IO流

Java中输入/输出流常用的流:
字节输入流 字节输出流 字符输入流 字符输出流
抽象基类 InputStream OutputStream Reader Writer
访问文件 FileInputStream FileOutputStream FileReader FileWriter
(节点流)
缓冲流 BufferedInputStream BufferedOutputStream BufferedReader BufferedWriter
(处理流)
操作对象 ObjectInputStream ObjectOutputStream

字节输入流:
* 1.创建一个FileInputStream对象
* 2.定义一个标记,用来控制输入流的读取
* 3.循环读取,如果读取到了-1,说明读取到了文件的末尾,循环结束
* 4.关闭资源。*****
一个一个的读

创建字节数组一起输出
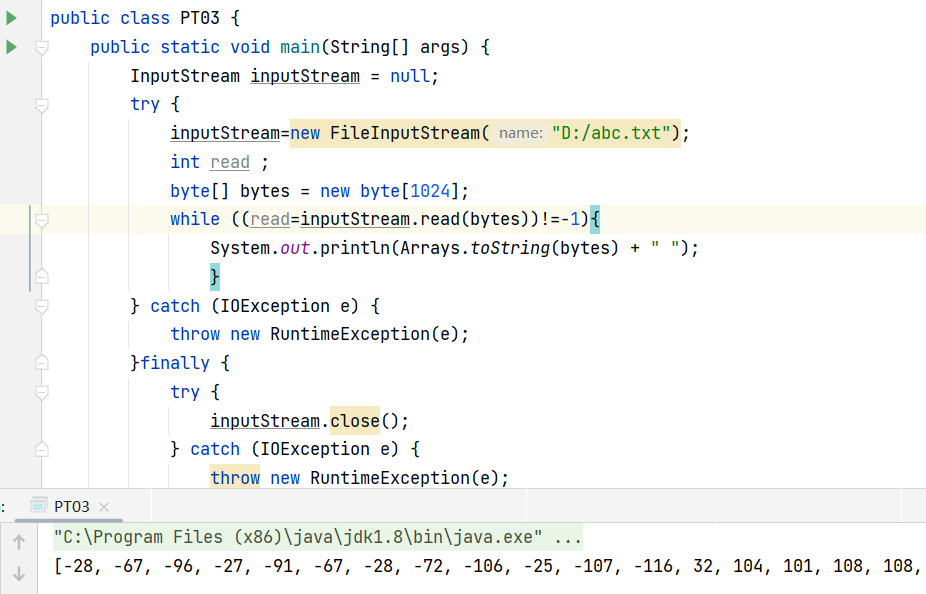
注意:我们发现一个流读完了就没有了,不能再读了。
* 当一个流读完之后会默认调用mark和reset方法来进行记录和重置,
* 这个流就已经重置到了上次读完的位置,
* 所以就无法再次读取内容。并不是读完一次之后就关闭了流。
点击查看代码
@Test
public void test01() {
InputStream inputStream = null;
try {
inputStream = new FileInputStream("e:/aaa.txt");
// 开始读的操作,read方法,返回值是int,当返回值为-1时,说明文件读取到了末尾
// 读取文件是否结束的标记
int read;
// 字节流读数据的时候一个字节一个字节去读
// 循环读取
while((read = inputStream.read()) != -1) {
System.out.print(read + " ");
}
System.out.println();
System.out.println("读取完毕,再读一次。。。。");
// 字节流读数据的时候一个字节一个字节去读
// 循环读取
while((read = inputStream.read()) != -1) {
System.out.print(read + " ");
}
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
try {
// 关闭流
inputStream.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
* 注意:我们发现一个流读完了就没有了,不能再读了。
*
* 当一个流读完之后会默认调用mark和reset方法来进行记录和重置,
* 这个流就已经重置到了上次读完的位置,
* 所以就无法再次读取内容。并不是读完一次之后就关闭了流。
*
字节输出流
FileOutputStream构造器:
boolean append参数:如果传入true,则代表在原有基础上追加,不覆盖
如果传入false,或者不传,覆盖原有内容
写的操作,目标文件如果不存在,会自动新建。

文件的复制
点击查看代码
public static void main(String[] args) {
InputStream inputStream = null; //文件的复制
OutputStream outputStream = null;
try {
int len;
byte[] bytes = new byte[10];
inputStream = new FileInputStream("D:/abc.txt");
outputStream = new FileOutputStream("D:/ych.txt");
while ((len=inputStream.read(bytes))!=-1){
outputStream.write(bytes,0,len);
}
System.out.println("文件复制成功");
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
} catch (IOException e) {
throw new RuntimeException(e);
}finally {
try {
if (Objects.nonNull(inputStream)){
inputStream.close();
}
} catch (Exception e) {
throw new RuntimeException(e);
}
try {
if (Objects.nonNull(outputStream)){
outputStream.close();
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
字符流
输出数据

字符流
输入数据

* 字符处理流(用的最多)
* 缓冲流
*
* 只能处理纯文本文件:
* .txt,.java,.html,.css.........
*
* 利用缓冲字符流来写一个文件的复制
缓冲字符流
输入数据

缓冲字符流
输出数据

* 外层流,内层流,关闭了外层的流,内层的流会随之关闭。
* 我们最终会把所有的.class文件打包,把这个包部署到服务器上。
* 从始至终,.java仅仅是我们程序员写的,给程序员看的。
* .java甚至不会参与到打包中,不会出现在服务器上。
*
* 运维人员去服务器部署项目,部署的就是一堆的.class。
* 我们的.properties属性文件是不参与编译的。

序列化与反序列化:操作对象
* 序列化:将对象写入到IO流中,将内存模型的对象变成字节数字,
* 可以进行存储和传输。
* 反序列化:从IO流中恢复对象,将存储在硬盘上或者从网络中接收的数据
* 恢复成对象模型
* 使用场景:所有可在网络上传输的对象都必须是可序列化的,
* 否则会报错,所有保存在硬盘上的对象也必须要可序列化。
*
* 序列化版本号:
* 反序列化必须拥有class文件,但随着项目的升级,class文件也会升级
* 序列化保证升级前后的兼容性。
*
* java序列化提供了一个版本号
* 版本号是可以自由指定,如果不指定,JVM会根据类信息自己计算一个版本号,
* 所以无法匹配,则报错!!!
*
* 不指定版本号,还有一个隐患,不利于JVM的移植,可能class文件没有改,
* 但是不同的jvm计算规则不一样,导致无法反序列化
*
* 如果只修改了方法,反序列化是不受影响,无需修改版本号
* 修改了静态变量static,瞬态变量transient,反序列化也不受影响,无需修改版本号
总结:
* 1.所有需要网络传输的对象都需要实现序列化接口
* 2.对象的类名、实例变量都会被序列化;方法、类变量、transient变量不会被序列化
* 3.如果想让某个变量不被序列化,可以用transient修饰
* 4.序列化对象的引用类型成员变量,也必须是可序列化的,否则会报错
* 5.反序列化时必须有序列化对象的class文件
* 6.同一个对象被序列化多次,只有第一次序列化为二进制流,以后都只是保存序列化的版本号
* 7.建议所有可序列化的类加上版本号,方便项目升级。



![This article lets you quickly understand implicit type conversion [integral promotion]!](/img/16/4edc7ef23384b22d50ebd894b8911a.png)