当前位置:网站首页>Deep q-network (dqn)
Deep q-network (dqn)
2022-04-23 02:56:00 【Live up to your youth】
Basic concepts
DQN
DQN Full name Deep Q-Leaning Network,DQN The basic idea of the algorithm comes from Q-Learning, differ Q-learning,DQN Of Q The value is not directly through the status value s And the action a Calculated , It is calculated by neural network .
DQN The algorithm is essentially Q-Learning Algorithm , In the choice of strategy, and Q-Learning bring into correspondence with , use ϵ − g r e e d y \epsilon-greedy ϵ−greedy Strategy . stay Q-learning On the basis of ,DQN Two techniques are proposed to make Q The update iteration of the network is more stable :
1、 Experience playback :DQN Use the experience pool for multiple experiences ( s , a , r , s ′ ) (s, a, r, s') (s,a,r,s′) Preservation , During training , Randomly extract a certain amount of data from the experience pool for training , In this way, we can constantly optimize the network model .
2、 Fix Q The goal is Fixed-Q-Target: It mainly solves the problem of unstable algorithm training . Copy one and the original Q The network structure is the same Target Q The Internet , Used to calculate Q The target .DQN There are two networks with the same structure but different parameters , Current value ( p r e d i c t Q predictQ predictQ) The network is used for prediction and estimation Q value , The target ( t a r g e t Q targetQ targetQ) The network is used to predict the real Q value . The current value network uses the latest parameters , The target value network will use parameters from a long time ago .
among , t a r g e t Q targetQ targetQ The formula for calculating the value : t a r g e t Q = r + γ ∗ m a x Q ( s ′ , a ∗ ; θ ) targetQ=r+γ∗maxQ(s',a^*;θ) targetQ=r+γ∗maxQ(s′,a∗;θ)
p r e d i c t Q predictQ predictQ Calculation formula : p r e d i c t Q = Q ( s , a ; θ ) predictQ=Q(s,a;\theta) predictQ=Q(s,a;θ)
As shown in the figure below , Use the mean square error loss function 1 m ∑ j = 1 m ( t a r g e t Q − p r e d i c t Q ) 2 \frac 1 m \sum_{j=1}^{m}(targetQ- predictQ)^2 m1∑j=1m(targetQ−predictQ)2, Through the neural network of the gradient back propagation to update p r e d i c t Q predictQ predictQ All parameters of the network θ \theta θ. And every N Time step , Copy p r e d i c t Q predictQ predictQ All parameters of the network to t a r g e t Q targetQ targetQ In the network .

In short ,DQN Use ϵ − g r e e d y \epsilon-greedy ϵ−greedy Strategy to select actions and execute , Adopt experience recovery mechanism , Use experience pool storage ( state , action , value , Next state ) Information , After storage , Obtain data in batch form , Use the mean square error loss function , The gradient random descent method is used to update the current value ( p r e d i c t Q predictQ predictQ) Network parameters , Train the current value network , And every N Time step , Synchronize parameters to target values ( t a r g e t Q targetQ targetQ) The Internet .
DQN And Q-Learning The difference between :
As a whole ,DQN And Q-Learning The target value and the way in which the value is updated are very similar . however ,DQN take Q-Learning Combined with deep learning , The depth network is used to approximate the action value function , and Q-Learning Is stored in a table ;DQN The training method of experience playback is adopted , Random sampling from historical data , and Q-Learning Directly use the data of the next state for learning .
DQN The algorithm is shown in the figure below .


In the above code , Q ( ϕ j , a j ; θ ) Q(\phi_j,a_j;\theta) Q(ϕj,aj;θ) Current value ( p r e d i c t Q predictQ predictQ) Network prediction Q value , y i = r j + γ m a x a ′ Q ( ϕ j + 1 , a ′ ; θ ) y_i=r_j + \gamma max_{a'}Q(\phi_{j+1},a';\theta) yi=rj+γmaxa′Q(ϕj+1,a′;θ) For the target ( t a r g e t Q targetQ targetQ) Network prediction Q value .
Test code
Here's a DQN An example of snake eating
import random
import sys
from collections import deque
import numpy as np
import pygame as pg
import tensorflow as tf
import cv2 as cv
# Parameters
# Game frame rate
FPS = 5
# Window width 、 Height
WINDOW_WIDTH, WINDOW_HEIGHT = 640, 480
# Composition size
CELL_SIZE = 40
CELL_WIDTH, CELL_HEIGHT = WINDOW_WIDTH // CELL_SIZE, WINDOW_HEIGHT // CELL_SIZE
# Common colors
WHITE = (255, 255, 255)
BLACK = (0, 0, 0)
DARK_GREEN = (0, 155, 0)
GREEN = (0, 255, 0)
DARK_GRAY = (60, 60, 60)
RED = (255, 0, 0)
# Direction
UP = "up"
DOWN = "down"
LEFT = "left"
RIGHT = "right"
# Output of neural network
MOVE_UP = [1, 0, 0, 0]
MOVE_DOWN = [0, 1, 0, 0]
MOVE_LEFT = [0, 0, 1, 0]
MOVE_RIGHT = [0, 0, 0, 1]
def check_for_key_press():
if len(pg.event.get(pg.QUIT)) > 0:
pg.quit()
sys.exit()
key_up_events = pg.event.get(pg.KEYUP)
if len(key_up_events) == 0:
return None
if key_up_events[0].key == pg.K_ESCAPE:
pg.quit()
sys.exit()
return key_up_events[0].key
def show_start_screen():
title_font = pg.font.Font("freesansbold.ttf", 100)
title_surface1 = title_font.render("snake", True, WHITE, DARK_GREEN)
title_surface2 = title_font.render("snake", True, GREEN)
degree1 = 0
degree2 = 0
press_key_font = pg.font.Font("freesansbold.ttf", 18)
press_key_surface = press_key_font.render("press a key to play", True, DARK_GRAY)
while True:
screen.fill(BLACK)
# draw snake word
rotated_surface1 = pg.transform.rotate(title_surface1, degree1)
rotated_rect1 = rotated_surface1.get_rect()
rotated_rect1.center = (WINDOW_WIDTH / 2, WINDOW_HEIGHT / 2)
screen.blit(rotated_surface1, rotated_rect1)
rotated_surface2 = pg.transform.rotate(title_surface2, degree2)
rotated_rect2 = rotated_surface2.get_rect()
rotated_rect2.center = (WINDOW_WIDTH / 2, WINDOW_HEIGHT / 2)
screen.blit(rotated_surface2, rotated_rect2)
# draw press key word
press_key_rect = press_key_surface.get_rect()
press_key_rect.topleft = (WINDOW_WIDTH - 200, WINDOW_HEIGHT - 30)
screen.blit(press_key_surface, press_key_rect)
if check_for_key_press():
pg.event.get()
return
pg.display.update()
clock.tick(FPS)
degree1 += 3
degree2 += 3
def test_not_ok(temp, worm):
for body in worm:
if temp['x'] == body['x'] and temp['y'] == body['y']:
return True
return False
def get_random_location(worm):
temp = {'x': random.randint(0, CELL_WIDTH - 1), 'y': random.randint(0, CELL_HEIGHT - 1)}
while test_not_ok(temp, worm):
temp = {'x': random.randint(0, CELL_WIDTH - 1), 'y': random.randint(0, CELL_HEIGHT - 1)}
return temp
# Check whether the greedy snake appears 180 Turn around
def examine_direction(pre_direction):
if direction == UP and pre_direction == DOWN:
return False
if direction == DOWN and pre_direction == UP:
return False
if direction == LEFT and pre_direction == RIGHT:
return False
if direction == RIGHT and pre_direction == LEFT:
return False
return True
def draw_grid():
for x in range(0, WINDOW_WIDTH, CELL_SIZE):
pg.draw.line(screen, DARK_GRAY, (x, 0), (x, WINDOW_HEIGHT))
for y in range(0, WINDOW_HEIGHT, CELL_SIZE):
pg.draw.line(screen, DARK_GRAY, (0, y), (WINDOW_WIDTH, y))
def draw_worm_coord():
for body in worm_coord:
x = body['x'] * CELL_SIZE
y = body['y'] * CELL_SIZE
body_rect = pg.Rect(x, y, CELL_SIZE, CELL_SIZE)
pg.draw.rect(screen, DARK_GREEN, body_rect)
body_inner_rect = pg.Rect(x + 4, y + 4, CELL_SIZE - 8, CELL_SIZE - 8)
pg.draw.rect(screen, GREEN, body_inner_rect)
def draw_apple():
x = apple['x'] * CELL_SIZE
y = apple['y'] * CELL_SIZE
apple_rect = pg.Rect(x, y, CELL_SIZE, CELL_SIZE)
pg.draw.rect(screen, WHITE, apple_rect)
def run_game(action=None):
global direction, worm_coord, head, apple
pre_direction = direction
if action == MOVE_UP and direction != DOWN:
direction = UP
elif action == MOVE_DOWN and direction != UP:
direction = DOWN
elif action == MOVE_LEFT and direction != RIGHT:
direction = LEFT
elif action == MOVE_RIGHT and direction != LEFT:
direction = RIGHT
for event in pg.event.get():
if event.type == pg.QUIT:
pg.quit()
sys.exit()
elif event.type == pg.KEYUP:
if (event.key == pg.K_LEFT or event.key == pg.K_a) and direction != RIGHT:
direction = LEFT
elif (event.key == pg.K_RIGHT or event.key == pg.K_d) and direction != LEFT:
direction = RIGHT
elif (event.key == pg.K_UP or event.key == pg.K_w) and direction != DOWN:
direction = UP
elif (event.key == pg.K_DOWN or event.key == pg.K_s) and direction != UP:
direction = DOWN
elif event.key == pg.K_ESCAPE:
pg.quit()
sys.exit()
reward = 0
# Check if the greedy snake touches the wall
if worm_coord[head]['x'] == -1 or worm_coord[head]['x'] == CELL_WIDTH \
or worm_coord[head]['y'] == -1 or worm_coord[head]['y'] == CELL_HEIGHT:
worm_coord = [{'x': start_x, 'y': start_y},
{'x': start_x - 1, 'y': start_y},
{'x': start_x - 2, 'y': start_y}]
direction = RIGHT
screen_image = pg.surfarray.array3d(pg.display.get_surface())
reward = -1
return reward, screen_image
# Check whether the greedy snake has touched itself
for worm_body in worm_coord[1:]:
if worm_body['x'] == worm_coord[head]['x'] and worm_body['y'] == worm_coord[head]['y']:
worm_coord = [{'x': start_x, 'y': start_y},
{'x': start_x - 1, 'y': start_y},
{'x': start_x - 2, 'y': start_y}]
direction = RIGHT
screen_image = pg.surfarray.array3d(pg.display.get_surface())
reward = -1
return reward, screen_image
# Check if the greedy snake has eaten an apple
# If you eat an apple , Don't delete the end , It's equivalent to adding a section
if worm_coord[head]['x'] == apple['x'] and worm_coord[head]['y'] == apple['y']:
reward = 1
apple = get_random_location(worm_coord)
# If you don't eat apples , Delete the last section
else:
del worm_coord[-1]
# Snake movement logic
# If the greedy snake appears 180 Degree of rotation , Then the direction remains the same as the original direction
if not examine_direction(pre_direction):
direction = pre_direction
# Determine the position of the new head according to the direction of the greedy snake
new_head = {}
if direction == UP:
new_head = {'x': worm_coord[head]['x'], 'y': worm_coord[head]['y'] - 1}
elif direction == DOWN:
new_head = {'x': worm_coord[head]['x'], 'y': worm_coord[head]['y'] + 1}
elif direction == LEFT:
new_head = {'x': worm_coord[head]['x'] - 1, 'y': worm_coord[head]['y']}
elif direction == RIGHT:
new_head = {'x': worm_coord[head]['x'] + 1, 'y': worm_coord[head]['y']}
worm_coord.insert(0, new_head)
screen.fill(BLACK)
draw_grid()
draw_apple()
draw_worm_coord()
pg.display.update()
clock.tick(FPS)
screen_image = pg.surfarray.array3d(pg.display.get_surface())
return reward, screen_image
def run():
global screen, clock
pg.init()
screen = pg.display.set_mode((WINDOW_WIDTH, WINDOW_HEIGHT))
clock = pg.time.Clock()
show_start_screen()
# while True:
# run_game()
# clock.tick(FPS)
# show_game_over_screen(screen)
start_x, start_y = 5, 5
head = 0
worm_coord = [{'x': start_x, 'y': start_y},
{'x': start_x - 1, 'y': start_y},
{'x': start_x - 2, 'y': start_y}]
direction = RIGHT
apple = get_random_location(worm_coord)
# run()
# Training parameters
LEARNING_RATE = 0.99
INITIAL_EPSILON = 1.0
FINAL_EPSILON = 0.05
EXPLORE = 50000
OBSERVE = 100
REPLAY_MEMORY = 1024
BATCH = 14
tf.compat.v1.disable_eager_execution()
input_image = tf.compat.v1.placeholder("float", [None, 160, 120, 4])
action = tf.compat.v1.placeholder("float", [None, 4])
def convolutional_neural_network(input_image):
weights = {"w_conv1": tf.Variable(tf.zeros([8, 8, 4, 32])),
"w_conv2": tf.Variable(tf.zeros([4, 4, 32, 64])),
"w_conv3": tf.Variable(tf.zeros([3, 3, 64, 64])),
"w_fc4": tf.Variable(tf.zeros([128, 64])),
"w_out": tf.Variable(tf.zeros([64, 4]))}
bias = {"b_conv1": tf.Variable(tf.zeros([32])),
"b_conv2": tf.Variable(tf.zeros([64])),
"b_conv3": tf.Variable(tf.zeros([64])),
"b_fc4": tf.Variable(tf.zeros([64])),
"b_out": tf.Variable(tf.zeros([4]))}
conv1 = tf.nn.relu(tf.nn.conv2d(input_image, weights["w_conv1"], strides=[1, 4, 4, 1], padding="VALID")
+ bias["b_conv1"])
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
conv2 = tf.nn.relu(tf.nn.conv2d(conv1, weights["w_conv2"], strides=[1, 2, 2, 1], padding="VALID")
+ bias["b_conv2"])
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
conv3 = tf.nn.relu(tf.nn.conv2d(conv2, weights["w_conv3"], strides=[1, 1, 1, 1], padding="VALID")
+ bias["b_conv3"])
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
conv3_flat = tf.reshape(conv3, [-1, 128])
fc4 = tf.nn.relu(tf.matmul(conv3_flat, weights["w_fc4"]) + bias["b_fc4"])
out = tf.matmul(fc4, weights["w_out"] + bias["b_out"])
return out
def train(input_image):
tf.compat.v1.disable_eager_execution()
predict_action = convolutional_neural_network(input_image)
argmax = tf.compat.v1.placeholder("float", [None, 4])
gt = tf.compat.v1.placeholder("float", [None])
# Define the calculation process of the mean square loss function
action = tf.reduce_sum(tf.multiply(predict_action, argmax))
cost = tf.reduce_mean(tf.square(action - gt))
# Define the machine learning process
optimizer = tf.compat.v1.train.AdamOptimizer(1e-2).minimize(cost)
run()
D = deque()
_, image = run_game()
image = cv.cvtColor(cv.resize(image, (120, 160)), cv.COLOR_BGR2GRAY)
ret, image = cv.threshold(image, 1, 255, cv.THRESH_BINARY)
input_image_data = np.stack((image, image, image, image), axis=2)
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.initialize_all_variables())
# saver = tf.train.Saver()
n = 0
epsilon = INITIAL_EPSILON
while True:
action_t = predict_action.eval(feed_dict={input_image: [input_image_data]})[0]
argmax_t = np.zeros([4], dtype=np.int)
# Each state in epsilon To explore the probability of
if random.random() <= epsilon:
max_index = random.randrange(4)
else:
max_index = np.argmax(action_t)
argmax_t[max_index] = 1
if epsilon > FINAL_EPSILON:
epsilon -= (INITIAL_EPSILON - FINAL_EPSILON) / EXPLORE
reward, image = run_game(list(argmax_t))
image = cv.cvtColor(cv.resize(image, (120, 160)), cv.COLOR_BGR2GRAY)
ret, image = cv.threshold(image, 1, 255, cv.THRESH_BINARY)
image = np.reshape(image, (160, 120, 1))
input_image_data1 = np.append(image, input_image_data[:, :, 0: 3], axis=2)
D.append((input_image_data, argmax_t, reward, input_image_data1))
if len(D) > REPLAY_MEMORY:
D.popleft()
if n > OBSERVE:
min_batch = random.sample(D, BATCH)
input_image_data_batch = [d[0] for d in min_batch]
argmax_batch = [d[1] for d in min_batch]
reward_batch = [d[2] for d in min_batch]
input_image_data1_batch = [d[3] for d in min_batch]
gt_batch = []
out_batch = predict_action.eval(feed_dict={input_image: input_image_data1_batch})
for i in range(0, len(min_batch)):
gt_batch.append(reward_batch[i] + LEARNING_RATE * np.max(out_batch[i]))
# The model parameters are updated by gradient back propagation
optimizer.run(feed_dict={gt: gt_batch, argmax: argmax_batch, input_image: input_image_data_batch})
input_image_data = input_image_data1
n = n + 1
print(n, "epsilon:", epsilon, " ", "action:", max_index, " ", "reward:", reward)
train(input_image)
test result

In the test , The greedy snake carried out 50000 Round training , Every training , The greedy snake selects the appropriate action through the strategy function , And store the results in the experience pool , The code in the above two-way queue Q. Greedy snakes have basically the ability to avoid the edge and find the best way to eat apples .
版权声明
本文为[Live up to your youth]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204220657127120.html
边栏推荐
- Plug in for vscode
- The shell monitors the depth of the IBM MQ queue and scans it three times in 10s. When the depth value exceeds 5 for more than two times, the queue name and depth value are output.
- The problem of removing spaces from strings
- JZ76 删除链表中重复的结点
- Rhcsa day 3 operation
- Encapsulate components such as pull-down menu based on ele
- Decision tree principle of machine learning
- TypeScript(1)
- Niuke white moon race 6 [solution]
- It turns out that PID was born in the struggle between Lao wangtou and Lao sky
猜你喜欢

Traversal of l2-006 tree (middle and later order determination binary tree & sequence traversal)

php+mysql對下拉框搜索的內容修改

Domestic lightweight Kanban scrum agile project management tool

Encapsulation of ele table

How to build an integrated industrial Internet plus hazardous safety production management platform?

Those years can not do math problems, using pyhon only takes 1 minute?

Looking for a job, writing a resume to an interview, this set of information is enough!

Kubernetes - Introduction to actual combat
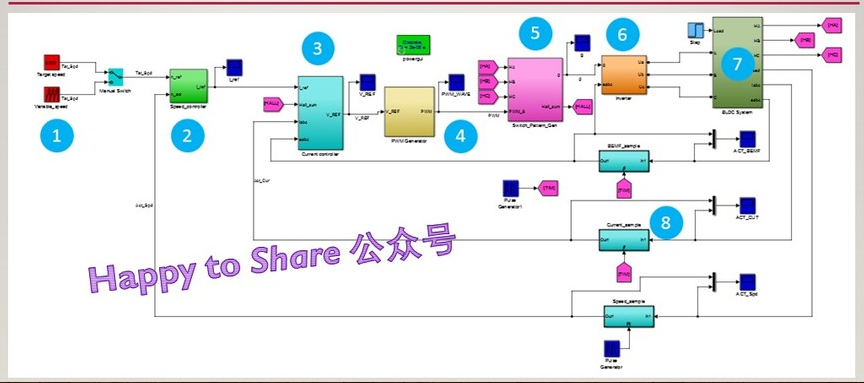
BLDC double closed loop (speed PI + current PI) Simulink simulation model

Actual combat of industrial defect detection project (IV) -- ceramic defect detection based on hrnet
随机推荐
What is the difference between varchar and char?
eventBus
Opencv fills the rectangle with a transparent color
win查看端口占用 命令行
Log cutting - build a remote log collection server
Classification and regression tree of machine learning
Wepy learning record
Basic workflow of CPU
Essential qualities of advanced programmers
Looking for a job, writing a resume to an interview, this set of information is enough!
基于多态的职工管理系统源码与一些理解
Decision tree principle of machine learning
Reverse a linked list < difficulty coefficient >
Redis data server / database / cache (2022)
Leangoo brain map - shared multi person collaborative mind mapping tool
JZ35 复杂链表的复制
L2-006 树的遍历(中后序确定二叉树&层序遍历)
JZ35 replication of complex linked list
Jz76 delete duplicate nodes in linked list
The space between the left and right of the movie ticket seats is empty and cannot be selected