.txt))
for i in $(seq $(cat nameadd.txt|wc -l))
do
useradd ${username[i-1]}
echo ${userpwd[i-1]}|passwd ${username[i-1]} --stdin
done
[[email protected] shell]# bash nameadd1.txt
useradd:用户“yuanrundong1”已存在
更改用户 yuanrundong1 的密码 。
passwd:所有的身份验证令牌已经成功更新。
useradd:用户“hepang”已存在
更改用户 hepang 的密码 。
passwd:所有的身份验证令牌已经成功更新。
useradd:用户“shiyuqian”已存在
更改用户 shiyuqian 的密码 。
passwd:所有的身份验证令牌已经成功更新。第三种:使用for循环进行创建。
[[email protected] shell]# cat name.txt
yuanrundong1 123456
hepang 123456
shiyuqian 123456
tanxue1 123456
[[email protected] shell]# cat nameadd2.txt
#!/bin/bash
while read user pwd
do
useradd $user
echo $pwd|passwd $user --stdin
done < name.txt
[[email protected] shell]# bash nameadd2.txt
useradd:用户“yuanrundong1”已存在
更改用户 yuanrundong1 的密码 。
passwd:所有的身份验证令牌已经成功更新。
useradd:用户“hepang”已存在
更改用户 hepang 的密码 。
passwd:所有的身份验证令牌已经成功更新。
useradd:用户“shiyuqian”已存在
更改用户 shiyuqian 的密码 。
passwd:所有的身份验证令牌已经成功更新。
useradd:用户“tanxue1”已存在
更改用户 tanxue1 的密码 。
passwd:所有的身份验证令牌已经成功更新。
6、awk中的数组
awk里的数组下标从1开始。求和、统计。

(1)分类 + 累加求和
[[email protected] shell]# cat ip.txt
172.16.130.26 16274.7
172.16.20.126 8783.61
172.16.130.33 5876.59
173.16.13.145 5389.23
172.16.13.145 5389.23
172.16.13.145 5389.23
172.16.20.126 8783.61
..........
[[email protected] shell]# awk '{ip[$1]+=$2}END{for (i in ip) print i,ip[i]}' ip.txt
173.16.13.145 21556.9
172.16.130.33 5876.59
172.16.13.145 16167.7
172.16.20.126 17567.2
172.16.130.26 16274.7
172.16.145.173 4974.36将求和的结果进行排序。
[[email protected] shell]# awk '{ip[$1]+=$2}END{for (i in ip) print i,ip[i]}' ip.txt |sort -k2 -nr
173.16.13.145 21556.9
172.16.20.126 17567.2
172.16.130.26 16274.7
172.16.13.145 16167.7
172.16.130.33 5876.59
172.16.145.173 4974.36(2)统计:门票统计
[[email protected] shell]# cat bill.txt
feng 100
feng 200
feng 350
li 200
ma 100000
li 239
li 890
zhang 100
zhang 350
ma 100000
[[email protected] shell]# awk '{bill[$1]+=$2}END{for (i in bill) print i,bill[i]}' bill.txt|sort -k2 -nr
ma 200000
li 1329
feng 650
zhang 450
=====①统计各个省份的票数,输出省份和总票数,按照降序排列
将省份作为key,将票数作为value.
a[$1]:数组
[[email protected] awk]# cat a.txt
山东 aa 2
河南 bb 3
江西 cc 3
湖南 aa 40
山东 bb 10
江西 dd 6
河南 cc 3
湖南 cc 3
[[email protected] shell]# awk '{a[$1]+=$3}END{for (i in a) print i,a[i]}' a.txt|sort -k2 -nr
湖南 43
山东 12
江西 9
河南 6②已知道一台服务器netstat -anpult输出格式如下:
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN 7404/mysqld
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN 6086/rpcbind
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 7122/sshd
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 7486/master
tcp 0 0 192.168.119.152:22 192.168.119.1:50031 ESTABLISHED 7889/sshd: [email protected]
tcp 0 36 192.168.119.152:22 192.168.119.1:56723 ESTABLISHED 9067/sshd: [email protected]
tcp 0 0 192.168.119.152:22 192.168.119.1:57028 ESTABLISHED 9181/sshd: [email protected]
tcp 0 0 192.168.119.152:22 192.168.119.1:50986 ESTABLISHED 8144/sshd: [email protected]
tcp6 0 0 :::111 :::* LISTEN 6086/rpcbind
统计每个state的数量。
[[email protected] shell]# awk 'NR>1{iptest[$6]+=1}END{for (i in iptest) print i,iptest[i]}' iptest.txt|sort -k2
TIME_WAIT 6
ESTABLISHED 6
LISTEN 4统计输出连接到本机连接数量最多的3个IP,并按连接数从多到少排序(降序)
NR>1:表示从第二行开始。
[[email protected] shell]# awk 'NR>1{if ($6~/ESTABLISHED/)iptest[$5]+=1}END{for (i in iptest) print i,iptest[i]}' iptest.txt|sort -k2 -nr
172.16.17.83:5921 2
172.16.10.25:5921 2
127.0.0.1:35422 2边栏推荐
- mysql 中登录报错:ERROR 1045 (28000): Access denied for user ‘root‘@‘localhost‘ (using password: YES)ERROR
- 【LeetCode-205】同构字符串
- VirtualAPK初探
- Unity的程序集Assembly 与 加快代码编译速度
- 无胁科技-TVD每日漏洞情报-2022-7-30
- Lua 元表(Metatable)
- 项目笔记——随机2
- 无胁科技-TVD每日漏洞情报-2022-7-28
- Error in render: “TypeError: Cannot read properties of undefined (reading ‘commentsContent‘)“
- 企业怎样申请SSL证书?
猜你喜欢




随机推荐
Apache APISIX 默认密钥漏洞复现
轻松理解进程与线程
不同类型SSL证书怎么选?
处理eking.Devos勒索病毒防范解密恢复操作攻略
Vulnhub靶机--born2root
无胁科技-TVD每日漏洞情报-2022-7-27
【LeetCode-350】两个数组的交集II
【LeetCode-389】找不同
BaseActvity的抽取
【LeetCode-349】两个数组的交集
【Unity】关于一个炮台Prefab的剖析
【LeetCode-73】矩阵置零
C# 基础之字典——Dictionary(二)
无胁科技-TVD每日漏洞情报-2022-8-4
GoAhead Server 环境变量注入(CVE-2021-42342)漏洞复现
Redis学习笔记【一】
Unity的程序集Assembly 与 加快代码编译速度
2022年全国职业技能大赛网络安全竞赛试题B模块自己解析思路(2)
C-动态内存管理
2022年全国职业技能大赛网络安全竞赛试题B模块自己解析思路(7)