当前位置:网站首页>Learning Notes---Machine Learning
Learning Notes---Machine Learning
2022-08-09 07:05:00 【Anakin6174】
Take notes as you read,Occasionally turn it over and look at it to really grasp it;Otherwise it will be quickly forgotten(艾宾浩斯遗忘曲线).
1 集成学习
集成学习 (ensemble learning)通过构建并结合多个学习器来完成学习任务.
根据个体学习器的生成方式 ,集成学习方法大致可分为两大类:即个体学习器问存在强依赖关系、必须串行生成的序列化方法?以及个体学习器间不存在强依赖关系、可同时生成的并行化方法;前者的代表是 Boosting,后者的代表是 Bagging 和"随机森林" (Random Forest) .
Boosting 是一族可将弱学习器提升为强学习器的算法.这族算法的工作机制类似:先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器数目达到事先指定的值 T , 最终将这 T 个基学习器进行加权结合.Boosting 族算法最著名的代表是 AdaBoost .
Bagging与随机森林
欲得到泛化性能强的集成,集成中的个体学习器应尽可能相互独立;虽然"独立"在现实任务中无法做到,但可以设法使基学习器尽可能具有较大的差异.给定一个训练数据集,一种可能的做法是对训练样本进行采样,产生出若干个不同的子集,A tomb learner is then trained from each data subset.这样,由于训练数据不同,我们获得的基学习器可望具有比较大的差异.
Bagging基于自助采样法;给定包含 m 个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时该样本仍有可能被选中,这样,经过 m次随机采样操作,我们得到含 m 个样本的采样集,初始训练集中有的样本在采样集里多次出现,有的则从未出现.由式 (2.1)可知,初始训练集中约有 63.2%的样本出现在来样集中.
照这样,我们可采样出 T 个含 m 个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合.这就是 Bagging 的基本流程.在对预测输出进行结合时, Bagging 通常对分类任务使用简单投票法,对回归任务使用简单平均法.
自助采样过程还给 Bagging 带来了另一个优点:由于每个基学习器只使用了初始训练集中约 63.2% 的样本,剩下约 36.8% 的样本可用作验证集来对泛化性能进行"包外估计" .
随机森林(Random Forest,简称 RF)是 Bagging的一个扩展变体.在以决策树为基学习器构建 Bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择.具体来说,传统决策树在选择划分属性时是在当前结点的属性集合(假定有 d 个属性)中选择一个最优属性;而在RF 中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含 k 个属性的子集,Then again from this subset Choose an optimal attribute to use to divide. 这里的参数k 控制了 The degree of randomness introduced ;若令 k = d , Then the construction of the base decision tree and Traditional decision trees are the same;若令 k = 1 , It is to randomly select an attribute to use to divide ; 一般情况下,推荐值 k = log2 d[Breiman, 2001].
随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,这就使得最终集成的泛化性能可通过个体学习器之间差异度的增加而进一步提升.
2, How to do diversity enhancement?
In ensemble learning, it is necessary to effectively generate a large diversity of individual learners . Compared to simply training an individual learner directly with the initial data,如何增强多样性呢?一般思路是在学习过程中引入随机性,Common practice is mainly on data samples、 输入属性、输出表示 、 algorithm parameters
扰动 .
3,特征选择
作用:
1,The curse of dimensionality problem is often encountered in real-world tasks,If important features can be selected,Models are constructed on only a subset of features,Then the curse of dimensionality problem can be greatly alleviated;
2,去除不相关的特征往往会降低学习任务的难度,Like a detective solving a crime,若将纷繁复杂的因素抽丝剥茧,只留下关键因素,则真相往往更易看清.
3,Reduce the computational and storage overhead involved
选择过程:子集搜索 + 子集评价(Available information entropy gain)
Common feature selections fall into three broad categories:过滤式(filter)、包裹式(wrapper)、嵌入式(embedding);
过滤式方法先对数据集进行特征选择,然后再训练学习器,特征选择过程与后续学习器无关.这相当于先用特征选择过程对初始特征进行"过滤",再用过滤后的特征来训练模型.
Wrapped feature selection directly uses the performance of the final learner to be used as a feature-set evaluation criterion.换言之,包裹式特征选择的目的就是为给定学习器选择最有利于其性能、 "Tailored to do"的特征子集.
在过滤式和包裹式特征选择方法中,特征选择过程与学习器训练过程有明显的分别;与此不同,嵌入式特征选择是将特征选择过程与学习器训练过程融为一体,两者在同一个优化过程中完成,即在学习器训练过程中自动地进行了特征选择.
4 L1范式与L2范式


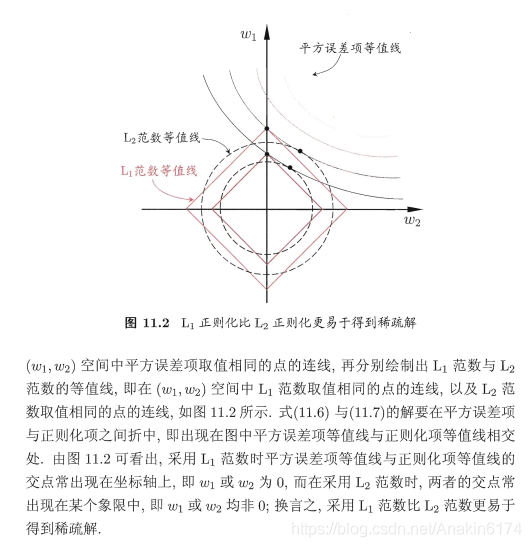
总的来说,L1与L2Both paradigms can reduce the risk of overfitting,但L1更容易获得稀疏解.
5 强化学习(Reinforcement Learning)简介
强化学习是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益.其灵感来源于心理学中的行为主义理论,即有机体如何在环境给予的奖励或惩罚的刺激下,逐步形成对刺激的预期,产生能获得最大利益的习惯性行为.(Get a strategy)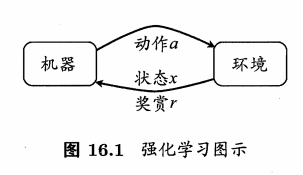
Reinforcement learning tasks usually use Markov decision processes (Markov Decision Process,简称 MDP)来描述:机器处于环境 E 中,状态空间为 X,其中每个状态 x 属于X ,是机器感知到的环境的描述,For example, in the task of planting melons, this is the description of the current growth of melon seedlings;机器能采取的动作构成了动作空间 A , Such as watering in the process of planting melons、Apply different fertilizers、Use different pesticides and many other actions to choose from;若某个动作 a属于A 作用在当前状态 x上,则潜在的转移函数 P will cause the environment to transition from the current state to another with some probability A个状态,Such as the state of melon seedlings for water shortage,If you choose action watering,The growth of the melon seedlings will change,The melon seedlings have a certain probability of recovery,There is also a certain probability that it cannot be recovered;在转移到另一个状态的同时,环境会根据潜在的"奖赏" (reward) 函数 R 反馈给机器一个奖赏,If you keep the melon seedlings healthy, you will be rewarded +1,Withered seedlings correspond to rewards-10,In the end, a good melon was planted with corresponding rewards +100. 综合起来,强化学习任务对应了四元组 E = (X,A,P,R),其中 P:X×A×X -->R 指定了状态转移概率 , R:X×A×X -->R 指定了奖赏;在有的应用中,奖赏函数可能仅与状态转移有关,即 R:X×X -->R .
需注意"机器"与"环境"的界限,For example in the watermelon quest,The environment is the natural world in which melons grow;in a chess game,The environment is the chessboard and opponents;in robot control,The environment is the body and physical world of the robot.总之,The transition of state in the environment、The return of the reward is not controlled by the machine,Machines can only affect the environment by choosing what actions to perform,The environment can also be perceived only by observing the state after the transition and the reward returned.
机器要做的是通过在环境中不断地尝试而学得一个"策略" (policy) π,根
According to this strategy,在状态 z 下就能得知要执行的动作 α= π(x) , 例如看到瓜苗状态是缺水时,能返回动作"浇水"策略有两种表示方法:The second is to express the policy as a functionπ :X -->A , 确定性策略常用这种表示;The other is the probability representation Ting :X×A–>R.,
随机性策略常用这种表示.π(x ,α) 为状态 x下选择动作 α 的概率;这里必须有∑π(x ,α)= 1 ;
强化学习在某种意义上可看作具有"延迟标记信息"的监督学习问题.
“K-摇臂赌博机”It can be seen as an example of one-step reinforcement learning.
在强化学习的经典任务设置中,机器所能获得的反馈信息仅有多步决策后的累积奖赏,但在现实任务中,往往能得到人类专家的决策过程范例,例如在种瓜任务上能得到农业专家的种植过程范例.从这样的范例中学习,称为"模仿学习" (imitation learning) .
深度强化学习全称是 Deep Reinforcement Learning(DRL),其所带来的推理能力 是智能的一个关键特征衡量,真正的让机器有了自我学习、自我思考的能力.深度强化学习(Deep Reinforcement Learning,DRL)本质上属于采用神经网络作为值函数估计器的一类方法,其主要优势在于它能够利用深度神经网络对状态特征进行自动抽取,避免了人工 定义状态特征带来的不准确性,make the agentAgent能够在更原始的状态上进行学习.
6 基于梯度的学习
线性模型和神经网络的最大区别,It is the nonlinearity of neural networks that makes most loss functions of interest non-convex.This means that the training of neural networks is usually iterative、基于梯度的优化,Just make the cost function reach a very small value;rather than a linear equation solver like the ones used to train linear regression models,Or for training logistic regression or SVMThe convex optimization algorithm has a global convergence guarantee.Convex optimization will converge from any initial parameter(理论上如此——Also robust in practice but may suffer from numerical issues).用于非凸损失函数的随机梯度下降没有这种收敛性保证,并且对参数的初始值很敏感.对于前馈神经网络,It is important to initialize all weight values to small random numbers.偏置可以初始化为零或者小的正值.训
Training algorithms are almost always based on various methods of using gradients to reduce the cost function.Some special algorithms are refinements and refinements of the idea of gradient descent.
An important aspect in deep neural network design is the choice of cost function.
A theme that runs through neural networks is that the gradient of the cost function must be sufficiently large and predictable,来为学习算法提供一个好的指引.饱和(become very flat)The function defeats this goal,Because they make the gradient very small.This happens in many situations,Because the activation function used to generate the output of the hidden unit or output unit will saturate.A negative log-likelihood helps us avoid this problem in many models.Many output cells will contain an exponential function,This can cause saturation when its variables take very large negative values.The log function in the negative log-likelihood cost function removes exponential effects in some output cells.
边栏推荐
猜你喜欢
错误:为 repo ‘oracle_linux_repo‘ 下载元数据失败 : Cannot download repomd.xml: Cannot download repodata/repomd.
ByteDance Interview Questions: Mirror Binary Tree 2020

SAP ALV data export many of the bugs

细谈VR全景:数字营销时代的宠儿
jvm线程状态

Variable used in lambda expression should be final or effectively final报错解决方案

用tensorflow.keras模块化搭建神经网络模型
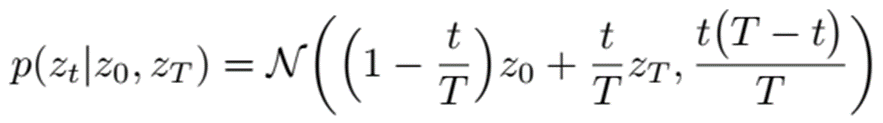
基于布朗运动的文本生成方法-LANGUAGE MODELING VIA STOCHASTIC PROCESSES
排序第二节——选择排序(选择排序+堆排序)(两个视频讲解)
搭载开源鸿蒙系统的嵌入式XM-RK3568工业互联方案
随机推荐
查看日志常用命令
jmeter并发数量以及压力机的一些限制
物理层课后作业
Thread Pool Summary
分布式理论
2017.10.26模拟 b energy
The water problem of leetcode
leetcode:55. 跳跃游戏
longest substring without repeating characters
Tkinter可以选择的颜色
类和结构体
2017icpc沈阳 G Infinite Fraction Path BFS+剪枝
分布式id 生成器实现
Quectel EC20 4G module dial related
排序第四节——归并排序(附有自己的视频讲解)
图论,二叉树,dfs,bfs,dp,最短路专题
HDU - 3183 A Magic Lamp Segment Tree
高项 04 项目变更管理
XxlJobConfig distributed timer task management XxlJob configuration class, replace
postgresql Window Functions