Application of deep learning methods in speech enhancement
Application of deep learning in speech enhancement
Press :
This article is about DNS,AEC,PLC And other organizers of international voice competitions ——Microsoft Research Labs Audio and acoustics research group (Audio and Acoustics Research Group) On 2021 Published in Sound capture and speech enhancement for speech-enabled devices An excerpt from , The work of this group in the field of speech enhancement this year is summarized . The author of the report is Ivan Tashev and Sebastian Braun. All pictures in this article are derived from the report and its citations .
1. ( Based on time-frequency domain supervised learning ) Speech enhancement module

This module mainly shows the process of time-frequency domain speech enhancement , Including short-time Fourier transform (STFT)、 feature extraction 、 neural network 、 Predict the goal 、 enhance / Transformation ( The process )、 Inverse short-time Fourier transform (iSTFT) And the loss function . Starting from the second line in the figure, it is only carried out in the training stage , This drawing suggests that A previous work of the group Map in ( See the picture below ) Use a combination of .
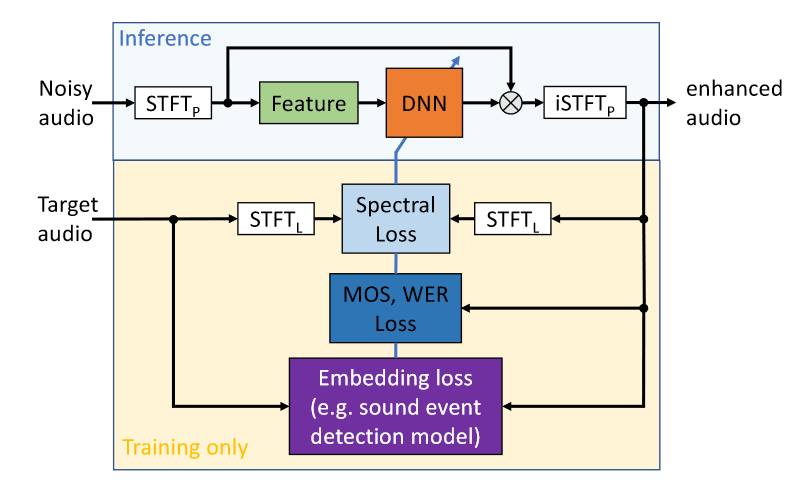
Here are the following points to discuss :
- STFT: Due to the diversity of noise modes, speech enhancement tasks are naturally different from speech separation tasks , Using Fourier transform basis function to transform noise and speech components into a specific space to distinguish patterns may be more conducive to the training and robustness of the network ; Besides , Due to the disadvantages of time-domain algorithm in reverberation and the possible cascade with traditional beamforming technology in array enhancement ; Of course, there are habits developed from traditional speech enhancement technology ; And most importantly , at present DNS Challenge The result of the game . Although there are some such as demucs And other excellent time-domain based speech enhancement algorithms , The speech enhancement algorithm based on time-frequency domain may have more advantages (tips: Here is my personal opinion ).
- feature extraction : In addition to the direct complex spectrum and amplitude spectrum , Microsoft specifically mentioned log power spectrum and ( Power law ) Compressed complex spectrum , Before describing these two features , Please note that there is no corresponding log amplitude spectrum or compressed complex spectrum for the prediction target in the report , It's primitive STFT Spectrum or masking of the domain , This is different from some previous literature corresponding to network output and input , What it wants to express is that the input is compressed and transformed ( Whether logarithmic compression or exponential compression ) The characteristics of will contribute to system performance .
Here is a brief description of the logarithmic power spectrum and ( Power law ) Compressed complex spectrum , The use of log amplitude spectrum is seen in the This article and This article , Defined as \(P = log10(|X(k, n)|^2)\)P = torch.log10(torch.norm(x_stft, dim=-1) + 1e-9);
The power-law compressed complex spectrum can be used for reference This article , Defined as \(X_{cprs}=\frac{X(k,n)}{|X(k,n)|}|X(k,n)|^{c}\)x_mag = torch.norm(x_stft, dim=-1) + 1e-9 x_cprs_mag = x_mag ** c x_cprs = torch.stack((x_stft[..., 0] / x_mag * x_cprs_mag, x_stft[..., 1] / x_mag * x_cprs_mag), dim=-1) - Loss function : The loss of compressed spectrum is recommended in the report , Other losses include mask Distance of 、 energy loss (SDR/SI-SDR)、 Spectral distance 、 Perceived weighted loss sum ( Of the above items or above items and others ) Joint losses .
Loss functions are defined and evaluated respectively in The literature and The literature in , Some of them are shown in the figure below
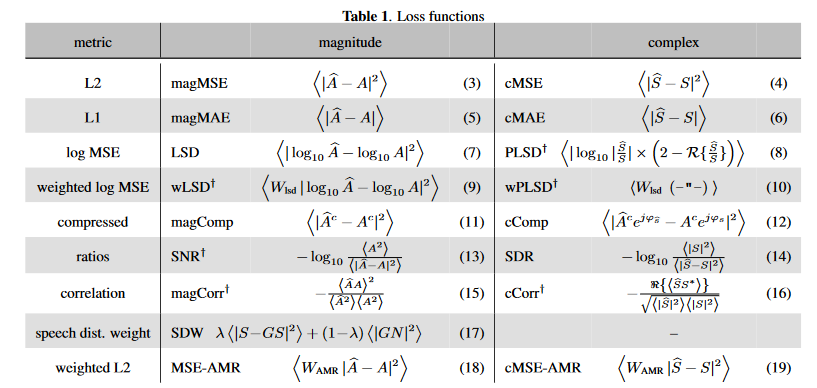
It is speculated that the compression spectrum loss with regular amplitude is recommended (Magnitude-regularized compressed spectral loss):\(\mathcal{L}=\frac{1}{\sigma_S^{c}}(\lambda\sum_{k,n}{|S^c-\widehat{S}^c|^2+(1-\lambda\sum_{k,n}{||S|^c-|\widehat{S}|^c|^2})})\), among \(\sigma_S\) It is the energy of pure voice with sound segment , The operation of compressed spectrum is consistent with the above definition ,\(c\) and \(\lambda\) Microsoft recommends 0.3.
2. Generation and expansion of training data

The data generation method recommended by Microsoft is shown in the figure above , Let's not consider reverberation , The energy of pure speech and noise are calculated respectively , The noisy data is obtained by mixing according to the signal-to-noise ratio , Then < Noisy data , Pure voice > Spectrum broadening with the same filter , Finally, adjust the dynamic range of voice volume. . It should be noted that :
- Clean the pure voice , choice MOS high , exclude “ dirty ” data
- Each is expected to be long enough ( Microsoft recommends 10s A word of , According to its evaluation, in its model 、 The characteristics and loss It should be at least longer than 5s, When conditions change, the shortest length of the sentence may also change )
- The signal-to-noise ratio recommended in the report is based on the mean 5 dB, variance 10 dB Random selection of Gaussian distribution
- The report recommends dBFS Increase the volume by average -28 dB, variance 10 dB Random selection of Gaussian distribution
- Spectrum enlargement refers to RNNoise Filter used in :\(H(z)=\frac{1+r_1z^{-1}+r_2z^{-2}}{1+r_3z^{-1}+r_4z^{-2}}\), among \(r_i\sim\mathcal{U}(-\frac{3}{8},\frac{3}{8})\). However, the literature cited in the report points out that due to the heavy amount of data , It is unnecessary to broaden the spectrum
Finally, consider the reverberation ( The green area in the picture ): Like other articles , Room impulse response (RIR) Convolution of pure speech to obtain reverberation speech . In order to make the voice sound natural , The target voice still has a small amount of reverberation , The specific implementation is to make the speech weighted by the weighting function RIR Convolution , The positioning of the weighting function is :\(w_{RIR}(t)=exp(-(t-t_0)\frac{6log(10)}{0.3}), if\quad t \ge t_0,(otherwise\quad w_{RIR}(t)=1)\)
3. Effective network architecture

Microsoft provides two network architectures , Respectively NSNet2(DNS Challenge Of baseline) and CRUSE(DNS Challenge Competition scheme submitted by China and Microsoft Microsoft-2).
The above two networks are RNNoise(by Valin)-style Amplitude spectral domain model and GCRN(by Tan)-style Complex spectral domain model ,RNNoise and GCRN It will be described in detail in a later blog , For an introduction to these two networks, see Blog and Blog Described in the . Finally, their results :