当前位置:网站首页>Machine translation baseline
Machine translation baseline
2022-04-23 03:41:00 【Cooking code King】
1 Downloading and preprocessing datasets
# Guide pack
import os
import torch
from d2l import torch as d2l
D:\ana3\envs\nlp_prac\lib\site-packages\numpy\_distributor_init.py:32: UserWarning: loaded more than 1 DLL from .libs:
D:\ana3\envs\nlp_prac\lib\site-packages\numpy\.libs\libopenblas.IPBC74C7KURV7CB2PKT5Z5FNR3SIBV4J.gfortran-win_amd64.dll
D:\ana3\envs\nlp_prac\lib\site-packages\numpy\.libs\libopenblas.XWYDX2IKJW2NMTWSFYNGFUWKQU3LYTCZ.gfortran-win_amd64.dll
stacklevel=1)
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip',
'94646ad1522d915e7b0f9296181140edcf86a4f5')
#@save
def read_data_nmt():
""" load ⼊“ English - French ” Data sets """
data_dir = d2l.download_extract('fra-eng')
with open(os.path.join(data_dir, 'fra.txt'), 'r', encoding='utf-8') as f:
return f.read()
raw_text = read_data_nmt()
print(raw_text[:75])
# Download successful !
Downloading ..\data\fra-eng.zip from http://d2l-data.s3-accelerate.amazonaws.com/fra-eng.zip...
Go. Va !
Hi. Salut !
Run! Cours !
Run! Courez !
Who? Qui ?
Wow! Ça alors !
# Preprocessing
def preprocess_nmt(text):
def no_space(char, prev_char):
return char in set(',.!?') and prev_char != ' '
# Replace long spaces with spaces 、 Turn lowercase , xa0 Is an uninterrupted space
text =text.replace('\u202f', ' ').replace('\xa0', ' ').lower()
# Insert spaces between words and punctuation
out = [' ' + char if i > 0 and no_space(char, text[i-1]) else char
for i, char in enumerate(text)]
return ''.join(out)
text = preprocess_nmt(raw_text)
print(text[:80])
go . va !
hi . salut !
run ! cours !
run ! courez !
who ? qui ?
wow ! ça alors !
2 Word metabolization
# You can set the number of samples
def tokenize_nmt(text, num_examples = None):
source, target = [], []
for i, line in enumerate(text.split('\n')):
if num_examples and i > num_examples:
break
parts = line.split('\t')
if len(parts) == 2:
source.append(parts[0].split(' '))
target.append(parts[1].split(' '))
return source, target
source, target = tokenize_nmt(text)
source[:6], target[:6]
([['go', '.'],
['hi', '.'],
['run', '!'],
['run', '!'],
['who', '?'],
['wow', '!']],
[['va', '!'],
['salut', '!'],
['cours', '!'],
['courez', '!'],
['qui', '?'],
['ça', 'alors', '!']])
# Draw a histogram containing the number of words
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):
d2l.set_figsize(figsize=(5,3))
_, _, patches = d2l.plt.hist(
[[len(l) for l in xlist], [len(l) for l in ylist]])
d2l.plt.xlabel(xlabel)
d2l.plt.ylabel(ylabel)
for patch in patches[0].patches:
patch.set_hatch('\\')
for patch in patches[1].patches:
patch.set_hatch('/')
d2l.plt.legend(legend)
show_list_len_pair_hist(['source', 'target'], '# tokens per sequence',
'count', source, target)

3 Building a vocabulary , Add various morphemes
# Building a vocabulary , Add various morphemes
src_vocab = d2l.Vocab(source, min_freq=2, reserved_tokens = ['<pad>', '<bos>', '<eos>'])
len(src_vocab)
10012
# test
src_vocab['hello'], src_vocab.to_tokens(1807)
(1807, 'hello')
4 Load data set , Cut or fill
# Cut and fill
def truncate_pad(line, num_steps, padding_token):
if len(line) > num_steps: # truncation
return line[:num_steps]
return line + [padding_token] * (num_steps - len(line))
truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>'])
[47, 4, 1, 1, 1, 1, 1, 1, 1, 1]
# Build small batch datasets
def build_array_nmt(lines, vocab, num_steps):
lines = [vocab[l] for l in lines]
lines = [l + [vocab['<eos>']] for l in lines]
array = torch.tensor([truncate_pad(
l, num_steps, vocab['<pad>']) for l in lines])
# It's a clever way to calculate the length
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)
return array, valid_len
5 Construct data iterators
def load_data_nmt(batch_size, num_steps, num_examples=600):
text = preprocess_nmt(read_data_nmt()) # Text preprocessing
source, target = tokenize_nmt(text, num_examples) # Generate sequence pairs
# Construct a Thesaurus
src_vocab = d2l.Vocab(source, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
tgt_vocab = d2l.Vocab(target, min_freq=2,
reserved_tokens=['<pad>', '<bos>', '<eos>'])
# Construct small batch data
src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)
tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)
data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
data_iter = d2l.load_array(data_arrays, batch_size)
# Data iterators , Thesaurus
return data_iter, src_vocab, tgt_vocab
# Read out the first small batch of data
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for x, x_valid_len, y, y_valid_len in train_iter:
print('x: ', x.type(torch.int32))
print('x The effective length of :', x_valid_len)
print('y: ', y.type(torch.int32))
print('y The effective length of :', y_valid_len)
break
x: tensor([[ 90, 19, 4, 3, 1, 1, 1, 1],
[136, 15, 4, 3, 1, 1, 1, 1]], dtype=torch.int32)
x The effective length of : tensor([4, 4])
y: tensor([[ 0, 12, 5, 3, 1, 1, 1, 1],
[ 0, 5, 3, 1, 1, 1, 1, 1]], dtype=torch.int32)
y The effective length of : tensor([4, 3])
6 Encoder decoder architecture

6.1 Encoder
from torch import nn
class Encoder(nn.Module):
""" Basic encoder interface """
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, x, *args):
raise NotImplementedError
6.2 decoder
class Decoder(nn.Module):
""" Basic encoder interface """
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, x, state):
raise NotImplementedError
6.3 Merge encoder and decoder
class EncoderDecoder(nn.Module):
""" Encoder - Base class of decoder architecture """
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_x, dec_x, *args):
enc_outputs = self.encoder(enc_x, *args) # Pour in data and other parameters
dec_state = self.decoder.init_state(enc_outputs, *args) # The thought vector is fed into the decoder
return self.decoder(dec_x, dec_state)
7 seq2seq Model

7.1 Encoder
import collections
import math
import torch
from torch import nn
from d2l import torch as d2l
class Seq2SeqEncoder(d2l.Encoder):
"""Seq2Seq Of RNN Encoder """
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# Embedded layer
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
def forward(self, x, *args):
# Output x The shape of the :batch_size, num_steps, embed_size
x = self.embedding(x)
# rnn in , The first axis is the time step
x = x.permute(1, 0, 2)
# The initial default state is 0
output, state = self.rnn(x)
# output dimension : (num_steps, batch_size, num_hiddens)
# state[0] The shape of the :(num_layers, batch_size, num_hiddens)
return output, state
# Instantiate the above encoder Dictionary size Word vector dimension Number of hidden layer units Encoder layers ( Number of hidden layers )
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
encoder.eval()
x = torch.zeros((4, 7), dtype=torch.long) # 4 A length of 7 Sentences , Batch size 、 Time step
output, state = encoder(x)
output.shape
torch.Size([7, 4, 16])
state.shape
torch.Size([2, 4, 16])
7.2 decoder
class Seq2SeqDecoder(d2l.Decoder):
""" be used for Seq2Seq Study of the rnn decoder """
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers, dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, x, state):
# x Dimensions :batch_size, num_steps, embed_size
x = self.embedding(x).permute(1, 0, 2)
# radio broadcast context, Make with x Systematic num_steps
context = state[-1].repeat(x.shape[0], 1, 1)
x_and_context = torch.cat((x, context), 2)
output, state = self.rnn(x_and_context, state)
output = self.dense(output).permute(1, 0, 2) # Change back
# output dimension : batch_size, num_steps, vocab_size
# state[0] dimension :num_layers, batch_size, num_hiddens
return output, state
# Instantiate the decoder
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16, num_layers=2)
decoder.eval()
state = decoder.init_state(encoder(x))
output, state = decoder(x, state)
output.shape, state.shape
(torch.Size([4, 7, 10]), torch.Size([2, 4, 16]))

7.3 Loss function
# First, shield irrelevant items
def sequence_mask(x, valid_len, value=0):
""" Mask irrelevant items in the sequence """
maxlen = x.size(1) # This determines that the length of the second dimension is always manipulated !!
# print(maxlen)
mask = torch.arange((maxlen), dtype=torch.float32,
device=x.device)[None, :] < valid_len[:, None]
# Improve one dimension on the row dimension , Promote a dimension on the column dimension
# print(torch.arange((maxlen), dtype=torch.float32,
# device=x.device)[None, :])
# print(mask, ~mask, sep='\n')
# print(valid_len[:, None])
x[~mask] = value # hold 0 Give items that need to be shielded
return x
# test
x = torch.tensor([[1, 2, 3], [4, 5, 6]])
sequence_mask(x, torch.tensor([1, 2]))
tensor([[1, 0, 0],
[4, 5, 0]])
# Test broadcast
torch.tensor([[0., 1., 2.]]) < torch.tensor([[1],
[2]])
~torch.tensor([[True, True, False]])
tensor([[False, False, True]])
# Shield all items on the last few axes ; You can also specify non-zero values to replace these items
x = torch.ones(2, 3, 4)
sequence_mask(x, torch.tensor([1, 2]), value=-1) # The front in the second dimension 1 And the former 2 Item reserved
tensor([[[ 1., 1., 1., 1.],
[-1., -1., -1., -1.],
[-1., -1., -1., -1.]],
[[ 1., 1., 1., 1.],
[ 1., 1., 1., 1.],
[-1., -1., -1., -1.]]])
# Calculate the final cross entropy loss ( Shielding irrelevant predictions )
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
# pred shape :batch_size, num_steps, vocab_size
# label: batch_size, num_steps ( In fact, that is batch_size A sentence , Each sentence is... Long num_steps)
# valid_len:batch_size ( The length of each sentence )
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction = 'none'
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
pred.permute(0, 2, 1), label)
weighted_loss = (unweighted_loss * weights).mean(dim=1)
return weighted_loss
# test
loss = MaskedSoftmaxCELoss()
loss(torch.ones(3, 4, 10), torch.ones((3, 4), dtype=torch.long), torch.tensor([4, 2, 0]))
tensor([2.3026, 1.1513, 0.0000])
7.4 Training
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
""" Training seq2seq Model """
# xavier Initialization weight
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if 'weight' in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights) # Initialize network parameters
net.to(device) # Use gpu Training
optimizer = torch.optim.Adam(net.parameters(), lr=lr) # Use adam Optimize network parameters , Pour in the learning rate
loss = MaskedSoftmaxCELoss() # Create a loss function
net.train() # Network training mode
animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[10, num_epochs]) # Print data
# Train in rounds
for epoch in range(num_epochs):
timer = d2l.Timer() # timer
metric = d2l.Accumulator(2) # The sum of training losses , Number of lexical elements
for batch in data_iter: # Batch data training
optimizer.zero_grad() # The optimizer gradient is set to 0
x, x_valid_len, y, y_valid_len = [x.to(device) for x in batch] # Obtain this small batch data
bos = torch.tensor([tgt_vocab['<bos>']] * y.shape[0], # Add the start tag
device=device).reshape(-1, 1)
dec_input = torch.cat([bos, y[:, :-1]], 1) # Compulsory teaching teacher forcing, Add the start tag and the original output sequence
y_hat, _ = net(x, dec_input, x_valid_len) # Input into the network , Obtain the predicted value
l = loss(y_hat, y, y_valid_len) # Calculate the loss
l.sum().backward() # Scalar of the loss function “ Back propagation ”
d2l.grad_clipping(net, 1) # Prevent gradient explosions
num_tokens = y_valid_len.sum() # Total number of words in the tag
optimizer.step() # Optimizer optimization
with torch.no_grad():
metric.add(l.sum(), num_tokens) # Total losses , Total number of morphemes
# drawing
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0]) / metric[1], ) # Calculate the average loss
print(f'loss {
metric[0] / metric[1]:.3f}, {
metric[1] / timer.stop():.1f} '
f'tokens / sec on {
str(device)}')
# On the machine translation dataset , Create and train a rnn“ Encoder - decoder ” Model is used to Seq2Seq Learning from
# Initialize parameters
embed_size, num_hiddens, num_layers, dropout = 64, 64, 2, 0.3
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 500, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size, num_steps) # Load data and Thesaurus
# Construct a network model
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
# Training
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
loss 0.019, 17781.7 tokens / sec on cuda:0
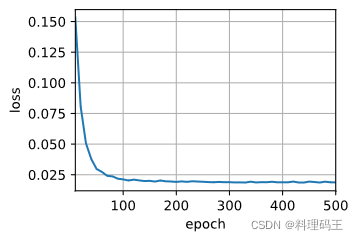
## Save the model
torch.save(net, 'mt_model_gru1.pth')
7.5 forecast
# seq2seq The prediction of the model
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps, device,
save_attention_weights=False):
# Prediction time , Set up net For the evaluation model
net.eval()
# Change the original sentence to tokens
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [src_vocab['<eos>']]
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
# use pad completion
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# Add batch axis
enc_x = torch.unsqueeze(torch.tensor(src_tokens, dtype=torch.long, device=device), dim=0)
# Calculate the thought vector
enc_outputs = net.encoder(enc_x, enc_valid_len)
# Initialize decoder with thought vector
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# Add batch axis
dec_x = torch.unsqueeze(torch.tensor([tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0)
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
# The decoder is filled with the initial word element <bos> And the decoder initialized by the thought vector
y, dec_state = net.decoder(dec_x, dec_state)
# Use the morpheme with the highest probability of prediction ( Greedy search ), As the input of the decoder in the next time step
dec_x = y.argmax(dim=2)
pred = dec_x.squeeze(dim=0).type(torch.int32).item() # Get this scalar
# Save attention weight
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# Once the sequence ends, the word element is predicted , The generation of the output sequence is completed
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred) # Will predict each time token Add the output sequence
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
7.6 Evaluation of prediction sequence ——BLEU indicators

- The first half is the penalty coefficient , Punish short prediction sequences
- The second half is accuracy
def bleu(pred_seq, label_seq, k): # Add up to k element
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred)) # Calculate penalty term
# Cycle statistics n Yuan accuracy , Use a dictionary to achieve
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1
label_subs[' '.join(pred_tokens[i: i + n])] -= 1
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
# test bleu final result
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device)
print(f'{
eng} => {
translation}, bleu {
bleu(translation, fra, k=2):.3f}')
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est mouillé ., bleu 0.658
i'm home . => je suis chez <unk> ., bleu 0.752
版权声明
本文为[Cooking code King]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204220601196567.html
边栏推荐
- 抽象类、接口、常用关键字
- 2022 团体程序设计天梯赛 模拟赛 L2-3 浪漫侧影 (25 分)
- A hundred dollars for a hundred chickens
- 2022 团体程序设计天梯赛 模拟赛 L1-7 矩阵列平移 (20 分)
- Initial experience of talent plan learning camp: communication + adhering to the only way to learn open source collaborative courses
- Test questions (2)
- Punch in: 4.23 C language chapter - (1) first knowledge of C language - (12) structure
- Abstract classes, interfaces and common keywords
- Unity games and related interview questions
- JS takes out the same elements in two arrays
猜你喜欢
Development record of primary sensitive word detection

Wechat applet cloud database value assignment to array error

Software testing process

51 single chip microcomputer: D / a digital to analog conversion experiment
Installation and configuration of clion under win10

Design and implementation of redis (1): understand data structures and objects
Photoshop installation under win10

What if you encounter symbols you don't know in mathematical formulas

Redis(17) -- Redis缓存相关问题解决

ROS series (IV): ROS communication mechanism series (3): parameter server
随机推荐
Applet - WXS
Definition format of array
Oracle JDK vs OpenJDK
Paddlepaddle does not support arm64 architecture.
Redis (17) -- redis cache related problem solving
Definition, understanding and calculation of significant figures in numerical analysis
The content of the website is prohibited from copying, pasting and saving as JS code
Design and implementation of redis (3): persistence strategy RDB, AOF
SQL learning record
Idea debug debugging tutorial
ROS series (III): introduction to ROS architecture
List interface of collection
Three column layout (fixed width on both sides in the middle and fixed width on both sides in the middle)
Common exceptions
Laboratory safety examination
Picture synthesis video
Use the thread factory to set the thread name in the thread pool
Unity basics 2
Common auxiliary classes
VS Studio 修改C语言scanf等报错