当前位置:网站首页>Data Mining-05
Data Mining-05
2022-08-09 13:17:00 【Draw a circle and curse you yebo】
线性判别分析
线性判别分析(linear discriminant analysis,LDA)是对费舍尔的线性鉴别方法的归纳,这种方法使用统计学,模式识别和机器学习方法,试图找到两类物体或事件的特征的一个线性组合,以能够特征化或区分它们.所得的组合可用来作为一个线性分类器,或者,更常见的是,为后续的分类做降维处理.
线性判别分析是一种经典的线性学习方法,在二分类问题上最早由Fisher在1936年提出,亦称Fisher线性判别.线性判别的思想非常朴素:给定训练样例集,设法将样例投影到一条直线上,使得同类样例的投影点尽可能接近,异样样例的投影点尽可能远离;在对新样本进行分类时,将其投影到同样的直线上,再根据投影点的位置来确定新样本的类别. [2]
LDA与方差分析(ANOVA)和回归分析紧密相关,这两种分析方法也试图通过一些特征或测量值的线性组合来表示一个因变量.然而,方差分析使用类别自变量和连续数因变量,而判别分析连续自变量和类别因变量(即类标签).逻辑回归和概率回归比方差分析更类似于LDA,因为他们也是用连续自变量来解释类别因变量的.
LDA的基本假设是自变量是正态分布的,当这一假设无法满足时,在实际应用中更倾向于用上述的其他方法.LDA也与主成分分析(PCA)和因子分析紧密相关,它们都在寻找最佳解释数据的变量线性组合.LDA明确的尝试为数据类之间不同建立模型. 另一方面,PCA不考虑类的任何不同,因子分析是根据不同点而不是相同点来建立特征组合.判别的分析不同因子分析还在于,它不是一个相互依存技术:即必须区分出自变量和因变量(也称为准则变量)的不同.在对自变量每一次观察测量值都是连续量的时候,LDA能有效的起作用.当处理类别自变量时,与LDA相对应的技术称为判别反应分析.
优点
可以直接求得基于广义特征值问题的解析解,从而避免了在一般非线性算法中,如多层感知器,构建中所常遇到的局部最小问题无需对模式的输出类别进行人为的编码,从而使 LDA 对不平衡模式类的处理表现出尤其明显的优势.与神经网络方法相比,LDA 不需要调整参数,因而也不存在学习参数和优化权重以及神经元激活函数的选择等问题;对模式的归一化或随机化不敏感,而这在基于梯度 下降的各种算法中则显得比较突出 [3] .在某些实际情形中,LDA 具有与基于结构风险最小化原理的支持向量机(SVM)相当的甚至更优的推广性能,但其计算效率则远优于SVM.正则判别分析法(CDA)寻找最优区分类别的坐标轴(k-1个正则坐标,k为类别的数量). 这些线性函数是不相关的,实际上,它们通过n维数据云定义了一个最优化的k-1个空间,能够最优的区分k个类(通过其在空间的投影)..
多类LDA:当出现超过两类的情况时,可以使用由费舍尔判别派生出的分析方法,它延伸为寻找一个保留了所有类的变化性的子空间.这是由 C.R.Rao 总结出来的.假设,C个类中每一个类都有均值和相同的协方差.
要实现典型的LDA技术前提是所有的样本都必须提前准备完毕.但有些情况下,没有现成的完整数据集或者输入观察数据是流的形式.这样,就要求LDA的特征提取有能力随着观察新样本的增加而更新LDA的特征,而不是在整个数据集上运行算法.例如,在移动机器人或实时脸部识别等实时应用中,提取的LDA特征能随着新观察值实时更新是非常重要的.这种能够通过简单观察新样本来更新LDA特征的技术就叫做增量LDA算法,在过去二十年里,它已经被广泛的研究过.Catterjee和Roychowdhury提出了一种增量自组织LDA算法来更新LDA特征.另外,Demir和Ozmehmet提出利用误差改正和赫布学习规则的线上本地学习算法来更新LDA特征.最后,Aliyari等人提供了快速增量LDA算法.
线性判别分析
Performs linear discriminant analysis can be usedlda()函数,And there are three kinds of the function execution form,依次尝试使用.
(1)公式formula格式
我们使用nmkatAs for discriminant variables,Other features of the rest of the variable as variable,根据公式nmkat~Using the training set data to runlda()函数:
1 2 3 4 5 6 7 |
|

结果分析:我们看到,可以根据lda()函数得到10The output item,Respectively used during the execution of the prior probability ofprior、Data set all kinds of other sample sizecounts、The mean of each variable in each category means等.
1 |
|
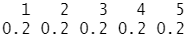
1 |
|

结果分析:Because we used in the process of sampling beforenmkatEach level of stratified sampling methods such as probability,Therefore as all kinds of other prior probability and the sample size in5A hierarchy are equal.具体的,5Kind of the prior probability of as0.2,之和为1,And each training focus on the spare144个样本.
1 |
|

结果分析:In above average output results,We can see some very can reflect the characteristics of the reality of data.比如,对于占地面积wfl变量,它明显随着租金nmkat的升高而逐步提高,We see in the rents for grade1(少于500马克)时,Covers an area of average was only about55.53平方米,And for the rent level5(The rent is not lower than1150 马克),The average area reached92.24平方米.The larger the area rents the expensive,This is a very common sense.
执行fitlda1Output can be directly to the discriminant result.
(2)数据框data.frame及矩阵matrix格式
Because both the body of the function format parameters asx与grouping,We put together,程序代码如下:
1 |
|
#设置属性变量(除第12个变量nmkat外)And stay discriminant variables(第12个变量nmkat)的取值
1 |
|

2.Discriminant rules visualization
我们首先使用plot()Direct discriminant rule tofit_ldalFor the object output graphics,如下图所示:
1 |
|

结果分析:从图可以看到,在所有4A linear discriminant(Linear Discriminants,即 LD)下1至5这5The distribution of category,Samples of different categories have been marked by corresponding digital.
我们可以通过dimenParameter setting to control the output graphics used in the discriminant number when the parameter value is greater than the total number of discriminant type,Take all the default style,Such as the following respectively by dimen=1和2As an example to generate graphics,分别如图所示:
1 2 3 |
|

结果分析:1类和5Classes are clear,2,3,4Class overlap a lot.
3.The test set for judging state variable to predict
Let's get before using discriminant rulefitldalTo test set datatestThe discriminant variables to benmkat 的类别进行预测.
1 2 3 |
|

1 |
|

结果分析:将class与 posteriorThe output of combined to see,We know that everything belonged to the highest of all kinds of other posterior probability of the sample was diagnosed categories.比如,posteriorOutput in item number for“3”Sample belongs to the2Class has the highest probability,约为0.501,So the sample in the discriminant is classified as class2.
In order to further evaluate the effect of the discriminant,We can generate test concentrationnmkatVariables predicted results with the actual category confusion matrix,代码如下:
1 |
|

1 |
|

结果分析:By the confusion matrix,Line indicates the actual category,Forecast column represents determine the category of the.在362个测试样本中,Actually belongs to the1类的有75个,By determining the results,75个样本中,有57A judge right,14A mistake as the first2类,3A mistake as the first3类.And the matrix of the diagonal elements on the sum of120,也就是说120A sample was sentenced to the wrong,Error rate will be calculated to,为0.33=120/362.
其中,属于第3The number of samples were wrong points up class,共有31个(Accounts for about half of the total)Classification by mistake.这之中有17A is wrong points into categories2,13Divided into the categories4.This may be due to category3与类别2、4The similarity between samples is too high,Performance to have larger overlap in the graphics area classification, as a result of difficult,As we have seen in the above,2、3、4Sample points of the three secondary rent amount together are inseparable.
Error rate can be calculated to evaluate the efficacy of the classification:
1 2 3 |
|

边栏推荐
- 箭头函数和普通函数的常见区别
- 1小时直播招募令:行业大咖干货分享,企业报名开启丨量子位·视点
- 位图与位运算
- The batch size does not have to be a power of 2!The latest conclusions of senior ML scholars
- 注释、关键字、标识符的区别你知道吗?
- Flutter Getting Started and Advanced Tour (3) Text Widgets
- The redis library cannot be imported
- Win10 compiles the x264 library (there are also generated lib files)
- ABP 6.0.0-rc.1的新特性
- WeChat Mini Program Payment and Refund Overall Process
猜你喜欢







随机推荐
数据挖掘-05
AI basketball referee, walking is special, ask harden care don't care
FFmpeg compiles and installs on win10 (configure libx264)
1小时直播招募令:行业大咖干货分享,企业报名开启丨量子位·视点
2022牛客多校(六)M. Z-Game on grid
Flutter入门进阶之旅(二)Hello Flutter
HAproxy:负载均衡
HAproxy: load balancing
26. Pipeline parameter substitution command xargs
00后写个暑假作业,被监控成这笔样
LeetCode #101. Symmetric Binary Tree
新起之秀 DPU,正在掀起数据中心变革!
Go-based web access parameters
Adalvo acquires its first branded product, Onsolis
Golang学习之路(五):Golang的函数
Flutter Getting Started and Advanced Tour (1) - Getting to Know Flutter
ABP 6.0.0-rc.1的新特性
腾讯发布第二代四足机器人Max,梅花桩上完成跳跃、空翻
Intra-group reverse order adjustment of K nodes
位图与位运算