当前位置:网站首页>car-price-deeplearning-0411
car-price-deeplearning-0411
2022-08-09 07:03:00 【Anakin6174】
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from tensorflow import keras
from sklearn.metrics import mean_absolute_error
from tqdm import tqdm
C:\ProgramData\Anaconda3\lib\site-packages\h5py\__init__.py:36: FutureWarning: Conversion of the second argument of issubdtype from `float` to `np.floating` is deprecated. In future, it will be treated as `np.float64 == np.dtype(float).type`.
from ._conv import register_converters as _register_converters
df = pd.read_csv(r'D:/Opendata/carprice/used_car_train_20200313.csv',sep = ' ')
df['notRepairedDamage'].replace('-', 0.5, inplace=True)
df['notRepairedDamage'] = df['notRepairedDamage'].astype(float)
# train_data = df[df['notRepairedDamage']==0]
data_test = pd.read_csv(r'D:/Opendata/carprice/used_car_testA_20200313.csv',sep = ' ')
data_test['notRepairedDamage'].replace('-', 0.5, inplace=True)
data_test['notRepairedDamage'] = data_test['notRepairedDamage'].astype(float)
df.shape
(150000, 31)
# 预处理
def date_proc_zero(x):
m = int(x[4:6])
if m == 0:
m = 1
return x[:4] + '-' + str(m) + '-' + x[6:]
def parse_date(df, colname):
newcol = colname + 'timestamp'
df[newcol] = pd.to_datetime(df[colname].astype('str').apply(date_proc_zero))
df[colname + '_year'] = df[newcol].dt.year
df[colname + '_month'] = df[newcol].dt.month
df[colname + '_day'] = df[newcol].dt.day
df[colname + '_dayofweek'] = df[newcol].dt.dayofweek
return df
train_data = df
train_data = parse_date(train_data, 'regDate')
train_data = parse_date(train_data, 'creatDate')
# 构造特征--Calculate car age,以月为单位
train_data['carAge'] = (train_data['creatDate_year'] - train_data['regDate_year']) * 12 + train_data['creatDate_month'] - train_data['regDate_month']
data_test = parse_date(data_test, 'regDate')
data_test = parse_date(data_test, 'creatDate')
# 构造特征--Calculate car age,以月为单位
data_test['carAge'] = (data_test['creatDate_year'] - data_test['regDate_year']) * 12 + data_test['creatDate_month'] - data_test['regDate_month']
train_data.info()
#Modify exception data
train_data['power'][train_data['power']>600]=600
data_test['power'][data_test['power']>600]=600
C:\ProgramData\Anaconda3\lib\site-packages\ipykernel_launcher.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
C:\ProgramData\Anaconda3\lib\site-packages\ipykernel_launcher.py:3: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy
This is separate from the ipykernel package so we can avoid doing imports until
def cross_cat_num(df,num_col,cat_col):
for f1 in tqdm(cat_col):
g = df.groupby(f1, as_index=False)
for f2 in tqdm(num_col):
feat = g[f2].agg({
'{}_{}_max'.format(f1, f2): 'max', '{}_{}_min'.format(f1, f2): 'min',
'{}_{}_median'.format(f1, f2): 'median', '{}_{}_mean'.format(f1, f2): 'mean',
'{}_{}_std'.format(f1, f2): 'std', '{}_{}_mad'.format(f1, f2): 'mad',
})
df = df.merge(feat, on=f1, how='left')
return df
cross_cat = ['bodyType', 'brand', 'regionCode','name','fuelType','gearbox']
cross_num = ['v_12','v_8', 'v_0', 'power', 'v_3','kilometer']
train_data = cross_cat_num(train_data,cross_num,cross_cat)
data_test = cross_cat_num(data_test,cross_num,cross_cat)
train_data = pd.get_dummies(train_data, prefix=None, prefix_sep='_', dummy_na=False, columns=['model','bodyType','gearbox','brand','fuelType','notRepairedDamage'], sparse=False, drop_first=False)
train_data.head()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| SaleID | name | regDate | power | kilometer | regionCode | seller | offerType | creatDate | price | ... | fuelType_0.0 | fuelType_1.0 | fuelType_2.0 | fuelType_3.0 | fuelType_4.0 | fuelType_5.0 | fuelType_6.0 | notRepairedDamage_0.0 | notRepairedDamage_0.5 | notRepairedDamage_1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 736 | 20040402 | 60 | 12.5 | 1046 | 0 | 0 | 20160404 | 1850 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 1 | 2262 | 20030301 | 0 | 15.0 | 4366 | 0 | 0 | 20160309 | 3600 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 2 | 2 | 14874 | 20040403 | 163 | 12.5 | 2806 | 0 | 0 | 20160402 | 6222 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 3 | 71865 | 19960908 | 193 | 15.0 | 434 | 0 | 0 | 20160312 | 2400 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 4 | 4 | 111080 | 20120103 | 68 | 5.0 | 6977 | 0 | 0 | 20160313 | 5200 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
5 rows × 560 columns
data_test = pd.get_dummies(data_test, prefix=None, prefix_sep='_', dummy_na=False, columns=['model','bodyType','gearbox','brand','fuelType','notRepairedDamage'], sparse=False, drop_first=False)
data_test.head()
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
| SaleID | name | regDate | power | kilometer | regionCode | seller | offerType | creatDate | v_0 | ... | fuelType_0.0 | fuelType_1.0 | fuelType_2.0 | fuelType_3.0 | fuelType_4.0 | fuelType_5.0 | fuelType_6.0 | notRepairedDamage_0.0 | notRepairedDamage_0.5 | notRepairedDamage_1.0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 150000 | 66932 | 20111212 | 313 | 15.0 | 1440 | 0 | 0 | 20160329 | 49.593127 | ... | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 1 | 150001 | 174960 | 19990211 | 75 | 12.5 | 5419 | 0 | 0 | 20160404 | 42.395926 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 2 | 150002 | 5356 | 20090304 | 109 | 7.0 | 5045 | 0 | 0 | 20160308 | 45.841370 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 3 | 150003 | 50688 | 20100405 | 160 | 7.0 | 4023 | 0 | 0 | 20160325 | 46.440649 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 4 | 150004 | 161428 | 19970703 | 75 | 15.0 | 3103 | 0 | 0 | 20160309 | 42.184604 | ... | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
5 rows × 558 columns
missing_cols = set( train_data.columns ) - set( data_test.columns )
print(missing_cols)
{'price', 'model_247.0'}
data_test['model_247.0'] = 0
train_data.columns
Index(['SaleID', 'name', 'regDate', 'power', 'kilometer', 'regionCode',
'seller', 'offerType', 'creatDate', 'price',
...
'fuelType_0.0', 'fuelType_1.0', 'fuelType_2.0', 'fuelType_3.0',
'fuelType_4.0', 'fuelType_5.0', 'fuelType_6.0', 'notRepairedDamage_0.0',
'notRepairedDamage_0.5', 'notRepairedDamage_1.0'],
dtype='object', length=560)
train_data.fillna(train_data.median(),inplace= True)
data_test.fillna(train_data.median(),inplace= True)
tags=list(train_data.columns)
print(len(tags))
print(tags)
tags.remove('price')
tags.remove('creatDatetimestamp')
tags.remove('SaleID')
tags.remove('regDatetimestamp')
print(len(tags))
print(tags)
#特征归一化
min_max_scaler = MinMaxScaler()
min_max_scaler.fit(train_data[tags].values)
x = min_max_scaler.transform(train_data[tags].values)
x_ = min_max_scaler.transform(data_test[tags].values)
#获得y值
y = train_data['price'].values
#切分训练集
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size = 0.1)
model = keras.Sequential([
keras.layers.Dense(500,activation='relu',input_shape=[556]),
keras.layers.Dense(300,activation='relu'),
keras.layers.Dense(200,activation='relu'),
keras.layers.Dense(1)])
model.compile(loss='mean_absolute_error',
optimizer='Adam')
model.fit(x_train,y_train,batch_size = 2048,epochs=100) # 100+10
<tensorflow.python.keras.callbacks.History at 0xf898710>
#Compare the training and validation sets
print(mean_absolute_error(y_train,model.predict(x_train)))
460.7230023605912
test_pre = model.predict(x_test)
print(mean_absolute_error(y_test,test_pre))
517.5352069231669
#Output result prediction
y_=model.predict(x_)
data_test_price = pd.DataFrame(y_,columns = ['price'])
results = pd.concat([data_test['SaleID'],data_test_price],axis = 1)
results.to_csv('results0411.csv',sep = ',',index = None)
def build_model_xgb(x_train,y_train):
model = xgb.XGBRegressor(n_estimators=150, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #, objective ='reg:squarederror'
model.fit(x_train, y_train)
return model
def build_model_lgb(x_train,y_train):
estimator = lgb.LGBMRegressor(num_leaves=127,n_estimators = 150)
param_grid = {
'learning_rate': [0.01, 0.05, 0.1, 0.2],
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(x_train, y_train)
return gbm
## 定义了一个统计函数,方便后续信息统计
def Sta_inf(data):
print('_min',np.min(data))
print('_max:',np.max(data))
print('_mean',np.mean(data))
print('_ptp',np.ptp(data))
print('_std',np.std(data))
print('_var',np.var(data))
import lightgbm as lgb
import xgboost as xgb
from sklearn.model_selection import GridSearchCV
print('Train lgb...')
model_lgb = build_model_lgb(x_train,y_train)
# val_lgb = model_lgb.predict(x_val)
# MAE_lgb = mean_absolute_error(y_val,val_lgb)
# print('MAE of val with lgb:',MAE_lgb)
Train lgb...
C:\ProgramData\Anaconda3\lib\site-packages\sklearn\model_selection\_split.py:1978: FutureWarning: The default value of cv will change from 3 to 5 in version 0.22. Specify it explicitly to silence this warning.
warnings.warn(CV_WARNING, FutureWarning)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-35-42ba48cb64d4> in <module>()
4 print('Train lgb...')
5 model_lgb = build_model_lgb(x_train,y_train)
----> 6 val_lgb = model_lgb.predict(x_val)
7 MAE_lgb = mean_absolute_error(y_val,val_lgb)
8 print('MAE of val with lgb:',MAE_lgb)
NameError: name 'x_val' is not defined
val_lgb = model_lgb.predict(x_test)
MAE_lgb = mean_absolute_error(y_test,val_lgb)
print('MAE of val with lgb:',MAE_lgb)
MAE of val with lgb: 560.9402517671131
print('Train xgb...')
model_xgb = build_model_xgb(x_train,y_train)
val_xgb = model_xgb.predict(x_test)
MAE_xgb = mean_absolute_error(y_test,val_xgb)
print('MAE of val with xgb:',MAE_xgb)
Train xgb...
MAE of val with xgb: 595.2708631515503
cross_cat = [‘bodyType’, ‘brand’, ‘regionCode’,‘name’,‘fuelType’,‘gearbox’]
cross_num = [‘v_0’,‘v_1’, ‘v_3’, ‘v_6’, ‘v_12’,‘v_14’]
model = keras.Sequential([
keras.layers.Dense(500,activation=‘relu’,input_shape=[556]),
keras.layers.Dense(300,activation=‘relu’),
keras.layers.Dense(200,activation=‘relu’),
keras.layers.Dense(1)])
----------473
边栏推荐
猜你喜欢
高项 04 项目变更管理
分布式id 生成器实现
Distributed id generator implementation
postgresql Window Functions
更改Jupyter Notebook默认打开目录
【报错】Root Cause com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
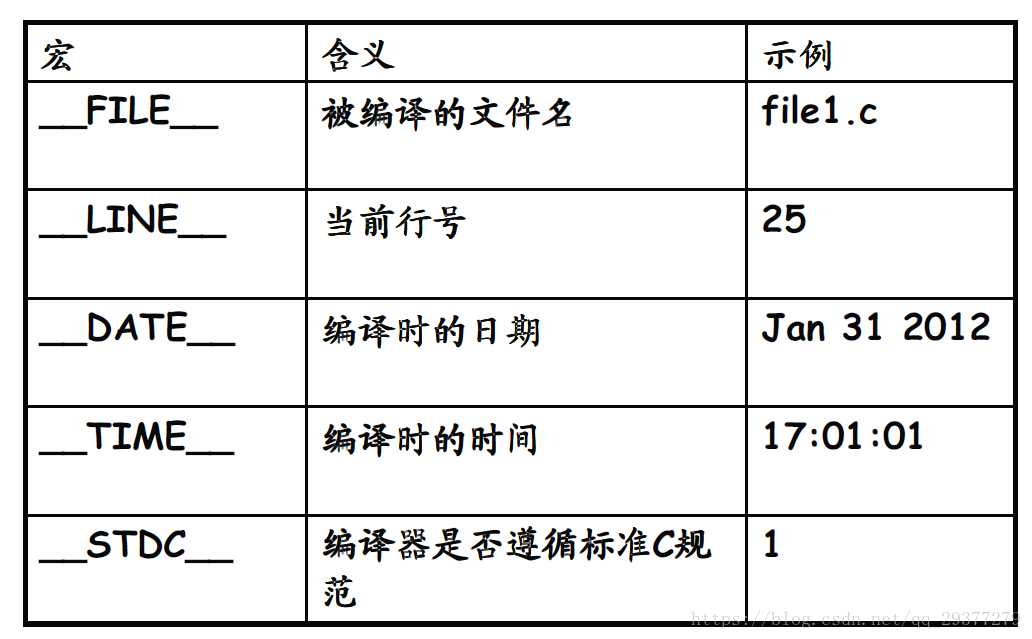
Built-in macros in C language (define log macros)
子路由及路由出口配置
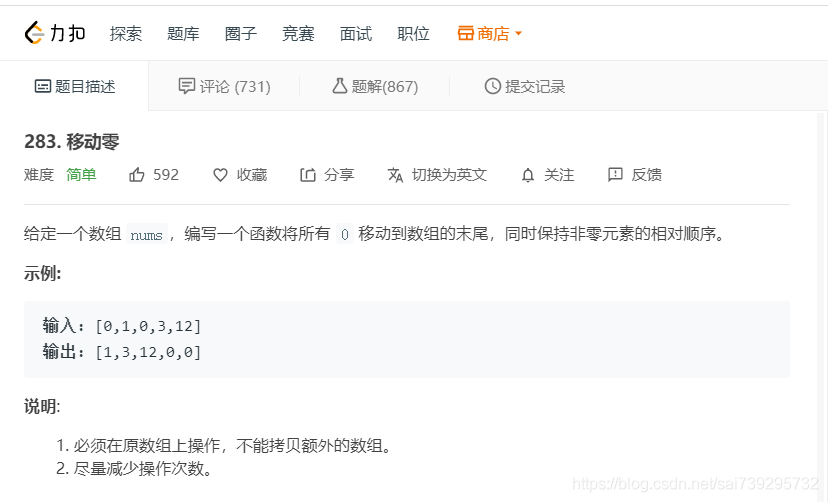
Zero shift of leetcode
常见的分布式事务解决方案
随机推荐
字节跳动面试题之镜像二叉树2020
线程池总结
Inception V3 Eye Closure Detection
list与string转换
分布式理论
AD picture PCB tutorial 20 minutes clear label shop operation process, copper network
stm32定时器之简单封装
字节也开始缩招了...
子路由及路由出口配置
MUI无法滚动?完美解决
rsync:recv_generator: mkdir (in backup) failed:Permission denied (13) |failed to set times on '.'
P1505 [国家集训队]旅游 树链剖分
The AD in the library of library file suffix. Intlib. Schlib. Pcblib difference
【ROS2原理8】节点到参与者的重映射
Forest Program dfs+tanjar仙人掌
failed (13: Permission denied) while connecting to upstream
2022 年全球十大最佳自动化测试工具
APP product source data interface (taobao, jingdong/spelling/suning/trill platform details a lot data analysis interface) code and docking tutorial
unity第一课
leetcode 之 70 爬楼梯问题 (斐波那契数)