当前位置:网站首页>友邦人寿可观测体系设计与落地
友邦人寿可观测体系设计与落地
2022-08-10 12:17:00 【InfoQ】
业务场景与挑战
业务特点和架构
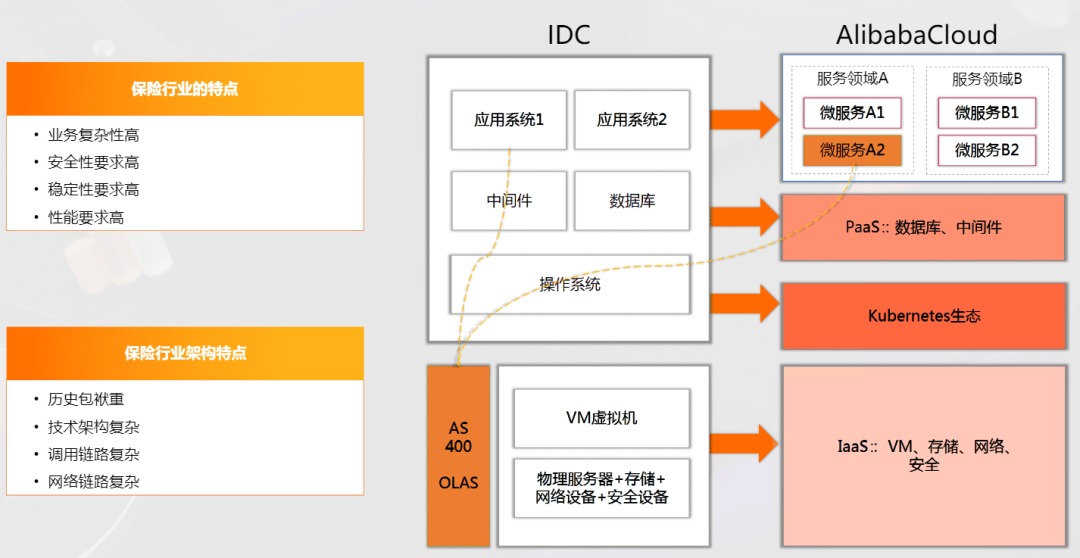
可观测性建设痛点和挑战

- 观测复杂度提升:云原生微服务化虽然带来了很高的 HA,但也提升了系统的复杂度,加大了可观测的难度。核保通过率、交单成功率、用户的日活/月活散落在各个业务模块里,业务需要提供全局视角,以观察整个保单生命周期里重要业务节点的运行情况,并获取研发态的具体情况。
- 技术选型困难:由于历史原因,友邦内部应用技术选型不一,版本各异,导致可观测技术和调用链追踪面临很大的困难。
- 统一观测困难:友邦是一家金融公司,开发系统和应用运维完全分开,日志也完全分开存储和维护,因此无法将以上数据在同一个大盘里呈现。
- 指标治理:IaaS层、PaaS 层和应用层有很多指标,单数据库方面就可能有超过 200 多个指标。如果希望指标达到比较容易理解与追踪的数量,则需要不断地进行回顾、删减。
- 快速故障定位:在 IDC 机房时代,没有直观的方式让应用查看自己的资源是否足够。虽然已经有商业 APM 工具,但其价格高昂,不属于经济有效的方式。问题发生时,因为只有少量应用安装了 APM ,所以调用链不完整,无法实现快速故障定位。
可观测性建设流程和规划

- 服务资源追踪:可以将服务运行节点上的 CPU 内存、网络磁盘、 IO 应用指标进行聚合。问题发生时,能够轻松观察到异常指标。
- 提供服务 Top 视图:按照服务的调用量、请求耗时、热点排名,应用可以很方便获知哪些是热点 API、哪些 API 请求量较高等,可以更好地规划自身的服务资源。
- 调用链追踪:关联服务上下游,并且最好是无侵入式,可以很方面地从 Trace关联到日志,获取到链路问题所在。
- 调用时长分布:观察服务的上游与下游,观察异步耗时,请求慢时可以很方便地判断是服务资源耗时还是依赖服务资源耗时。
- 数据库关联操作:帮助应用观察到 API 的关联 SQL、慢 SQL、 Redis 的查询存在慢 key 查询 、Mongo 存在慢查询等操作。
实践与落地
可观测性整体设计思路
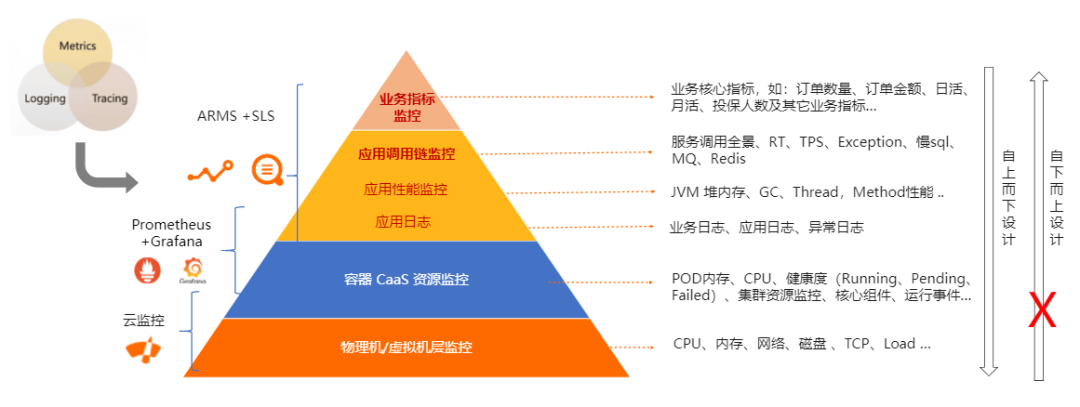
全生命周期监控指标设计

可观测性架构大图

统一监控平台

关于可观测性咨询服务

边栏推荐
- 【集合】HashSet和ArrayList的查找Contains()时间复杂度
- phpstrom 快速注释:
- mSystems | 中农汪杰组揭示影响土壤“塑料际”微生物群落的机制
- Twikoo腾讯云函数部署转移到私有部署
- Keithley DMM7510 accurate measurement of ultra-low power consumption equipment all kinds of operation mode power consumption
- Jenkins修改端口号, jenkins容器修改默认端口号
- Overview of Loudi Petrochemical Experiment Design and Construction Planning
- IP地址分类以及网络地址的计算(子网划分、超网划分)[通俗易懂]
- Guo Jingjing's personal chess teaching, the good guy is a robot
- 基础 | batchnorm原理及代码详解
猜你喜欢

Reversing words in a string in LeetCode

G1和CMS的三色标记法及漏标问题
Ethernet channel 以太信道

StarRocks on AWS 回顾 | Data Everywhere 系列活动深圳站圆满结束
![ArcMAP has a problem of -15 and cannot be accessed [Provide your license server administrator with the following information:Err-15]](/img/da/b49d7ba845c351cefc4efc174de995.png)
ArcMAP has a problem of -15 and cannot be accessed [Provide your license server administrator with the following information:Err-15]

解决 idea 单元测试不能使用Scanner

DNS欺骗-教程详解

如何培养ui设计师的设计思维?

Chapter9 : De Novo Molecular Design with Chemical Language Models

2022年8月中国数据库排行榜:openGauss重夺榜眼,PolarDB反超人大金仓
随机推荐
Detailed explanation of es6-promise object
一文详解 implementation api embed
AtCoder Beginner Contest 077 D - Small Multiple
odps sql 不支持 unsupported feature CREATE TEMPORARY
神经网络学习-正则化
神经网络可视化有3D版本了,美到沦陷!(已开源)
郭晶晶家的象棋私教,好家伙是个机器人
Loudi Cosmetics Laboratory Construction Planning Concept
如何培养ui设计师的设计思维?
【黑马早报】雷军称低谷期曾想转行开酒吧;拜登正式签署芯片法案;软银二季度巨亏230亿美元;北京市消协约谈每日优鲜...
九宫格抽奖动效
MySQL索引的B+树到底有多高?
Alibaba Cloud Jia Zhaohui: Cloud XR platform supports Bizhen Technology to present a virtual concert of national style sci-fi
shell:正则表达式及三剑客grep命令
wirshark 常用操作及 tcp 三次握手过程实例分析
关于flask中static_folder 和 static_url_path参数理解
LeetCode·297.二叉树的序列化与反序列化·DFS·BFS
LeetCode·每日一题·640.求解方程·模拟构造
交换机的基础知识
Nanodlp v2.2/v3.0 light curing circuit board, connection method of mechanical switch/photoelectric switch/proximity switch and system state level setting