当前位置:网站首页>【语义分割】2019-CCNet ICCV
【语义分割】2019-CCNet ICCV
2022-08-06 03:58:00 【說詤榢】
【语义分割】2019-CCNet ICCV
论文题目:CCNet: Criss-Cross Attention for Semantic Segmentation
1. 简介
1.1 简介
存在的问题:Non-local也说了它自己存在的问题,就是十分吃显存,于是呢,有了问题,就要解决:
上下文信息对于语义分割和目标检测任务都很重要,这里提出CCNet。对于每个像素,criss-cross attention模块能获得其交叉路径上所有像素的上下文信息,通过进一步的递归操作,每个像素最终可以捕获全图像的依赖关系。此外,提出类别一致损失使得criss-cross attention模块生成更具判别性的特征。
CCNet有以下优点:
(1)GPU显存友好,比non-local block少11倍显存消耗
(2)高计算效率,比non-local block少85%
(3)最先进性能,Cityscapes可达81.9%
2. 网络
2.1 整体架构
CCNet网络结构如下图所示,
- CNN表示特征提取器(backbone),
- Reduction减少特征图的通道数以减少后续计算量,
- Criss-Cross Attention用来建立不同位置像素间的联系从而丰富其语义信息,
- R表示Criss-Cross Attention Module的循环次数,注意多个Criss-Cross Attention Module共享参数。

上面是文章提出的CCNet结构。
- 输入图像经过深度卷积神经网络(DCNN)传递,生成特征图X。
- 获得特征图X之后,首先应用卷积层以获得降维的特征图 H H H,
- 然后将特征图 H H H放入
十字交叉注意力模块(CCA)模块并生成新的特征图 H ′ H^\prime H′,这些特征图 H ′ H^\prime H′汇聚长距离的上下文信息并且每个像素以十字交叉的方式进行同步。
特征图 H ′ H^\prime H′
仅在水平和垂直方向上聚合上下文信息,这对于语义分割而言还不够。为了获得更丰富和更密集的上下文信息,我们将特征图 H ′ H^\prime H′再次输入到交叉注意模块中,然后输出特征图 H ′ ′ H^{\prime\prime} H′′。
因此,特征图 H ′ ′ H^{\prime\prime} H′′中的每个位置实际上收集了来自所有像素的信息。
前后两个纵横交错的注意模块共享相同的参数,以避免添加过多的额外参数。
此递归结构命名为递归纵横交叉注意(RCCA)模块。
将密集的上下文特征 H ′ ′ H^{\prime\prime} H′′与特征图 X X X通过Concat操作堆叠起来。
紧接着是一层或数个具有批量归一化和激活以进行特征融合的卷积层。 最后,将融合的特征输入进分割层以生成最终的分割图。
2.2 CCA模块(Criss-Cross Attention Module)
- PSPNet中提出PPM结构来捕获上下文信息,在PPM模块中采用不同的kernel size对输入的feature map作池化,然后upsampling到统一的size。在每个池化分支,由于kernel size是固定的,只能对每个pixel都考虑其周围固定大小的上下文信息,显然,不同的pixel需要考虑的上下文信息是不同的,因此说这种方法是非自适应的。
- 为了生成密集的,逐像素的上下文信息,Non-local Networks使用自注意力机制来使得特征图中的任意位置都能感知所有位置的特征信息,从而生成更有效的逐像素特征表达。如图1所示,特征图的每个位置都通过self-adaptively predicted attention maps与其他位置相关联,因此生成更丰富的特征表达。但是,这种方法是时间和空间复杂度都为O((HxW)x(HxW)),H和W代表特征图的宽和高。
由于语义分割中特征图的分辨率都很大,因此这种方法需要消耗巨大的计算复杂度和占用大量的GPU内存。有改进方法吗?
作者发现non-local操作可以被两个连续的criss-cross操作代替,对于每个pixel,一个criss-cross操作只与特征图中(H+W-1)个位置连接,而不是所有位置。这激发了作者提出criss-cross attention module来从水平和竖直方向聚合long-range上下文信息。通过两个连续的criss-cross attention module,使得每个pixel都可以聚合所有pixels的特征信息,并且将时间和空间复杂度由 O ( ( H × W ) × ( H × W ) ) O((H\times W)\times(H\times W)) O((H×W)×(H×W))降低到 O ( ( H × W ) × ( H + W − 1 ) ) O((H\times W)\times(H+W-1)) O((H×W)×(H+W−1))。
具体地说,non-local module和criss-cross attention module都输入一个HxW的feature map来分别生成attention maps(上面的分支)和adapted feature maps(下面的分支)。然后采用加权和为聚合方式。在criss-cross attention module中,feature map中的每个position(蓝色方格)通过预测的稀疏attention map与其所在同一行和同一列的其他positions相连,这里的attention map只有H+W-1个权重而不是non-local中的HxW,如图2。进一步地,提出了recurrent criss-cross attention module来捕获所有pixels的长依赖关系,并且所有的criss-cross attention module都共享参数以便减少参数量。
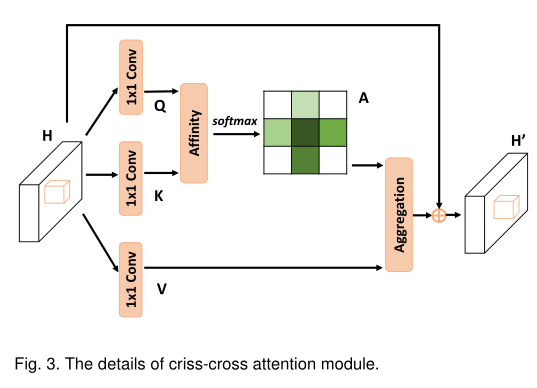
假设输入为 X : [ N , C , H , W ] X:[N, C, H, W] X:[N,C,H,W],为了让一个像素与其他位置像素建立联系,首先在该像素的纵向和横向建立联系,
以纵向为例:
①通过1x1卷积,得到 Q h : [ N , C r , H , W ] , K h : [ N , C r , H , W ] , V h : [ N , C , H , W ] , Q w , K w , V w Q_h:[N, Cr, H, W],K_h:[N, Cr, H, W], V_h:[N, C, H, W],Q_w,K_w,V_w Qh:[N,Cr,H,W],Kh:[N,Cr,H,W],Vh:[N,C,H,W],Qw,Kw,Vw同理;
②维度变换,reshape得到 Q h : [ N ∗ W , H , C r ] , K h : [ N ∗ W , C r , H ] , V h : [ N ∗ W , C , H ] Q_h:[N * W,H,Cr],K_h:[N * W,Cr,H],V_h:[N * W,C,H] Qh:[N∗W,H,Cr],Kh:[N∗W,Cr,H],Vh:[N∗W,C,H];
③Q_h和K_h矩阵乘法,得到 e n e r g y h : [ N ∗ W , H , H ] energy_h:[N * W, H, H] energyh:[N∗W,H,H];(源码中Enegy_H计算时加上了个维度为[N*W, H, H]的对角-inf矩阵,但是energy_w计算时没加,有点没搞懂。。)
④类似上面的流程,得到 e n e r g y h : [ N ∗ W , H , H ] energy_h:[N * W, H, H] energyh:[N∗W,H,H]和 e n e r g y w : [ N ∗ H , W , W ] energy_w:[N * H, W, W] energyw:[N∗H,W,W],reshape后维度变换得到 e n e r g y h : [ N , H , W , H ] energy_h:[N, H, W, H] energyh:[N,H,W,H]和 e n e r g y w : [ N , H , W , W ] energy_w:[N, H, W, W] energyw:[N,H,W,W],拼接得到 e n e r g y : [ N , H , W , H + W ] energy:[N, H, W, H + W] energy:[N,H,W,H+W];
⑤在energy最后一个维度使用softmax,得到attention系数;
⑥将attention系数拆分为 a t t n h : [ N , H , W , H ] attn_h:[N, H, W, H] attnh:[N,H,W,H]和 a t t n w : [ N , H , W , W ] attn_w:[N, H, W, W] attnw:[N,H,W,W],维度变换后与 V h V_h Vh和 V w V_w Vw分别相乘得到输出 o u t h out_h outh和 o u t w out_w outw;
⑦将 o u t h + o u t w out_h+out_w outh+outw,并乘上一个系数 γ γ γ(可学习参数),再加上residual connection,得到最终输出。
''' This code is borrowed from Serge-weihao/CCNet-Pure-Pytorch '''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
# def INF(B,H,W):
# return -torch.diag(torch.tensor(float("inf")).cuda().repeat(H),0).unsqueeze(0).repeat(B*W,1,1)
def INF(B, H, W):
return -torch.diag(torch.tensor(float("inf")).repeat(H), 0).unsqueeze(0).repeat(B * W, 1, 1)
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self, in_dim):
super(CrissCrossAttention,self).__init__()
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x)
proj_query_H = proj_query.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height).permute(0, 2, 1)
proj_query_W = proj_query.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width).permute(0, 2, 1)
proj_key = self.key_conv(x)
proj_key_H = proj_key.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_key_W = proj_key.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
proj_value = self.value_conv(x)
proj_value_H = proj_value.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_value_W = proj_value.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
energy_H = (torch.bmm(proj_query_H, proj_key_H)+self.INF(m_batchsize, height, width)).view(m_batchsize,width,height,height).permute(0,2,1,3)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize,height,width,width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:,:,:,0:height].permute(0,2,1,3).contiguous().view(m_batchsize*width,height,height)
#print(concate)
#print(att_H)
att_W = concate[:,:,:,height:height+width].contiguous().view(m_batchsize*height,width,width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize,width,-1,height).permute(0,2,3,1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize,height,-1,width).permute(0,2,1,3)
#print(out_H.size(),out_W.size())
return self.gamma*(out_H + out_W) + x
if __name__ == '__main__':
model = CrissCrossAttention(64)
x = torch.randn(2, 64, 5, 6)
out = model(x)
print(out.shape)
2.3 总结
本文是ICCV2019的语义分割领域的文章,旨在解决long-range dependencies问题,提出了基于十字交叉注意力机制(Criss-Cross Attention)的模块,利用更少的内存,只需要11x less GPU内存,并且相比non-local block更高的计算效率,减少了85%的FLOPs。最后,该模型在Cityscaoes测试集达到了81.4%mIOU,在ADE20K验证集达到了45.22%mIOU。
3. 代码
import time
from collections import OrderedDict
import torch.nn as nn
from torch.nn import functional as F, Softmax
import numpy as np
from torch.autograd import Variable
affine_par = True
import functools
import logging
import sys, os
from typing import Optional, Any
from warnings import warn
import torch
import torch.autograd as autograd
import torch.distributed as distributed
# from inplace_abn import InPlaceABN, InPlaceABNSync
# BatchNorm2d = functools.partial(InPlaceABNSync, activation='identity')
BatchNorm2d = nn.BatchNorm2d
_default_level_name = os.getenv('ENGINE_LOGGING_LEVEL', 'INFO')
_default_level = logging.getLevelName(_default_level_name.upper())
class LogFormatter(logging.Formatter):
log_fout = None
date_full = '[%(asctime)s %(lineno)[email protected]%(filename)s:%(name)s] '
date = '%(asctime)s '
msg = '%(message)s'
def format(self, record):
if record.levelno == logging.DEBUG:
mcl, mtxt = self._color_dbg, 'DBG'
elif record.levelno == logging.WARNING:
mcl, mtxt = self._color_warn, 'WRN'
elif record.levelno == logging.ERROR:
mcl, mtxt = self._color_err, 'ERR'
else:
mcl, mtxt = self._color_normal, ''
if mtxt:
mtxt += ' '
if self.log_fout:
self.__set_fmt(self.date_full + mtxt + self.msg)
formatted = super(LogFormatter, self).format(record)
# self.log_fout.write(formatted)
# self.log_fout.write('\n')
# self.log_fout.flush()
return formatted
self.__set_fmt(self._color_date(self.date) + mcl(mtxt + self.msg))
formatted = super(LogFormatter, self).format(record)
return formatted
if sys.version_info.major < 3:
def __set_fmt(self, fmt):
self._fmt = fmt
else:
def __set_fmt(self, fmt):
self._style._fmt = fmt
@staticmethod
def _color_dbg(msg):
return '\x1b[36m{}\x1b[0m'.format(msg)
@staticmethod
def _color_warn(msg):
return '\x1b[1;31m{}\x1b[0m'.format(msg)
@staticmethod
def _color_err(msg):
return '\x1b[1;4;31m{}\x1b[0m'.format(msg)
@staticmethod
def _color_omitted(msg):
return '\x1b[35m{}\x1b[0m'.format(msg)
@staticmethod
def _color_normal(msg):
return msg
@staticmethod
def _color_date(msg):
return '\x1b[32m{}\x1b[0m'.format(msg)
def get_logger(log_dir=None, log_file=None, formatter=LogFormatter):
logger = logging.getLogger()
logger.setLevel(_default_level)
del logger.handlers[:]
if log_dir and log_file:
if not os.path.isdir(log_dir):
os.makedirs(log_dir)
LogFormatter.log_fout = True
file_handler = logging.FileHandler(log_file, mode='a')
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
stream_handler = logging.StreamHandler()
stream_handler.setFormatter(formatter(datefmt='%d %H:%M:%S'))
stream_handler.setLevel(0)
logger.addHandler(stream_handler)
return logger
logger = get_logger()
def load_model(model, model_file, is_restore=False):
t_start = time.time()
if isinstance(model_file, str):
device = torch.device('cpu')
state_dict = torch.load(model_file, map_location=device)
if 'model' in state_dict.keys():
state_dict = state_dict['model']
else:
state_dict = model_file
t_ioend = time.time()
if is_restore:
new_state_dict = OrderedDict()
for k, v in state_dict.items():
name = 'module.' + k
new_state_dict[name] = v
state_dict = new_state_dict
model.load_state_dict(state_dict, strict=False)
ckpt_keys = set(state_dict.keys())
own_keys = set(model.state_dict().keys())
missing_keys = own_keys - ckpt_keys
unexpected_keys = ckpt_keys - own_keys
if len(missing_keys) > 0:
logger.warning('Missing key(s) in state_dict: {}'.format(
', '.join('{}'.format(k) for k in missing_keys)))
if len(unexpected_keys) > 0:
logger.warning('Unexpected key(s) in state_dict: {}'.format(
', '.join('{}'.format(k) for k in unexpected_keys)))
del state_dict
t_end = time.time()
logger.info(
"Load model, Time usage:\n\tIO: {}, initialize parameters: {}".format(
t_ioend - t_start, t_end - t_ioend))
return
def INF(B, H, W):
return -torch.diag(torch.tensor(float("inf")).repeat(H), 0).unsqueeze(0).repeat(B * W, 1, 1)
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self, in_dim):
super(CrissCrossAttention, self).__init__()
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim // 8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x)
proj_query_H = proj_query.permute(0, 3, 1, 2).contiguous().view(m_batchsize * width, -1, height).permute(0, 2,
1)
proj_query_W = proj_query.permute(0, 2, 1, 3).contiguous().view(m_batchsize * height, -1, width).permute(0, 2,
1)
proj_key = self.key_conv(x)
proj_key_H = proj_key.permute(0, 3, 1, 2).contiguous().view(m_batchsize * width, -1, height)
proj_key_W = proj_key.permute(0, 2, 1, 3).contiguous().view(m_batchsize * height, -1, width)
proj_value = self.value_conv(x)
proj_value_H = proj_value.permute(0, 3, 1, 2).contiguous().view(m_batchsize * width, -1, height)
proj_value_W = proj_value.permute(0, 2, 1, 3).contiguous().view(m_batchsize * height, -1, width)
energy_H = (torch.bmm(proj_query_H, proj_key_H) + self.INF(m_batchsize, height, width)).view(m_batchsize, width,
height,
height).permute(0,
2,
1,
3)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize, height, width, width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:, :, :, 0:height].permute(0, 2, 1, 3).contiguous().view(m_batchsize * width, height, height)
# print(concate)
# print(att_H)
att_W = concate[:, :, :, height:height + width].contiguous().view(m_batchsize * height, width, width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize, width, -1, height).permute(0, 2, 3, 1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize, height, -1, width).permute(0, 2, 1, 3)
# print(out_H.size(),out_W.size())
return self.gamma * (out_H + out_W) + x
def outS(i):
i = int(i)
i = (i + 1) / 2
i = int(np.ceil((i + 1) / 2.0))
i = (i + 1) / 2
return i
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, dilation=1, downsample=None, fist_dilation=1, multi_grid=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=dilation * multi_grid, dilation=dilation * multi_grid, bias=False)
self.bn2 = BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=False)
self.relu_inplace = nn.ReLU(inplace=True)
self.downsample = downsample
self.dilation = dilation
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out = out + residual
out = self.relu_inplace(out)
return out
class PSPModule(nn.Module):
""" Reference: Zhao, Hengshuang, et al. *"Pyramid scene parsing network."* """
def __init__(self, features, out_features=512, sizes=(1, 2, 3, 6)):
super(PSPModule, self).__init__()
self.stages = []
self.stages = nn.ModuleList([self._make_stage(features, out_features, size) for size in sizes])
self.bottleneck = nn.Sequential(
nn.Conv2d(features + len(sizes) * out_features, out_features, kernel_size=3, padding=1, dilation=1,
bias=False),
# InPlaceABNSync(out_features),
BatchNorm2d(out_features),
nn.Dropout2d(0.1)
)
def _make_stage(self, features, out_features, size):
prior = nn.AdaptiveAvgPool2d(output_size=(size, size))
conv = nn.Conv2d(features, out_features, kernel_size=1, bias=False)
# bn = InPlaceABNSync(out_features)
bn=BatchNorm2d(out_features)
return nn.Sequential(prior, conv, bn)
def forward(self, feats):
h, w = feats.size(2), feats.size(3)
priors = [F.upsample(input=stage(feats), size=(h, w), mode='bilinear', align_corners=True) for stage in
self.stages] + [feats]
bottle = self.bottleneck(torch.cat(priors, 1))
return bottle
class RCCAModule(nn.Module):
def __init__(self, in_channels, out_channels, num_classes):
super(RCCAModule, self).__init__()
inter_channels = in_channels // 4
self.conva = nn.Sequential(nn.Conv2d(in_channels, inter_channels, 3, padding=1, bias=False),
# InPlaceABNSync(inter_channels)
BatchNorm2d(inter_channels)
)
self.cca = CrissCrossAttention(inter_channels)
self.convb = nn.Sequential(nn.Conv2d(inter_channels, inter_channels, 3, padding=1, bias=False),
# InPlaceABNSync(inter_channels)
BatchNorm2d(inter_channels)
)
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels + inter_channels, out_channels, kernel_size=3, padding=1, dilation=1, bias=False),
# InPlaceABNSync(out_channels),
BatchNorm2d(out_channels),
nn.Dropout2d(0.1),
nn.Conv2d(512, num_classes, kernel_size=1, stride=1, padding=0, bias=True)
)
def forward(self, x, recurrence=1):
output = self.conva(x)
for i in range(recurrence):
output = self.cca(output)
output = self.convb(output)
output = self.bottleneck(torch.cat([x, output], 1))
return output
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes, criterion, recurrence):
self.inplanes = 128
super(ResNet, self).__init__()
self.conv1 = conv3x3(3, 64, stride=2)
self.bn1 = BatchNorm2d(64)
self.relu1 = nn.ReLU(inplace=False)
self.conv2 = conv3x3(64, 64)
self.bn2 = BatchNorm2d(64)
self.relu2 = nn.ReLU(inplace=False)
self.conv3 = conv3x3(64, 128)
self.bn3 = BatchNorm2d(128)
self.relu3 = nn.ReLU(inplace=False)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.relu = nn.ReLU(inplace=False)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=True) # change
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation=4, multi_grid=(1, 1, 1))
# self.layer5 = PSPModule(2048, 512)
self.head = RCCAModule(2048, 512, num_classes)
self.dsn = nn.Sequential(
nn.Conv2d(1024, 512, kernel_size=3, stride=1, padding=1),
# InPlaceABNSync(512),
BatchNorm2d(512),
nn.Dropout2d(0.1),
nn.Conv2d(512, num_classes, kernel_size=1, stride=1, padding=0, bias=True)
)
self.criterion = criterion
self.recurrence = recurrence
def _make_layer(self, block, planes, blocks, stride=1, dilation=1, multi_grid=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
BatchNorm2d(planes * block.expansion, affine=affine_par))
layers = []
generate_multi_grid = lambda index, grids: grids[index % len(grids)] if isinstance(grids, tuple) else 1
layers.append(block(self.inplanes, planes, stride, dilation=dilation, downsample=downsample,
multi_grid=generate_multi_grid(0, multi_grid)))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(
block(self.inplanes, planes, dilation=dilation, multi_grid=generate_multi_grid(i, multi_grid)))
return nn.Sequential(*layers)
def forward(self, x, labels=None):
x = self.relu1(self.bn1(self.conv1(x)))
x = self.relu2(self.bn2(self.conv2(x)))
x = self.relu3(self.bn3(self.conv3(x)))
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x_dsn = self.dsn(x)
x = self.layer4(x)
x = self.head(x, self.recurrence)
outs = [x, x_dsn]
if self.criterion is not None and labels is not None:
return self.criterion(outs, labels)
else:
return outs
def Seg_Model(num_classes, criterion=None, pretrained_model=None, recurrence=0, **kwargs):
model = ResNet(Bottleneck, [3, 4, 23, 3], num_classes, criterion, recurrence)
if pretrained_model is not None:
model = load_model(model, pretrained_model)
return model
if __name__ == '__main__':
x = torch.randn(1, 3, 224, 224)
model = Seg_Model(num_classes=19)
y = model(x)
for i in y:
print(i.shape)
参考资料
https://blog.csdn.net/qq_43088966/article/details/112966316
边栏推荐
- Electric power class topic of the question
- Induction of common annotations in Sring
- ctf (finalrec)
- Web3.exceptions.ExtraDataLengthError
- LeetCode: 623. Add a line to the binary tree [DFS or BFS]
- [Untitled] Directory Test
- Fragment的四种跳转方式
- 2022年阿里云服务器配置选取攻略
- The third day of learning MySQL: functions (basic)
- 2.cuBLAS开发指南中文版--使用cuBLAS API
猜你喜欢

2022年阿里云服务器配置选取攻略

Programmer's first day at work | Daily anecdote

Wang Qi, Secretary of the Party Committee and President of Shanghai Pudong Development Bank Changsha Branch, and Jiang Junwen, President of Huarong Xiangjiang Bank, visited Kylin Principal for investi

Preprocessing (in-depth understanding of C language)

6.软件测试-----自动化测试之unittest框架

ctf (finalrec)

Classic sql example

xctf attack and defense world web master advanced area command_execution

2022 使用Go语言构建现代 Web 应用程序实战内容课程

Use BeanUtils with caution, the performance really stretches!
随机推荐
sql server, two tables, the same field, the same amount of data (50 million), execute the same query, one table executes an index scan, scanning 50 million, which takes 2 minutes, the other table exec
2018HBCPC Partial Solutions
Failed to save image in R language ggplot2 loop
Django用orm修改mysql数据库运行出现错误
Qt开发经验小技巧231-235
LabVIEW 应用程序视窗始终置于顶层
jvm: synchronized关键字不同用法产生不同的字节码
暑假集训week3-DP
leetcode:1374. Generate an odd number of each character string
2.cuBLAS开发指南中文版--使用cuBLAS API
xctf attack and defense world web master advanced area command_execution
Develop SQL editors with Monaco Editor
2022 Alibaba Cloud server configuration selection strategy
What is an inner class?
Django reports an error ModuleNotFoundError: No module named 'mysqlclient'
P1065 [NOIP2006 提高组] 作业调度方案
用户认证——Kerberos部署
[wpf] Detailed explanation of three callbacks for dependency properties
Pytorch入门实战(5):基于nn.Transformer实现机器翻译(英译汉)
物联网协议概述