当前位置:网站首页>LN论文、五种归一化原理和实现
LN论文、五种归一化原理和实现
2022-08-09 04:35:00 【likeGhee】
文章目录
LN论文导读
BN优点:批归一化(BN)技巧是基于batch的训练样本的均值和方差对mini_batch输入进行归一化,能在前馈神经网络(FNN)中显著降低训练时间
BN缺点:批归一化依赖于batch大小,RNN中时间步骤是不确定的,通过训练,我可以确定下第1层或前几层的样本分布,但RNN可能会有N长度的时间片,出现测试样本长度大于训练的所有样本长度情况,往往长序列样本较少,越往后时间片BN越不好学习,计算的μ和σ就会非常不具有代表性
BN和LN不同点:BN训练和测试的行为表现是不一样,训练时BN用指数滑动平均(Weighted Moving Average)的方式不断地积累均值和方差(统计变量:moving average和moving variance),测试的时候使用最后一次采集得到滑动均值和方差作为归一化的统计量
而LN训练和测试行为表现是一样的,LN对单个样本的均值方差归一化,在循环神经网络中每个时间步骤可以看作是一层,LN可以单独在一个时间点做归一化,因此LN可以用在循环神经网络中
BN和LN相同点:LN和BN一样,LN也在归一化之后用了自适应的仿射变换(bias和gain)
内部协变问题:训练网络时候分布一直发生变化
BN公式:权重系数gain,统计变量均值μ和标准差σ,计算新的α_
一般样本集过大,公式确切的计算整个训练集不太现实,因此用经验估计μ和σ(指数滑动平均),batch越少误差越大
LN公式:对同一层的所有神经元做平均,假设这一层的神经元个数为H,对每个神经元α求和再平均,得到第L层所有神经元的均值,标准差也是一样的,对同一层的所有神经元计算公式σ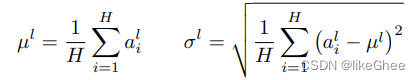
这样H个数是确定的,而BN的seqLen可能是不确定的
所有神经元共享同一套归一化参数,但是每个样本有各自的归一化参数
不同于批归一化,与mini_batch无关,只与神经元的个数有关,
共享参数是gain和bias
RNN中使用LN:re-center加一个偏置,re-scales乘一个系数
LN论文地址
https://arxiv.org/pdf/1607.06450.pdf
五种归一化
Batch Normalization及实现
BN是per channel across mini_batch,通过batch保持channel维度
[NLC] -> [C]
[NCHW] -> [C]
看一下pytorch官网的batchNorm1D作为例子,输入是x=[N,C,L],batchNorm2D输入是[N,C,H,W]
torch.nn.BatchNorm1d类torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True, device=None, dtype=None)
num_features,表示输入张量的特征维度(embedding大小)
eps用于分母的数值稳定,防止分母为0
momentum,用于计算滑动平均和滑动方差,对于累积移动平均值(即简单平均值),可以设置为“None”,默认为0.1
affine,为True时做仿射变换(gain和bias)
track_running_stats为False时,不会记录历史的移动平均值
公式: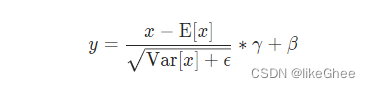
均值和标准差都是通过整个mini_batch对每个维度单独计算的,可学习向量是gama和β,标准差使用的是有偏估计(1/n), 训练过程中会不断的记录历史的均值和方差,使用0.1的momentum做一个移动的估计,当我们训练结束之后用最后一个时刻的估计量做inference
调用API,传入emb_dim,为了方便验证关闭affine,传入的input的格式是[N,C,L],输出格式也是[N,C,L],我们习惯[N,L,C],我们就转置一下
之后我们自己实现BN,使用torch.mean计算平均值,我们需要从batch维度和时间这个维度求通道的均值,所以dim=(0,1),同时用torch.std注意是unbiased=False,是有偏估计
import torch
batch_size, time_steps, emb_dim = 2, 3, 4
input_x = torch.randn([batch_size, time_steps, emb_dim]) # [N,L,C]
eps = 1e-5
# 调用官方的nn.BatchNorm1d
batch_norm_op = torch.nn.BatchNorm1d(emb_dim, affine=False)
bn_y_op = batch_norm_op(input_x.transpose(-1, -2)).transpose(-1, -2)
print(bn_y_op)
# 手写实现BN,per channel norm
def my_batch_norm(inputx):
bn_mean = inputx.mean(dim=(0, 1), keepdim=True)
bn_std = inputx.std(dim=(0, 1), unbiased=False, keepdim=True)
verify_bn_y = (inputx - bn_mean)/(bn_std + eps)
return verify_bn_y
print(my_batch_norm(input_x))
Layer Normalization及实现
LN是per sample和per layer,保持sample和layer维度
[NLC] -> [NL]
[NCHW] -> [N, H, W]
有区别与BN,LN不考虑mini_batch维度,所以计算mean和var仅在dim维度,在RNN中,我们对每一个时刻每个单一样本的emb_dim计算均值和方差
我们来看官网的LN的APItorch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None)
normalized_shape,input shape from an expected input of size,通常传入emb_dim大小,可以理解为每次求平均和方差的公式中H大小=emb_dim大小,即神经元个数
elementwise_affine,是否做仿射变换
同样的使用x=[N,L,C],因为API不要求[N,C,L]格式,我们就不用转置了,这里的均值的标准差是在最后一个维度C去计算的,dim=-1
基于以上分析,我们手写实现一下LN
import torch
batch_size, time_steps, emb_dim = 2, 3, 4
input_x = torch.randn([batch_size, time_steps, emb_dim]) # [N,L,C]
eps = 1e-5
# 调用官方的API
layer_norm_op = torch.nn.LayerNorm(emb_dim, elementwise_affine=False)
ln_y_op = layer_norm_op(input_x)
print(ln_y_op)
def my_layer_norm(inputx):
mean = inputx.mean(dim=-1, keepdim=True)
std = inputx.std(dim=-1, unbiased=False, keepdim=True)
return (inputx - mean)/(std + eps)
print(my_layer_norm(input_x))
Instance normalization及实现
IN是per sample和per channel,保持sample和channel维度
[N,L,C] -> [N,C]
[N,C,H,W]->[N,C]
实例归一化,一般用在风格迁移上,即计算均值和标准差的时候对每个样本的每个维度单独计算均值和标准差,当x=[N,L,C]时即计算dim=[1]维度
官网APItorch.nn.InstanceNorm1d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False, device=None, dtype=None)
num_features,传入dim维度
affine,一般情况下为False,不需要再加上gamma和bias这两个仿射变换
输入x可以是[N,C,L]或者[C,L],我们的x一般是[N,L,C],因为我们要转置一下,和BN用法类似
我们手写实现IN,per sample per channel,计算dim=[1]维度即可,同样的标准差是有偏估计
import torch
batch_size, time_steps, emb_dim = 2, 3, 4
input_x = torch.randn([batch_size, time_steps, emb_dim]) # [N,L,C]
eps = 1e-5
# 调用官方的API
instance_norm_op = torch.nn.InstanceNorm1d(emb_dim, affine=False)
in_y_op = instance_norm_op(input_x.transpose(-1, -2)).transpose(-1, -2)
print(in_y_op)
def my_instance_norm(inputx):
in_mean = inputx.mean(dim=[1], keepdim=True)
in_std = inputx.std(dim=[1], unbiased=False, keepdim=True)
return (inputx - in_mean) / (in_std + eps)
print(my_instance_norm(input_x))
为什么IN能实现风格迁移,输入是[N,L,C],我们对dim=1求均值和标准差,相当于当前这个单一样本在所有时刻不变的东西,我们减去均值再除以标准差,相当于我们把这个单一的时序样本在所有时刻中都有的东西消去了,什么东西是这个样本在所有时刻都有的呢,就是这个样本(图片)的风格,如果是音频,那就是这个人的说话的身份是不变
Group normalization及实现
GN是per sample,per group
[N,G,L,C//G] -> [N, G]
[N,G,C//G,H,W] -> [N,G]
我们对channel划分成group,group的计算和LayerNorm一致,类似群卷积中的做法,将input_tensor划分成不同的group,对每个group计算均值和方差
官网APItorch.nn.GroupNorm(num_groups, num_channels, eps=1e-05, affine=True, device=None, dtype=None)
num_groups,group数目,比如channel是4,那么我们可以划分成两个group
num_channels,传入x的通道数
输入x.shape = (N,C,∗),因此我们需要转置一下
自己实现GN,第一步,我们需要在通道这个维度给x划分成num_groups组,使用torch.split函数
torch.split(tensor, split_size_or_sections, dim=0)
split_size_or_sections,每一组的大小,因此是参数
=num_channels//num_groups
随后遍历split列表,对每个group求mean和std
最后将列表用torch.cat拼接回来
import torch
batch_size, time_steps, emb_dim = 2, 3, 4
input_x = torch.randn([batch_size, time_steps, emb_dim]) # [N,L,C]
eps = 1e-5
# 调用官方的API
group_norm_op = torch.nn.GroupNorm(num_groups=2, num_channels=emb_dim, affine=False)
gn_y_op = group_norm_op(input_x.transpose(-1, -2)).transpose(-1, -2)
print(gn_y_op)
def my_group_normalization(num_groups, num_channels, inputx):
# 将inputx的最后一维切分成num_groups份
group_inputx = torch.split(inputx, num_channels // num_groups, dim=-1)
results = []
for g_inputx in group_inputx:
# 求的是整个group的mean,所以考虑空间维度和通道维度
group_mean = g_inputx.mean(dim=[1, 2], keepdim=True)
group_std = g_inputx.std(dim=[1, 2], keepdim=True, unbiased=False)
gn = (g_inputx - group_mean) / (group_std + eps)
results.append(gn)
# 最后一维度拼接回来
return torch.cat(results, dim=-1)
print(my_group_normalization(2, emb_dim, input_x))
Weight normalization及实现
对权重做一个归一化,将权重的幅度和方向解耦
官网APItorch.nn.utils.weight_norm(module, name='weight', dim=0)
参数是module,传入module,返回module
dim=0是指权重的维度,默认0就好
公式:向量v除以它的模,得到单位的方向向量,再乘以一个新的gama,gama是可学习的
那么我们使用weight_norm,需要先定义一层Module,用Linear层实验
module.weight_g是幅度g,是随机初始化的,我们直接拿来用
import torch
import torch.nn as nn
emb_dim = 4
input_x = torch.randn([2, 3, emb_dim])
# linear层:x @ w^T,x每行和w每列相乘
linear = nn.Linear(emb_dim, 3, bias=False)
weight_norm_linear = torch.nn.utils.weight_norm(linear)
wn_linear_output = weight_norm_linear(input_x)
print(wn_linear_output)
# 手写实现weight_norm,这里dim=1,是和每个sample内积的那个维度,即每一列
weight_direction = linear.weight / linear.weight.norm(dim=1, keepdim=True)
weight_magnitude = linear.weight_g
print(weight_direction.shape)
print(weight_magnitude.shape)
# 用到了点乘广播机制,自动填充到相同维度进行相点乘
my_weight = weight_magnitude * weight_direction
print(input_x @ my_weight.transpose(-1, -2))
边栏推荐
- 抖音直播间带货最新玩法和运营技巧
- I.MX6U-ALPHA开发板(高精度定时器)
- 松柏集(江风起)
- ABP中的数据过滤器
- 单根k线图知识别以为自己都懂了
- "IP" command to configure network interface
- 松柏集(云衣裳)
- Ali YunTianChi competition problem (machine learning) - ali cloud security malware detection (complete code)
- AttributeError: partially initialized module 'cv2' has no attribute 'gapi_wip_gst_GStreamerPipeline'
- TASSEL软件导入plink格式文件报错
猜你喜欢

gopacket usage example

LeetCode - remove consecutive nodes with a sum of zero from a linked list

The influence law of genes for disease - read the paper

Talking about the process and how to create it

人类微生物组和缺失遗传力--读论文

助力To B业务,这类企业端数据值得风控童鞋关注

笔记本电脑重装系统后开机蓝屏要怎么办

337. Robbery III

ceph create pool, map, delete exercises

2022年低压电工练习题及模拟考试
随机推荐
Poly1CrossEntropyLoss的pytorch实现
杰理之采用mix out eq 没有作用【篇】
[Server data recovery] A case of data recovery when the Ext4 file system cannot be mounted and an error is reported after fsck
杰理之播歌曲前后音量大小不一样【篇】
npm package.json
【数学】点积与叉积
岭回归和LASSO回归
Alibaba Cloud Tianchi Contest Question (Machine Learning) - Repeat Purchase Prediction of Tmall Users (Complete Code)
MKNetworkKit replacing domain name wrong solution
HyperLynx(四)差分传输线模型
Correct use of BaseDexClassLoader
npm package.json
浅谈进程与其创建方式
【每日一题】761. 特殊的二进制序列
阿里云天池大赛赛题(深度学习)——视频增强(完整代码)
人类微生物组和缺失遗传力--读论文
JVM垃圾回收机制简介
助力To B业务,这类企业端数据值得风控童鞋关注
软件质效领航者 | 优秀案例•国金证券DevOps建设项目
Talking about the process and how to create it