Overview of read write separation :
The read traffic is allocated to the slave node . This is a very good feature , If a business only needs to read data , Then we just need to connect one slave Read data from the machine .
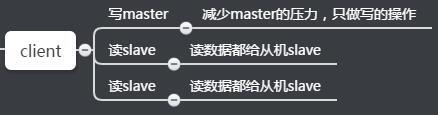
Although reading and writing have advantages , Be able to read this part Assign to each slave Slave , If not enough , Direct addition slave Just the machine . But there are also the following problems :
1、 Replication data delay
There may be slave Delays lead to inconsistent reading and writing , Of course, you can also use the monitor offset offset, If offset If it is out of range, switch to master On , Logic switching , And the specific delay , Can pass info replication Of offset Check the indicators .
For scenarios that cannot tolerate a lot of delays , You can write external monitoring programs ( such as consul) Listen for the copy offset of the master and slave nodes , When the delay is large, the alarm is triggered or the client is informed to avoid reading the slave node with high delay
Example : Simulate network latency ( Just write down the steps , No simulation and screenshot , If you are interested, try it yourself )
# Use redis Mirror creates a new redis From the node server ``docker run --privileged -itd --name redis-slave2 --net mynetwork -p 6390:6379 --ip 172.10.0.4 redis
notes :--privileged Give Way docker The container will have access to all devices of the host
adopt linux Flow control tool under , Simulate network latency , Use code to simulate , Because the operation on the network belongs to special permission, you need to add --privileged Parameters
# install linux Flow control tool under , Use it to simulate network latency ``yum ``install` `iproute
Configure delay 5s( second )
# Get into redis-slave2 Inside the container ``docker ``exec` `-itd redis-slave2 ``bash` `# Configure the network latency of this server 5 Second ``tc qdisc add dev eth0 root netem delay 5000ms` `# Then you can use swoole To check and view the results ` `# The command to delete the delayed network server is as follows :``tc qdisc del dev eth0 root netem delay 5000ms
Be careful : This configuration network delay should not be used indiscriminately .. Especially the production environment ......
At the same time, from the node of slave-serve-stale-data Parameters are also related to this , It controls the behavior of the slave node in this case : If yes( The default value is ), The slave node can still respond to the client's commands ; If no, The slave node can only respond to info、slaveof Wait for a few orders . The setting of this parameter is related to the application's requirements for data consistency ; If there is a high demand for data consistency , It should be set to no.
Only N Only when a slave node is linked can it be written :
Redis 2.8 in the future , You can set the master node only when there is N When the console is linked from the node, it can write the request . However , because Redis Using asynchronous replication , Therefore, there is no way to ensure that a given write request is actually received from the node , Therefore, there is a possibility of data loss in a window period .
The next step is to explain how this feature works :
The slave node will... Every second ping Master node , Tell it that all copy streams are working .
The master node will remember the latest... Received from each slave node ping
The user can configure the master node with a delay between the lowest value equal to the number of slave nodes and the highest value
If at least N Slave nodes , If less than delay M second , Then the write will be accepted .
You may feel that the best efforts to ensure data security mechanism , Although data consistency cannot be guaranteed , But data is lost in at least a few seconds . In general, range data loss is much better than no range data loss .
If the conditions are not met , The main node will return an error , And the write request will not be accepted
The host is configured with two parameters :min-slaves-to-write <number of slaves>min-slaves-max-lag <number of seconds>
How to choose , Do you want to separate reading and writing ?
There is no best plan , Only the most appropriate scene , Read write separation requires that the business can tolerate a certain degree of data inconsistency , It is suitable for business scenarios with more reading and less writing , Read / write separation , For what ? The main reason is to establish a master-slave architecture , In order to expand horizontally slave node To support greater read throughput .
2、 From the node failure problem
For the failure of the slave node , You need to maintain a list of available slave nodes on the client , When the slave node fails , Switch to another slave or master immediately .
3、 Inconsistent configuration
The master is different from the slave , It often leads to different configurations of the master and slave , And it brings problems .
①、 Data loss :
Sometimes the configuration of the master and the slave is inconsistent , for example maxmemory atypism , If the host is configured maxmemory by 8G, Slave slave Set to 4G, It can be used at this time , And it's not going to go wrong . But if you want to make high availability , When the slave node becomes the master node , You will find that the data has been lost , And it can't be undone .
4、 Avoid full replication
Full replication means when slave After the slave is disconnected and restarted ,runid Make a change that results in the need for master Copy all the data in the host . This process of copying all the data is very resource intensive .
Full replication is inevitable , For example, full replication is inevitable for the first time , At this point, we need to select the small master node , And maxmemory Don't be too big , It's going to be faster . At the same time, choose to do full replication at low peak time .
The reason for full replication :
①、 First, the operation of the master and slave machines runid Mismatch . Explain it. , If the master node restarts ,runid It's going to change . If you monitor from a node to runid Not the same , It will think that your node is not secure . When a fail over occurs , If the primary node fails , Then the slave will become the master node .****
②、 Insufficient copy buffer space , For example, the default value 1M, It can be partially copied . But if the cache is not big enough , First of all, you need a network outage , Partial replication cannot meet . Second, you need to increase the copy buffer configuration (relbacklogsize), Buffer enhancement to the network . Refer to the previous instructions .
****
How to solve it ?
In some scenarios , You may want to restart the primary node , For example, the memory fragmentation rate of the primary node is too high , Or you want to adjust some parameters that can only be adjusted at startup . If you use the normal method to restart the master node , Will make runid change , May lead to unnecessary full replication !****
To solve this problem ,Redis Provides debug reload How to restart : After restart , The master node runid and offset It's not affected , Avoid full replication .
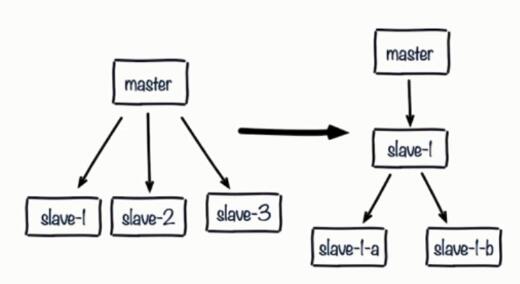
5、 Copy the storm
When a host has many slave From the plane , host master Hang up , At this time master After the host restarts , because runid There is a change , be-all slave The slave machine has to make a full copy . This will cause a replication storm of single node and single machine , It's going to be very expensive .
How to solve it ?
Tree structure can be used to reduce the consumption of master node by multiple slave nodes
Using a tree from a node is very useful , The network overhead is handed over to the slave nodes in the middle layer , You don't have to consume the top master node . But this kind of tree structure also brings the complexity of operation and maintenance , Increases the difficulty of handling failover manually and automatically .
6、 Single machine replication
because Redis The single thread architecture of , Usually a single machine will deploy multiple Redis example . When a machine (machine) Deploy multiple master nodes simultaneously on (master) when , If each master There's only one mainframe slave Slave , So when the machine goes down , There will be a lot of full replication . This is a very dangerous situation , Bandwidth is going to be taken up right away , It can lead to unavailability .

How to solve it ?
The master node should be spread over multiple machines as much as possible , Avoid deploying too many primary nodes on a single machine .****
When the host machine fails, it provides a fail over mechanism , Full replication after full volume recovery
版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231904213904.html