当前位置:网站首页>目标检测中mAP计算以及源码解析
目标检测中mAP计算以及源码解析
2022-08-09 02:35:00 【lp_oreo】
目标检测中mAP的计算很基础、很重要,当然经常被别人忽略。这位博主对mAP的分析也非常详细了,但是缺少对整个mAP代码的分析,我斗胆在这里简单分析一下目标检测中mAP的代码。本文的主要代码源自于这个github源码。
1. mAP的理论知识
1.1 交并比(Intersection Over Union, IoU)
交并比使用来衡量两个边界框的重叠程度。公式需要标注边界框 和预测边界框
和预测边界框 ,它可以用来判断当前检测的边界框是否有效。具体而言,当与之间的交并比大于交并比阈值的时候,我们将该次的预测边界框视为True Positive;反之,将其视为False Positive。换句话说,TP和FP与交并比有直接关系。交并比的计算公式等于和面积的交集与和面积的并集的之比:
,它可以用来判断当前检测的边界框是否有效。具体而言,当与之间的交并比大于交并比阈值的时候,我们将该次的预测边界框视为True Positive;反之,将其视为False Positive。换句话说,TP和FP与交并比有直接关系。交并比的计算公式等于和面积的交集与和面积的并集的之比:
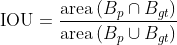
为了更清晰的表述交并比的公式,可以使用一幅图来表明它们之间的关系。其中,红色矩形表示检测的边界框,而绿色表示标注的边界框。
1.2 TP, FP, FN, TN
在计算mAP之前,需要了解下面四个衡量指标:
(1)True Positive (TP):表示一个正确的检测结果。在标注边界框附近存在预测边界框,并且预测边界框与标注边界框之间的IoU大于交并比阈值。
(2)False Positive (FP):表示一个错误的检测结果。在标注边界框附近存在预测边界框,但是预测边界框与标注边界框之间的IoU小于交并比阈值。
(3)False Negative(FN):表示在一个标注边界框附近,检测网络并没有输出预测值。换句话说,就是漏检了。
(4)True Negative(FN):计算mAP的时候,这个指标并不需要,因此就不再详细介绍。
1.3 查准率(Precision)和查全率(Recall)
查准率表示模型成功预测正样本的能力。它的计算公式如下:
![]()
查全率表示模型能够预测出正样本的能力。它的计算公式如下:
![]()
个人认为判断一个检测模型的性能,首先要求这个模型能够找到正样本,因此这就要求模型需要较高的查全率;其次需要模型对正样本的预测效果要好,因此在较高查全率的基础上查准率也要高。所以在下面mAP的计算中是查全率为横坐标,查准确为纵坐标进行mAP的计算。也即是说,查全率是前提,查准率是进阶能力。
1.4 平均精确率(Average Precision)
平均准确率(AP)是衡量目标检测器的一个性能指标,它可以根据P-R曲线与坐标轴所围成的面积计算得到。其中,P-R曲线表示在以查全率为横坐标,查准率为纵坐标的坐标系下,所绘制的曲线,具体绘制过程下面会详细介绍。其中计算AP值有两种方法,但是这边我只详细介绍其中一种,因为这个方法更为常用。该方法称为Interpolating all points(另一个方法称为11-point interpolation),该方法的公式为:
![]()
其中
![]()
上面的公式可能有些难懂,我们根据案例来进行分析。

这里有7张图像,15个标注的边界框和24个预测边界框。其中绿色矩形表示标注的边界框,而红色表示预测的边界框。为了更方便的引用,我们使用符号ABC等来依次指代每张图像中的预测边界框。下面的表格中汇总了每个边界框相应的置信度。我们根据置信度阈值等于0.3对每个预测边界框值都计算该边界框属于TP还是FP,我们将计算结果放在表格的最后一列。
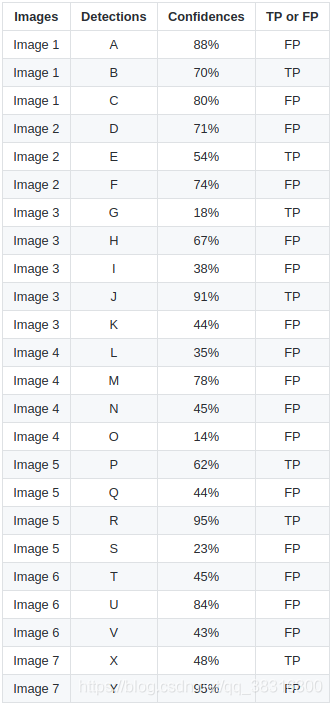
在某些图像中,一个标注的边界框存在多个预测结果(图2,3,4,5,6和7中都存在相似的情况)。对于这种情况,我们首先要去预测边界框的交并比大于交并比阈值,否则将其指定为FP;如果经过阈值处理之后依然存在多个检测结果,我们将置信度较大的设置为TP,其他的预测边界框指定为FP。比如图2中D和E边界框都是预测一个物体,但是D的交并比在0.2左右,小于阈值0.3,因此将其设置为FP。在这篇文章中说,选择交并比较大的那个指定为TP,可能值得商榷,因为源码中是将置信度大的指定为TP。
接着,我们需要根据预测边界框的置信度降序排序,得到重新排列后的结果。我们依次遍历每一个预测结果,计算目前为止所出现的TP以及FP出现的次数,将其记作为Acc TP和Acc FP,然后根据这两个指标得到Precision和Recall。计算结果如下表所示:

然后,我们根据每个(Recall, Precision)在P-R坐标系下描点绘图,而我们所关心的AP值就是下图中红色区域与坐标轴的面积。
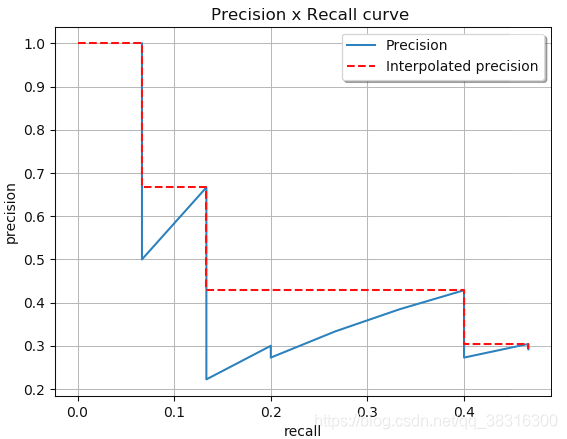
为了更准确的表示AP值所表示的区域,我们使用下面四个矩形区域的面积来说明AP所表示的面积:

因此AP值其实就是四个矩形面积之和:
![]()
每个矩形面积为以及AP值可以表示为:
![]()
![]()
![]()
![]()
![]()
![]()
![]()
2. 源码解析
假设数据集中一共有N个类别的物体,每一类对应的AP值分别为 。因此,该检测模型的mAP可以由下面公式计算得到:
。因此,该检测模型的mAP可以由下面公式计算得到:

因此,mAP的计算过程就是求每一类物体的AP值,然后求和取平均。下面简单叙述一下mAP的计算过程:
classes <- 所有类别标签的集合
rests <- 每一类precision和recall以及AP的值的集合
predicts <- 模型预测的所有结果
ground_truth <- 标注的所有结果
# 对每一类物体求AP
for cls in classes do:
preds <- precits中所有类别为cls的边界框信息
gts <- ground_truth中所有类别为cls的边界框信息
TP <- 长度为len(preds)的数组,并初始化为0
FP <- 长度为len(preds)的数组,并初始化为0
occupied <- 记录每个图像中n个gt是否被pred负责预测的词典
# 确定每一个pred是TP还是FP
for i, pred in enumerate(preds) do:
# 找到该pred与gts哪个边界框的IOU最大,将让该pred负责预测该gt,并保存该gt的索引
for j, gt in enumerate(gts) do:
jou = IOU(pred, gt)
jmax = j
# 当iou不小于阈值并且该边界框预测的gt没有被预测,将其设置为TP
if iou >= threshold and (occupied[cls][imax] == 0):
TP[i] = 1
else
FP[i] = 1
# 根据TP和FP求acc_TP和acc_FP
acc_TP = np.cumsum(TP)
acc_FP = np.cumsum(FP)
rec = acc_TP / len(gts)
prec = acc_TP / (acc_TP + acc_FP)
# 根据rec和prec求ap
ap <- CalculateAveragePrecision(rec, prec)
# 将每一类的ap保存在rests中
rests.append(ap)
其中ap的求解涉及到CalculateAveragePrecision函数的编写,在下面我会再详细的介绍一下。现在,对mAP计算的源码在进行仔细的剖析,分析其计算mAP的计算流程和思想。
2.0 函数的参数初始化
我们定义计算mAP的函数为GetPascalVOCMetrics,它接收三个形参,分别为预测和标注边界框(这两个不同的边界框在一个变量中表示)、IOU阈值和插值方法(因为mAP有两种计算方式,我们就默认使用上文讲的计算方法)。然后,我们需要初始化一些变量,用来作为计算的中间变量。
def GetPascalVOCMetrics(boundingboxes,
IOUThreshold=0.5,
method=MethodAveragePrecision.EveryPointInterpolation):
# 输出结果初始化为一个列表
ret = []
# List with all ground truths (Ex: [imageName,class,confidence=1, (bb coordinates XYX2Y2)])
# 存放标记的所有边界框(与下文的detections一起使用,用于求每个预测结果是TP还是FP)
groundTruths = []
# List with all detections (Ex: [imageName,class,confidence,(bb coordinates XYX2Y2)])
detections = []
# 存放该数据集中所有的类别(需要求每个类别的AP值)
classes = []
# 这段代码涉及到一些更加细节的问题,你可以将其视为从boundingboxes中获取gt和pred的边界框信息
# detections = [['00001', 'person', 0.88, (5.0, 67.0, 36.0, 115.0)],[],....]
# gt的值也类似,只不过第三列数据是0或者1,而不是小数
for bb in boundingboxes.getBoundingBoxes():
# [imageName, class, confidence, (bb coordinates XYX2Y2)]
if bb.getBBType() == BBType.GroundTruth:
groundTruths.append([
bb.getImageName(),
bb.getClassId(), 1,
bb.getAbsoluteBoundingBox(BBFormat.XYX2Y2)
])
else:
detections.append([
bb.getImageName(),
bb.getClassId(),
bb.getConfidence(),
bb.getAbsoluteBoundingBox(BBFormat.XYX2Y2)
])
# get class
if bb.getClassId() not in classes:
classes.append(bb.getClassId())
# 对类别进行排序
classes = sorted(classes)
...
return ret2.1 某一类的预测和标注边界框
下面需要求每一类物体的AP值。本节代码只需要放在这一行代码下面即可
...
classes = sorted(classes)我们需要从上文的detections和groundTruths中获得该类的所有预测的边界框和标注的边界框,并初始化TP和FP的值:
# 遍历每一个类别
for c in classes:
# 初始化此类的检测结果
dects = []
# 得到该类所有的检测结果
[dects.append(d) for d in detections if d[1] == c]
# 初始化此类的标注结果
gts = []
# 得到该类所有的ground truth
[gts.append(g) for g in groundTruths if g[1] == c]
# 得到标注边界框的数量,用于求recall
npos = len(gts)
# 将检测的结果根据检测的置信度降序排列
dects = sorted(dects, key=lambda conf: conf[2], reverse=True)
# 初始化TP和FP
TP = np.zeros(len(dects))
FP = np.zeros(len(dects))
# 样例:det = Counter({'00003': 3, '00001': 2, '00002': 2, '00004': 2, '00005': 2, '00006': 2, '00007': 2})
# 下面就是求每一幅图像中gt的数量,key表示图像名称,value表示该图像中n个gt的列表,用来表示该gt是否有predict用来预测。
det = Counter([cc[0] for cc in gts])
for key, val in det.items():
det[key] = np.zeros(val)2.2 求每个预测结果是TP还是FP
本节的代码只需要放在与上文代码的同缩进位置即可。这一部分的主要内容就是判断每个预测结果的编辑框到底是TP还是FP,我们可以遍历所有的预测结果。其中需要注意一个问题,我们怎么知道那个预测结果是预测哪个标注值?我们可以让该预测的边界框与该图像中所有的标注边界框挨个求交并比,预测结果与哪个标注的边界框的交并比最大,我们将认为该预测结果用来预测这个标注的边界框。
# 精确到该类在哪个图像中
for d in range(len(dects)):
# print('dect %s => %s' % (dects[d][0], dects[d][3],))
# Find ground truth image
# 将所有属于文件detect[d][0]图像的gt都保存下来
gt = [gt for gt in gts if gt[0] == dects[d][0]]
iouMax = sys.float_info.min
# 选择gt与当前预测值的边界框最大的交并比
for j in range(len(gt)):
# print('Ground truth gt => %s' % (gt[j][3],))
iou = Evaluator.iou(dects[d][3], gt[j][3])
if iou > iouMax:
iouMax = iou
jmax = j
# Assign detection as true positive/don't care/false positive
# 如果阈值
if iouMax >= IOUThreshold:
# 表示当前jmax个物体
if det[dects[d][0]][jmax] == 0:
TP[d] = 1 # count as true positive
# 表示这个gt已经有相应的prediction进行预测了
det[dects[d][0]][jmax] = 1 # flag as already 'seen'
# print("TP")
else:
FP[d] = 1 # count as false positive
# print("FP")
# - A detected "cat" is overlaped with a GT "cat" with IOU >= IOUThreshold.
# 假阴性
else:
FP[d] = 1 # count as false positive
# print("FP")2.3 求每一个类的AP值
经过上述代码求解之后,我们可以的得到FP和TP矩阵了,但是这和我们所需要的acc_FP和acc_TP还是很大的区别。下图表示我们求得到TP和FP:

而我们所需要的acc_FP和acc_TP的矩阵如下:

我们发现acc_FP和acc_TP其实就是FP和TP累加得到的结果,我们可以使用numpy中的cumsum函数得到:
acc_FP = np.cumsum(FP)
acc_TP = np.cumsum(TP)
rec = acc_TP / npos
prec = np.divide(acc_TP, (acc_FP + acc_TP))因此precision和recall的结果就为:

接下来,我们需要根据rec和prec求AP值。这时候我们就必须要仔细分析一下从P-R曲线计算AP的具体逻辑了:
下面总结一个规律:
(1)在rec数组中,其值是降序排列的,这是因为recall之和模型检测出来的TP数量有关,而TP数量只增不减。
(2)prec的值总体上呈现递减趋势,但是在中间可能会出现数值起伏的情况。
AP值就是四个矩形的面积,我们的目标就是如何将这四个矩形的面积给求出来。下面有三个主要步骤:
(1)对recall和precision数组进行扩充:recall需要扩充0和1坐标,因此precision的0和1坐标的坐标值就应该扩充为0。这样做是为了方便求出A1和A4矩形的面积。
(2)将precision数组中数据的分布由锯齿状趋势变成阶梯状趋势:这样做是是为了保证一个矩形中的precision的值是一样的(这在求ap值是会用到)
(3)找到recall数组中数据发生变化的数据索引:只用当recall中数据发生变化的时候,我们才计算矩形的面积。
def CalculateAveragePrecision(rec, prec):
# 对rec和prec数组进行前后数据的填充
mrec = []
mrec.append(0)
[mrec.append(e) for e in rec]
mrec.append(1)
mpre = []
mpre.append(0)
[mpre.append(e) for e in prec]
mpre.append(0)
# 切割矩形的高度
for i in range(len(mpre) - 1, 0, -1):
mpre[i - 1] = max(mpre[i - 1], mpre[i])
ii = []
# 找到每个矩形的分界点
for i in range(len(mrec) - 1):
if mrec[1:][i] != mrec[0:-1][i]:
ii.append(i + 1)
ap = 0
# 求每个矩形的面积
for i in ii:
ap = ap + np.sum((mrec[i] - mrec[i - 1]) * mpre[i])
# return [ap, mpre[1:len(mpre)-1], mrec[1:len(mpre)-1], ii]
return [ap, mpre[0:len(mpre) - 1], mrec[0:len(mpre) - 1], ii]2.4 mAP的计算
从上面的代码中,我们得到了每一类AP的相关值,我们只需要求和取平均就行了。
mAP = acc_AP / validClasses
mAP_str = "{0:.2f}%".format(mAP * 100)
print('mAP: %s' % mAP_str)
f.write('\n\n\nmAP: %s' % mAP_str)
边栏推荐
- JS 截取数组的最后几个元素
- Jenkins配置钉钉通知
- ApiFile配置环境
- 【AspNetCore】实现JWT(使用Microsoft.AspNetCore.Authentication.JwtBearer)
- 2020.12.4 log
- yii2的安装之路
- Duplicate class com.google.common.util.concurrent.ListenableFuture found in modules
- 从0开始搭建自动化测试框架之PO分层架构
- ROS 、SLAM 学习 error整理
- The most fierce "employee" in history, madly complaining about the billionaire boss Xiao Zha: So rich, he always wears the same clothes!
猜你喜欢

gpio子系统和pinctrl子系统(下)

How js implements array deduplication (7 kinds)

eladmin container deployment super detailed process

MT4/MQL4入门到精通外汇EA教程第一课 认识MetaEditor

【AspNetCore】实现JWT(使用Microsoft.AspNetCore.Authentication.JwtBearer)

高性能 MySQL(十二):分区表

uart_spi练习

online schema change and create index

Maya engine modeling

带你做接口测试从零到第一条用例 总结
随机推荐
【AspNetCore】实现JWT(使用Microsoft.AspNetCore.Authentication.JwtBearer)
OJ:L2-012 关于堆的判断
带你做接口测试从零到第一条用例 总结
2022 Eye Care Products Exhibition, Beijing Eye Health Exhibition, Ophthalmology Exhibition, Myopia Correction Equipment Exhibition
Analysis of when AuthenticationSuccessHandler is called after UsernameAuthenticationFilter is authorized successfully
数字 01 Vivado2018.2安装及实操
UsernameAuthenticationFilter授权成功后调用AuthenticationSuccessHandler时的解析
D. Tournament Countdown
Tricore架构上的调试案例
MT4/MQL4 Getting Started to Mastering EA Tutorial Lesson 1 - MQL Language Common Functions (1) OrderSend() Function
The security of the pension insurance?Reliable?
MT4/MQ4L入门到精通EA教程第二课-MQL语言常用函数(二)-账户信息常用功能函数
LintCode 146. 大小写转换 II
帮助安全红队取得成功的11条建议
Which is the best increased whole life insurance?Is it really safe?
科大讯飞笔试题复盘
Likou Brush Question Record--Common Functions
10.1-----19. Delete the Nth node from the bottom of the linked list
jmeter的websocket插件安装和使用方法
MySQL/Oracle字符串分割