当前位置:网站首页>Deep learning classic network analysis and target detection (I): r-cnn
Deep learning classic network analysis and target detection (I): r-cnn
2022-04-23 18:05:00 【Jsper0420】
Deep learning classical network analysis ( One ):R-CNN
- 1. Background introduction
- 2. object detection (Object Detection)
- 3.R-CNN
-
- 3.1 Traditional target detection
- 3.2 R-CNN And traditional target detection
- 3.3 R-CNN Target detection process
- 3.4 R-CNN Network architecture
- 3.5 Selective Search And R-CNN
- 3.6 IoU Occurring simultaneously than
- 3.7 Non maximum suppression NMS
- 3.8 Correction candidate area :BBox Regression
- 3.9 R-CNN Training
- 4. SPP-Net( Expand )
- 5. summary
R-CNN See my blog for details :
Deep study, thesis reading ( 7、 ... and ):R-CNN《Rich feature hierarchies for accurate object detection and semantic segmentation》
1. Background introduction
object detection (Object Detection) It is a kind of image segmentation based on target geometry and statistical features , It combines the segmentation and recognition of the target , Generally speaking, given a picture, it is necessary to accurately locate the position of the object , And complete the identification of object categories . Its accuracy and real-time performance is an important capability of the whole system .
After convolutional neural network is successfully applied to image classification ,2014 year ,Ross Girshick,Jeff Donahue And so forth R-CNN(Regions with CNN features) Method , And try to apply it to target detection . Before Szegedy They have tried to use deep convolution neural network to directly predict the target detection boundary box , Will position (localization) The problem is seen as a regression (regression) problem , But the effect is not very good , stay Pascal VOV 2007 There are only 30.5% The accuracy of the .R-CNN On this basis, it makes a reflection , Instead of simply looking at the problem as a regression model , Switch to sliding windows (sliding-window) Methods , And achieved 58.5% The accuracy of the .
R-CNN The full name is Region-CNN ( Regional convolution neural networks ), It is the first algorithm that successfully applies deep learning to target detection .R-CNN Based on Convolutional Neural Networks (CNN), Linear regression , And support vector machines (SVM) And so on , Realize target detection technology .
2. object detection (Object Detection)
Want to know R-CNN, Be sure to understand what target detection is ? Only understand the principle of target detection , Can understand R-CNN. In many technical fields of computer vision , object detection (Object Detection) It is also a very basic task , Image segmentation 、 Object tracking 、 Key point detection usually depends on target detection .
During target detection , Because of the number of objects in each image 、 Size and posture vary , That is, unstructured output , This is very different from image classification , And objects are often blocked , Therefore, object detection technology is also very challenging , Since its birth, it has always been one of the focus areas of research scholars .
In computer vision , Image classification 、 Target detection and image segmentation are the most basic 、 It is also the most rapidly developing 3 Fields , We can look at the difference between these tasks .
Image classification : The input image often contains only one object , The purpose is to determine what object each image is , It's an image level task , Relatively simple , The development is also the fastest .
object detection : There are often many objects in the input image , The purpose is to judge the position and category of the object , It is a very core task in computer vision . ·
Image segmentation : Input is similar to object detection , Determine which category each pixel belongs to , It belongs to pixel level classification . There are many connections between image segmentation and object detection tasks , Models can also learn from each other .
Object detection is an important application of deep learning , It is to identify the objects in the picture , And mark the position of the object , There are usually two steps :
1、 classification , What is object recognition

2、 location , Find out where the object is

In addition to detecting individual objects , It also supports the detection of multiple objects , As shown in the figure below :

This problem is not so easy to solve , Because the size of the object varies widely 、 The placement angle is changeable 、 The attitude is uncertain , And there are many kinds of objects , Many objects can appear in the picture 、 Appear anywhere . therefore , Target detection is a complex problem .
The most direct way is to build a deep neural network , Enter the sample and the image position as labels , And then pass by CNN The Internet , Then through a classification header (Classification head) The full connection layer identifies what objects are , Through a regression head (Regression head) Full connection layer regression calculation location , As shown in the figure below :

but “ Return to ” Not easy to do , Too much computation 、 Convergence time is too long , We should try to turn it into “ classification ”, At this time, it is easy to think of the idea of framing , That is, take different sizes of “ box ”, Let the box appear in a different position , Calculate the score of this box , Then get the box with the highest score as the prediction result , As shown in the figure below :

According to the score compared above , The black box in the lower right corner is selected as the prediction of the target position .
But the problem is : How big should the frame be ? Too small , Incomplete object recognition ; Too big , The recognition result has a lot of other information . What to do with that ? Then take boxes of all sizes and calculate them .
As shown in the figure below ( To identify a bear ), Use boxes of various sizes to repeatedly intercept in the picture , Input to CNN Identify and calculate the score , Finally determine the target category and location .

This method is inefficient , It's too time-consuming . Is there an efficient target detection method ?R-CNN Born in the sky
3.R-CNN
3.1 Traditional target detection
Traditional target detection methods are generally divided into three stages : First Select some candidate regions on a given image , then Extract features from these areas , Last Use the trained classifier for classification .

- Area selection
This step is to locate the target . The traditional method is to use exhaustive strategy . Because the target may be anywhere on the picture , The size is variable , therefore The strategy of sliding window is used to traverse the whole image , And you need to set different lengths and widths . Although this strategy can detect all possible locations , But the time complexity is too high , Too many redundant windows , It seriously affects the performance of subsequent feature extraction and classification speed .

- feature extraction
The quality of feature extraction will directly affect the accuracy of classification , However, due to the morphological diversity of targets , Extracting a robust feature is not a simple thing . The common features of this stage are SIFT( Scale invariant feature transformation ,Scale-invariant feature transform) and HOG( Directional gradient histogram feature ,Histogram of Oriented Gradient) etc. .
- classifier
Finally, the classifier , Often used classifiers include Adaboost,SVM,Decision Tree etc. . In many cases, a single classifier may not meet our requirements , Today, deep learning is used to complete various tasks , Especially when participating in various competitions , Definitely, I will Use different models and different inputs Ensemble. For example, we often use different cutting sub regions for prediction , Or use different benchmark models to predict , Finally, take the average probability, etc .
in summary , There are two main problems in traditional target detection : One is the region selection strategy based on sliding window There is no pertinence , High time complexity , Window redundancy ; Second, the characteristics of manual design There is no good robustness to diversity .
3.2 R-CNN And traditional target detection
R-CNN Compared with traditional target detection ,R-CNN Used CNN Network to extract features .
Supervised pre training with large samples + The small sample fine-tuning method solves the problems that small samples are difficult to train or even over fit ( In real tasks , Tagged data may be scarce )
3.3 R-CNN Target detection process
The flow is shown in the following figure :


- The first is the original picture , Then use some methods to generate some regions of interest on the original map , That is, the area that may contain the target (region proposals).
- Candidate regions to be generated resize To a fixed size ( Because the input of neural network is fixed , In fact, the input of convolution operation can not be fixed , The input size of the full connection layer is fixed , This is what the later models will improve ),
- take resize After the image is input into a CNN The Internet ( This network can be a ready-made model , Then fine tune ),CNN The network will extract feature vectors with fixed dimensions ( The original text uses AlexNet, Remove the last output layer , Extract 4096 Dimension characteristics , It is much less than the traditional way )
- Then input the extracted features to a group of pre trained SVM classifier ( Altogether k individual ,k That is, the total number of categories , Each is a binary classifier ), Identify the target in the area ( At the same time, it roughly locates the position of the target , The following content will refine the position , Make it more accurate .

In short :
- Given an input picture , Extract from the picture 2000 Category independent candidate areas .
- For each area use CNN Extract a fixed length feature vector .
- And then use... For each area SVM Target classification .
about R-CNN for :
-
Area selection
There are many ways to generate candidate regions , such as :objectness、selective search、category-independen object proposals、constrained parametric min-cuts(CPMC)、multi-scale combinatorial grouping、Ciresan.R-CNN It's using Selective Search Algorithm . -
feature extraction
R-CNN Took one of them 4096 The eigenvectors of the dimensions , It's using Alexnet. It should be noted that Alextnet The input image size of is 227x227. And by Selective Search The size of the candidate area is different , In order to Alexnet compatible ,R-CNN By very violent means , That's it Ignore the size and shape of the candidate area , Unity changes to 227*227 The size of the . There is a detail , stay Yes Region When you make a transformation , First, these areas are inflated , In its box It's surrounded by p Pixel , That is, the border has been added artificially , ad locum p=16. -
classifier
Object classifier ( A specific group SVM classifier ), How many categories , Just how many... You need to train SVM classifier , Each classifier determines whether the input is the corresponding category .
3.4 R-CNN Network architecture
R-CNN The network used is AlexNet, The pre training dataset is ILSVRC2013.
because AlexNet Appearance , The world's eyes return to the field of neural networks , Take this as an opportunity , There are all kinds of networks, such as VGG、GoogleNet、ResNet wait . suffer AlexNet inspire , The author of the paper tries to put AlexNet stay ImageNet The ability of target recognition is generalized to PASCAL VOC Target detection from above .

AlexNet Detailed explanation of the network , See my blog :
Deep learning classical network analysis ( Two ):AlexNet
3.5 Selective Search And R-CNN
The region selection process in traditional target detection methods uses the idea of exhaustive method rather than the method of generating candidate regions , Detect every sliding window , The information overlap of adjacent windows is high , The detection speed is slow , This leads to the judgment of a lot of invalid areas , An image of normal size can be easily raised more than 1 Million candidate areas . Is there any way to reduce the number of candidate areas ?
J. R. R. Uijlings stay 2012 It was proposed that selective search Method , This method actually uses the classical image segmentation method Graphcut, First, do the initial segmentation of the image , Then the segmentation results are filtered and merged by hierarchical grouping method , Finally output all possible positions , Narrow the candidate area to 2000 about .

say concretely , Firstly, the image is over segmented to obtain a set of regions composed of several equal regions S, This is an initialized set ;
Then use the color 、 texture 、 Features such as size and spatial overlap , Calculate the similarity in each adjacent region ; Find the two areas with the highest similarity , Merge them into a new set and delete the original two subsets from the area set . Repeat the above iterative process , Until the beginning of the collection S It's empty , The segmentation result of the image is obtained , Get the candidate region boundary , That is, the initial box .
stay R-CNN Use... In the framework Selective search Control the candidate area to 2000 about , The corresponding operation box will be zoomed , Send in CNN Training in , adopt SVM And a regressor to determine the category of the object and locate it . because CNN It has very strong nonlinear representation ability , Good feature learning can be carried out for each region , So the performance is greatly improved .
R-CNN Its main features are as follows :
Take advantage of selective search Method , That is, the image is segmented by instance Split into small pieces , then Select small blocks with high similarity , Put these Similar small pieces are combined into a large block , Last The whole object generates a large rectangular box , This method greatly improves the screening speed of candidate regions .
use stay ImageNet The parameters learned on the data set preprocess the neural network , The problem of insufficient labeled data in the process of target detection and training is solved .( Transfer learning )
The frame is calibrated by linear regression model , Reduce the background white space in the image , Get more accurate positioning .
This method will PASCAL VOC The detection rate on the is from 35.1% Promoted to 53.7%, Its significance and AlexNet stay 2012 The great breakthrough in classification task in is quite , It has a far-reaching impact on the field of target detection . however ,selective search The scheme still has the problem of too much calculation .
3.6 IoU Occurring simultaneously than
Target detection , There is a common indicator , It's called IoU(Intersection over Union), It is often used to Measure... In the target detection task , Accuracy of location information of prediction results .
In the subject of target detection , We need to get from the given picture , Guess what's in this picture ( Or what kind of ) thing , And speculate that ( Or these things ) The exact location of things in the picture . such as , In the picture below , We speculate that there is a STOP identification , And its inferred position is given ( The red box ).
however , The green box in the picture is STOP Identify the real location . There is a certain deviation in the position of the two boxes . that , How should we measure the size of this deviation ?

We usually use IoU(Intersection over Union) This indicator is used to measure the size of the deviation mentioned above .
IoU The calculation principle of is very simple :

In the language of set in Mathematics , That is, the of the two regions “ intersection ”, Divided by two regions “ Combine ”↓
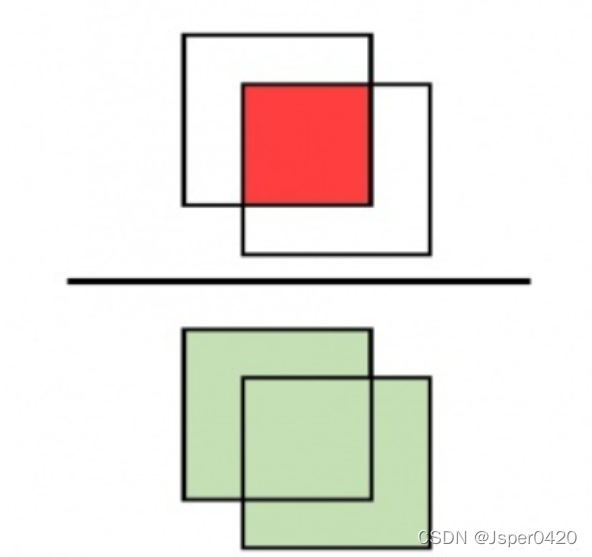
IoU The maximum value of is 1, At this time, the actual area of the object completely coincides with the inferred area ;IoU The minimum value of is 0, At this time, there is no overlap between the actual area of the object and the inferred area .
IoU In fact, it is a relatively strict evaluation index . The actual area deviates slightly from the inferred area , It's got to come out IoU The value of may also become quite small .
3.7 Non maximum suppression NMS
Previously said ,selective research Will produce 2k individual region proposals. after svm After scoring , An object may have multiple frames . Here's the picture :
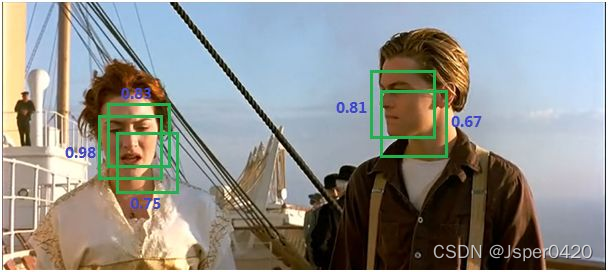
But we Need an object with only one optimal frame ( All frames relative to the same object , namely SVMs Select the best one from a column vector of the matrix obtained after scoring ). So using NMS To suppress redundant boxes , Get the result as shown in the figure below :

For example : An object finally gets A,B,C,D,E,F Six boxes , according to SVMs Scoring from high to low happens to be the same A,B,C,D,E,F. Pick the one with the highest score A, And then go through the rest ( The candidate set ), Calculate in sequence relative to A Of IOU, If IOU> threshold , Then discard the corresponding box ( for example :IOU(A,B)> threshold , Then abandon B), Otherwise, put back the candidate set . After traversing , If the candidate set still has elements and the number of elements is greater than 1, Continue to select the candidate with the highest score in the candidate set ( For example, the last round only abandoned B, The candidate set is C,D,E,F, So now the highest score is C), Then traverse the candidate set , Then calculate in turn ( ditto ), Know that there are no elements in the candidate set , Or there's only one element left . Then what remains is the optimal box .
In other words, there will still be multiple boxes , My understanding is that IOU> Just abandon , It eliminates the repeated occurrence of multiple boxes in the same area , But there may be multiple targets of the same type in a picture , For example, the above picture has two faces , The remaining multiple boxes are, to some extent, labeled multiple targets
3.8 Correction candidate area :BBox Regression
Remove redundant box Is not enough , Because of these box All generated by algorithms , And ground truth There must be a discrepancy , We hope these box As close as possible to ground truth. Such as below

Yellow is generated by the algorithm region proposal, Green is ground truth, We need to fine tune the yellow box , Make it close to the green box . So a set of BBox Repression( Each corresponds to a category ) To do this , Enter the original box , Predict a new box to approach ground truth. Because a box can be represented by four values (x,y,w,h) They are the abscissa of the center point of the frame , Ordinate of center point , wide , high .

We want to change the red box to the blue box ( Approach and ground truth, Retention pit : Why not just turn to the green box ). The conversion method is as follows :
G x ′ = A w ⋅ d x ( A ) + A x G y ′ = A h ⋅ d y ( A ) + A y \begin{aligned} &G_{x}^{\prime}=A_{w} \cdot d_{x}(A)+A_{x} \\ &G_{y}^{\prime}=A_{h} \cdot d_{y}(A)+A_{y} \end{aligned} Gx′=Aw⋅dx(A)+AxGy′=Ah⋅dy(A)+Ay
G w ′ = A w ⋅ exp ( d w ( A ) ) G h ′ = A h ⋅ exp ( d h ( A ) ) \begin{aligned} G_{w}^{\prime} &=A_{w} \cdot \exp \left(d_{w}(A)\right) \\ G_{h}^{\prime} &=A_{h} \cdot \exp \left(d_{h}(A)\right) \end{aligned} Gw′Gh′=Aw⋅exp(dw(A))=Ah⋅exp(dh(A))
You can see that you need to learn d x ( A ) , d y ( A ) , d w ( A ) , d h ( A ) d_{x}(A), d_{y}(A), d_{w}(A), d_{h}(A) dx(A),dy(A),dw(A),dh(A) Four changes ( Maybe a little confused , Go on Let's have a look ). We know that the real translation and zoom between the red box and the green box is :
t x = ( x − x a ) / w a , t y = ( y − y a ) / h a t W = log ( w / w a ) , t h = log ( h / h a ) \begin{aligned} t_{\mathrm{x}} &=\left(x-x_{\mathrm{a}}\right) / w_{\mathrm{a}}, \quad t_{\mathrm{y}}=\left(y-y_{\mathrm{a}}\right) / h_{\mathrm{a}} \\ t_{\mathrm{W}} &=\log \left(w / w_{\mathrm{a}}\right), \quad t_{\mathrm{h}}=\log \left(h / h_{\mathrm{a}}\right) \end{aligned} txtW=(x−xa)/wa,ty=(y−ya)/ha=log(w/wa),th=log(h/ha)
take t ∗ ( ∗ ⊂ x , y , w , h ) t_{*}(* \subset x, y, w, h) t∗(∗⊂x,y,w,h) Bring in the above four formulas , Replace d ∗ ( A ) d_{*}(A) d∗(A), Can you understand the above four changes 了 . Now we want to make d ∗ d_{*} d∗ As close as possible t ∗ t_{*} t∗ . At the same time region proposal And GT The difference is small , d ∗ d_{*} d∗ Can see Is a linear variation :
d ∗ ( A ) = w ∗ T ⋅ Φ ( A ) d_{*}(A)=w_{*}^{T} \cdot \Phi(A) d∗(A)=w∗T⋅Φ(A)
among ϕ ( A ) \phi(A) ϕ(A) Namely region proposal stay feature map Corresponding eigenvalues in .
How to measure t ∗ t_{*} t∗ and d ∗ d_{*} d∗ The gap between , That's definition Loss function :
Loss = ∑ i N ( t ∗ i − w ^ ∗ T ⋅ Φ ( A i ) ) 2 \operatorname{Loss}=\sum_{i}^{N}\left(t_{*}^{i}-\widehat{w}_{*}^{T} \cdot \Phi\left(A^{i}\right)\right)^{2} Loss=i∑N(t∗i−w
∗T⋅Φ(Ai))2
3.9 R-CNN Training
Supervised pre training : I said before R-CNN One place of innovation is Supervised pre training with large samples + Small sample fine-tuning solves the problem that small samples are difficult to train or even over fit Other questions . So we can directly use the existing trained network , Many deep learning libraries integrate some powerful network structures and trained weights , Just use it . Of course, you can also redesign the network structure , Then use a large data set to train . Note that there are also targets in this dataset bounding box Information , But in the pre training, only images are used label Information , That is, a classifier is trained here , It has nothing to do with positioning .
Fine tuning in specific areas : After pre training , We have a “ Super strong ” classifier ,AlexNet Yes 1000 Outputs , That is, you can distinguish 1000 Classes . But no matter how strong this classifier is , At present, it may not be very useful for our task . Because it has not seen the data style in a specific task . Therefore, you need to fine tune it with the data set in the task . Including parameters and structure .
According to the task , Change the output layer to N+1:N Categories , One more is the background . The so-called specific task in the original text is PASCAL VOC, Used PASCAL VOC 2010 Data set of , It only needs to distinguish 20 Categories
sample : Here is a IOU The concept of , If you don't know Baidu, you can know . Because there is often only one category in the sample data Bounding box(Ground Truth, That is, the target location information in the sample ), And by Selective search The algorithm produces region proposals Follow Ground Truth There must be a difference . You will now IOU>0.5 Of region proposals Label the corresponding category , Otherwise, put a background label , use one-hot code .
Parameter setting : The learning rate is set as the learning rate during pre training 1/10, Saying so will not destroy the initial . then mini-batch size=128, among 32 A positive sample ( Cover all classes ),96 Negative samples .
For example, now we need to make a traffic sign detection system , and ILSVRC2013 There are no pictures of the traffic signs in , But the tasks are similar , The features extracted from the bottom of the network are also universal to a certain extent , So add a new data set on the original basis , Let it have the ability to recognize traffic signals . The biggest advantage of this is that a better model can be obtained on a small sample . Because there are few sample data , If the initial value of the model is randomized , Then you may not get an ideal model .
Object classifier ( A specific group SVM classifier ): How many categories , Just how many... You need to train SVM classifier , Each classifier determines whether the input is the corresponding category . Positive sample :CNN Extracted ground truth Eigenvector of ; Negative sample :CNN Extracted IOU<0.3 Of region prosoals Eigenvector of .( Note that the definition of positive and negative samples here is better than CNN Strictly , And the input is CNN The extracted feature vector ) Because the number of negative samples is much more than that of positive samples , First, it will cause imbalance in proportion , Second, there are too many negative samples , It will cause pressure on external memory and memory . So we used hard negative mining. Be careful SVM Your training is separate , Because of the need to sum CNN Different samples during training , And you need to train first CNN To extract features .
When the above is done , We got it R-CNN Model ( You should also add NMS step ). This model can be well classified region proposals, At the same time, it also makes a general positioning of the target . But notice region proposals That's too much , And and ground truth There are differences , So we need to use the non maximum suppression method (NMS) Get rid of the excess region proposals And the use of BBox Regression To fix box The location of .
4. SPP-Net( Expand )
Even though RCNN By reducing candidate boxes, the amount of calculation is reduced , Take advantage of CNN Learning improves the ability of feature expression , But it still has two major flaws .SPPnet It is a paper that can not be ignored in the field of target detection , Works of he Kaiming, the great God , It feels much more friendly to read .
SPPnet There are two main highlights :
- It solves the deep convolution neural network (CNNs) The input of must require a fixed image size ( for example 224*224) The limitation of .
- In the field of target detection, it improves the efficiency of feature extraction , Speed compared to R-CNN promote 24-102 times .
4.1 R-CNN The problem is
1. Redundant computing
because R-CNN The way is for Mr. to become a candidate area , Then convolute the region , The candidate regions will overlap to a certain extent , because selective search The method is still not good enough , Lead to CNN Repeat convolution on the same region to extract features . and R-CNN Method stores the extracted features , Then use the traditional SVM Classifiers to classify , Resulting in the need for large storage space .
2. Scaling of candidate regions
because R-CNN Methods all regions were scaled to the same scale for network training , But actually selective search The selected target box has various sizes , This may cause the target to deform , Neither clipping nor scaling can solve this problem .
4.2 SPP-Net Innovation points
4.2.1 Let the input image of the network be of any size
SPP-Net Mainly for The second defect is to improve , The main idea is Removed the... From the original image crop/warp Wait for the operation , Instead, the spatial pyramid pooling layer on the convolution feature (Spatial Pyramid Pooling,SPP) The reason for scaling the image to a fixed scale , Because of the existence of the full connection layer . The input of the full connection layer needs a fixed size , So use Pictures of different sizes slice , Just The unified transformation must be carried out before entering the full connection layer . However, cutting or zooming directly will cause the loss of picture information , Sometimes Because the candidate box is too small, only some targets can be obtained , Make the information input into the neural network incomplete , Here's the picture .

Zooming after image clipping will lead to object deformation and distortion , It also affects the detection effect .

The basic structure of deep convolution neural network is divided into : Convolution layer (conv layers)-> Pooling layer (pooling layers)-> Fully connected layer (fc layers). When we were designing the network , The input dimension of the full connection layer must be fixed in advance . Push forward from the full connection layer , It is necessary to keep the input size of the first layer convolution fixed , for example 224 * 224(ImageNet)、32 * 32(LenNet) etc. . This requires us to check the picture , You need to pass the picture through crop( tailoring )、warp( The tensile ) And other operations to transform the picture into a fixed size , To input the neural network . These operations will lead to the loss or deformation of picture information to a certain extent . Regarding this SPPnet The proposed solution is to pool the layer with a spatial pyramid after the last layer of convolution layer (Spatial Pyramid Pooling) Instead of ordinary pool layer .
SPP The proposal can be made through A special pool layer ,Spatial Pyramid Pooling Layer to solve , It realizes the combination of the input characteristic map of any scale into the output of specific dimension , So as to remove the... On the original image crop/warp And so on .

Spatial Pyramid Pooling The characteristic graph after convolution operation (feature maps), In blocks of different sizes ( Pool box ) To extract features , Namely 4 * 4,2 * 2,1 * 1, Put these three grids on the feature map below , You can get 16+4+1=21 Different kinds of blocks (Spatial Bins), We're from here 21 In blocks , Each block extracts a feature ( The extraction method includes average pooling 、 Maximum pooling, etc ), In this way, a fixed 21 Dimension eigenvector . The process of pooling by the combination of grids of different sizes is spatial pyramid pooling . In this way , We just design m individual n * n A grid of any size can generate an eigenvector of any dimension , We don't need to care about the size of the feature map after multi-layer convolution , This also means that we don't need to care about the size of the image input online .
Spatial Pyramid Pooling It is the spatial pyramid pool layer on the convolution feature , No matter how big the input image is , Suppose that the final single channel featuramap Scale is N*N.** utilize max pooling The operation divides it into 1x1,2x2,4x4 Of 3 Zhang Zi Tu , thus Originally arbitrary N*N Of featuremap, Are expressed as 21 A fixed dimensional vector **, Then enter the full connection layer . When actually carrying out the detection task , You can design this according to the task itself spp operation . This solves the problem of graphs with different input sizes , Avoid scaling deformation and other operations .

4.2.2 Improve the inefficiency of feature calculation 
utilize R-CNN Target detection , Although in VOC and ImageNet It shows excellent detection accuracy , however R-CNN The calculation of feature extraction is very time-consuming , Mainly because there are as many as... In each picture 2000 The pixels of a candidate region are called repeatedly CNN Extract features . There are a lot of overlapping parts in the candidate regions , This design obviously causes a lot of computational waste .
SPPnet The approach is first through selective search , Search out the image to be tested 2000 Candidate windows . This step and R-CNN equally . Then put the whole picture to be tested , Input CNN in , One time feature extraction , obtain feature maps, And then in feature maps Find the region of each candidate box through the mapping relationship , Then we use pyramid space pooling for each candidate box , Extract the fixed length feature vector . and R-CNN The input is for each candidate box , And then into CNN, because SPP-Net It only needs to extract the feature of the whole picture once , The speed will be greatly improved .
The key to the problem is the characteristic graph (feature maps) The size of is based on the size of the picture and the convolution kernel size of the convolution layer (kernel size) And step size (stride) Decisive , How to find the corresponding candidate region on the original graph on the feature graph , That is, what is the mapping relationship between the two .
A formula is given in the paper :
hypothesis ( x ′ , y ′ ) \left(x^{\prime}, y^{\prime}\right) (x′,y′) Represents the coordinate points on the feature map , Coordinates ( x , y ) (x, y) (x,y) Represents the point on the original input picture , Then there is the following rotation between them Exchange relation , This mapping concern is related to the network structure : ( x , y ) = ( S x ′ , S y ′ ) (x, y)=\left(S x^{\prime}, S y^{\prime}\right) (x,y)=(Sx′,Sy′)
In turn, , We hope to pass ( x , y ) (x, y) (x,y) Coordinate solution ( x ′ , y ′ ) \left(x^{\prime}, y^{\prime}\right) (x′,y′) , Then the calculation formula is as follows :
Left、Top: x ′ = ⌊ x / S ⌋ + 1 x^{\prime}=\lfloor x / S\rfloor+1 x′=⌊x/S⌋+1
Right,Bottom : x ′ = ⌈ x / S ] i a n − 1 x^{\prime}=\lceil x / S]^{i a n}-1 x′=⌈x/S]ian−1.
S Namely CNN All of the strides The product of the , Including pooling 、 Convolution stride
4.3 SPP-Net Some of the problems
Inherited R-CNN The problem of
① Need to store a large number of features
② Complex multi-stage training
③ Long training time
5. summary
First, let's review R-CNN Processing flow :
- Enter a multi-target image , use selective search The algorithm extracts about 2000 individual region proposals;
- First in every region proposal Add around 16 Pixel values ( by proposal region Average value , Incline to this ) Border , Then directly deform into 227×227 Size (AlexNet Input size for );
- First of all, put all the warped region proposals After subtracting its own average , And then, in turn, put each 227×227 Of warped region proposal Input AlexNet CNN Internet access 4096 Dimension characteristics ,2000 individual region proposals Of CNN Combine features into 2000×4096 D matrix ;
- take 2000×4096 Dimensional features and 20 individual SVM The weight matrix 4096×20 Multiply , get 2000×20 The dimensional matrix represents each region proposal Is the score of an object category ;
- Respectively for the above 2000×20 Each column in the dimensional matrix, i.e. each class, is subject to non maximum suppression to eliminate overlap region proposals, Get this column, that is, the highest score in this category region proposals;
- Use them separately 20 A regressor for the above 20 Of the remaining categories region proposals Perform regression operation , Finally get the highest score of each category after correction bounding box.
R-CNN Technical points :
- R-CNN use AlexNet
- R-CNN use Selective Search Technology generation Region Proposal.
- R-CNN stay ImageNet We're going to train first , Then use the mature weight parameters in PASCAL VOC On the dataset fine-tune
- R-CNN use CNN Extracting features , And then use a series of SVM Make category predictions .
- R-CNN Of bbox Position regression is based on DPM The inspiration of , I trained a linear regression model .
R-CNN shortcoming :
- Need to store a large number of features
- Complex multi-stage training
- Long training time
版权声明
本文为[Jsper0420]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/04/202204231804166738.html
边栏推荐
- Docker 安裝 Redis
- JD-FreeFuck 京东薅羊毛控制面板 后台命令执行漏洞
- Install pyshp Library
- Eigen learning summary
- re正則錶達式
- Process management command
- Theory and practice of laser slam in dark blue College - Chapter 2 (odometer calibration)
- Logic regression principle and code implementation
- Pointers in rust: box, RC, cell, refcell
- Nodejs安装
猜你喜欢

cv_ Solution of mismatch between bridge and opencv
解决允许在postman中写入注释请求接口方法

2022 Jiangxi energy storage technology exhibition, China Battery exhibition, power battery exhibition and fuel cell Exhibition
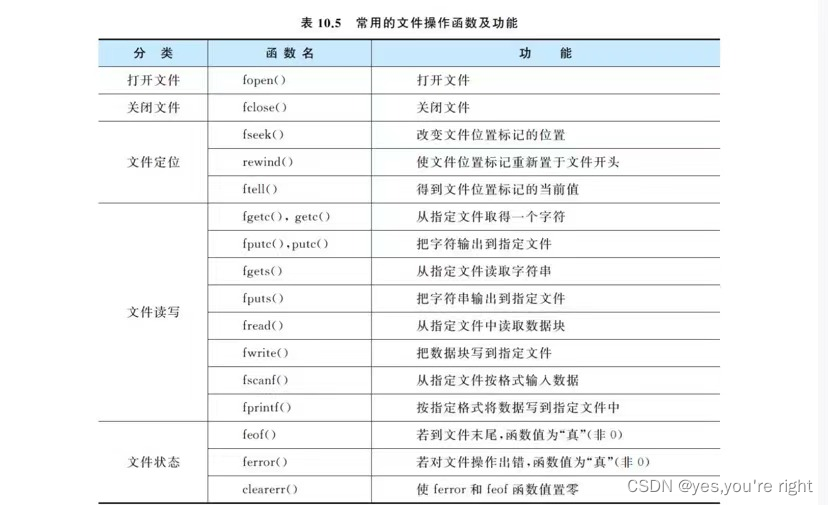
Using files to save data (C language)
Go's gin framework learning

From source code to executable file

Cloud native Virtualization: building edge computing instances based on kubevirt
re正则表达式

ArcGIS table to excel exceeds the upper limit, conversion failed
Install pyshp Library
随机推荐
Auto. JS custom dialog box
Timestamp to formatted date
MySQL_ 01_ Simple data retrieval
Nat Commun|在生物科学领域应用深度学习的当前进展和开放挑战
YOLOv4剪枝【附代码】
Go language JSON package usage
Crawl the product data of Xiaomi Youpin app
I / O multiplexing and its related details
C network related operations
Go语言JSON包使用
Secure credit
ES6 face test questions (reference documents)
Rust: how to implement a thread pool?
Basic usage of crawler requests
Multi thread crawling Marco Polo network supplier data
.105Location
Calculation of fishing net road density
Rust: shared variable in thread pool
Amount input box, used for recharge and withdrawal
7-21 wrong questions involve knowledge points.