当前位置:网站首页>机器学习(六)——贝叶斯分类器
机器学习(六)——贝叶斯分类器
2022-04-23 09:03:00 【一大块肉松】
贝叶斯分类器是一类分类算法的总称,均以贝叶斯定理为理论基础
一、预备知识—贝叶斯决策论
1.公式
\qquad 贝叶斯决策论是概率框架下的实施决策的基本方法。对于分类任务来说,在所有相关概率都已知的理想情况下,贝叶斯决策论考虑如何基于概率和误判损失来选择最优的类别标记。
\qquad 假设有N种输出类别,表示为 y y y={ c 1 , c 2 , c 3 . . . . . c N c_1,c_2,c_3.....c_N c1,c2,c3.....cN}
\qquad λ i j \lambda_{ij} λij表示为将一个真实属于 c j c_j cj的样本误分类为 c i c_i ci产生的损失。
\qquad 则将样本 x x x分类为 c i c_i ci所产生的期望损失,即在样本 x x x上的“条件风险”为:
上述公式可以理解为:


要想实现正确的分类,则需要最小化期望损失,上述是单个样本的期望损失,则整体的损失期望为:
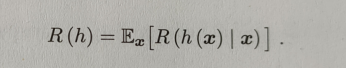
\qquad 根据上式可以得知,若对每个样本最小化条件风险,则整体的风险 R ( h ) R(h) R(h),也将被最小化。这就产生了贝叶斯判定准则:为最小化总体风险,只需在每个样本上选择那个能使条件风险 R ( c ∣ x ) R(c|x) R(c∣x)最小的类别标记。

h ∗ h^* h∗称为贝叶斯最优分类器。
2.最小化分类错误率
误判损失 λ i j \lambda_{ij} λij,设置为0/1损失函数:

此时条件风险:

上式由来:

于是最小化分类错误率的贝叶斯最优分类器为:

即对每个样本 x x x,选择能使后验概率 P ( c ∣ x ) P(c|x) P(c∣x)最大的类别标记
3.后验概率
\qquad 由以上讲解可知,要求得最小化决策风险,首先要获得后验概率 P ( c ∣ x ) 。 P(c|x)。 P(c∣x)。
\qquad 从这个角度来说,机器学习的所要完成的任务是基于有限的训练样本集尽可能准确的估计出后验概率 P ( c ∣ x ) P(c|x) P(c∣x),根据生成策略不同,分成了两大模型:
判别式模型
生成式模型
所谓的判别式模型,直接建模后验概率 P ( c ∣ x ) 。 P(c|x)。 P(c∣x)。
所谓的生成式模型,:对联合概率分布 P ( c , x ) P(c,x) P(c,x)建模,再得到后验概率 P ( c ∣ x ) 。 P(c|x)。 P(c∣x)。
生成式的模型:

基于贝叶斯定理可写成:

其中: P ( c ∣ x ) : 后 验 概 率 P(c|x):后验概率 P(c∣x):后验概率
P ( c ) : 先 验 概 率 P(c):先验概率 P(c):先验概率
P ( x ∣ c ) : 似 然 概 率 P(x|c):似然概率 P(x∣c):似然概率
二、极大似然估计
根据贝叶斯定理:

求最大后验概率 P ( c ∣ x ) P(c|x) P(c∣x)转化为求最大似然 P ( x ∣ c ) P(x|c) P(x∣c)。
\qquad 设训练集为 D D D
\qquad 第 c c c类的标签记为 θ c \theta_c θc
\qquad 记由第c类的标签组成的集合为 D c D_c Dc(个人理解 D c : D_c: Dc:就是指集合中哪些特征组合起来可以得到 θ c \theta_c θc类样本)
\qquad 假设这些样本都是独立同分布的,则参数 θ c \theta_c θc对于数据集 D c D_c Dc的似然是:
上式是连乘操作,容易造成下溢,通常使用对数似然:


三、朴素贝叶斯分类器
1.定义
朴素贝叶斯分类器采用了“属性条件独立性假设”:对已知类别,假设所有的属性相互独立。
根据属性条件独立性假设,可重写贝叶斯法则:
即求最大化:
令 D c D_c Dc 表示训练集 D D D中第c类样本组成的集合,根据独立同分布的性质可计算出先验概率 P ( c ) P(c) P(c):
令 D c , x i D_{c,x_i} Dc,xi 表示 D c D_c Dc中在第 i i i个属性上取值为 x i x_i xi的样本组成的集合,则条件概率 P ( x i ∣ c ) P(x_i|c) P(xi∣c):
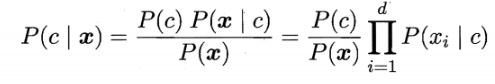



2.计算案例
为了避免其他属性携带的信息被训练集中未出现的属性值抹去,在估计概率时通常要进行“平滑“,常用”拉普拉多修正“。
四、半朴素贝叶斯分类器
在现实任务中,满足不了朴素贝叶斯所假设的属性条件独立,即很难成立。
由此半朴素贝叶斯分类器由此产生
\qquad 半朴素贝叶斯分类器的基本想法:适当考虑一部分属性间的相互依赖信息,从而既不需要进行完全概率联合计算,又不至于彻底忽略了比较强的属性依赖关系。
\qquad ”独依赖估计“(One-Dependent Estimation ,ODE)是半朴素贝叶斯分类器最常用的一种策略,也就是指假设每个属性在类别之外最多仅依赖于一个其他属性,即

不同的做法,可以产生不同的独依赖分类器:
SPORT
TAN
AODE
五、贝叶斯网
贝叶斯网刻画了所有属性之间所存在的依赖关系。
贝叶斯网,有称为“信念网”;
在现实任务中,贝叶斯网是未知的,需要我们根据训练集找出结构最恰当的贝叶斯网。
“评分搜索”是求解这个问题的常用方法。
\qquad 但是现实,是从训练集中搜索找到最优贝叶斯网结构是一个NP难问题,难以快速求解。
\qquad 有两种常用的策略能在有限的时间内求解近似解:
\qquad 第一种:贪心法,例如从某个网络结构出发,每次调整一条边,直到评分函数值不再降低为止;
\qquad 第二种:通过给网络结构施加约束来削减搜索空间,例如将网络结构限定为树形结构。
五、EM算法
\qquad 在前面的讨论中,我们一直假设训练样本所有属性变量的值都已被观测到,即训练样本是“完整”的。
\qquad 但在实际应用中往往会遇到“不完整”的训练样本,例如由于西瓜的根蒂已经脱落,无法看出是“蜷缩”还是“硬挺”,则训练样本的“根蒂”属性变量值未知,在这种存在”未观测“变量的情形下,是否仍然能对模型参数进行估计呢?
针对存在未知属性变量的现象,我们可以采用EM算法
EM算法是常用的估计参数隐变量的利器。
相比于之前的公式,多了 Z Z Z(隐变量集)

EM算法的基本思想:若参数 θ \theta θ已知,则可根据训练数据推断出最优隐变量 Z Z Z的值(E步);反之,若 Z Z Z已知,则可方便的对参数 θ \theta θ做极大似然估计。
六、学习资料
版权声明
本文为[一大块肉松]所创,转载请带上原文链接,感谢
https://blog.csdn.net/weixin_51547017/article/details/124336658
边栏推荐
- 搞不懂时间、时间戳、时区,快来看这篇
- About CIN, scanf and getline, getchar, CIN Mixed use of getline
- ONEFLOW learning notes: from functor to opexprinter
- valgrind和kcachegrind使用運行分析
- Go language self-study series | golang structure pointer
- Consensus Token:web3.0生态流量的超级入口
- LaTeX论文排版操作
- web页面如何渲染
- Talent Plan 学习营初体验:交流+坚持 开源协作课程学习的不二路径
- LeetCode_ DFS_ Medium_ 1254. Count the number of closed islands
猜你喜欢

Resource packaging dependency tree

cadence的工艺角仿真、蒙特卡洛仿真、PSRR

PLC point table (register address and point table definition) cracking detection scheme -- convenient for industrial Internet data acquisition

Experimental report on analysis of overflow vulnerability of assembly language and reverse engineering stack

Automatic differentiation and higher order derivative in deep learning framework

Brief steps to build a website / application using flash and H5
深度学习框架中的自动微分及高阶导数

Data visualization: use Excel to make radar chart

L2-022 重排链表 (25 分)(map+结构体模拟)

企业微信应用授权/静默登录
随机推荐
About CIN, scanf and getline, getchar, CIN Mixed use of getline
Go language self-study series | initialization of golang structure
Latex paper typesetting operation
How to read excel table to database
Experimental report on analysis of overflow vulnerability of assembly language and reverse engineering stack
Data visualization: use Excel to make radar chart
政务中台研究目的建设目标,建设意义,技术创新点,技术效果
MYCAT configuration
完全二叉搜索树 (30 分)
Idea package jar file
论文阅读《Multi-View Depth Estimation by Fusing Single-View Depth Probability with Multi-View Geometry》
Cadence process angle simulation, Monte Carlo simulation, PSRR
关于堆的判断 (25 分) 两种插入方式
Solidity 问题汇总
调包求得每个样本的k个邻居
The most concerned occupations after 00: civil servants ranked second. What was the first?
Introduction to GUI programming swing
npm报错 :operation not permitted, mkdir ‘C: \Program Files \node js \node_ cache _ cacache’
Notes d'apprentissage oneflow: de functor à opexprinterpreter
Failed to download esp32 program, prompting timeout