当前位置:网站首页>Machine learning (Zhou Zhihua) Chapter 14 probability graph model
Machine learning (Zhou Zhihua) Chapter 14 probability graph model
2022-04-23 02:37:00 【YJY131248】
About teacher Zhou Zhihua 《 machine learning 》 The study notes of this book
Record the learning process
This blog record Chapter14
List of articles
1 hidden Markov model
Probability graph model (probabilistic graphical model): A probabilistic model that uses graphs to express the correlation of variables . The most common is Use a node to represent one or a group of random variables , Between nodes Edges represent the probability correlation between variables , namely Variable diagram . The probability graph model can be roughly classified as :
- Directed acyclic graph ( Directed graph model or Bayesian network )
- Undirected graph ( Undirected graph model or Markov Network )
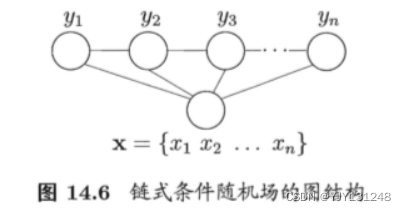
hidden Markov model (HMM): It's the simplest dynamic Bayesian network , It's a famous digraph model . It is mainly used in time series data modeling . There are two kinds of variables in hidden Markov model :
- State variables ( Hidden variables ): It means the first one i i i System status at any time { y 1 , y 2 , ⋯ , y n } \{y_1,y_2,\cdots,y_n\} { y1,y2,⋯,yn}, It's usually hidden 、 Unobservable .
- Observation variables : { x 1 , x 2 , ⋯ , x n } \{x_1,x_2,\cdots, x_n\} { x1,x2,⋯,xn}, It means the first one i i i Observations at the moment .
In hidden Markov model , The system is usually in multiple states { s 1 , s 2 , ⋯ , s N } \{s_1,s_2,\cdots,s_N\} { s1,s2,⋯,sN} Between , So the state variable y i y_i yi The value range of is usually N N N A discrete space with possible values , So the state variable y i y_i yi Value range of Y Y Y Usually there is N N N A discrete space with possible values ( Y ⊂ S Y \subset S Y⊂S). The observed variables can be discrete or continuous . For the convenience of discussion , We assume that its value range X = { o 1 , o 2 , ⋯ , o M } X=\{o_1,o_2,\cdots,o_M\} X={ o1,o2,⋯,oM}.

At any moment , The value of the observed variable x t x_t xt Only by state variables y t y_t yt determine , It has nothing to do with the values of other state variables and observation variables . meanwhile t t t The state of the moment y t y_t yt Only depends on t − 1 t-1 t−1 The state of the moment y t − 1 y_{t-1} yt−1, And the rest n − 2 n-2 n−2 It has nothing to do with two states , That's what's called “ Markov chain ”: The next state of the system is determined only by the current state , Not dependent on any previous state . The joint probability distribution of all variables is defined as :
P ( x 1 , y 1 , ⋯ , x n , y n ) = P ( y 1 ) P ( x 1 ∣ y 1 ) ∏ i = 2 n P ( y i ∣ y i − 1 ) P ( x i ∣ y i ) P(x_1,y_1,\cdots,x_n,y_n)=P(y_1)P(x_1|y_1)\prod_{i=2}^nP(y_i|y_{i-1})P(x_i|y_i) P(x1,y1,⋯,xn,yn)=P(y1)P(x1∣y1)i=2∏nP(yi∣yi−1)P(xi∣yi)
In addition to structural information , To determine a hidden Markov model, we also need the following three sets of parameters :
-
State transition probability :
a i j = P ( y t + 1 = s j ∣ y t = s i ) , 1 ≤ i , j ≤ N a_{ij}=P(y_{t+1}=s_j|y_t=s_i),\ \ \ \ \ 1\le i,j\le N aij=P(yt+1=sj∣yt=si), 1≤i,j≤N -
Output observation probability :
b i j = P ( x t = o j ∣ y t = s i ) b_{ij}=P(x_t=o_j|y_t=s_i) bij=P(xt=oj∣yt=si) -
Initial state probability :
π i = P ( y 1 = s i ) \pi_i=P(y_1=s_i) πi=P(y1=si)
2 Markov random Airport
Markov random Airport (MRF): A typical Markov Network , Is a famous undirected graph model :
- node : A variable or set of variables
- edge : Dependencies between variables
Markov random fields have a set of potential functions (potential functions), It's also called “ factor ”, That is, a nonnegative real function defined on a subset of variables , It is mainly used to define the probability distribution function .
In Markov random fields , For a subset of nodes in the graph , If any two nodes have edge connections , The node subset is called a “ group ”, If you add another node to the group , Can't form a group , It is called a “ Great regiment ”.

In Markov random field , The joint probability distribution among multiple variables can be decomposed into the product of multiple factors based on the clique decomposition , Each factor is related to only one cluster . say concretely , about n n n A variable X = { x 1 , x 2 , ⋯ , x n } X=\{x_1,x_2,\cdots, x_n\} X={
x1,x2,⋯,xn} , The set of all groups is C C C, And regiment Q ∈ C Q\in C Q∈C The corresponding variable set is recorded as X Q X_Q XQ , Then the joint probability P ( X ) P(X) P(X) Defined as
P ( X ) = 1 Z ∏ Q ∈ C ψ ( X Q ) P(X)=\frac{1}{Z}\prod_{Q\in C} \psi(X_Q) P(X)=Z1Q∈C∏ψ(XQ)
How to get... In Markov random field “ Conditional independence ” Well ? Also with the help of Separate The concept of . As shown in the figure below , If from the node set A Node in to B All nodes in must pass through the node set C Node in , Then it is called node set A and B Passive node set C Separate , C be called " Separate sets " (separating set).
Yes, Markov random field , Yes “ Global markov ” (global Markov property): Given the separation set of two variable subsets , Then the two variable subsets are conditionally independent . in other words , In the picture A, B and C The corresponding variable sets are X A , X B , X C X_A,X_B, X_C XA,XB,XC, be X A X_A XA and X B X_B XB In the given X C X_C XC Under the condition of Independence , Write it down as X A ⊥ X B ∣ X C XA\perp XB|X_C XA⊥XB∣XC.

By global Markov property , Two useful inferences can be drawn :
- Local Markov : Given the adjacency of a variable , Then the variable condition is independent of other variables .
- Paired markov sex : Given all the other variables , Two nonadjacent variables are conditionally independent .
Let's look at the potential function in Markov random field , Its effect is Quantitative characterization of variable sets X Q X_Q XQ Correlation of variables in ( Nonnegative function ), And There is a preference for the value of all variables .
To satisfy nonnegativity , Exponential functions are often defined as potential functions :
ψ Q ( X Q ) = e − H Q ( X Q ) \psi_Q(X_Q)=e^{-H_Q(X_Q)} ψQ(XQ)=e−HQ(XQ)
3 Conditional random field
Conditional random field (Conditional Random Field, abbreviation CRF) It's a discriminant undirected graph model , It's a discriminant model . Conditional random fields try to deal with multiple variables in Conditional probability after given Observations Modeling .
Make G = ( V , E ) G=(V,E) G=(V,E) Represents nodes and marked variables y y y Undirected graph with one-to-one correspondence of prime , y v y_v yv Indicates the connection with the node v v v The corresponding tag variable , n ( v ) n(v) n(v) Represents a node v v v Adjacent nodes of , If the figure G G G Each variable of the y v y_v yv All satisfy Markov property , namely
P ( y v ∣ x , y V \ { v } ) = P ( y v ∣ x , y n ( v ) ) P(y_v|x,y_{V\backslash \{v\}})=P(y_v|x,y_{n(v)}) P(yv∣x,yV\{
v})=P(yv∣x,yn(v))
be ( y , x ) (y,x) (y,x) Constitute a conditional random field .
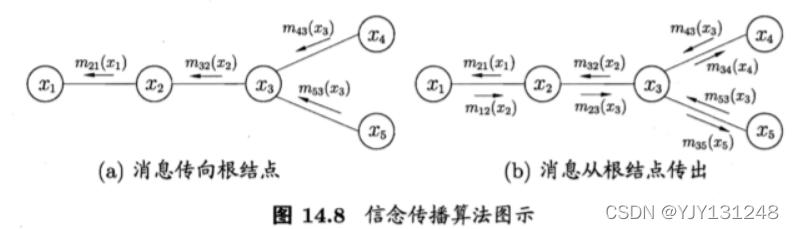
4 Learning and inference
- Variable elimination

- The spread of faith
5 Approximate inference
- MCMC sampling : The key is to construct " The stationary distribution is p p p Markov chain of " To generate samples .
- Variational inference : By using the known simple distribution to approximate the complex distribution to be inferred , And by limiting the type of approximate distribution , Thus, a local optimal 、 But the approximate a posteriori distribution with definite solution .
6 Topic model
Topic model (topic model) It's a family Generative directed graph model , It is mainly used to process discrete data ( Such as text collection ), In information retrieval 、 Natural language processing and other fields are widely used . Implicit Dirichlet distribution model (Latent Dirichlet Allocation, abbreviation LDA) It is a typical representative of topic model .
Basic concepts in topic model :
- word (word): The most basic discrete element
- file (document): Regardless of the order ( The word bag )
- topic of conversation (topic): A series of Related words , And the probability of their occurrence under this probability
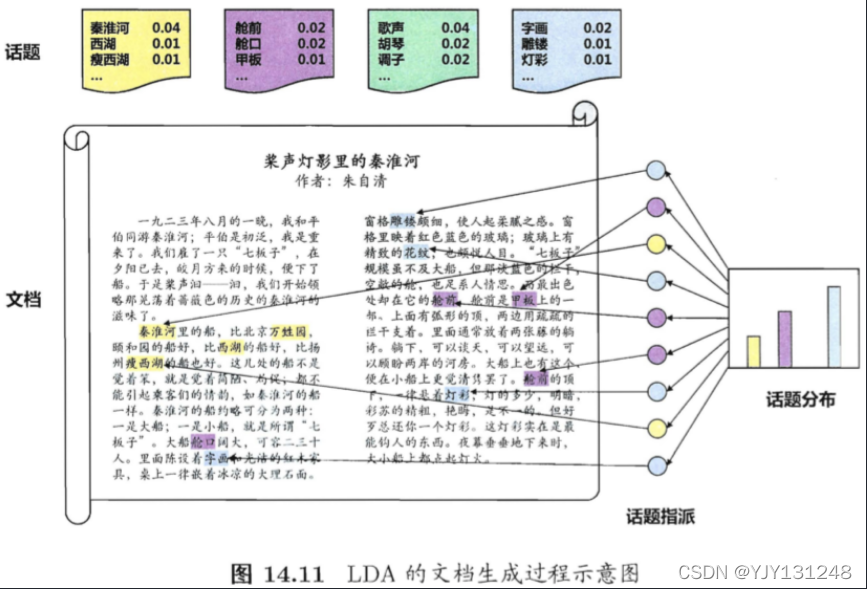
Let's assume that the dataset contains a total of K K K A topic and T T T document , The word in the document comes from a containing N N N A dictionary of words . We use it T T T individual N N N Dimension vector w = { w 1 , w 2 , ⋯ , w T } w=\{w_1,w_2,\cdots,w_T\} w={ w1,w2,⋯,wT} Represents a dataset ( Document collection ), K K K individual N N N Dimension vector β k ( k = 1 , 2 , ⋯ , K ) \beta_k\ \ (k=1 ,2,\cdots, K) βk (k=1,2,⋯,K) It means the topic , among w T ∈ R N w_T\in \mathbb R^N wT∈RN Of the n n n Weight w t , n w_{t,n} wt,n Represents a document t t t Middle word n n n The frequency of words , β k ∈ R N \beta_k\in \mathbb R^N βk∈RN Of the n n n Weight β k , n \beta_{k,n} βk,n It means the topic k k k Middle word n n n The frequency of words .
LDA Look at documents and topics from the perspective of a generative model . say concretely ,LDA Think that each document contains multiple topics , You might as well use vectors θ t ∈ R N \theta_t\in \mathbb R^N θt∈RN Represents a document t t t The proportion of each topic included in , θ t , k \theta_{t,k} θt,k Represents a document t t t Topics included in k k k The proportion of , Then through the following steps from the topic " Generate " file t t t:
- According to the parameters α \alpha α The Dirichlet distribution randomly samples a topic distribution θ t \theta_t θt
- Follow the steps below to generate... In the document N N N Word
- according to θ t \theta_t θt Assign topics , Get document t t t Middle word n n n The topic of z t , n z_{t,n} zt,n
- According to the word frequency distribution corresponding to the assigned topic β k \beta_k βk Random sampling generates words
版权声明
本文为[YJY131248]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204230236363265.html
边栏推荐
- Deploying sbert model based on torchserve < semantic similarity task >
- Cuisine leetcode
- day18--栈队列
- 能做多大的单片机项目程序开发,就代表了你的敲代码的水平
- 使用Go语言构建Web服务器
- How big the program development of single chip microcomputer project can be, it represents your level of knocking code
- After idea is successfully connected to H2 database, there are no sub files
- C语言中*与&的用法与区别 以及关键字static和volatile 的含义
- 005_ redis_ Set set
- 十六、异常检测
猜你喜欢

Usage of vector common interface

012_ Access denied for user ‘root‘@‘localhost‘ (using password: YES)

Global, exclusive and local routing guard

How to prevent leakage of operation and maintenance data

Day 3 of learning rhcsa
A domestic image segmentation project is heavy and open source!

Halo open source project learning (I): project launch

So library dependency
Target narak
day18--栈队列
随机推荐
PTA: praise the crazy devil
R language advanced | generalized vector and attribute analysis
How to solve the complexity of project document management?
MySQL JDBC programming
Implementation of distributed scenario business operation log (based on redis lightweight)
Push data from onenet cloud platform to database
程序设计天梯赛 L1-49 天梯赛分配座位(模拟),布响丸辣
arduino esp8266 网络升级 OTA
都是做全屋智能的,Aqara和HomeKit到底有什么不同?
Explain JS prototype and prototype chain in detail
1、 Sequence model
A domestic image segmentation project is heavy and open source!
Data warehouse construction table 111111
PTA: Romantic reflection [binary tree reconstruction] [depth first traversal]
电源电路设计原来是这么回事
Parental delegation model [understanding]
Hack the box optimum
使用Go语言构建Web服务器
[xjtu Computer Network Security and Management] session 2 Cryptographic Technology
Flink stream processing engine system learning (I)